
"It depends on where AI is used": Players' attitude patterns and evaluative logics toward different AI applications in digital games
Source: arXiv:2604.27812 · Published 2026-04-30 · By Ting-Chen Hsu, Jiangxu Lin, Wenran Chen, Fei Qin, Zheyuan Zhang
TL;DR
This paper asks a narrower question than “do players like AI in games?” It argues that player acceptance depends on the site of intervention: the same AI label is evaluated differently when it drives NPC dialogue, generates narrative, adjusts balance, recommends content, moderates communities, creates art, supports co-creation, or changes gameplay systems. The authors use an open-ended survey to surface the reasons players give for accepting, rejecting, or conditionally accepting AI across these eight contexts.
The core contribution is a cross-context thematic map. From 1,856 valid open-text responses collected from 310 questionnaires, the authors identify recurring reasons for support and resistance, then compress them into six higher-level evaluative logics: experiential enrichment, instrumental efficiency, system reliability, agency and control, authorship and compliance, and human oversight. The result is a context-sensitive model of AI acceptance in games: players tend to welcome AI when it improves immersion, novelty, personalization, or efficiency, but resist it when it threatens stability, autonomy, authenticity, fairness, ownership, or accountability.
Key findings
- The survey yielded 345 questionnaires and 2,760 open-ended responses; after removing 35 invalid questionnaires and 624 invalid individual responses, the final thematic analysis set was 1,856 valid responses from 310 questionnaires.
- Two researchers pre-coded 20% of the cleaned data and reached Cohen’s κ = 0.71, which the paper treats as substantial agreement before finalizing the codebook.
- Across the 1,856 valid responses, the team identified 2,562 coded segments, averaging 1.38 codes per response; 584 responses (31.47%) received more than one code.
- Players welcomed AI-driven NPCs mainly for immersion/presence, personalization/richness, freedom, and lower development cost, but resisted them for out-of-character behavior, lack of emotion, logical confusion, and low system stability.
- For dynamic balance adjustment, players supported AI when it reduced frustration, preserved challenge, or improved personalization, but opposed it when it disrupted rhythm, weakened autonomy, or reduced sense of achievement.
- For personalized matching/recommendation, support centered on efficiency and catering to diverse preferences, while opposition centered on monotony, inaccurate matching, impaired autonomy, and privacy concerns.
- For art asset generation, acceptance was tied to developer benefits, completion, and aesthetics, while rejection emphasized low innovation, weak authenticity/emotionality, copyright risk, limited controllability, and a perfunctory feeling.
- The paper identifies six evaluative logics that recur across contexts: experiential enrichment, instrumental efficiency, system reliability, agency and control, authorship and compliance, and human oversight.
Methodology — deep read
The study is framed as a context-sensitive attitude analysis rather than a performance benchmark or a system-building paper. The implicit threat model is not adversarial security; instead, the “problem” is understanding how players evaluate AI when it intervenes in different parts of the game ecosystem. The authors assume respondents are ordinary game players with subjective experiences and preferences, and they are interested in reasons for acceptance, rejection, and conditional acceptance rather than trying to infer causal effects or population prevalence.
Data came from an open-ended questionnaire distributed to players. The paper reports 345 questionnaires collected, producing about 2,760 open-text responses. After preprocessing, 35 invalid questionnaires were removed because of anomalous completion times or blank open-ended sections, leaving 310 questionnaires and 2,480 responses for cleaning. A further 624 individual responses were discarded as invalid, producing the final analytic corpus of 1,856 valid open-text responses. The final sample was aged 17–34 years (mean 21.79), with 116 males, 187 females, and 7 non-binary participants. The questionnaire also captured nickname, age, gender, academic background, and weekly gaming time. The eight prompts asked about AI used for intelligent NPCs, emergent narrative/task generation, dynamic balance adjustment, personalized matching/recommendation, content review and community governance, art asset generation, AI-supported co-creation gameplay, and dynamic evolution/emergence of gameplay elements.
The analysis uses codebook-based thematic analysis. The authors first took a random 20% sample of the cleaned open-text responses and had two researchers independently pre-code it using a bottom-up approach. This pre-coding phase was used to discover the recurring reasons players gave across the eight contexts. Inter-rater reliability was measured with Cohen’s kappa and reached κ = 0.71. Based on the pre-coding and discussion, the team built a formal codebook with code names, definitions, and examples. The same two researchers then coded the remaining 80% in parallel using the finalized codebook. A key methodological choice is that coding was attitude-neutral: supportive, neutral, and critical rationales were all captured in the same thematic framework rather than separated into sentiment buckets. Because a single response could express multiple reasons, multiple codes could be attached to one response; disagreements were escalated to a third senior researcher for final resolution.
The analytical pipeline had three steps. First, they built within-context theme profiles to identify recurring reasons for acceptance, rejection, or conditional acceptance for each AI application. Second, they compared those themes across contexts using a context-by-theme matrix; descriptive counts were used only as supplementary indicators, not as inferential statistics. Third, they performed a second-cycle interpretive synthesis to abstract the concrete themes into six higher-level evaluative logics. One concrete example: for AI-generated art assets, the paper distinguishes responses that see AI as a useful production aid (developer benefit, higher completion, aesthetics) from responses that reject it on authorship, copyright, authenticity, emotionality, controllability, or “perfunctory” grounds. That distinction is then linked to the broader logics of instrumental efficiency, authorship/compliance, and human oversight.
Evaluation is qualitative rather than predictive. There are no train/test splits, no classifiers, and no hypothesis tests over population effects. The main reliability check is the 20% double-coding with κ = 0.71. The paper compares contexts through qualitative synthesis and frequency counts, but explicitly says it does not make statistical claims about prevalence or causal relationships. Reproducibility is partial: the questionnaire and codebook are included in appendices, but the paper does not mention code release, a public dataset, frozen annotations, or an external replication package. The main empirical limitation is therefore the usual one for thematic survey studies: rich contextual interpretation, but limited ability to generalize beyond the sample or quantify effect sizes.
Technical innovations
- A cross-context survey design that treats AI in games as multiple intervention sites rather than a single undifferentiated technology.
- An attitude-neutral codebook for open-ended responses that allows supportive, neutral, and opposing rationales to coexist in the same thematic framework.
- A six-logic synthesis layer that abstracts concrete reasons into higher-order evaluative logics: experiential enrichment, instrumental efficiency, system reliability, agency and control, authorship and compliance, and human oversight.
- A context-by-theme comparison across eight AI application scenarios, showing that the same value concerns activate differently depending on where AI is inserted into the game system.
Datasets
- Open-ended survey corpus — 345 questionnaires / ~2,760 responses collected; 310 questionnaires / 1,856 valid open-text responses analyzed — author-collected survey
- Participant demographics — 310 respondents, ages 17–34 (M=21.79), 116 male / 187 female / 7 non-binary — author-collected survey
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.27812.
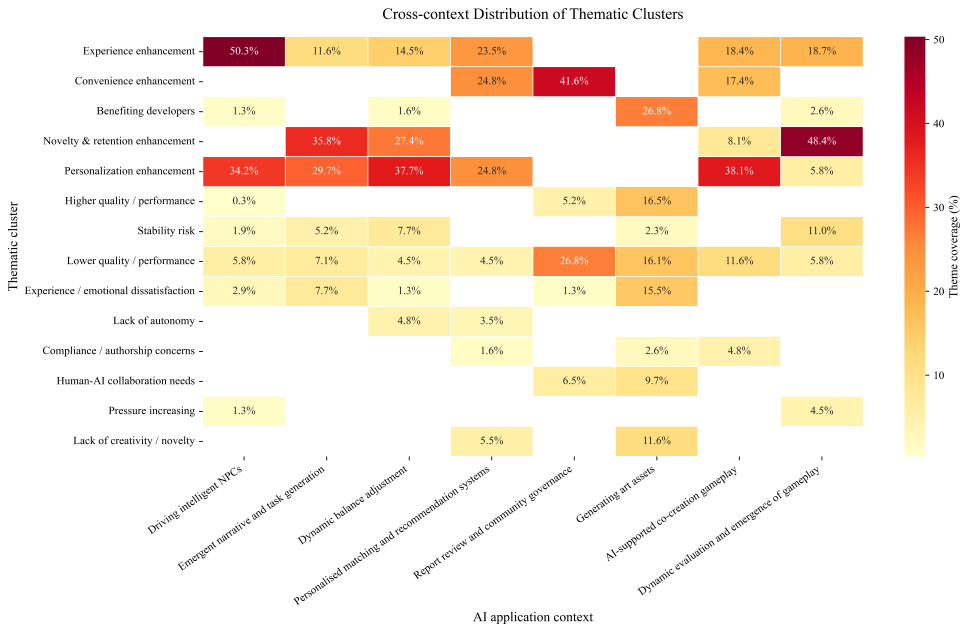
Fig 1: Distribution of thematic clusters across AI application contexts
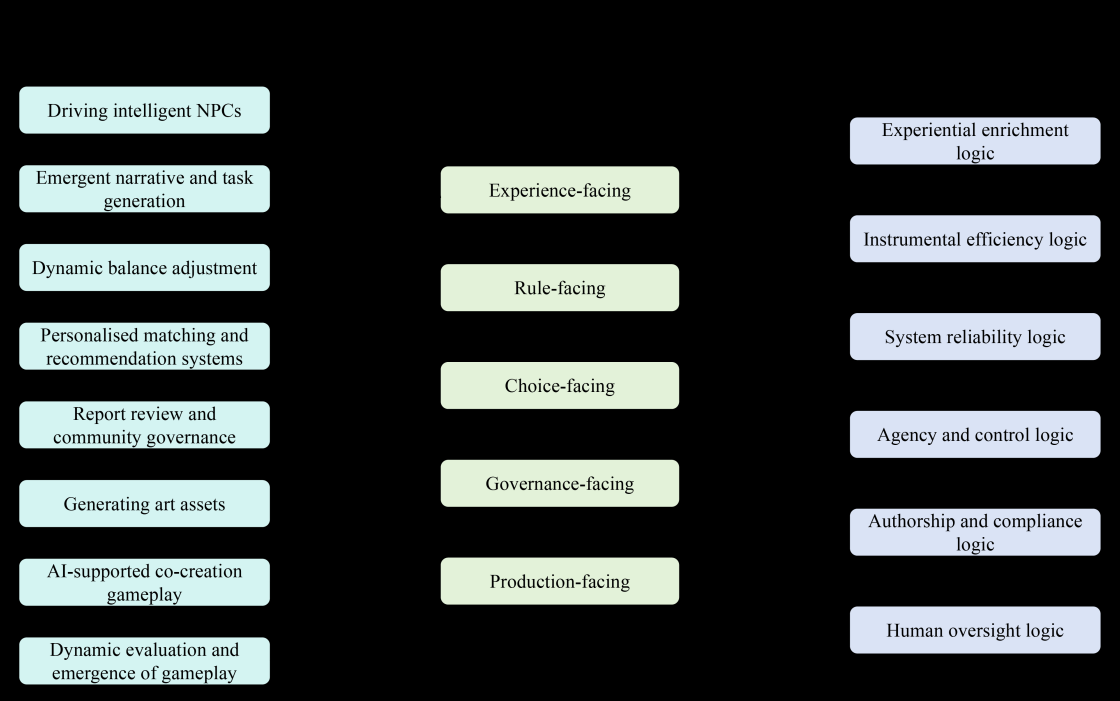
Fig 2: integrates these findings by linking the eight application contexts to broader sites of
Limitations
- Open-ended responses are broad but shallow; the authors note they could not probe follow-up questions or resolve ambiguous answers in depth.
- The coding framework intentionally merges supportive, neutral, and opposing rationales, so polarity-specific conclusions remain underexplored.
- The paper relies on descriptive counts and thematic comparison, not statistical prevalence estimates or causal inference.
- The sample is relatively small and narrow for generalization: 310 respondents, ages 17–34, and no evidence of cross-cultural validation.
- No external replication package, frozen annotation set, or code release is mentioned in the provided text.
- The study does not test distribution shift across genres, regions, or different player subpopulations.
Open questions / follow-ons
- Do the six evaluative logics hold across genres with very different player expectations, such as competitive shooters, social sandboxes, and narrative RPGs?
- How do demographics, skill level, genre preference, and prior exposure to generative AI shift the balance between experiential enrichment, agency loss, and authorship concerns?
- Would the same pattern appear in behavioral data or scenario-based experiments, or is it specific to open-ended self-report?
- Can the proposed logics predict when players will tolerate AI assistance versus demand human oversight in governance, moderation, and content creation?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main takeaway is that “AI acceptance” is highly context-dependent and tightly coupled to perceived agency, reliability, and oversight. That maps well onto human-interaction design in verification flows: users are more tolerant of automation when it clearly reduces effort without taking away control, but become skeptical when it feels opaque, unfair, or overreaching. In practice, this suggests that anti-bot systems should minimize the impression of arbitrary intervention, preserve user autonomy where possible, and be especially careful in contexts where errors look like judgment failures rather than simple friction.
The paper also provides a useful language for thinking about user backlash. In a CAPTCHA or bot-detection setting, players/users may accept automation as an instrumental efficiency tool, but resistance will rise if the system appears unstable, blocks legitimate action, or lacks human recourse. The “human oversight” logic is especially relevant: if an automated decision can harm access, users need a believable path to review, appeal, or alternative verification. That is less about making the system feel friendly and more about aligning intervention with trust, fairness, and accountability.
Cite
@article{arxiv2604_27812,
title={ "It depends on where AI is used": Players' attitude patterns and evaluative logics toward different AI applications in digital games },
author={ Ting-Chen Hsu and Jiangxu Lin and Wenran Chen and Fei Qin and Zheyuan Zhang },
journal={arXiv preprint arXiv:2604.27812},
year={ 2026 },
url={https://arxiv.org/abs/2604.27812}
}