
Towards Improving Speaker Distance Estimation through Generative Impulse Response Augmentation
Source: arXiv:2605.00721 · Published 2026-05-01 · By Anton Ratnarajah, Mehmet Ergezer, Arun Nair, Mrudula Athi
TL;DR
This paper addresses the ICASSP 2025 GenDARA / Room Acoustics and Speaker Distance Estimation challenge, where the core bottleneck is sparse and mismatched room impulse response (RIR) data for training speaker distance estimation (SDE) models. The authors’ idea is to synthesize additional RIRs with FastRIR, but not in a generic way: they strip away room-geometry conditioning and condition only on source and listener locations, then filter the generated signals so they better match the target challenge distributions before using them for SDE fine-tuning.
The main result is that this augmentation pipeline substantially lowers distance-estimation error. Using their generated and filtered RIRs, they report MAE reductions from 1.66 m to 0.6 m on GWA rooms and from 2.18 m to 0.69 m on Treble rooms. The gains are strongest at medium-to-long ranges; they explicitly note worse performance below 1 m, where the synthetic data are sparse and the acoustics are harder to model. The paper is therefore less about a novel SDE architecture and more about a practical recipe for making synthetic acoustic augmentation useful under a tight distribution-matching constraint.
Key findings
- Task 1 pretraining used 100,000 RIRs from the GWA dataset before dataset-specific fine-tuning on Treble and GWA enrollment RIRs.
- They generated approximately 1 million candidate RIRs with modified FastRIR, then retained about 25% after filtering, yielding around 260,000 high-quality RIRs.
- The quality filter enforced T60 within ±20% of the reference distribution and excluded RIRs with T60 exceeding 1.8695.
- The filter also excluded source-receiver distances below 0.8 m and above 7.1 m, based on physical consistency with expected DRR behavior.
- SDE MAE improved from 1.66 m to 0.6 m on GWA rooms after augmentation and fine-tuning.
- SDE MAE improved from 2.18 m to 0.69 m on Treble rooms after augmentation and fine-tuning.
- They report that separate dataset-specific SDE models improved further, with MAE reductions of 10% for Treble and 5% for GWA relative to their unified model.
- Performance is notably worse for speaker positions under 1 m, which the authors attribute to limited close-range training examples and harder-to-model near-field acoustics.
Methodology — deep read
The threat model is implicit rather than adversarial in the security sense: the paper is not about an active attacker but about data scarcity and domain mismatch in SDE training. The authors assume the challenge provides sparse enrollment RIRs for each environment and that source/listener locations are the primary variables worth conditioning on. They also assume that within Rooms 1–10 and Rooms 11–20, acoustic conditions are sufficiently stable that separate generative models can be trained for Treble and GWA without needing to model every microscopic room variation.
For data, the paper uses 100,000 RIRs from the GWA dataset as the pretraining corpus for FastRIR. For fine-tuning, they split each dataset’s enrollment RIRs 80/20, using 80% for training and 20% for validation/checkpoint selection. They also produce about 1 million synthetic RIR candidates from the modified generator by sampling speaker/listener positions, then filter them down to roughly 260,000. The paper does not specify the exact number of enrollment RIRs, the exact train/validation counts per split, or whether any held-out room-wise split was used beyond the described 80/20 partition. No explicit preprocessing beyond the representation changes and quality filtering is described.
Architecturally, they start from the open-source FastRIR diffusion-based GAN-like generator and modify it in three stated ways: they remove room-geometry conditioning, extend it to generate 1-second RIRs at 32 kHz, and adapt the input features so they encode only distance-related parameters. They also adopt an RIR representation scheme from MESH2IR to keep energy distribution consistent across distances. The novelty here is not a brand-new generator family, but a simplification and reconditioning of FastRIR so that it is driven only by source-receiver geometry rather than full room layout. That is important because the target task is distance estimation, not full scene reconstruction.
The training regime is two-stage. First, FastRIR is pretrained on GWA RIRs. Second, there are separate fine-tuning runs for Treble and GWA enrollment data, explicitly kept separate because the authors believe the two simulation families differ too much to combine safely with limited data. After generation, they apply a hand-designed quality filter to synthetic RIRs. The filter keeps only samples whose reverberation time T60 lies within ±20% of the reference distribution, excludes overly long T60s above 1.8695, rejects distances under 0.8 m and above 7.1 m, and checks that the energy-decay curve and early reflections look physically plausible. They then run an off-the-shelf hyperparameter optimization loop over learning rate (1e-5 to 1e-3) and epoch count (5 to 50) to fine-tune the downstream SDE model. The paper does not name the optimizer, batch size, loss function, weight decay, seed policy, or hardware, so those details are unavailable from the text provided.
For evaluation, they compare SDE performance before and after augmentation on all twenty test rooms, with figures separated into the first ten Treble rooms and the last ten GWA rooms. Figure 2 shows ground-truth distance distributions, predicted distributions, and predicted-vs-true scatter plots with MAE and correlation coefficients. The main reported metric is MAE. The baseline SDE model achieves 1.66 m on GWA and 2.18 m on Treble; their augmented pipeline reduces these to 0.6 m and 0.69 m, respectively. They also perform an additional dataset-specific experiment where training separate SDE systems for Treble and GWA yields another 10% MAE reduction for Treble and 5% for GWA relative to the unified model. Figure 3 compares generated time-domain RIRs from the Treble- and GWA-fine-tuned generators at the same source-receiver distance and shows different reflection patterns, supporting the claim that simulation-specific fine-tuning matters. The paper does not report statistical significance testing, confidence intervals, or cross-validation beyond the described validation split.
A concrete end-to-end example: starting from a speaker/listener position pair, the modified FastRIR generates a 1-second, 32 kHz synthetic RIR conditioned only on that distance-related geometry. The synthetic candidate is then screened for plausible T60, DRR, decay curve shape, and early reflections. If it passes, it joins the augmented corpus used to fine-tune the SDE model. That fine-tuned model is then evaluated on challenge rooms, where the authors report the large MAE drops above. Reproducibility is partially supported by the use of an open-source generator (FastRIR) and explicit references to prior datasets and models, but the paper does not mention code release, frozen weights, or release of the filtered RIR set.
Technical innovations
- They modify FastRIR to condition only on speaker and listener locations, removing explicit room-geometry conditioning.
- They introduce a synthetic-RIR quality filter based on T60, DRR, decay-curve shape, early reflections, and distance bounds to align generated data with challenge distributions.
- They use MESH2IR-style RIR representation to stabilize energy distribution across different source-receiver distances.
- They show that separate fine-tuning on Treble and GWA produces better RIRs than a single unified fine-tune when deployment context is known.
Datasets
- GWA — 100,000 RIRs for FastRIR pretraining; additional enrollment RIRs for fine-tuning — public dataset
- Treble enrollment RIRs — size not specified in the provided text — challenge data
- C4DM — size not specified in the provided text — baseline experiments
- VCTK — size not specified in the provided text — baseline experiments
Baselines vs proposed
- Provided baseline SDE model: MAE = 1.66 m on GWA vs proposed: 0.6 m
- Provided baseline SDE model: MAE = 2.18 m on Treble vs proposed: 0.69 m
- Unified augmented SDE model vs dataset-specific SDE models: MAE reduced by 10% on Treble and 5% on GWA relative to the unified model (exact absolute values not reported)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.00721.
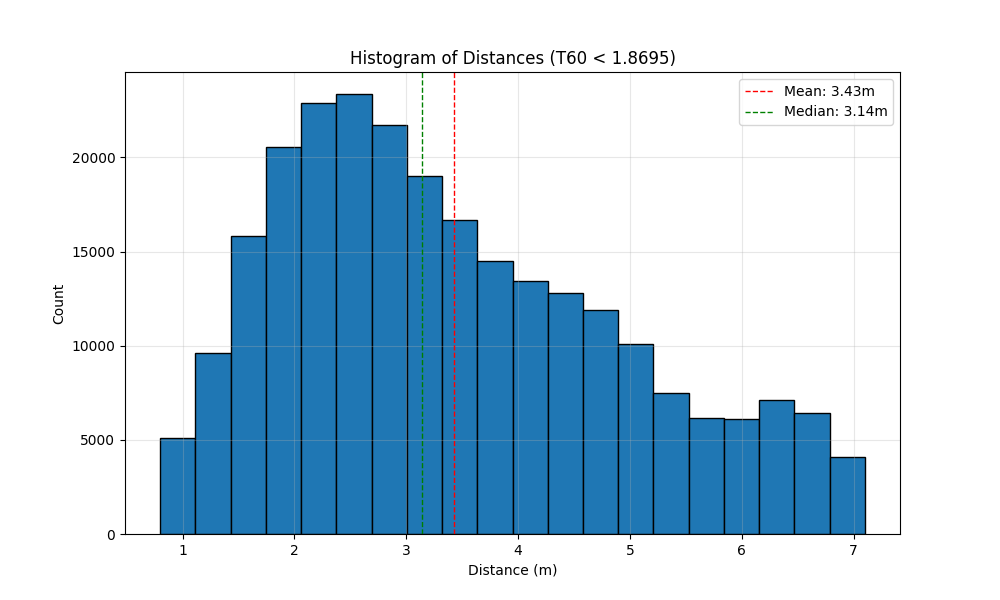
Fig 1: illustrates the distance distribution for these refined
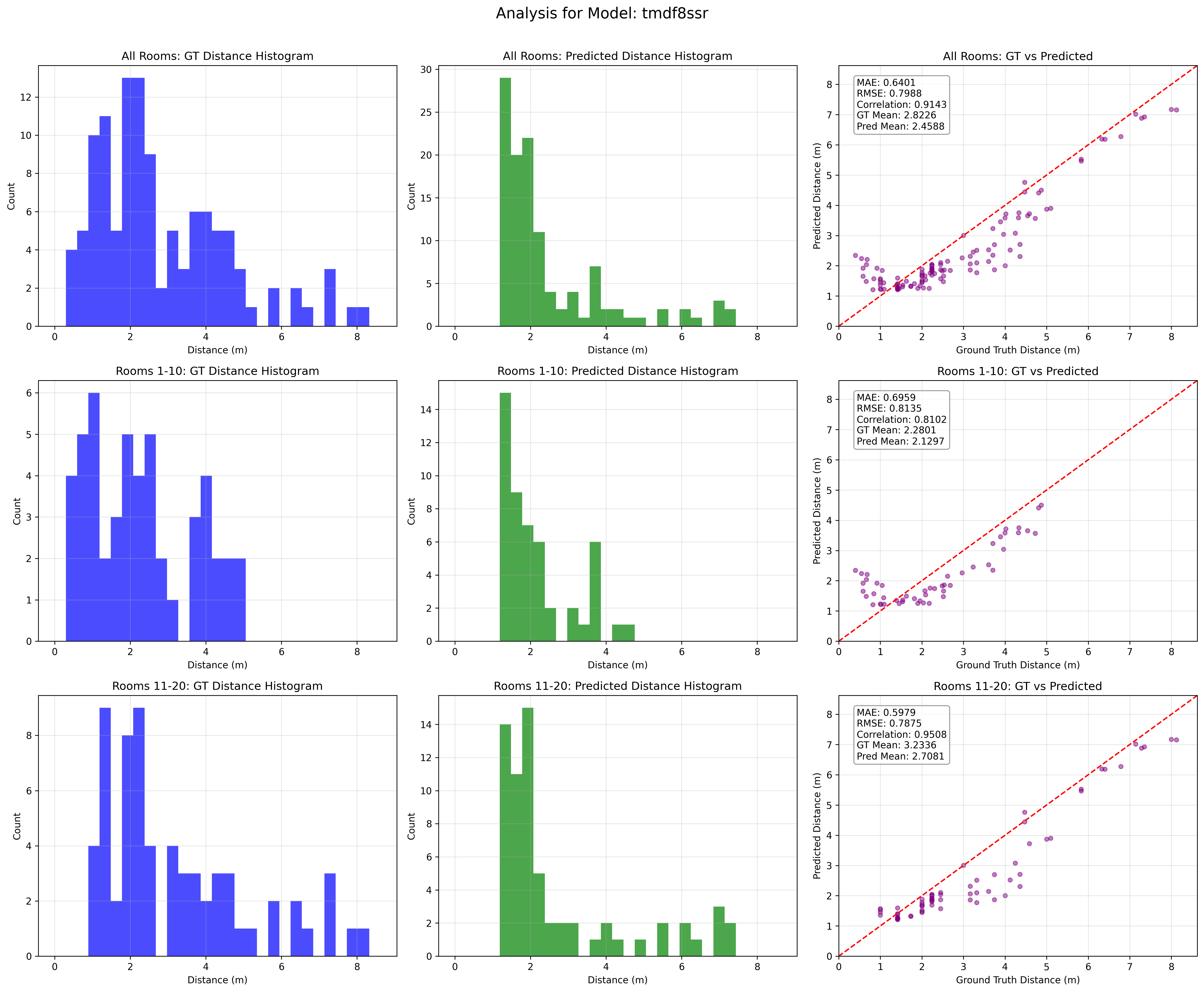
Fig 2: Performance evaluation of our speaker distance es-
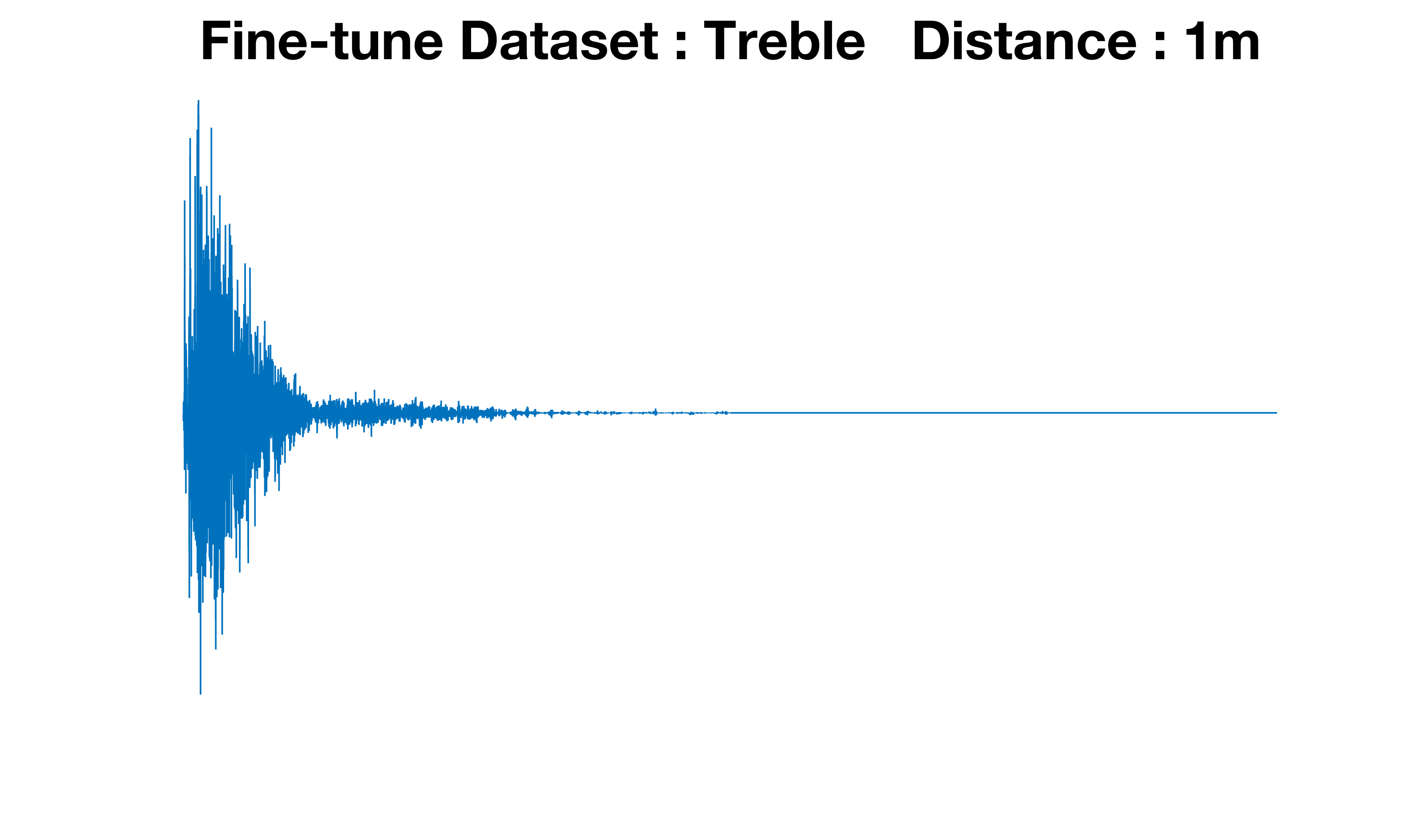
Fig 3: Time-domain comparison of RIRs generated using
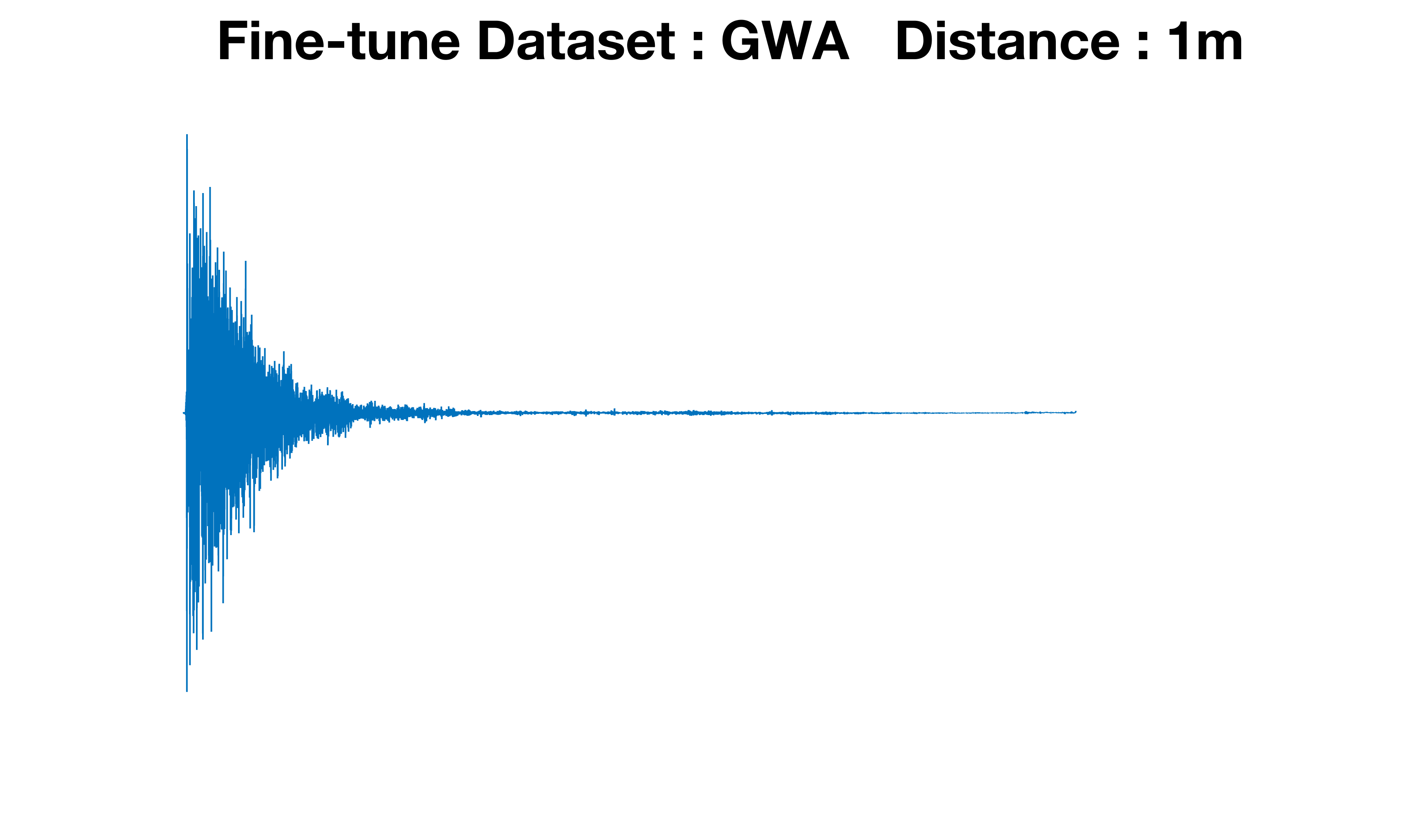
Fig 4 (page 3).
Limitations
- The paper does not report the exact number of enrollment RIRs, so the effective sample size for fine-tuning is unclear.
- The quality filter is hand-designed and somewhat heuristic; the paper does not validate it against an external perceptual or physical ground-truth criterion.
- Performance drops below 1 m, especially for Treble, indicating weak close-range coverage in the synthetic data.
- No statistical significance tests, confidence intervals, or variance across random seeds are reported in the provided text.
- The generator and downstream model details are underspecified: batch size, optimizer, loss, hardware, and seed strategy are not given.
- The work is evaluated on controlled challenge rooms, so generalization to more diverse real-world acoustic scenes remains untested.
Open questions / follow-ons
- Can the quality filter be learned automatically rather than tuned with fixed thresholds on T60, DRR, and distance bounds?
- Would a joint model that conditions on room class plus geometry outperform the fully geometry-agnostic FastRIR variant?
- How well does the augmentation strategy transfer to real recordings with microphone mismatch, background noise, and non-ideal room geometry?
- Can the close-range failure mode below 1 m be fixed with targeted near-field synthesis or separate local-distance modeling?
Why it matters for bot defense
For bot-defense or CAPTCHA practitioners, the most relevant lesson is methodological: synthetic augmentation only helps when the generator is aligned tightly with the deployment distribution, and filtering can matter as much as generation. The paper’s quality-control stage is a concrete example of rejecting large amounts of synthetic data to preserve fidelity, which maps well to adversarial settings where naive augmentation can widen the train-test gap instead of shrinking it.
More broadly, this work suggests a useful pattern for detection systems under sparse labels: generate lots of candidates, then enforce physics- or behavior-based consistency before training. In CAPTCHA and bot-detection pipelines, that translates to being careful about synthetic traffic, interaction traces, or environmental signals—especially when the hardest cases are rare regimes like very close-range speaker positions here, or low-and-slow humanlike bot behavior in a defense context.
Cite
@article{arxiv2605_00721,
title={ Towards Improving Speaker Distance Estimation through Generative Impulse Response Augmentation },
author={ Anton Ratnarajah and Mehmet Ergezer and Arun Nair and Mrudula Athi },
journal={arXiv preprint arXiv:2605.00721},
year={ 2026 },
url={https://arxiv.org/abs/2605.00721}
}