
Empowering Heterogeneous Graph Foundation Models via Decoupled Relation Alignment
Source: arXiv:2605.00731 · Published 2026-05-01 · By Ziyu Zheng, Yaming Yang, Zhe Wang, Ziyu Guan, Wei Zhao
TL;DR
This paper addresses a specific failure mode in multi-domain heterogeneous graph foundation models: when you try to pretrain across domains with different node/edge types, standard global feature alignment methods such as PCA or SVD can erase type-specific meaning and scramble relation structure. The authors argue that this causes two distinct pathologies: “Type Collapse” (different node types overlap after alignment) and “Relation Confusion” (relation reconstruction error rises because topology is distorted). Their central claim is that heterogeneous graphs need relation-aware alignment, not just a unified feature space.
To fix this, they propose Decoupled relation Subspace Alignment (DRSA), a plug-and-play preprocessing module that separates semantic feature projection from structural relation alignment. DRSA first reconstructs heterogeneous relations in a low-rank bilinear subspace using fixed random projections per node type, then decomposes aligned node embeddings into a semantic component plus a structural residual. The optimization is done with alternating block-coordinate descent and closed-form updates. In experiments on several benchmark heterogeneous graphs, DRSA consistently improves downstream cross-domain and few-shot performance when inserted before existing GFM-style encoders, with especially large gains for some baseline-model/dataset pairs.
Key findings
- DRSA improves RMR on ACM node classification from 50.88±14.82 ACC to 65.07±11.33, DBLP from 30.03±5.07 to 82.71±9.06, and AMiner from 25.92±4.27 to 41.20±8.94 (Table II).
- On DBLP node classification, GCOPE+DRSA reaches 79.59±7.05 ACC vs 42.83±5.50 for GCOPE, a +36.76 percentage-point absolute gain (Table II).
- On ACM node classification, MDGPT+DRSA reaches 76.99±11.08 ACC vs 47.40±5.66 for MDGPT, a +29.59 point gain (Table II).
- On Yelp edge classification, GCOPE+DRSA reaches 81.42±7.70 ACC vs 54.50±8.67 for GCOPE, a +26.92 point gain; AUC rises from 70.00±3.38 to 87.42±4.11 (Table III).
- On Yelp, SAMGPT+DRSA reportedly improves edge-classification accuracy by 21.66% absolute, according to the text, showing the method is not limited to one base encoder.
- The paper reports 20%-30% gains on state-of-the-art graph foundation models (GCOPE, MDGPT, SAMGPT) across multiple datasets for node classification, indicating DRSA mainly fixes input-alignment bottlenecks rather than replacing the encoder.
- The authors’ ablation narrative attributes the improvement to the dual mechanism: relation-subspace alignment reduces relation confusion, while feature-structure decomposition prevents type collapse; however, the excerpt does not provide the corresponding ablation table values.
- All reported downstream evaluations are repeated 20 times with different k-shot label samples, and results are reported as mean ± standard deviation (classification metrics: ACC, AUC, F1).
Threat model
The relevant challenge is not an active attacker but heterogeneous cross-domain mismatch: the model assumes multiple unlabeled source-domain heterogeneous graphs with different node types, feature dimensions, and relation semantics, and it must generalize to an unseen target-domain heterogeneous graph. The method assumes no manually designed metapaths and does not rely on target labels during pretraining. It does not consider adversaries that poison source graphs, manipulate node features, or adaptively exploit the alignment procedure; instead, it aims to prevent negative transfer caused by type-specific semantic divergence and relation-structure inconsistency.
Methodology — deep read
The threat model is implicit rather than adversarial in the cryptographic sense: the “adversary” is the distribution shift between source-domain heterogeneous graphs and an unseen target-domain heterogeneous graph, plus the mismatch induced by naive alignment. The paper assumes unlabeled source-domain graphs for pretraining, an unseen target-domain graph for evaluation, and no reliance on manually defined metapaths. It does not model an adaptive attacker who tries to subvert the alignment module; instead, it focuses on negative transfer caused by cross-domain feature shifts and intra-domain relation gaps.
The data setup uses six public heterogeneous graph benchmarks: DBLP, ACM, IMDB, Aminer, Freebase, and Yelp, with Table I summarizing node types, relation types, target node class counts, and node counts. For example, ACM has Paper (4019), Author (7167), and Subject (60) nodes, with relations P-A and P-S and a paper-classification target over 3 classes; DBLP has Author (4057), Paper (14328), Conference (20), and Term (7723) nodes, with P-A, P-C, and P-T relations and 4 author classes; IMDB has Movie (4278), Director (2081), and Actor (5257) nodes and 3 movie classes. The paper describes a leave-one-out multi-domain transfer protocol: one dataset is held out as the target, and the remaining datasets are used for multi-domain pretraining. For downstream node classification, they sample k labeled instances per class for training and use the rest for testing; for link prediction, they define categories by edge types. The excerpt does not specify any train/validation/test split beyond the repeated k-shot sampling for downstream tasks.
Architecturally, DRSA is a preprocessing alignment module that sits before the downstream graph encoder. Its first component is a dual-relation subspace projection. For each node type τ, it defines an outgoing projection A_τ and an incoming projection B_τ, with a low-rank dimension ρ much smaller than k. For a relation between source type ϕ_s and destination type ϕ_d, the relation operator is formed as M_r = A_ϕs B_ϕd^T. Importantly, these A and B matrices are sampled from a Gaussian N(0, σ²) and then frozen, not learned. The relation structure is reconstructed by H_ϕs M_r H_ϕd^T, so the model tries to fit heterogeneous adjacency/relation matrices in a shared latent relation space rather than forcing all node features into one global PCA/SVD subspace. The second component is feature-structure decoupling: each aligned representation is decomposed as H_τ = X_τ P_τ + E_τ, where P_τ is a type-specific semantic projection and E_τ is a residual capturing structure-specific variation. The objective combines relation reconstruction and feature decomposition with ℓ2 penalties on E_τ and P_τ.
Optimization is explicitly alternating and closed-form. Stage 1 fixes feature terms and updates H_τ from relation information alone by solving a convex quadratic subproblem per node type. The text derives normal equations C_τ H_τ^T = B_τ, where C_τ aggregates second-order statistics of neighboring aligned features and the bilinear relation operators, separately handling outgoing and incoming edges for directed heterogeneous graphs. Stage 2 fixes H_τ and updates P_τ and E_τ via ridge-regression-style closed forms: P_τ = (X_τ^T X_τ + γI)^{-1} X_τ^T(H_τ - E_τ), then E_τ = (H_τ - X_τP_τ)/(1+β). This two-stage loop is repeated for T iterations and interpreted as block coordinate descent; the paper claims each subproblem is convex and the objective monotonically decreases, but the excerpt does not provide a formal convergence proof beyond this statement. A concrete end-to-end example is the ACM setup: node features for paper/author/subject are aligned into a shared k-dimensional latent space, relation structure is reconstructed using low-rank bilinear operators for P-A and P-S, and the resulting aligned graph is fed into a pretrained encoder (e.g., GCN/HAN depending on the baseline) before few-shot paper classification.
Evaluation is broad but not especially deep on methodology details. They benchmark ten baselines across three categories: metapath-based methods (MP2V, HeCo, HGMAE), metapath-free heterogeneous methods (RMR, HetGPT, HGPrompt), and graph foundation models (GCOPE, MDGPT, SAMGPT). For single-domain methods, they use SVD to align feature dimensions to 50 before pretraining; for the graph foundation models, they keep a parameter-sharing encoder and integrate DRSA as a universal preprocessing module, yielding variants like GCOPE+DRSA and RMR+DRSA. Encoders are standardized: HAN for HeCo/HGMAE, GAT for RMR, and GCN for all other methods, with hidden size 256. Metrics are ACC, AUC, and F1 for classification, and the reported results are mean ± standard deviation over 20 repeated k-shot runs. The paper also evaluates edge classification to test whether the learned alignment preserves heterogeneous relations. The implementation was run on an NVIDIA RTX 5090 GPU with 32GB memory. Reproducibility is partly supported by released code on GitHub, but the excerpt does not mention frozen weights, exact seeds, or whether all datasets/scripts are fully public.
Technical innovations
- Decoupled feature-structure alignment: the method separates semantic projection X_τP_τ from structural residual E_τ, instead of forcing a single aligned embedding to explain both node semantics and relation topology.
- Low-rank dual-relation subspace projection: relation types are reconstructed through bilinear operators M_r = A_ϕs B_ϕd^T, which factor heterogeneous interactions into shared type-level subspaces rather than one dense matrix per relation.
- Frozen random projection operators: A_τ and B_τ are sampled from a Gaussian and kept non-trainable, reducing parameter coupling and making the relation subspace alignment plug-and-play.
- Block-coordinate closed-form optimization: the algorithm alternates between structure-driven H updates and feature decomposition updates, with each subproblem solved analytically rather than via end-to-end gradient descent.
Datasets
- DBLP — author 4057, paper 14328, conference 20, term 7723 nodes; relations P-A 19645, P-C 14328, P-T 85810 — public benchmark
- ACM — paper 4019, author 7167, subject 60 nodes; relations P-A 13407, P-S 4019 — public benchmark
- IMDB — movie 4278, director 2081, actor 5257 nodes; relations M-D 4278, M-A 12828 — public benchmark
- Aminer — paper 6564, author 13329, reference 35890 nodes; relations P-A 18007, P-R 58831 — public benchmark
- Yelp — business 2614, user 1286, service 4, rating levels 9 nodes; relations B-U 30383, B-S 2614, B-L 2614 — public benchmark
- Freebase — included in the evaluation list, but the excerpt does not provide node/relation counts or target task details — public benchmark
Baselines vs proposed
- MP2V: ACM ACC = 32.61±0.99 vs proposed (RMR+DRSA): 65.07±11.33
- HeCo: DBLP ACC = 55.47±10.43 vs proposed (HeCo is not shown with DRSA in the excerpt; the paper instead reports HeCo baseline only in Table II)
- HGMAE: ACM ACC = 67.22±12.96 vs proposed (no DRSA variant shown in the excerpt)
- RMR: DBLP ACC = 30.03±5.07 vs proposed (RMR+DRSA): 82.71±9.06
- HGPrompt: ACM ACC = 56.07±9.73 vs proposed (HGPrompt+DRSA): 70.90±11.51
- HetGPT: DBLP ACC = 32.44±5.95 vs proposed (HetGPT+DRSA): 75.72±9.62
- GCOPE: ACM ACC = 49.02±7.42 vs proposed (GCOPE+DRSA): 80.48±11.26
- MDGPT: DBLP ACC = 32.19±2.69 vs proposed (MDGPT+DRSA): 77.70±10.10
- SAMGPT: ACM ACC = 46.34±4.82 vs proposed (SAMGPT+DRSA): 76.34±12.49
- RMR: Yelp edge-classification ACC = 37.89±9.85 vs proposed (RMR+DRSA): 44.26±7.46
- GCOPE: Yelp edge-classification ACC = 54.50±8.67 vs proposed (GCOPE+DRSA): 81.42±7.70
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2605.00731.
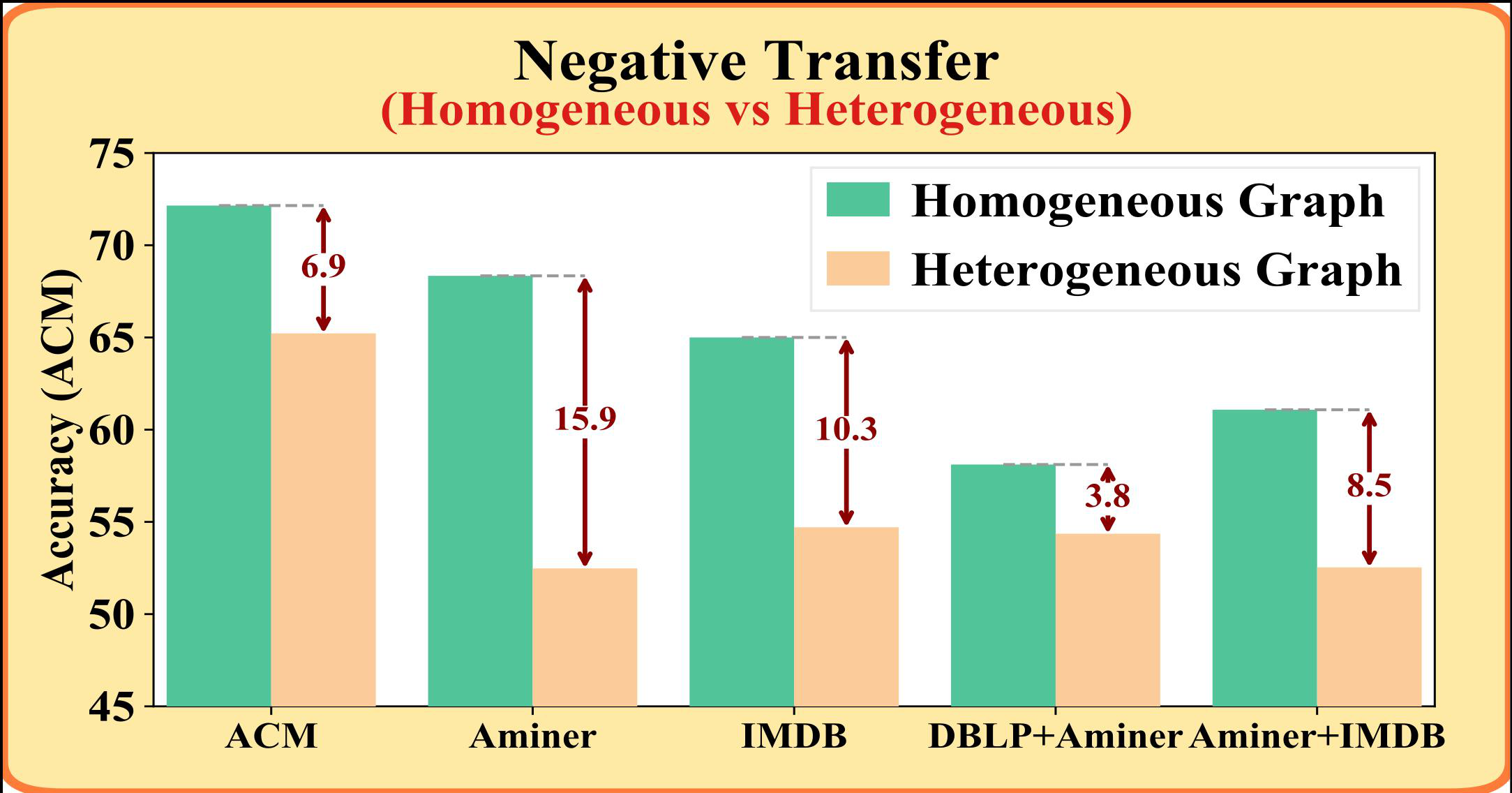
Fig 1: Multi-domain heterogeneous graph foundation models
Fig 2: Multi-domain heterogeneous graphs face two fundamen-

Fig 3: Overview of the DRSA framework. DRSA decouples node features into semantic projections and structural residuals,
Fig 4 (page 2).
Fig 5 (page 2).
Fig 6 (page 2).
Fig 7 (page 2).
Fig 8 (page 2).
Limitations
- The excerpt does not provide the full ablation table, so the relative importance of the dual-relation projection versus the feature-residual decomposition is not numerically isolated here.
- The random projection matrices A_τ and B_τ are frozen by design, but the paper excerpt does not justify the chosen random dimension ρ or discuss sensitivity to σ and ρ.
- The evaluation is strong on cross-domain transfer but weak on stress tests against distribution shift severity, missing types, or noisy/perturbed relations.
- For single-domain baselines, the paper uses SVD alignment to 50 dimensions, which may not be an equally strong or equally fair preprocessing baseline for all methods.
- The excerpt does not report runtime, memory overhead, or convergence speed of the alternating solver, so practical cost remains unclear.
- The source text mentions Freebase in the benchmark list but does not show its results in the provided tables, leaving some coverage ambiguous.
Open questions / follow-ons
- How sensitive is DRSA to the random projection rank ρ and to the number of alternating iterations T across very different graph scales?
- Can the relation-subspace formulation be learned end-to-end with the downstream encoder while preserving stability, or is the frozen-projection design essential?
- How well does DRSA handle domain shift that changes not just distributions but also the relation schema itself, such as missing or extra node/edge types at test time?
- Would the same decoupled alignment idea help in other graph pretraining settings, such as temporal heterogeneous graphs or multimodal graphs with text/image features?
Why it matters for bot defense
For bot-defense and CAPTCHA-adjacent practitioners, the main takeaway is architectural rather than directly operational: if your detection or risk model uses heterogeneous graphs of users, devices, sessions, payments, IPs, and challenge outcomes, a naive global alignment layer can destroy type-specific signals and flatten structurally different entities into one space. DRSA suggests a safer pattern: align only the shared relational subspace while preserving type semantics through a residual channel. That is relevant when you want a reusable representation layer across regions, products, or attack surfaces without collapsing device, account, and behavior roles into one indistinguishable embedding.
The practical reaction is to be cautious about PCA/SVD-style preprocessing when mixing heterogeneous telemetry sources. If you are transferring a graph model from one market or product line to another, DRSA’s decoupled design is a reminder to inspect whether performance failures come from the encoder or from the input alignment step. For CAPTCHA or bot-fraud pipelines, the method also suggests a route to fewer hand-engineered metapaths by learning relation-aware alignment directly; however, because the paper’s evaluation is on academic/movie/review graphs rather than abuse graphs, any deployment would need fresh validation on real adversarial traffic and schema drift.
Cite
@article{arxiv2605_00731,
title={ Empowering Heterogeneous Graph Foundation Models via Decoupled Relation Alignment },
author={ Ziyu Zheng and Yaming Yang and Zhe Wang and Ziyu Guan and Wei Zhao },
journal={arXiv preprint arXiv:2605.00731},
year={ 2026 },
url={https://arxiv.org/abs/2605.00731}
}