
I'm Fine, But My Voice Isn't: Cross-Modal Affective Dissonance Detection for Reflective Journaling
Source: arXiv:2604.27517 · Published 2026-04-30 · By Sumin Lee
TL;DR
This paper tackles a specific failure mode in reflective journaling: people often write text that does not match how they sound. The author formalizes that mismatch as Cross-Modal Affective Dissonance Detection (CADD), a three-way classification problem with directional classes: Masking (text positive, audio negative), Coping (text negative, audio positive), and Congruent. The key idea is not to predict generic emotion, but to detect disagreement between transcript sentiment and vocal affect as a potential signal of emotional self-presentation in journaling.
The paper’s main technical contribution is DACM, a dual-encoder multimodal model built on frozen XLM-RoBERTa-base text features and WavLM-base-plus audio features. Its central novelty is asymmetric cross-modal attention: one modality’s pooled vector queries the other modality’s full sequence, avoiding the scalar-softmax degeneracy that makes pooled-to-pooled attention effectively non-trainable. On a synthetic TTS dataset called CADD-Journal (1,800 samples), DACM reaches macro-F1 0.711 ± 0.025, with the largest gain coming from the asymmetric attention module itself. However, zero-shot transfer to natural corpora collapses sharply, showing that the controlled TTS setting is learnable but far from solving real-world in-the-wild dissonance detection.
Key findings
- CADD-Journal contains 1,800 samples total, balanced across 3 classes (600 each); the split is 1,260 train / 270 val / 270 test.
- Text-only under the shared-sentence-pool design collapses to predicting Congruent, giving macro-F1 0.167±0.000, which is below stratified random guessing at 0.333 for a 3-class balanced split.
- DACM achieves macro-F1 0.711±0.025 on CADD-Journal; the best-seed per-class F1s are 0.839 (Masking), 0.845 (Coping), and 0.522 (Congruent).
- Replacing pooled fusion with asymmetric cross-modal attention yields the dominant ablation gain: DACM-noAttn macro-F1 0.469±0.021 vs DACM 0.711±0.025, a +0.242 increase.
- Keeping asymmetric attention but removing the DIM gives DACM-noDIM macro-F1 0.678±0.007, so the DIM adds +0.033 on top of attention-contextualized features.
- DACM-Base with simple pooled fusion underperforms AudioOnly: 0.441±0.014 vs 0.448±0.023, supporting the claim that naive fusion can suppress acoustic signal.
- Leave-one-voice-out evaluation remains reasonably strong: mean macro-F1 0.655, with per-voice scores 0.645 (Jarnathan), 0.689 (Juniper), and 0.632 (Eve).
- Zero-shot transfer is poor on naturalistic corpora: CMU-MOSEI F1 0.512 on a 2-class silver-label setting (random 0.500), IEMOCAP F1 0.362 (3-class silver-label, random 0.333), and CH-SIMS F1 0.335 (3-class gold labels, random 0.333).
Threat model
The adversary is not a malicious attacker but the mismatch between written self-presentation and vocal affect in reflective journaling. The model assumes the user may consciously or unconsciously alter the textual narrative while the speech signal still carries useful affective information. It does not assume access to private latent state labels, and for the real-world corpora it cannot rely on gold dissonance annotations; the paper also explicitly excludes clinical diagnosis and does not claim robust inference under adversarial manipulation of both text and audio.
Methodology — deep read
The threat model is not an adversarial security setting in the usual sense; it is a behavioral inference setting. The user-facing task asks whether a transcript and its paired speech are congruent or emotionally dissonant, and the paper assumes the adversary is essentially the mismatch itself: people who intentionally or unintentionally sanitize written journal entries while their voice still leaks affect. The author explicitly frames Gross’s process model of emotion regulation as an interpretive lens, not as a claim that the synthetic samples instantiate real suppression or reappraisal. The model is intended for voluntary self-reflection in non-clinical populations, and the paper warns against treating outputs as diagnostic verdicts.
The dataset, CADD-Journal, is synthetic and tightly controlled. It has 1,800 total samples built from 100 seed sentences shared across all acoustic conditions, which is the crucial design choice: because sentence content is reused across classes, text alone should not carry class information. Audio is rendered with ElevenLabs Eleven v3 using explicit emotion tags. Negative tags include sad, angry, annoyed, and appalled; positive tags include happy, excited, cheerful, and calm. The paper says each class has 600 samples total, with 420 train / 90 val / 90 test per class, for a static 70/15/15 split stratified at the sentence_id level. The authors also use three synthetic voices (Jarnathan, Juniper, Eve). This design is meant to isolate acoustic cues from lexical content and make any gain over text-only attributable to cross-modal reasoning.
DACM is a dual-encoder architecture. Text is encoded by frozen XLM-RoBERTa-base, producing a pooled CLS vector h_t and a token sequence H_t; audio is encoded by frozen WavLM-base-plus, producing a masked-mean vector h_a and a frame sequence H_a. Before fusion, the paper uses Weighted Layer Pooling over all 12 hidden layers for each encoder. The key architectural contribution is asymmetric cross-modal attention: rather than attending pooled vector to pooled vector, which would produce a scalar score and make softmax collapse to 1 (thus killing gradients for W_Q and W_K), the model uses one modality’s pooled vector as query and the opposing modality’s full sequence as keys/values. Concretely, h_t→a = MHA(Q=h_t, K=V=H_a) and h_a→t = MHA(Q=h_a, K=V=H_t). This preserves a non-trivial attention tensor and allows the attention weights to vary across time steps. On top of that, the Dissonance Interaction Module (DIM) computes four features from the contextualized cross-modal vectors: a gated difference, a Hadamard product, cosine similarity, and a stop-gradient unimodal disagreement vector d = sg(ŷ_t) − sg(ŷ_a), where ŷ_t and ŷ_a are unimodal logits. These are concatenated into a 1,540-dimensional vector and fed to a two-layer MLP with hidden size 512 and dropout 0.4, plus an agreement head and a mismatch score S = (1 − cos)/2.
Training uses a composite loss: label-smoothed cross-entropy (ε=0.1) plus 0.3× a bipolar cosine margin loss, 0.2× text auxiliary loss, 0.2× audio auxiliary loss, and 0.1× agreement loss. Hyperparameters reported are AdamW with lr 5e-4, batch size 16, patience 7, and gradient clipping at 1.0. The encoders are frozen across all conditions so that ablations differ in fusion logic rather than in pretrained backbone capacity. Results are reported over three random seeds {42, 123, 456}, and the paper notes that standard deviations are non-trivial, especially for smaller deltas like +0.033 from the DIM. One concrete path through the model: a sentence like a neutral journaling transcript paired with acoustically negative speech is encoded by the frozen encoders, contextualized through asymmetric attention so each modality selectively queries the other, then DIM combines disagreement features to classify the pair as Masking, while also producing a scalar mismatch score for the UI.
Evaluation is intentionally layered. First, the paper compares text-only, audio-only, pooled fusion, pooled fusion with DIM, attention-based fusion without DIM, and the full DACM model to isolate the source of gains. The strongest ablation claim is that asymmetric attention is the main driver of performance, while DIM is secondary and mainly useful once cross-modal context exists. Second, the paper reports leave-one-voice-out generalization across the three synthetic voices to test whether the model memorizes speaker identity. Third, it performs zero-shot cross-corpus transfer to three naturalistic datasets: CMU-MOSEI, IEMOCAP, and CH-SIMS. For these corpora, the paper constructs silver labels for CMU-MOSEI and IEMOCAP via SiEBERT text sentiment plus an emotion-to-valence mapping for audio, while CH-SIMS uses gold labels mapped to the CADD taxonomy. The key result is that the model’s in-domain performance does not survive the transition to natural speech. The paper does not report statistical significance tests beyond mean ± std across seeds, and reproducibility is partial: code is released on GitHub, but the CADD-Journal data itself is synthetic and the natural-corpus labels for transfer are partly silver, not gold.
Technical innovations
- CADD reframes lexical-acoustic mismatch as a directional three-way label space (Masking, Coping, Congruent) rather than a generic multimodal sentiment alignment problem.
- CADD-Journal uses a shared-sentence-pool TTS design so transcript content is constant across conditions, forcing any classifier to exploit acoustic information rather than lexical shortcuts.
- DACM introduces asymmetric cross-modal attention with pooled queries and full-sequence keys/values to avoid the scalar-softmax degeneracy of pooled-to-pooled fusion.
- The DIM adds explicit mismatch features, including a stop-gradient unimodal-disagreement vector, to separate classification from interpretable dissonance scoring.
- The paper quantifies a previously unmeasured domain gap between controlled synthetic dissonance and naturalistic speech via zero-shot transfer to CMU-MOSEI, IEMOCAP, and CH-SIMS.
Datasets
- CADD-Journal — 1,800 samples — synthetic TTS via ElevenLabs Eleven v3; 100 shared seed sentences, 3 voices
- CMU-MOSEI — 572 samples — public benchmark; silver labels derived from SiEBERT + emotion-to-valence mapping
- IEMOCAP — 5,674 samples — public benchmark; silver labels derived from SiEBERT + emotion-to-valence mapping
- CH-SIMS — 4,404 samples — public benchmark; gold labels mapped to CADD taxonomy
Baselines vs proposed
- TextOnly: macro-F1 = 0.167±0.000 vs proposed DACM = 0.711±0.025
- AudioOnly: macro-F1 = 0.448±0.023 vs proposed DACM = 0.711±0.025
- DACM-Base: macro-F1 = 0.441±0.014 vs proposed DACM = 0.711±0.025
- DACM-noAttn: macro-F1 = 0.469±0.021 vs proposed DACM = 0.711±0.025
- DACM-noDIM: macro-F1 = 0.678±0.007 vs proposed DACM = 0.711±0.025
- CADD-Journal zero-shot on CMU-MOSEI: F1 = 0.512 vs random = 0.500
- CADD-Journal zero-shot on IEMOCAP: F1 = 0.362 vs random = 0.333
- CADD-Journal zero-shot on CH-SIMS: F1 = 0.335 vs random = 0.333
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.27517.

Fig 1: illustrates four sequential stages: (1) unimodal encoding

Fig 2: ReflectJournal: (A/B) recording interface, (C) jour-

Fig 3 (page 4).
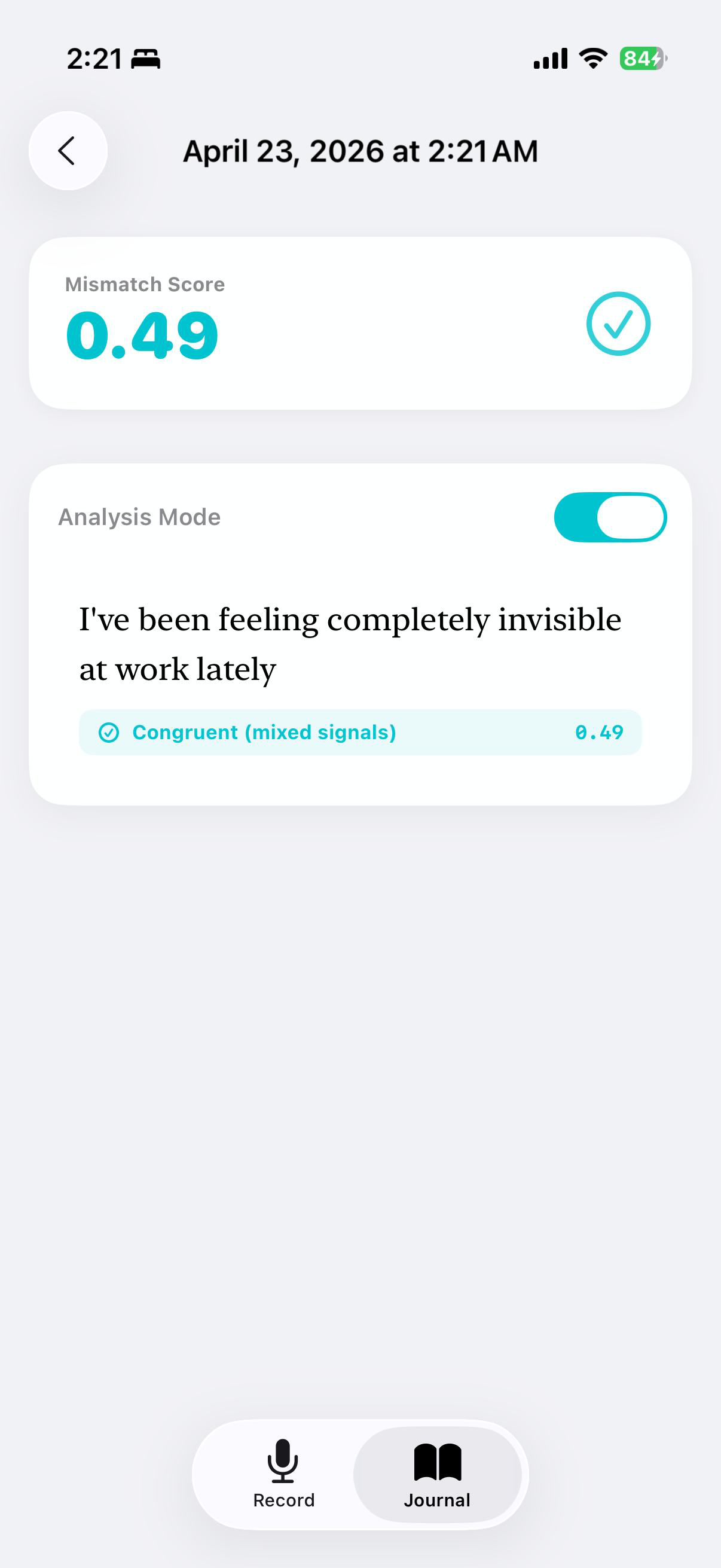
Fig 4 (page 4).
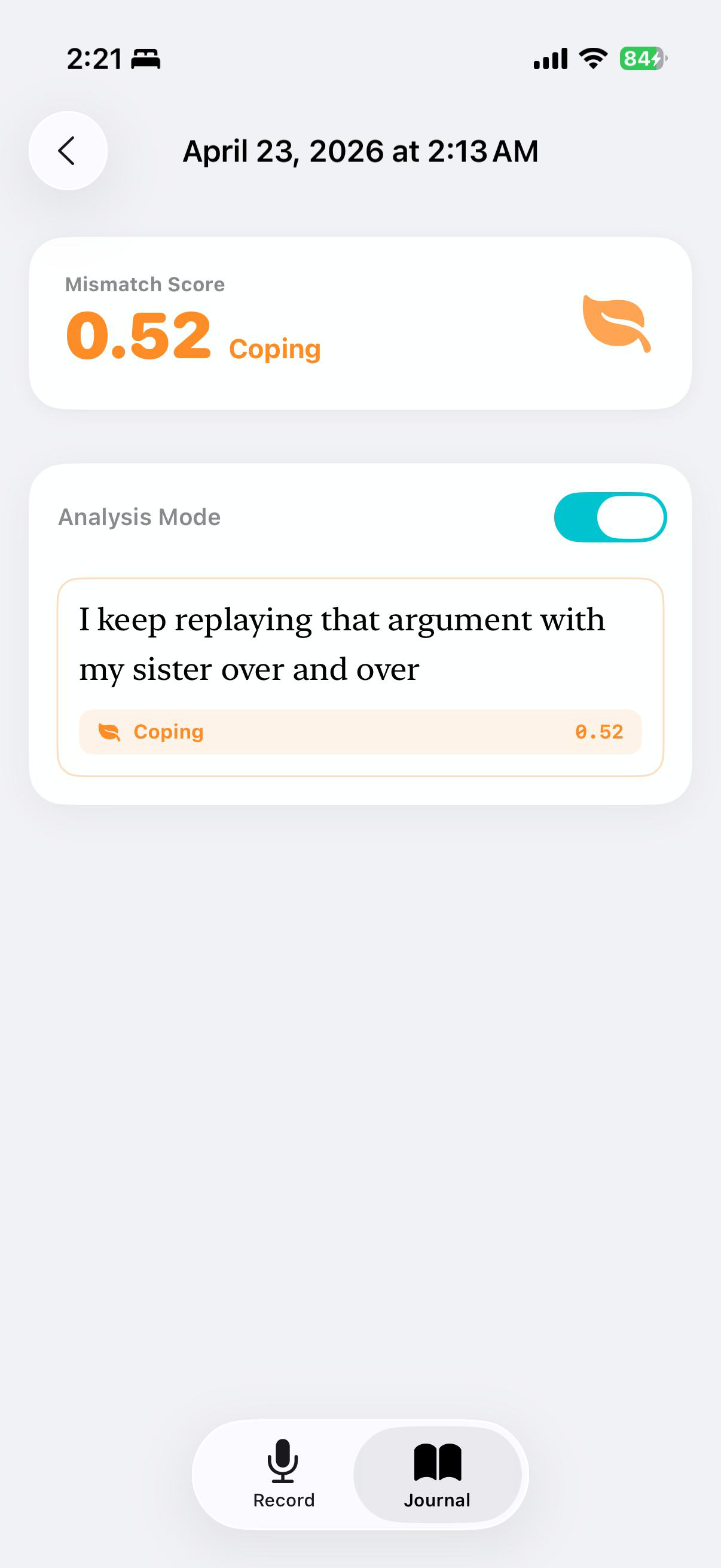
Fig 5 (page 4).
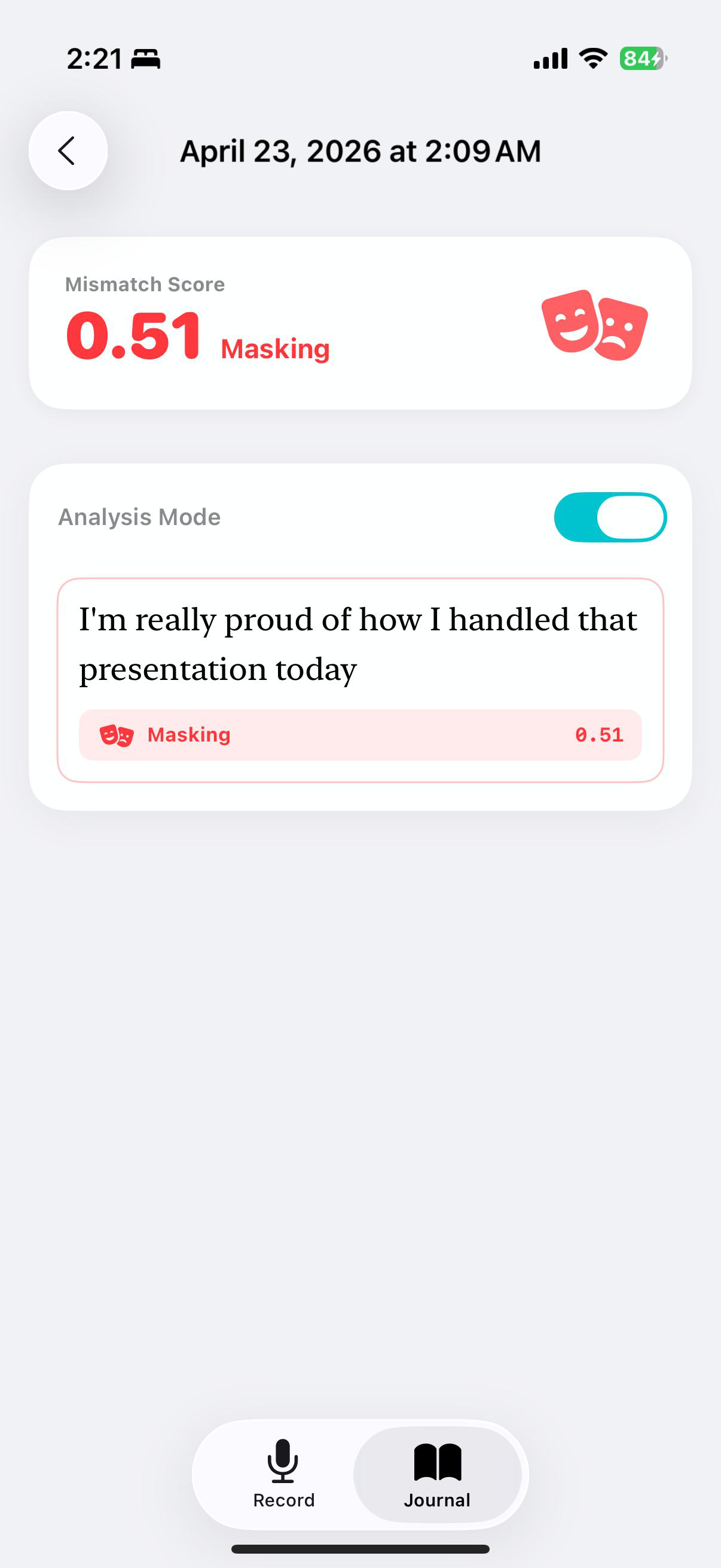
Fig 6 (page 4).
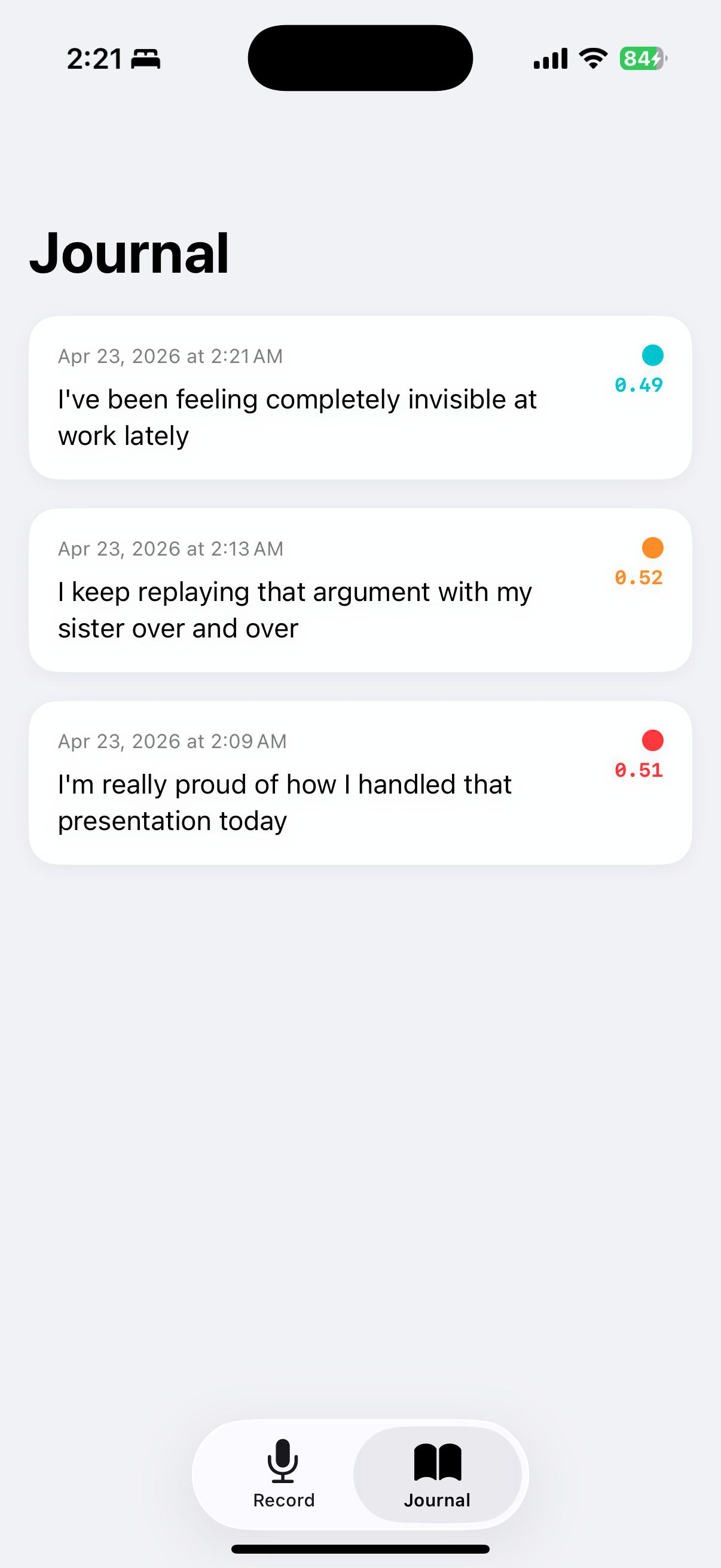
Fig 7 (page 4).
Fig 8 (page 4).
Limitations
- CADD-Journal is synthetic TTS, so it tests acoustic-lexical mismatch but not genuine emotion regulation; the Gross-model labels are interpretive anchors, not psychological ground truth.
- Cross-corpus evaluation uses silver labels for CMU-MOSEI and IEMOCAP, so part of the apparent domain gap may be label noise rather than model failure.
- The dataset uses only three synthetic English voices, so demographic and language diversity are largely untested.
- ReflectJournal is a design probe, not a user study; there is no evidence yet that the mismatch score or prompt threshold improves reflection or avoids harm.
- The main ablations are averaged over only three seeds, and the paper itself notes that small differences such as +0.033 for the DIM are suggestive rather than definitive.
- No calibrated decision threshold, clinical validation, or cross-cultural robustness test is reported for the app-level mismatch score.
Open questions / follow-ons
- Can the CADD taxonomy be re-annotated on real self-reflective speech with independent text-sentiment and acoustic-valence labels that are not derived from proxy estimators?
- Would a jointly trained or partially fine-tuned speech-text encoder close more of the TTS-to-real gap, or does the gap mainly reflect label/task mismatch rather than representation limits?
- How stable is the mismatch score S under speaker identity, dialect, age, and language variation, especially outside English?
- What kind of user study would validate whether surfacing Masking/Coping prompts actually improves reflection without causing distress?
Why it matters for bot defense
For bot-defense practitioners, the main takeaway is methodological rather than directly deployable: if a signal looks strong in controlled synthetic data but collapses on naturalistic data, the likely issue is domain mismatch and label construction, not just model architecture. That is a familiar warning for CAPTCHA and abuse-detection systems, where proxy datasets can overstate real-world separability.
The architectural lesson is that naive multimodal fusion can suppress the rare signal you care about. In a defense setting, if you have a strong and a weak modality, pooled fusion may wash out the weak-but-diagnostic channel; asymmetric attention or other modality-specific querying can preserve it. The evaluation lesson is also relevant: the paper’s zero-shot cross-corpus test is a good template for checking whether a detector learned a robust behavioral pattern or just a dataset artifact. The app deployment note is also a reminder that any user-facing detector needs a carefully calibrated threshold and a human-centered workflow, not just a classifier score.
Cite
@article{arxiv2604_27517,
title={ I'm Fine, But My Voice Isn't: Cross-Modal Affective Dissonance Detection for Reflective Journaling },
author={ Sumin Lee },
journal={arXiv preprint arXiv:2604.27517},
year={ 2026 },
url={https://arxiv.org/abs/2604.27517}
}