
Finding the one: identifying the host of compact binary mergers
Source: arXiv:2604.28132 · Published 2026-04-30 · By Alberto Salvarese, Hsin-Yu Chen, Daniel E. Holz
TL;DR
This paper tackles a practical bottleneck in gravitational-wave astronomy: how to narrow down the host galaxy of a compact binary merger when no electromagnetic counterpart is available and the localization volume still contains many galaxies. The authors’ core idea is deliberately simple: instead of trying to score every galaxy equally, they focus on the most luminous galaxies inside the 3D LVK localization volume, because luminosity is used as a proxy for stellar mass or star-formation rate and therefore for merger probability. They then check which of those bright galaxies are consistent with the GW distance through a redshift–distance (H0) consistency test.
The result is a small candidate set for three of the best-localized events available at the time: S250207bg, GW190814, and S250830bp. Under their selection rule of the brightest 1% of galaxies in each event volume and a broad H0 prior, they identify 1, 1, and 4 candidate galaxies, respectively. Their mock-catalog test suggests that 29.4%, 32.2%, and 36.4% of those candidates could arise by random association, so the authors present them as plausible follow-up targets rather than secure hosts. They also show that if the candidates are indeed hosts or cluster members of the hosts, the implied H0 posteriors are broadly consistent with current measurements, and they argue the method should improve substantially as LVK localization volumes shrink in future observing runs.
Key findings
- Among the five best-localized O3/O4 events in Table 1, only S250207bg, GW190814, and S250830bp had approximately spatially uniform galaxy distributions in GLADE+; S240925n and S241011k were discarded because their sky areas overlap the Galactic plane and catalog incompleteness/extinction distort the observed galaxy density.
- Using the brightest 1% of galaxies above a band-dependent luminosity threshold of roughly L_th ~ 2–16 × 10^10 h^-2 L_sun, the paper retains Ng = 2, 2, and 3 galaxies for S250207bg, GW190814, and S250830bp, respectively, from the GLADE+ catalog.
- The H0 consistency filter yields 1 candidate for S250207bg, 1 candidate for GW190814, and 4 candidates for S250830bp; these are listed in Table 2 with redshift, coordinates, band, magnitude, and inferred H0.
- The probability that at least one identified galaxy is a random association is 29.4% for S250207bg, 32.2% for GW190814, and 36.4% for S250830bp, estimated from 500 mock-catalog realizations.
- For S250207bg and GW190814, the single identified galaxies have H0 medians of 82.29 and 83.05 km s^-1 Mpc^-1 under the uniform prior, while S250830bp’s four candidates give 63.62 km s^-1 Mpc^-1 for the lowest-median candidate and a combined-event posterior centered at 79.27 km s^-1 Mpc^-1 for all three events (Table 3).
- When the authors repeat the analysis after removing confirmed AGNs, the S250207bg candidate disappears, but GW190814 and S250830bp retain the same non-AGN candidates, which the authors interpret as supporting plausibility rather than ruling them out.
- A GW170817 sanity check is used to show the method can recover a galaxy in the same cluster as the true host: with Ng increased to 4 (since the nominal Ng<1 for its tiny localization volume), NGC 4968 is identified as H0-consistent and is in the same cluster as NGC 4993.
Threat model
The implicit adversary is the uncertainty and incompleteness of the localization problem: a GW event is localized to a 3D volume that contains many galaxies, the catalog is incomplete especially near the Galactic plane, and the true host may be electromagnetically dark. The method assumes the LVK sky map and distance posterior are trustworthy, the galaxy catalog redshifts are usable, and that a true host is more likely to be among the most luminous galaxies or a galaxy in the same cluster. It does not attempt to defend against a maliciously manipulated catalog or adversarial GW posteriors; it is a statistical host-ranking method under imperfect observational coverage.
Methodology — deep read
Threat model and assumptions: this is not a bot-defense or ML adversarial paper, but it does have a clear inference problem. The “adversary,” if you want to use that language, is the combinatorial ambiguity of a GW localization volume plus catalog incompleteness. The authors assume the LVK sky map and distance posterior are correct, that the GLADE+ galaxy catalog provides sky position and redshift information for the relevant galaxies, and that galaxy luminosity is a useful proxy for merger-host probability. They do not model an intentional attacker; instead they are trying to reduce false host associations under incomplete information. A key assumption is that any true host is likely to be among the brightest galaxies in the localization volume, or at least in the same cluster as one of those galaxies.
Data and sample construction: the sky/localization data come from LVK GraceDB sky maps for the five best-localized O3/O4 events in Table 1. The galaxy data come from GLADE+ (about 22.5 million galaxies), which provides right ascension, declination, redshift, and multi-band photometry. They compute each GW event’s comoving localization volume by reprojecting the sky map to a common HEALPix grid with nside=1024 (equal-area pixels of 3.28×10^-3 deg^2), then taking the 90% sky credible region and the symmetric 90% credible interval of the line-of-sight luminosity-distance posterior. That yields volumes of 18.1, 23.9, 33.0, 76.9, and 99.7 ×10^3 Mpc^3 for S250207bg, GW190814, S250830bp, S240925n, and S241011k, respectively. They then discard S240925n and S241011k because the spatial distribution of galaxies in those volumes is heavily biased by the Galactic plane. For the retained events, they define a galaxy subset by requiring galaxies to lie both inside the sky credible region and inside a redshift interval derived from the GW distance bounds and a broad H0 range [50,140] km s^-1 Mpc^-1. They explicitly state that the selection is done in several photometric bands (B, BJ, J, K, H, W1, W2), with band-dependent luminosity thresholds chosen so the mean number density is 10^-3 Mpc^-3 and then keep the top fg=1% brightest galaxies, which determines Ng in each event volume.
Architecture / algorithm: the method is a Bayesian ranking/filtering pipeline rather than a learned model. First, for each GW event and each line of sight, they extract the conditional luminosity-distance posterior from the skymap parameterization used by ligo.skymap: p(DL|D, αi, δi)=DL^2 ni_DL N(μi_DL, σi_DL). They convert the distance posterior to a comoving-distance interval using a fiducial flat ΛCDM cosmology with H0=67.74 km s^-1 Mpc^-1 and Ωm=0.3075. Next, for every galaxy in GLADE+ inside the 90% sky region, they translate the GW distance interval into a redshift interval [z^-i, z^+i] using a conservative H0 range [50,140] km s^-1 Mpc^-1, and keep galaxies whose measured redshift falls in that interval. After that, they rank/select the brightest galaxies in each band via absolute magnitude; the paper notes that changing the fiducial H0 shifts absolute magnitudes but not the relative ranking, so the selection is stable. Finally, for each candidate galaxy they compute an H0 posterior using the dark-siren formalism: p(H0|D) ∝ π(H0)L(D|H0), where the likelihood marginalizes over distance, sky position, and redshift, includes a selection factor β(H0), and uses the galaxy catalog as a discrete redshift prior pCBC(z|{z}i). For the one-galaxy case this collapses to a single LOS integral, Eq. C12.
Training regime and computation: there is no training in the ML sense. The important tunable choices are the bright-galaxy fraction fg=1%, the assumed comoving number density ρg=10^-3 Mpc^-3, the H0 consistency window (median in [50,90], central 68% spanning 60–80 km s^-1 Mpc^-1), and the mock-catalog procedure used to estimate random-association probability. For that null test, they generate a uniform-in-comoving-volume mock galaxy catalog, preserve the spectroscopic/photometric redshift mixture observed in GLADE+ for each event, assign σz=0.001 for spectroscopic redshifts and σz=0.013(1+z) capped at 0.015 for photometric ones, then draw Ng galaxies at random within the localization volume 500 times. The paper does not report a stochastic seed strategy because there is no learned training loop, and the only repeated randomization is the 500-trial association test.
Evaluation protocol and a concrete example: the main evaluation is event-by-event host candidate identification plus H0-consistency checking, followed by a random-association estimate and a sanity check with GW170817. For S250207bg, the pipeline starts with the 90% sky region and distance interval from GraceDB, projects to redshift bounds, intersects those with GLADE+, selects the brightest subset, and computes the H0 posterior for each surviving galaxy. Table 2 reports one candidate galaxy (10375180+3348504 in 2MASS, z=0.0501, BJ=-21.31) with H0=82.29^{+12.6}_{-9.66} km s^-1 Mpc^-1 and random-association probability 29.4%. They then repeat the analysis after removing confirmed AGNs using Stern et al. and Assef et al. criteria plus SIMBAD; the S250207bg candidate is classified as an AGN and disappears, leaving no alternative H0-consistent galaxy, which the authors interpret as suggestive rather than conclusive. Results are summarized in Fig. 1 (3D galaxy distributions with identified candidates), Fig. 2 (H0 posteriors, with a uniform prior and a GW170817-informed prior), Table 2 (candidate properties), and Table 3 (posterior medians and 68% intervals). Reproducibility is moderate: the authors specify software (numpy, matplotlib, astropy, healpy, ligo.skymap) and the catalogs / sky-map sources, but this is not presented as a fully packaged code release with frozen data products in the text provided.
Technical innovations
- They turn bright-galaxy targeting into a host-identification filter for GW events, using luminosity as a proxy for host probability rather than treating all catalog galaxies equally.
- They derive an H0-consistency criterion from each candidate galaxy’s redshift and the LVK distance posterior, using it as a physically motivated ranking test instead of a purely positional match.
- They estimate false-association probability with a Monte Carlo mock catalog and explicitly retain the candidate if it survives both the bright-galaxy selection and the broad H0 consistency window.
- They show a GW170817 cluster-member recovery test to validate that the approach can find a galaxy associated with the host environment even when the true host itself is not selected.
- They incorporate AGN vetting as a post-selection sanity check, because AGN luminosity can contaminate a brightest-galaxies heuristic.
Datasets
- GLADE+ — approximately 22.5 million galaxies — public catalog
- GraceDB / LVK sky maps for S250207bg, GW190814, S250830bp, S240925n, S241011k, and GW170817 — event-specific localization posteriors — public LVK data products
Baselines vs proposed
- Uniform random galaxy selection (mock catalog): at least one random association = 29.4% / 32.2% / 36.4% for S250207bg / GW190814 / S250830bp vs proposed bright-galaxy + H0 filter: 1 / 1 / 4 candidate galaxies
- GW170817 host check: nominal Ng < 1 from the volume-based rule vs proposed Ng = 4 override yielded one H0-consistent galaxy, NGC 4968, in the same cluster as NGC 4993
- Uniform H0 prior: S250207bg median H0 = 82.29 km s^-1 Mpc^-1, GW190814 = 83.04, S250830bp = 63.62, combined all events = 79.27; GW170817-informed prior shifts these to 76.31, 77.43, 70.64, and 76.65, respectively
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.28132.

Fig 1 (page 1).
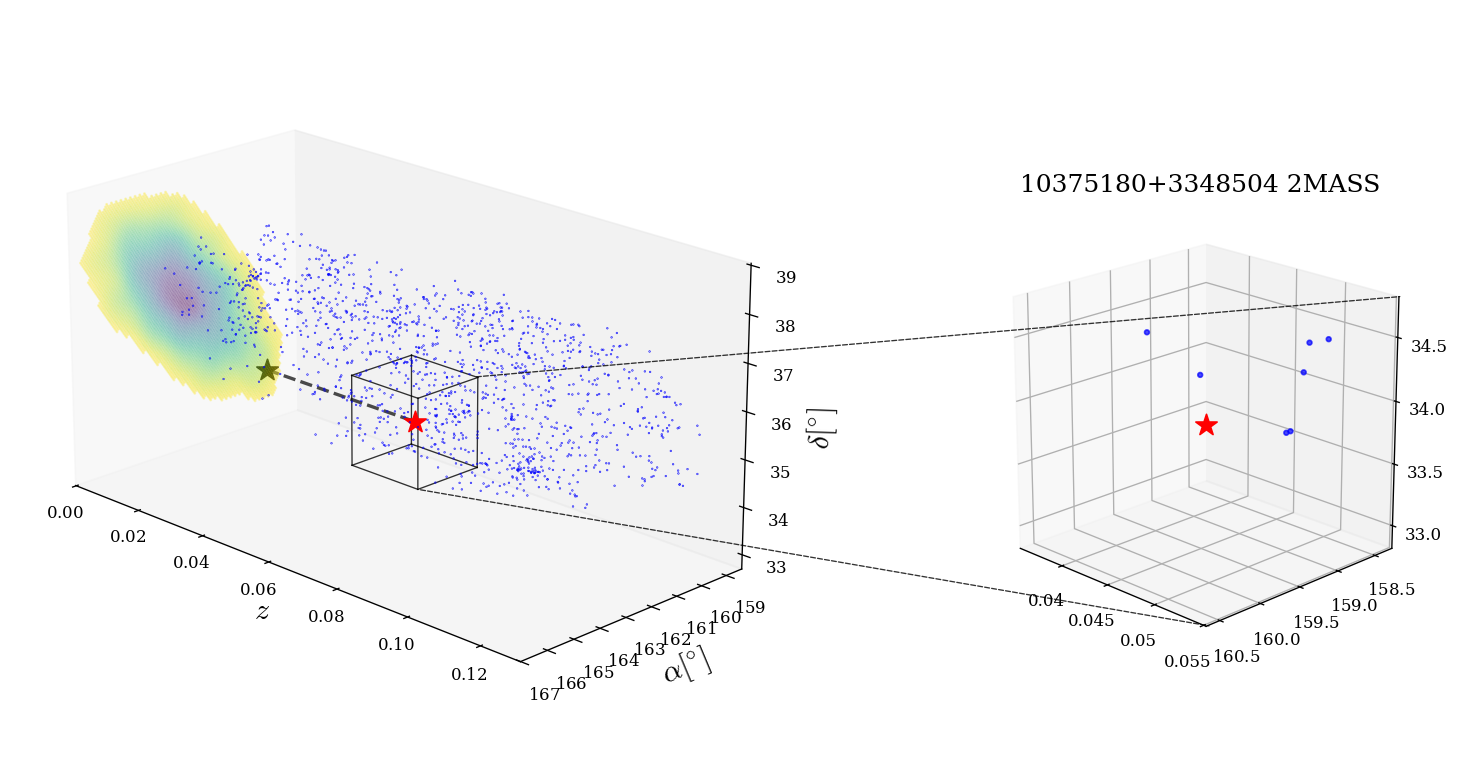
Fig 1: Three-dimensional view of the GLADE+ galaxies (blue dots) contained within the localization volumes of S250207bg
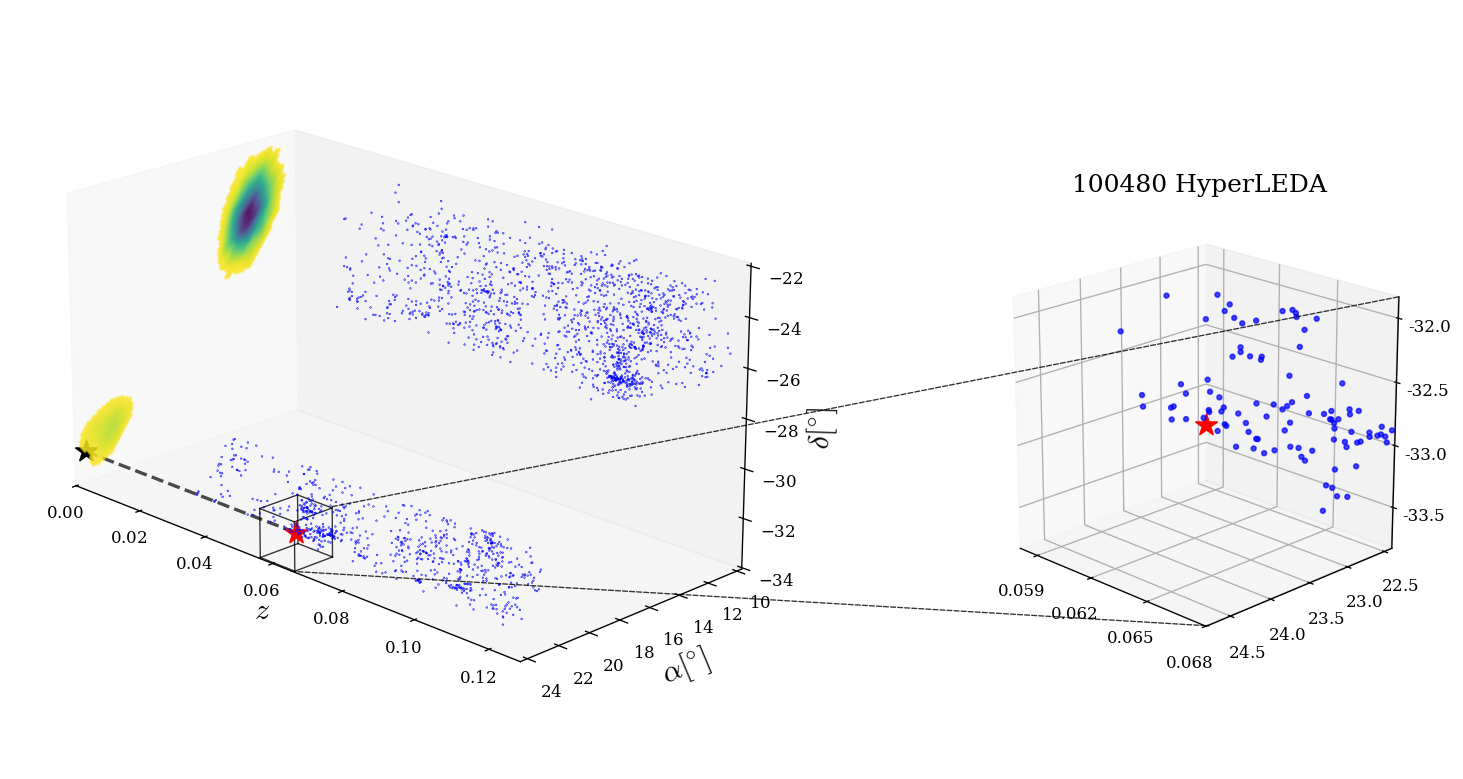
Fig 2: H0 posteriors for S250207bg, GW190814, S250830bp, and their combinations. The left panel assumes a uniform prior
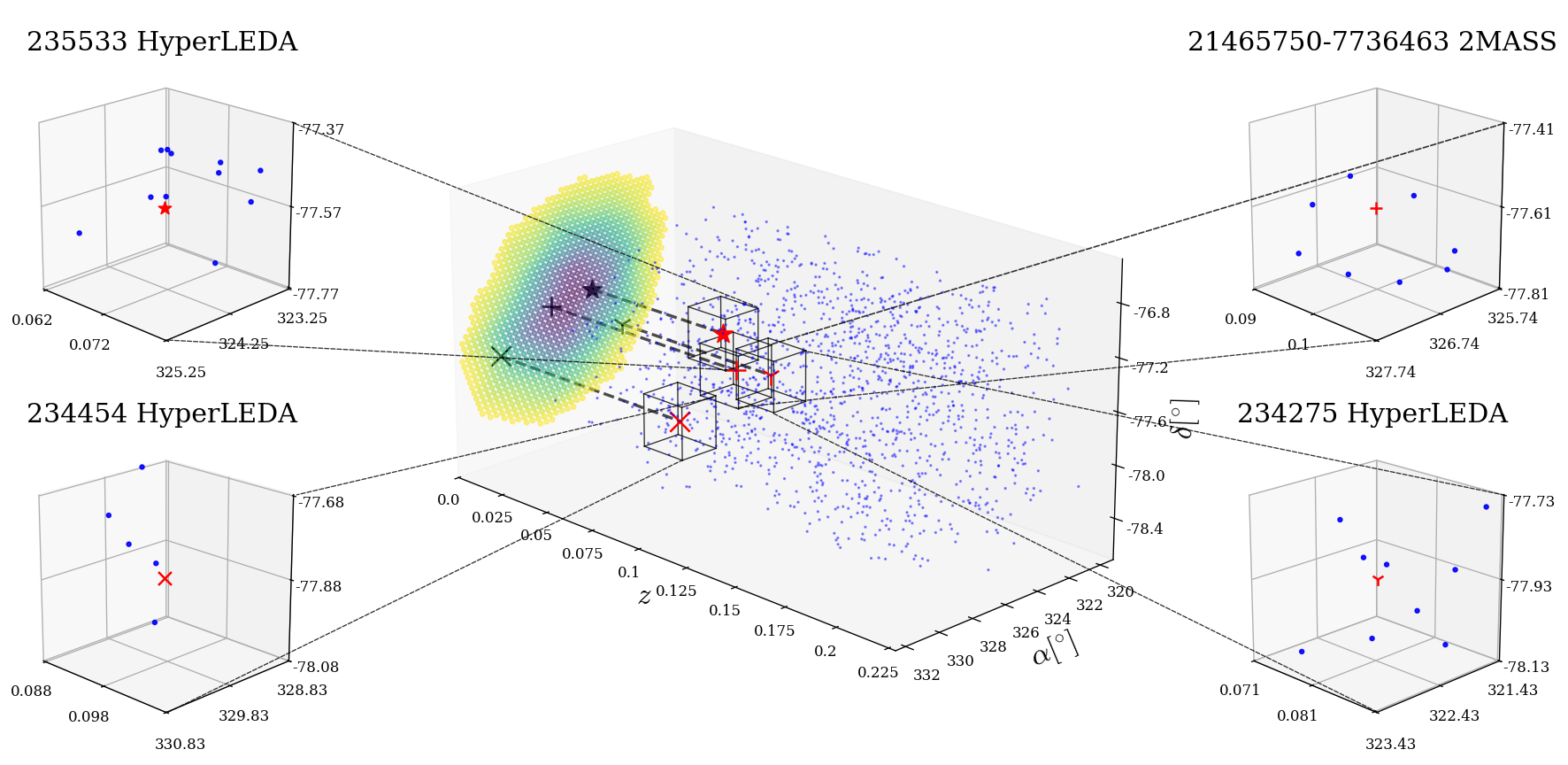
Fig 4 (page 4).
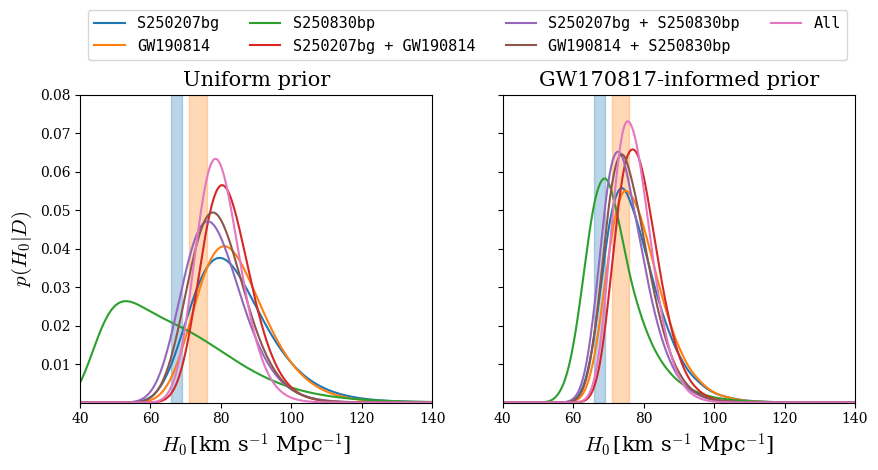
Fig 5 (page 5).
Fig 3: Top panel:
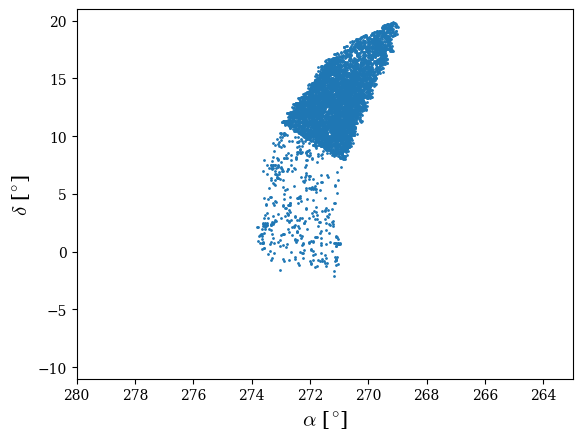
Fig 7 (page 8).
Limitations
- The method is demonstrated on only three retained events, so the empirical support is thin and not enough to estimate true precision/recall for host recovery.
- The candidate set is not validated against known true hosts for the three main events, because those hosts are not securely known; the paper therefore cannot measure top-1 host accuracy.
- The random-association calculation uses a uniform mock catalog and argues that large-scale structure is unnecessary, but that simplification may miss correlations between luminous galaxies and real overdensities/voids.
- Brightest-1% selection is a heuristic, and the paper does not optimize fg, ρg, or the H0-consistency window against an external validation set.
- S250207bg’s only candidate is flagged as an AGN; after AGN removal, no alternative candidate remains, which weakens confidence in the event-level identification.
- The H0 posteriors shown in Table 3 depend on simplifying selection-function treatment (β(H0) ∝ H0^3 in the local-universe approximation) and on priors; the authors themselves note that more accurate selection corrections would likely shift H0 upward.
Open questions / follow-ons
- How should fg and the luminosity threshold be optimized if the goal is maximum host-recovery probability at fixed false-association rate?
- Can the bright-galaxy heuristic be replaced by a learned or physically calibrated host-probability model that uses color, morphology, star-formation rate, and environment jointly?
- How much do real large-scale structure and cluster membership change the random-association estimate compared with the uniform mock catalog used here?
- Can the method be extended to include explicit probability weighting over multiple candidate galaxies rather than hard thresholding on H0 consistency?
Why it matters for bot defense
For a bot-defense engineer, the main transferable idea is not astronomy-specific; it is the use of a strong prior to collapse a large candidate set into a small, reviewable subset while preserving a probabilistic estimate of false positives. Here the prior is astrophysical brightness plus localization geometry; in bot defense, the analog would be using high-signal features to rank sessions, accounts, or challenges before spending expensive verification budget. The cautionary part is equally important: the paper shows that a narrow heuristic can be useful, but only if you continuously estimate random-association rate and check for systematic contamination such as AGNs here, or false positives / proxy leakage in a defense pipeline. That is a good pattern for triage systems: use a cheap filter, then attach a calibrated consistency test and a null model so you know how often you are being fooled.
Cite
@article{arxiv2604_28132,
title={ Finding the one: identifying the host of compact binary mergers },
author={ Alberto Salvarese and Hsin-Yu Chen and Daniel E. Holz },
journal={arXiv preprint arXiv:2604.28132},
year={ 2026 },
url={https://arxiv.org/abs/2604.28132}
}