
LLM as Clinical Graph Structure Refiner: Enhancing Representation Learning in EEG Seizure Diagnosis
Source: arXiv:2604.28178 · Published 2026-04-30 · By Lincan Li, Zheng Chen, Yushun Dong
TL;DR
This paper addresses the challenge of robust representation learning from noisy EEG data for automated seizure detection. Existing graph construction techniques for EEG channels, whether correlation-based or data-driven, are prone to generating redundant and spurious edges due to signal noise and variability, which degrade downstream performance. Motivated by large language models' (LLMs) advanced reasoning and contextual understanding, the authors propose a novel two-stage framework where an initial EEG channel graph is constructed by a Transformer-based edge predictor, then refined by an LLM that acts as an intelligent graph edge filter using both textualized and statistical features of channel pairs. Experiments on the public TUSZ dataset show that this LLM-refined graph learning approach significantly improves seizure detection accuracy, achieving an F1 score of 0.7907 versus 0.7351 for the best non-LLM baseline. The refined graphs are not only sparser and more consistent but also more physiologically plausible, aligning with known seizure propagation dynamics. The study furthermore establishes a clinical graph refinement benchmark comparing multiple state-of-the-art LLMs, revealing that larger models such as GPT-5 provide the most stable and interpretable graph reasoning.
Key findings
- The LLM-refined framework improves seizure detection F1 from 0.7351 (generative graph learner) to 0.7907 (GPT-5 + Transformer graph), boosting accuracy from 0.9039 to 0.9315 on TUSZ dataset (Table 1).
- Graph sparsity reduces with LLM refinement, with GPT-5 producing the sparsest graphs (0.3741) compared to Mistral 7B (0.4213), indicating effective edge pruning (Table 2).
- Jensen-Shannon Divergence (graph structural consistency) decreases systematically with model size, reaching 0.0265 for GPT-5, showing more stable graph reasoning (Table 2).
- LLM-based edge refinement creates clinically plausible EEG networks that capture seizure onset in frontal regions and propagation to temporal lobe, aligning with ground-truth annotations (Fig 2).
- Edge difference heatmaps reveal GPT series produce highly consistent graph structures, while smaller models like Mistral and Llama show more stochastic, less stable connectivity patterns (Fig 3).
- Textualization of EEG channel features (anatomical location, high-level observations) plus statistical metrics (mean amplitude, skewness, energy, zero-crossing rate) enables effective LLM reasoning about edge validity.
- The LLM refinement operates on initial Transformer-MLP predicted edges by querying the LLM with structured prompts for each candidate edge, iteratively producing final refined adjacency matrices.
- Smaller LLMs tend to explore diverse edges but with less reliability, while larger LLMs yield coherent, interpretable graphs better aligned with physiological knowledge.
Threat model
The threat model is implicit rather than adversarial security focused: the challenge is modeling noisy, artifact-rich EEG signals that include redundant and spurious channel correlations which confuse graph neural network representations. The adversary is essentially the noise and variability inherent to clinical EEG acquisition that can mislead traditional graph construction methods. The model assumes no malicious attacker or adversarial manipulation but instead addresses robustness against signal noise and physiologically irrelevant connections.
Methodology — deep read
The study proposes a two-stage EEG graph structure learning framework for seizure detection. First, a Transformer-based edge predictor constructs an initial graph: each EEG channel's time series is encoded into an embedding vector using a Transformer encoder that models temporal dependencies. For each node pair (i, j), embeddings are concatenated and fed into a two-layer MLP with sigmoid output to predict the edge existence probability p_ij. Edges with probabilities above a threshold phi form the initial adjacency matrix. This initial graph aims to capture potential channel interactions but may include redundant/noisy edges.
Second, a large language model (LLM) refines the graph edges using contextual reasoning. For each candidate edge, textualized EEG features from GPT-4o describing channel label, anatomical location, and signal observations plus a comprehensive set of statistical features (mean, std, dominant freq, min/max, skewness, kurtosis, energy, zero-crossing rate, etc.) are concatenated for both nodes. These structured data form a natural language query prompt asking the LLM (tested across several models including GPT-4o, GPT-5, Llama, Gemini, Mistral) whether a meaningful connection exists. The LLM responds yes/no to retain or prune the edge. Applying this procedure iteratively for all candidate edges produces a refined graph adjacency matrix.
The refined graph is input to a graph representation learning model (GraphS4mer with internal graph learning disabled to isolate graph influence) that predicts seizure or non-seizure labels for each EEG segment. The entire system is trained and evaluated on the publicly available Temple University EEG Seizure Corpus (TUSZ) v1.5.2 with 19 channels, containing 5612 EEG recordings and 3050 seizure annotations.
Experiments compare multiple graph construction strategies on identical backbones through metrics (F1, accuracy, recall). They also conduct a systematic benchmark of multiple LLMs as structural judges using graph-level statistics (sparsity, Jensen-Shannon Divergence) for reasoning quality. Interpretability analyses visualize node importance evolution over seizure onset and propagation, and pairwise structural difference heatmaps quantify graph refinement stability across LLM models.
Training details such as epoch count, batch size, optimizer, or random seeds are not explicitly stated in the text. Code release and reproducibility statements are not mentioned, so it is unclear if models or prompts are publicly available. The LLM refinement relies on proprietary prompt designs combining textual and statistical EEG features in natural language format.
For a concrete example, EEG channel F3 embedding and channel T4 embedding from Transformer are scored by the MLP edge predictor; if above threshold, detailed textual description and statistics for F3 and T4 are submitted as prompt to GPT-5-mini, which outputs yes/no to retain the edge in the refined adjacency matrix. This refined graph benefits downstream seizure detection with higher F1 accuracy, showing that LLM reasoning can effectively filter spurious EEG connections.
Technical innovations
- Novel two-stage graph construction framework combining Transformer-based edge prediction with LLM-based edge refinement exploiting contextual and statistical reasoning.
- Integration of natural language textualization of EEG channel features plus quantitative statistical EEG descriptors as inputs for LLM graph refinement prompts.
- Systematic benchmarking of diverse general-purpose LLMs as graph structural judges in a clinical EEG seizure detection context, revealing scaling trends in reasoning quality.
- Use of LLM responses to iteratively prune initial data-driven graph connectivity, producing physiologically plausible and interpretable EEG brain networks.
- Application of LLM guidance to improve graph sparsity and downstream seizure classification accuracy on a large scale public clinical EEG dataset.
Datasets
- Temple University Hospital EEG Seizure Corpus (TUSZ) v1.5.2 — 5612 EEG recordings and 3050 seizure annotations — public clinical dataset
Baselines vs proposed
- Distance-based graph: F1 = 0.6508 vs GPT-5 + Transformer graph: F1 = 0.7907
- Self-correlation graph: Accuracy = 0.8453 vs GPT-5 + Transformer graph: Accuracy = 0.9315
- KNN-based graph: Recall = 0.7362 vs GPT-5 + Transformer graph: Recall = 0.8058
- Generative graph learner: F1 = 0.7351 vs GPT-5 + Transformer graph: F1 = 0.7907
- Mistral 7B + Transformer graph: F1 = 0.7458 vs GPT-5 + Transformer graph: F1 = 0.7907
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.28178.
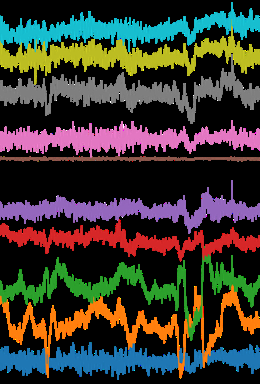
Fig 1: (Left) The proposed two-stage LLM-based clinical graph generation and refinement framework. (Right) The overall clinical EEG

Fig 2: Node feature importance distributions across different

Fig 3 (page 4).
Fig 4 (page 4).
Fig 5 (page 4).

Fig 6 (page 4).
Fig 7 (page 4).
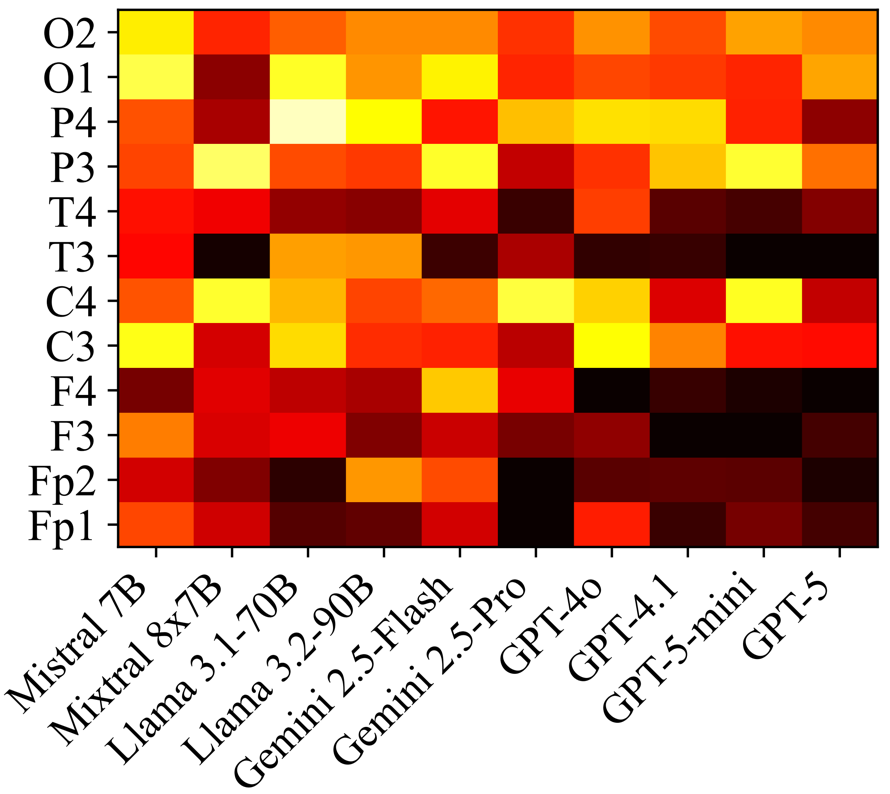
Fig 3: Edge Difference Heatmap. It shows the pairwise structural
Limitations
- No explicit adversarial robustness evaluation against malicious EEG signal perturbations or spoofing attacks.
- Lack of detailed training hyperparameters and description of Transformer and MLP optimization steps limits exact reproducibility.
- Proprietary prompt design for LLM queries is not fully disclosed; thus, prompting strategy details are unclear.
- Evaluation is restricted to the TUSZ dataset; no validation on other EEG seizure or brain activity datasets to test generalizability.
- No ablation study quantifying contribution of individual EEG statistical features vs textual descriptions in LLM refinement.
- Potential latency and computational cost of invoking large LLMs for real-time EEG analysis is not addressed.
Open questions / follow-ons
- How well does the LLM-based graph refinement generalize to other EEG datasets and seizure types beyond TUSZ?
- Can LLM refinement be made computationally efficient enough for real-time or resource-constrained clinical settings?
- What is the comparative impact of textualized EEG features vs purely statistical features in LLM edge decision making?
- How does the system perform under adversarial EEG noise or spoofing attacks designed to confuse the LLM or edge predictor?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this work illustrates a novel usage of large language models beyond text to enhance graph structure learning in noisy, high-dimensional biomedical signals. The core insight — that LLMs can act as context-aware filters to prune spurious and noisy edges from learned graphs, improving downstream task accuracy and interpretability — may inspire analogous strategies in bot-detection where graph representations of user interactions, device signals, or behavioral data are noisy or high-dimensional. Deploying LLMs as edge refiners could help in filtering irrelevant or adversarially noisy connections in interaction graphs, yielding more robust graph embeddings for classification.
However, practical challenges for CAPTCHA-scale real-time inference with large LLMs remain. The paradigm of combining data-driven initial graph construction with LLM-guided pruning could nonetheless lead to hybrid architectures for bot-detectors based on graph neural networks that require improved robustness against noise and obfuscation. The interpretability gains demonstrated may also help explainability demands in security applications. Overall, the paper provides a sophisticated example of cross-modal LLM utility in structured signal refinement that could influence future bot-defense graph learning pipelines.
Cite
@article{arxiv2604_28178,
title={ LLM as Clinical Graph Structure Refiner: Enhancing Representation Learning in EEG Seizure Diagnosis },
author={ Lincan Li and Zheng Chen and Yushun Dong },
journal={arXiv preprint arXiv:2604.28178},
year={ 2026 },
url={https://arxiv.org/abs/2604.28178}
}