
Meritocratic Fairness in Budgeted Combinatorial Multi-armed Bandits via Shapley Values
Source: arXiv:2605.00762 · Published 2026-05-01 · By Shradha Sharma, Swapnil Dhamal, Shweta Jain
TL;DR
This paper addresses the challenge of introducing meritocratic fairness in budgeted combinatorial multi-armed bandits with full-bandit feedback (BCMAB-FBF), a setting where only the aggregate reward of chosen subsets is observed rather than individual arm rewards. Traditional Shapley value, a cooperative game theory concept for fair value allocation, cannot be directly used because coalitions larger than the budget K are infeasible and the valuation function is unknown. The authors propose the K-Shapley value, a novel extension of the Shapley value tailored for restricted coalition sizes, and prove it uniquely satisfies key fairness axioms (Symmetry, Linearity, Null player, and a modified Efficiency). Building upon this, they present K-SVFair-FBF, a bandit algorithm that adaptively estimates K-Shapley values under noisy, full-bandit feedback using Monte Carlo approximations and repeated evaluations to reduce noise. The algorithm balances exploration and fairness-driven exploitation, achieving a provable fairness regret of ∈(˜O(T^{3/4})) which is close to the theoretical lower bound for full feedback. Experimental results on synthetic, federated learning (FL), and social influence maximization (SIM) datasets demonstrate that K-SVFair-FBF attains significantly lower fairness regret and more merit-proportional selection frequencies than strong baselines, while maintaining overall performance like global model accuracy in FL. This work is the first to address meritocratic fairness in BCMAB-FBF without strong reward structure assumptions.
Key findings
- Introduced K-Shapley value uniquely satisfying Symmetry, Linearity, Null player, and a novel K-efficiency axiom in budget-restricted cooperative games.
- K-SVFair-FBF algorithm achieves sublinear fairness regret bounded by ˜O(T^{3/4} K M^{1/2}) with high probability (Theorem 3).
- Monte Carlo approximation with R=500 permutations and L=200 repeated plays yields stable and low-variance K-Shapley value estimates for noisy full-bandit feedback.
- In synthetic experiments (M=20, K=5), K-SVFair-FBF maintains near-constant merit-to-selection ratios across arms, indicating selections proportional to estimated merit (Fig 1a).
- In social influence maximization (534 nodes, K=20), K-SVFair-FBF outperforms Fair-CMAB and greedy baselines, achieving lower fairness regret and more equitable node selection (Fig 1b, 2b).
- For federated learning on CIFAR-10 with 100 clients (K=10), K-SVFair-FBF achieves lower fairness regret and improves global model accuracy relative to Shapley and fairness baseline methods (Fig 1c, 2c, Appendix C.5).
- Baseline approaches (Fair-CMAB, ETCG, GAP-E) either rely on fixed quota fairness or focus on reward maximization, resulting in skewed merit-to-selection ratios and higher fairness regret.
- K-SVFair-FBF balances the twin noise sources from learning valuation functions and Monte Carlo estimation better than exploration-separation methods like MURaS, leading to improved regret rates.
Threat model
The adversary is the stochastic and unknown environment generating rewards for subsets of arms, with the learner only observing noisy aggregate rewards of selected subsets (full-bandit feedback). The adversary cannot reveal individual arm contributions or alter the valuation function dynamically. There is no assumption of adversarial arms or strategic manipulation. Learners must contend with inherent observational noise and limited feedback structure.
Methodology — deep read
The authors tackle the problem of meritocratic fairness where arms in a budgeted combinatorial multi-armed bandit with full-bandit feedback (BCMAB-FBF) are selected proportionally to their merit, but individual arm contributions are unobserved.
Threat model & assumptions: The adversary is implicit in the stochastic environment with unknown reward distributions per arm subset; the learner only observes the noisy combined reward of subsets (super arms) of size bounded by K from M arms. No structural assumptions (like submodularity or linearity) are made on the unknown valuation function.
Data: Experiments use synthetic datasets (20 arms, Gaussian noise), federated learning CIFAR-10 partitioned among 100 clients with non-IID Dirichlet distribution, and a social influence maximization dataset from a Facebook subgraph (534 nodes), evaluating fairness and cumulative regret over T=10^8 time steps effectively shortened by internal sampling.
Architecture / algorithm: The key novel component is the K-Shapley value, extending Shapley values to restricted coalitions of size ≤ K, computed as an expectation over marginal contributions limited to feasible coalitions. It satisfies fairness axioms including a novel K-efficiency replacing standard efficiency given grand coalitions are infeasible. On top, the K-SVFair-FBF algorithm initializes with round-robin exploration ensuring each arm is tried, then at each step:
- Uses Monte Carlo sampling with R=500 random permutations of selected subset, and L=200 repeated plays to estimate marginal contributions with variance reduction (Algorithm 2).
- Maintains and updates empirical K-Shapley value estimates per arm with Hoeffding-style confidence bounds to form optimistic estimates.
- Computes fractional selection probabilities proportional to optimistic estimates and uses a randomized rounding scheme (from Gandhi et al. 2006) to select a subset of size K unbiasedly.
- Updates counts and averages iteratively to reduce estimation noise and improve merit estimates.
Training regime: The algorithm runs over very long horizons (T=10^8), with effective rounds scaled by LR internal sampling to handle noise. Confidence bounds are adapted accordingly. Experiments average results over 30 random seeds. Computation is done on CPUs with ample memory.
Evaluation protocol: Metrics include fairness regret compared to the ideal merit-proportional policy, merit-to-selection ratio across arms, and task-specific performance like global model accuracy for federated learning. Baselines include Fair-CMAB (quota based fairness), ETCG (explore then commit), GAP-E (gap based exploration), and various FL-specific Shapley or fairness-aware methods. Results are presented with variance regions and ablation on R and L parameters. Statistical analyses use high probability bounds with Hoeffding inequalities.
Reproducibility: Code or dataset release status is not mentioned explicitly, but datasets used are standard or synthetic. The paper provides detailed algorithms and parameter settings for replication.
Concrete end-to-end example: At round t, the algorithm forms optimistic K-Shapley estimates ˆϕ+ for each arm using past noisy reward aggregation samples, adds confidence terms ct, then forms fractional policy vector πt proportional to ˆϕ+. It uses randomized rounding to choose subsets of size K, obtains the noisy combined reward, computes Monte Carlo marginal contributions via Algorithm 2 with R permutations and L repeats, then updates the K-Shapley estimates ˆϕt,a for all arms included, progressing towards merit-proportional fair selection. This process balances noise from bandit and Monte Carlo sampling, ensuring sublinear fairness regret convergence.
Technical innovations
- Definition and axiomatic characterization of K-Shapley value as a unique solution concept for restricted coalition sizes in budgeted cooperative games.
- K-SVFair-FBF algorithm combining adaptive K-Shapley value estimation under unknown valuation with Monte Carlo sampling and randomized rounding for meritocratic fairness under full-bandit feedback.
- Theoretical fairness regret bound of ˜O(T^{3/4}) for meritocratic fairness in BCMAB-FBF, integrating noise from valuation learning and approximation.
- Adaptation of classical cooperative game fairness axioms to a budget-constrained setting via the novel K-efficiency axiom.
Datasets
- Synthetic dataset — 20 arms with Gaussian noise — synthetic
- CIFAR-10 federated learning dataset — 100 clients, non-IID Dirichlet partition (α=0.2) — publicly available CIFAR-10
- Facebook social network dataset — 534 nodes, 8158 edges — from Leskovec and Mcauley (2012)
Baselines vs proposed
- Fair-CMAB: fairness regret stabilizes higher than K-SVFair-FBF; merit-to-selection ratio shows large skew vs K-SVFair-FBF's near-constant ratio
- ETCG: high skew in merit-to-selection ratio, omitted for clarity; higher fairness regret than K-SVFair-FBF on synthetic data
- MURaS: fairness regret ˜O(T^{4/5}), worse than K-SVFair-FBF's ˜O(T^{3/4})
- GAP-E: slower convergence, higher fairness regret compared to K-SVFair-FBF on social influence maximization
- In FL, K-SVFair-FBF improves global model accuracy relative to ShapleyFL, ShapFed, S-FedAvg baselines while maintaining fairness
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.00762.
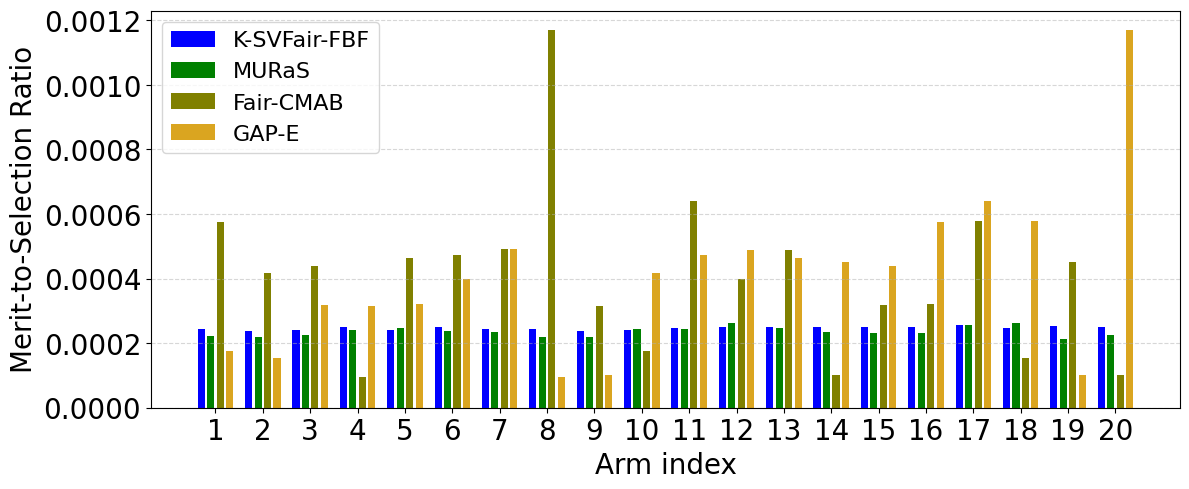
Fig 1: Comparative analysis for Merit-to-selection ratio across all datasets for K-SVFair-FBF and benchmark algorithms.
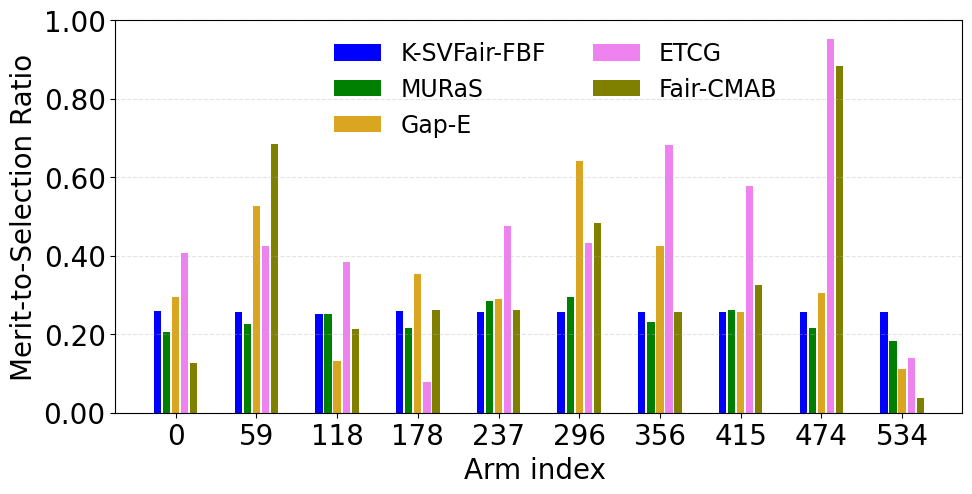
Fig 2: Comparative analysis for Fairness Regret for K-SVFair-FBF and benchmark algorithms.
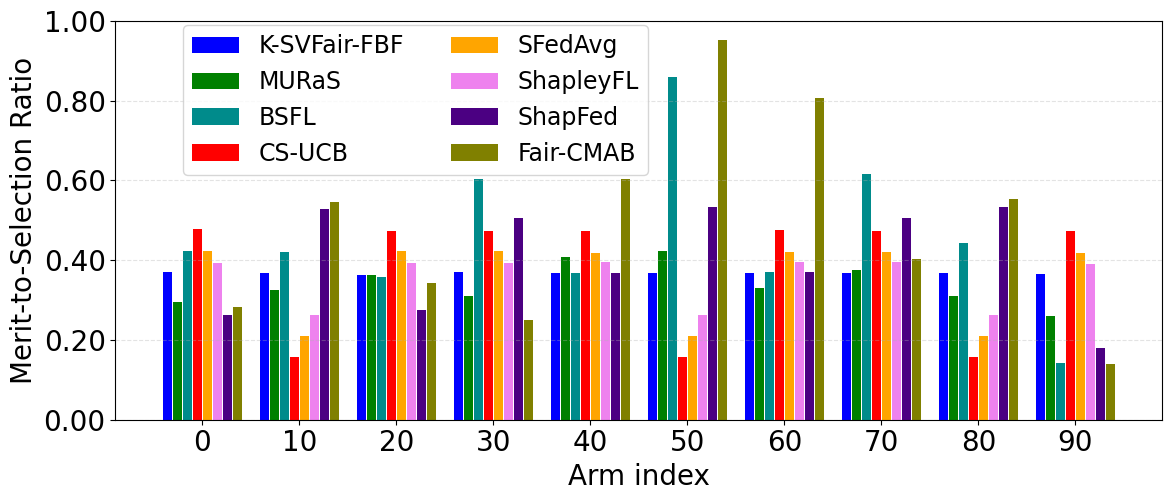
Fig 3 (page 7).
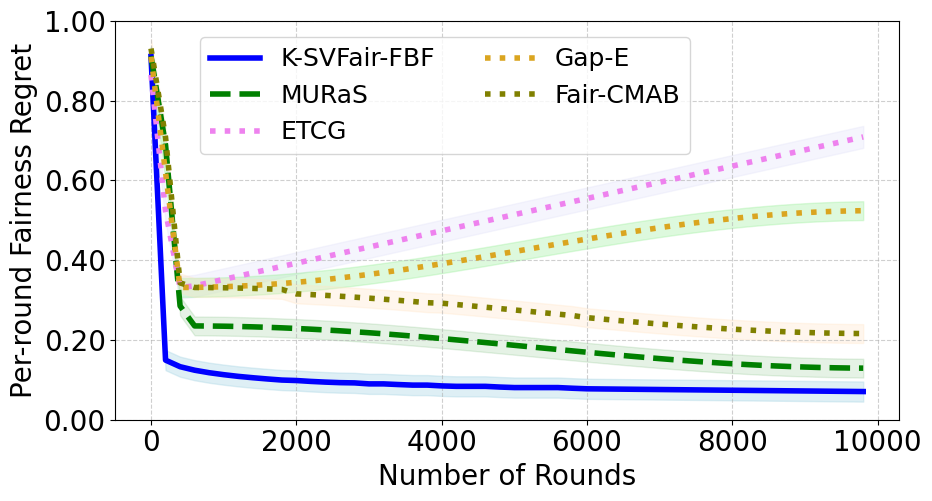
Fig 4 (page 7).
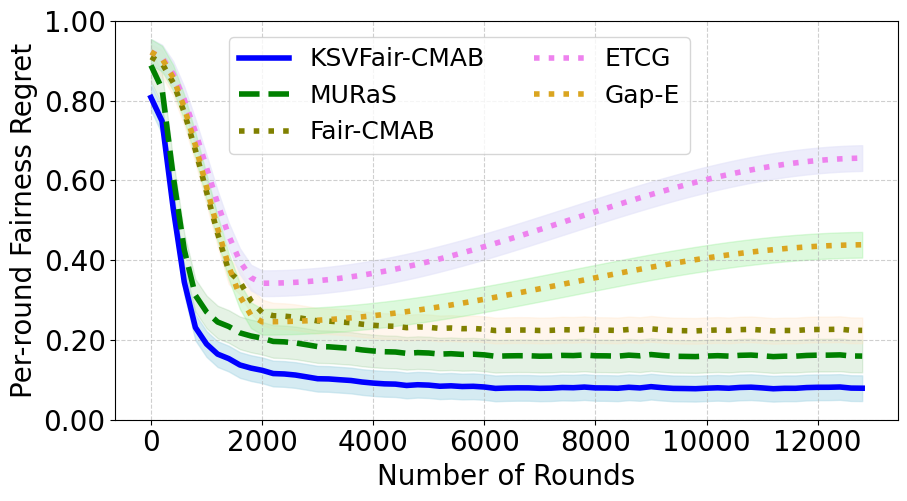
Fig 5 (page 7).
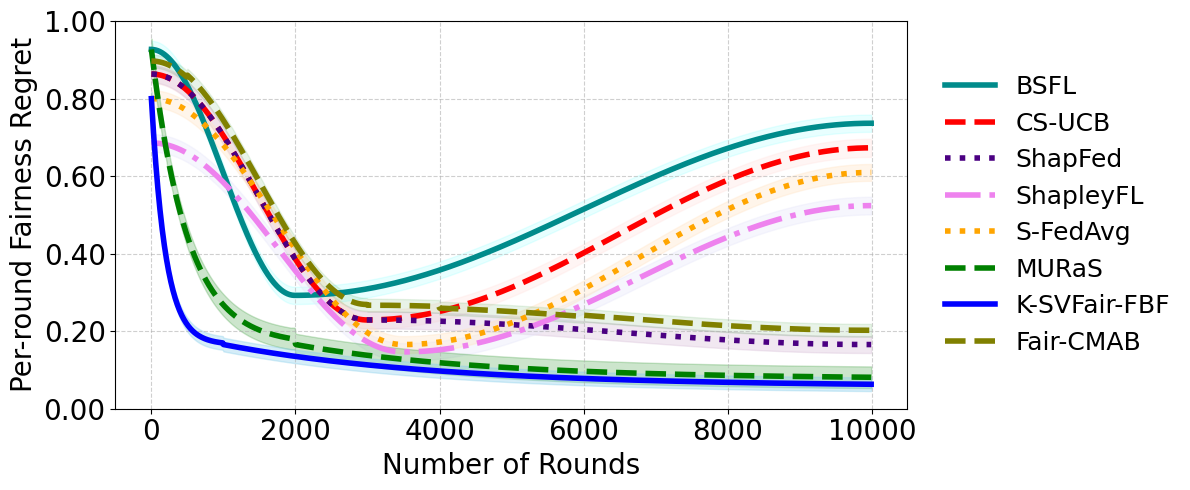
Fig 6 (page 7).
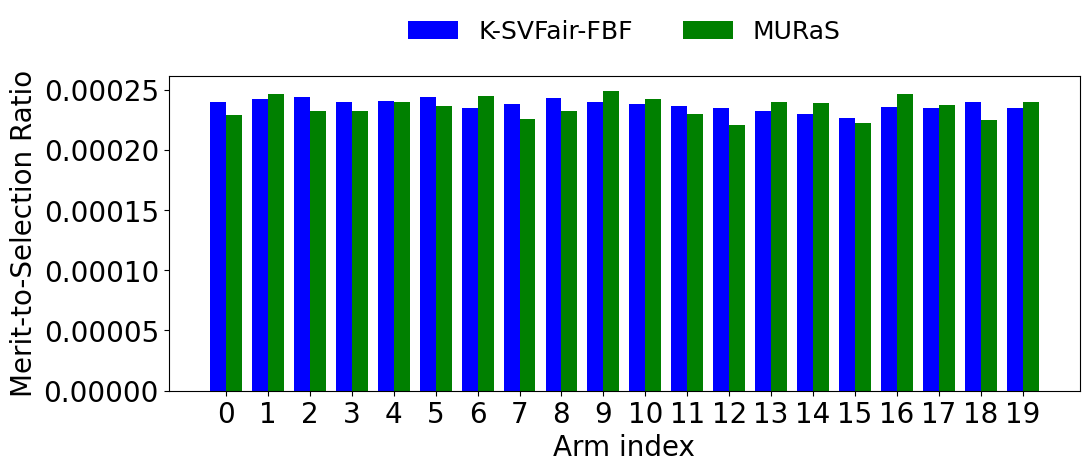
Fig 3: Comparative analysis for Synthetic Dataset for different values of R and L and merit-to-selection ration analysis for K-SVFair-FBF
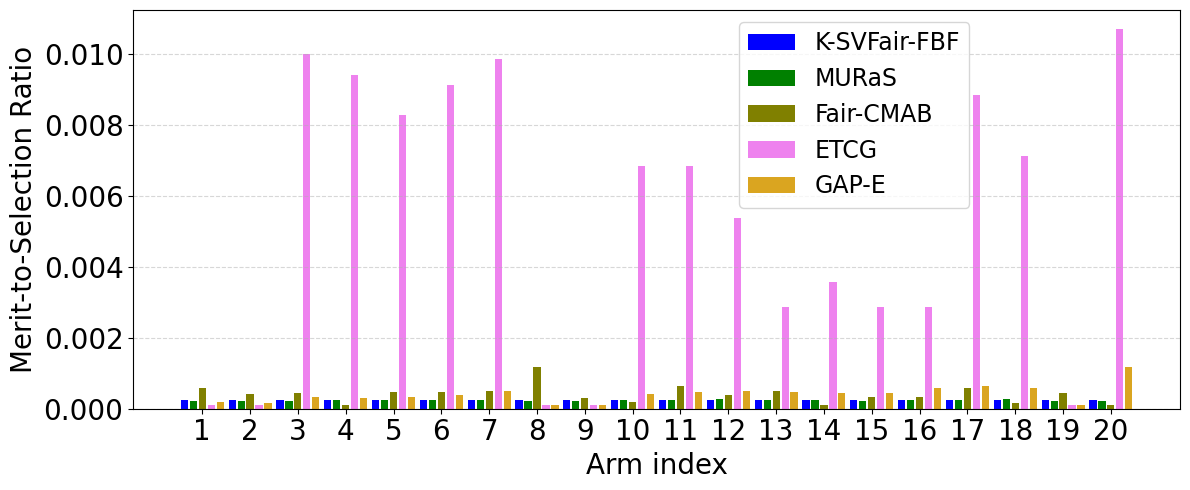
Fig 4: Comparative analysis of Federated Learning Dataset and Social Network Dataset on different values of R and L on K-SVFair-FBF.
Limitations
- The theoretical regret bound of ˜O(T^{3/4}) is slightly weaker than the lower bound O(T^{2/3}) for full-bandit feedback without fairness constraints, indicating room for tighter bounds.
- The algorithm relies on large numbers of Monte Carlo permutations (R=500) and repeated evaluations (L=200), which may be computationally expensive in large-scale or real-time settings.
- Valuation function is assumed fixed but unknown; the approach does not address dynamic or non-stationary reward distributions explicitly.
- Experiments focus on relatively moderate-sized problems (up to 534 nodes in social network); scalability to very large M or tighter budgets K is unclear.
- No adversarial or strategic manipulation scenarios considered; robustness to deliberate gaming of arm rewards is untested.
- Code release and reproducibility details beyond the description are not explicitly provided.
Open questions / follow-ons
- Can the K-Shapley fairness framework be extended to dynamic or non-stationary valuation functions where arm rewards change over time?
- How can the computational cost of Monte Carlo permutations and repeated evaluations be reduced for large-scale or real-time applications?
- Is it possible to tighten the regret bounds closer to the O(T^{2/3}) lower bound while maintaining fairness in full-bandit feedback?
- How would the approach perform under adversarial or strategic arms manipulating observed aggregated rewards?
Why it matters for bot defense
This work provides a principled method to ensure fair, merit-based allocation of resources or selections when only aggregate reward signals are available, a common challenge in bot-defense tasks where granular feedback per component (arm) is hidden or noisy. The K-Shapley value extends classical fairness concepts to budget-constrained combinatorial settings typical in real-world defenses where capacity or budget limits exist. The approach balances exploration and fairness-aware exploitation even under high uncertainty and aggregated feedback, offering a rigorous tool for bot-defense mechanisms that rely on combinatorial decisions without revealing component-level signals. Practitioners designing CAPTCHA or bot-detection workflows where only aggregate performance metrics are observed might apply similar estimation and selection approaches to allocate resources or attention meritocratically across multiple detection features or sources. However, the computational cost and noise sensitivity may require adaptation for latency-sensitive deployments.
Cite
@article{arxiv2605_00762,
title={ Meritocratic Fairness in Budgeted Combinatorial Multi-armed Bandits via Shapley Values },
author={ Shradha Sharma and Swapnil Dhamal and Shweta Jain },
journal={arXiv preprint arXiv:2605.00762},
year={ 2026 },
url={https://arxiv.org/abs/2605.00762}
}