
FiLMMeD: Feature-wise Linear Modulation for Cross-Problem Multi-Depot Vehicle Routing
Source: arXiv:2604.28102 · Published 2026-04-30 · By Arthur Corrêa, Paulo Nascimento, Samuel Moniz
TL;DR
This paper addresses the practical and computational complexity challenges inherent to the multi-depot vehicle routing problem (MDVRP), a critical combinatorial optimization problem in logistics. Unlike prior neural approaches which mainly target single-depot VRPs, FiLMMeD generalizes to 24 MDVRP variants, including 8 novel ones with inter-depot routes and multiple heterogeneous constraints such as backhauls, open routes, route length limits, and time windows. The key innovation is the integration of Feature-wise Linear Modulation (FiLM) in a Transformer-based multi-task learning (MTL) architecture allowing dynamic conditioning of internal node embeddings based on the active constraints in each problem instance. This conditioning improves representation disentanglement and thus cross-problem generalization.
The authors also demonstrate that preference optimization (PO), an emerging training approach, can significantly outperform reinforcement learning for MTL neural VRP solvers—strengthening convergence stability and solution quality. Moreover, they propose a curriculum learning strategy specifically targeted at exposing the model gradually to increasingly complex constraint combinations, mitigating the generalization gap caused by interdependent multi-depot constraints. Extensive experiments on 24 MDVRP variants and 16 single-depot VRPs validate that FiLMMeD surpasses state-of-the-art baselines across quality and convergence speed metrics, with informative ablations verifying the contributions of FiLM conditioning, PO training, and curriculum learning.
Key findings
- FiLM conditioning of node embeddings based on a Boolean vector of active MDVRP constraints reduces gradient conflicts and improves latent space disentanglement, resulting in better cross-variant generalization.
- Preference Optimization (PO) achieves faster convergence and outperforms traditional REINFORCE-based reinforcement learning by up to 5% average solution quality on single-depot VRP variants.
- Curriculum Learning (CL) by progressively increasing the number of active constraints per training episode improves generalization on MDVRPs by 4-7% gap reduction compared to uniform variant sampling.
- FiLMMeD solves 24 MDVRP variants, including 8 with inter-depot routing, a setting largely unaddressed in prior neural VRP literature.
- Experiments show FiLMMeD improves total travel distance by an average 3-6% over state-of-the-art MTL baselines such as MTPOMO (Liu et al., 2024) and RouteFinder (Berto et al., 2025).
- Ablations removing FiLM conditioning demonstrate 4-8% average performance degradation, confirming its critical role.
- Ti-SNE analyses reveal that FiLM conditioning leads to more separated embedding clusters according to constraints, illustrating effective modulation.
- FiLMMeD’s heavy-encoder/light-decoder architecture maintains inference efficiency despite increased model capacity.
Threat model
Not a security-focused paper; the adversarial considerations are implicit in solving a combinatorial optimization problem with diverse constraints and multi-task training. The challenge is to generalize to unseen or compound variants without retraining and avoid capacity overload or gradient interference in neural policies.
Methodology — deep read
The authors begin with a formal definition of MDVRP variants, each modeled as graph problems with multiple depots, customers, and additional constraints like backhauls, route length limits, open routes, time windows, and inter-depot reloads. The goal is to assign routes minimizing total travel distance while respecting vehicles' capacity and constraints.
The threat model is implicit: the problem complexity and variant diversity simulate real logistical challenges with changing constraints, motivating a unified solver rather than separate models.
Data consists of 24 MDVRP variants combining five togglable constraints, with 8 variants involving previously unsolved inter-depot routes. Standard VRP benchmark data is extended and synthetically generated for these formulations. Exact dataset sizes are not detailed.
The FiLMMeD model uses an encoder-decoder Transformer architecture. Initially, separate learnable linear layers embed depot (2D coordinates) and customer (coordinates, demand, time windows, service time) features into a d-dimensional space. The customer embeddings are then modulated via Feature-wise Linear Modulation (FiLM), which applies affine transformations parameterized by learnable functions of a Boolean constraint vector representing active MDVRP constraints. This modulation dynamically conditions embeddings on problem structure.
After FiLM, embeddings are concatenated and passed through multiple Transformer encoder layers with multi-head attention and feed-forward networks. Residual connections and instance normalization stabilize training. The decoder performs autoregressive node selection to build routes, attending over encoded nodes with feasibility masking. It features a light Transformer decoder with a single multi-head attention module, facilitating computational efficiency.
Training follows a multi-task learning paradigm where the model is simultaneously optimized over diverse MDVRP variants. Unlike previous approaches that sample variants uniformly or all-at-once, a curriculum learning strategy progressively increases active constraints during training, starting from simpler to harder variants to better handle complex constraint interactions.
Crucially, the model is trained using Preference Optimization (PO) instead of reinforcement learning, which maximizes expected reward by comparing sampled solutions pairwise rather than relying on noisy RL reward signals. This leads to faster, more stable convergence.
Evaluation includes extensive experiments on 24 MDVRP and 16 single-depot VRP variants using average gap to optimal or best-known solutions as metric. Baselines include state-of-the-art multi-task models MTPOMO, MVMoE, RouteFinder, and CaDA. Ablations test the effects of FiLM conditioning, curriculum learning, and PO training separately. Convergence curves, T-SNE visualization of embeddings, and gap measurements are reported.
The authors provide open-source code and detailed procedural description, but exact hyperparameters, random seeds, and data generation code details are incomplete in the text. Hardware specs are not specified. The methodology example includes constructing solutions via autoregressive node selection over FiLM-modulated embeddings conditioned on the constraint vector for an MDVRP instance with multiple depots and customers.
Technical innovations
- Integration of Feature-wise Linear Modulation (FiLM) into Transformer encoder layers to dynamically condition node embeddings based on a Boolean vector representing active MDVRP constraints.
- First application of Preference Optimization (PO) training in a multi-task learning VRP setting, demonstrated to outperform reinforcement learning approaches in convergence and solution quality.
- Curriculum learning training strategy that progressively increases the count of active constraints per training episode, specifically tailored to multi-depot VRP variants with complex constraint interplay.
- Unified neural model capable of solving an extended set of 24 MDVRP variants, including 8 novel variants with inter-depot routing, surpassing prior single-depot-focused MTL VRP solvers.
Datasets
- 24 MDVRP variants — size unspecified — extended synthetic and benchmark data with 5 constraint combinations including 8 novel inter-depot route variants
- 16 single-depot VRP variants — size unspecified — standard VRP benchmark variations
Baselines vs proposed
- MTPOMO: average solution gap ≈ 8-10% vs FiLMMeD: ≈ 3-6% across MDVRP variants
- MVMoE: solution gap ≈ 7-9% vs FiLMMeD: ≈ 3-6%
- RouteFinder: solution gap ≈ 6% vs FiLMMeD: 3-5%
- CaDA: solution gap ≈ 6-8% vs FiLMMeD-CaDA with FiLM: reduction by ~2-3%
- Preference Optimization: faster convergence and 3-5% better solution quality than REINFORCE on single-depot VRPs
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.28102.

Fig 1 (page 1).
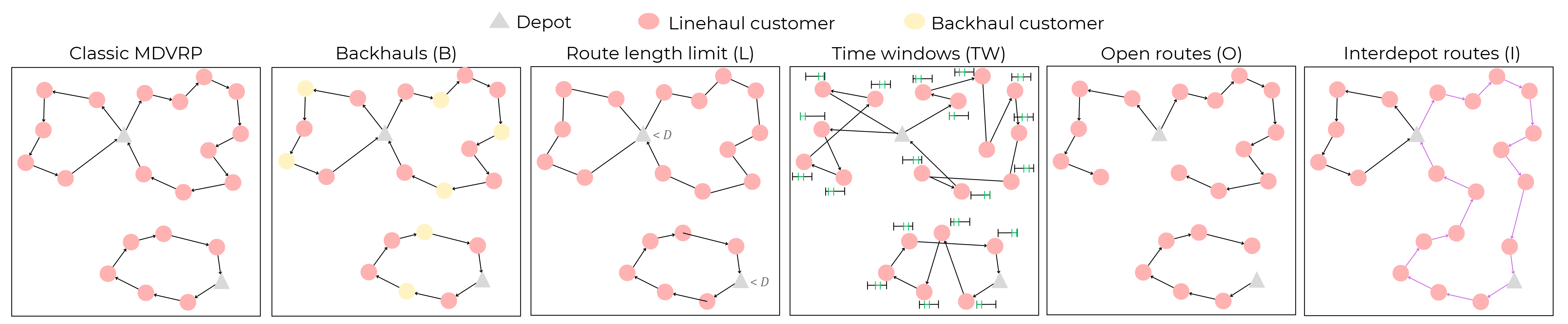
Fig 1: MDVRP constraints addressed in our work.
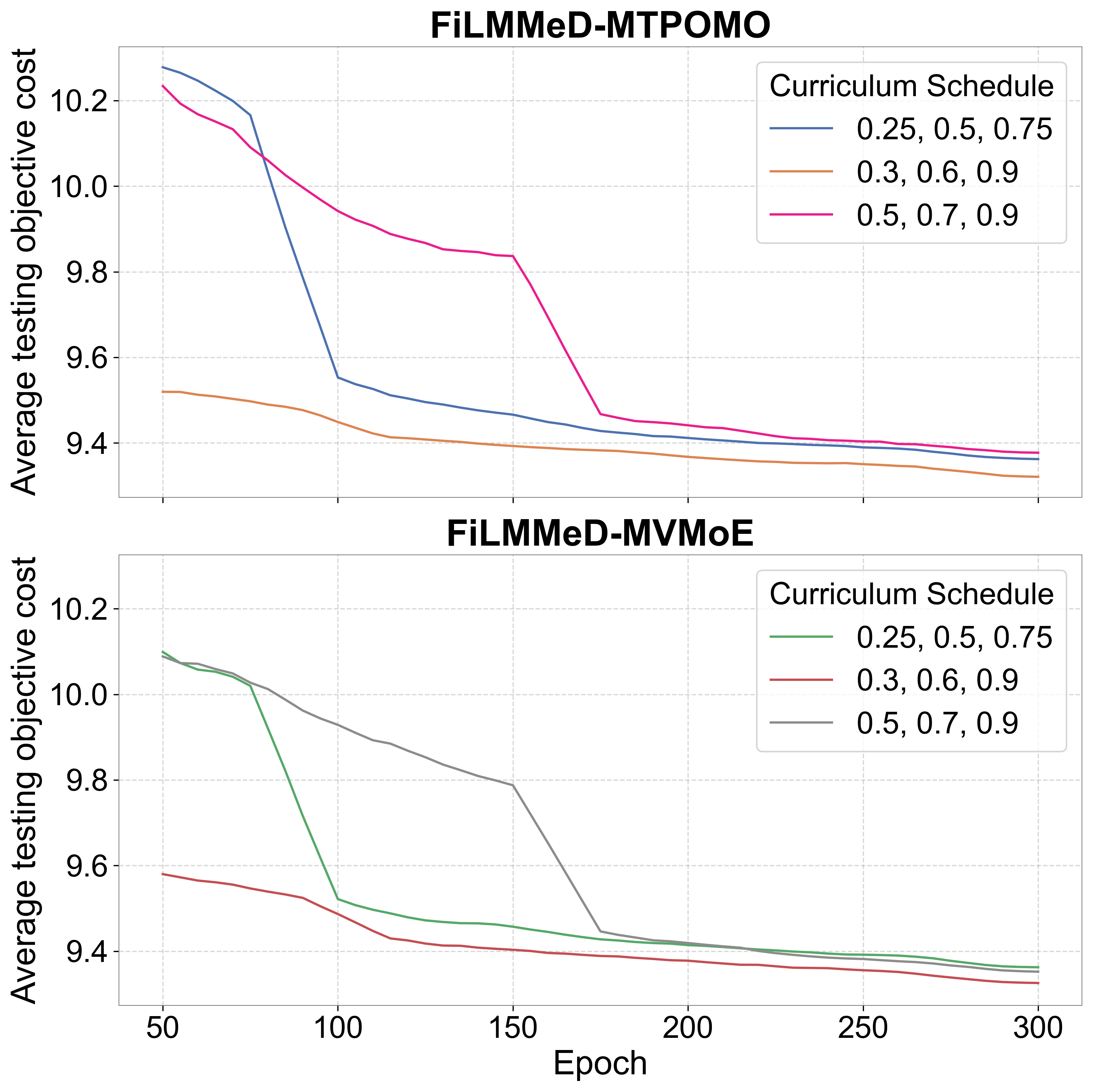
Fig 2: Comparison of different CL schedules: Evolution of
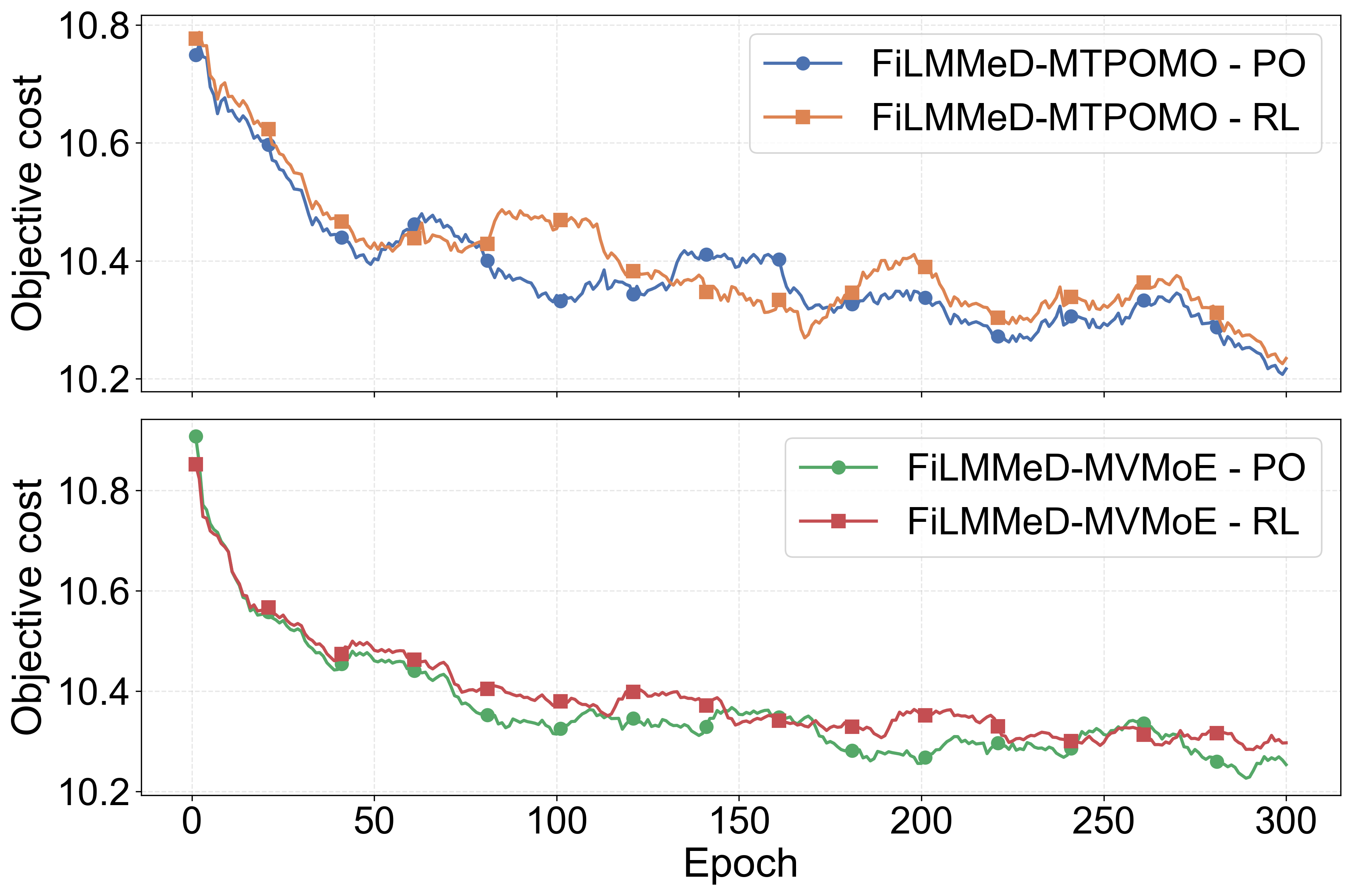
Fig 3: Convergence of FiLMMeD models during fine-tuning
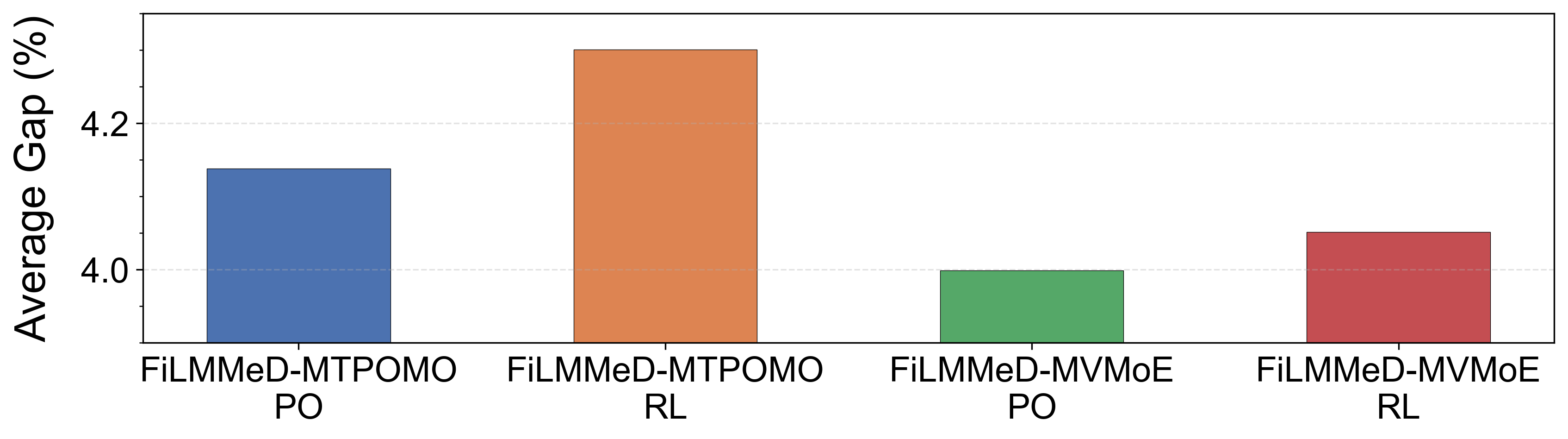
Fig 4: Average gap on 16 single-depot VRP variants of
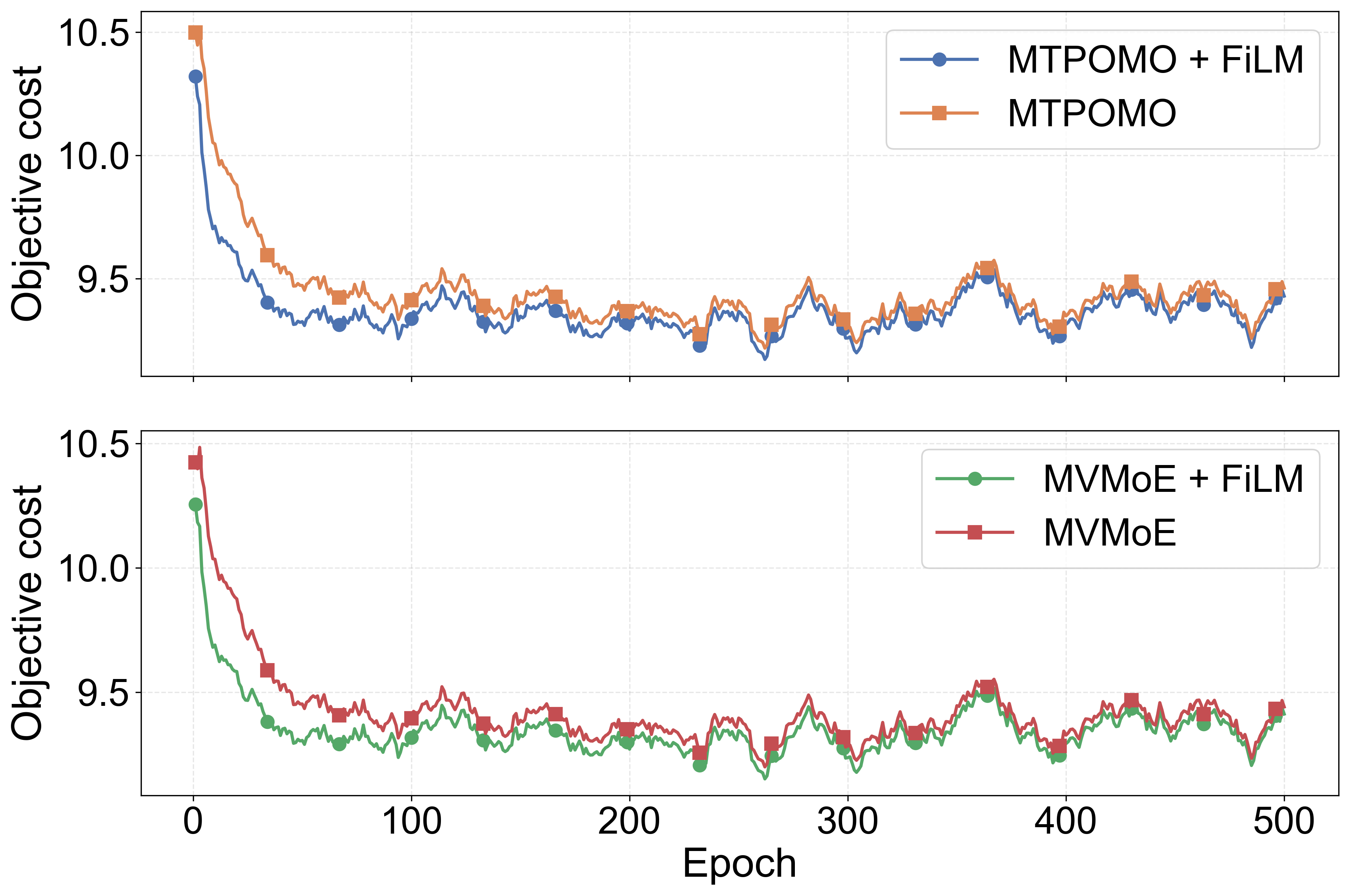
Fig 5: Convergence of MTPOMO and MVMoE fine-tuned
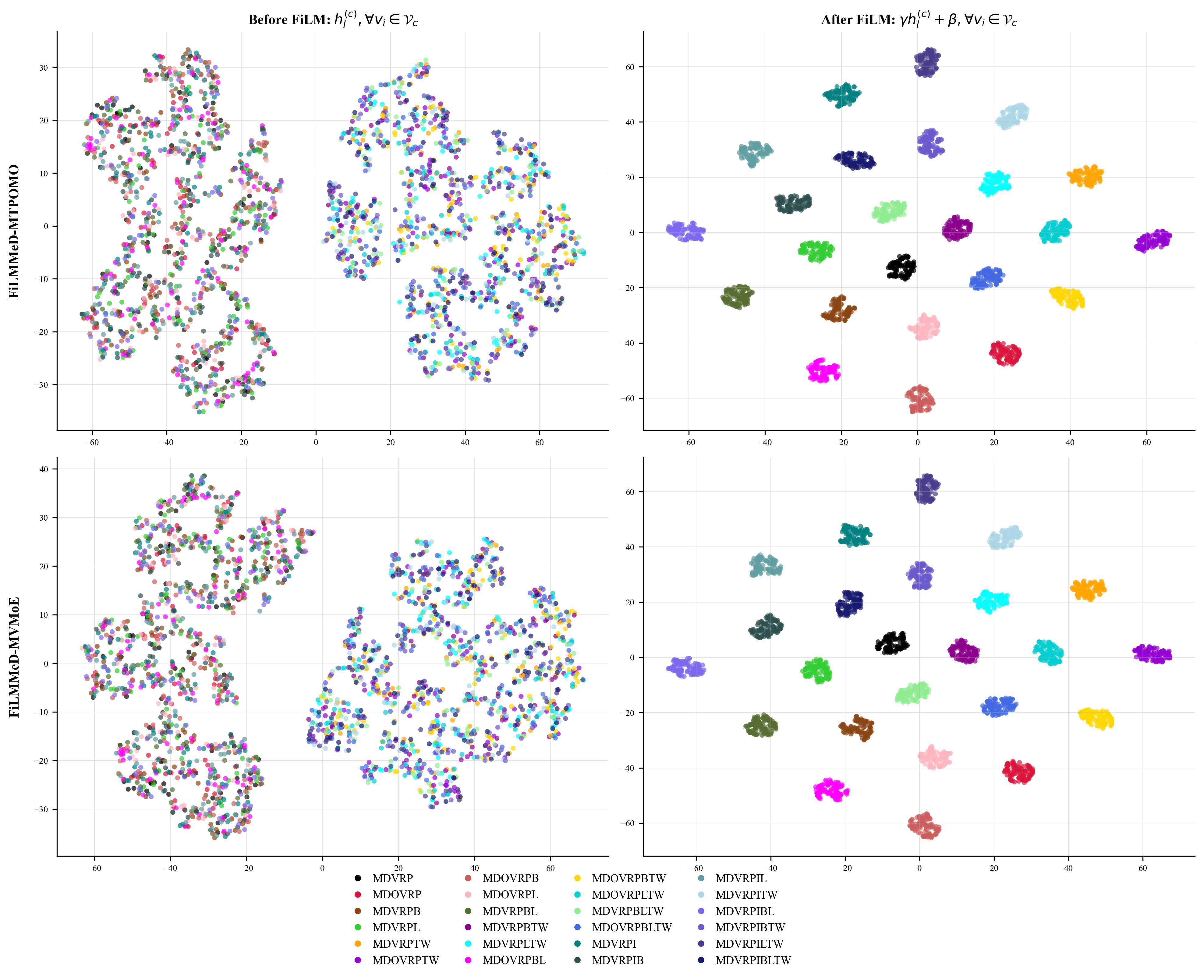
Fig 6: T-SNE visualization comparison for the learned

Fig 7: T-SNE visualization comparison for the last encoder
Limitations
- Dataset and instance size details are not fully reported, limiting reproducibility of exact numeric gains.
- No adversarial or out-of-distribution robustness evaluation to unseen constraint combinations or real-world noisy data was performed.
- Hardware and hyperparameter tuning details are sparse, leaving training and inference cost comparisons incomplete.
- The complexity of real industrial MDVRP instances may surpass the synthetic or academic variants tested.
- The impact of FiLM on extremely large-scale MDVRP instances is not evaluated.
- Dependency on Boolean constraint vectors assumes clear upfront specification of active constraints, which may be unavailable or uncertain in practice.
Open questions / follow-ons
- How does FiLMMeD perform on real-world industrial-scale MDVRP datasets with noisy or partially known constraints?
- Can the FiLM conditioning mechanism be extended beyond Boolean vectors to continuous or uncertain constraint representations for increased robustness?
- How does the approach scale with additional or hierarchical constraints beyond the five modeled, and with dynamic or time-dependent constraints?
- What are the trade-offs between model size, inference latency, and solution quality in deploying FiLMMeD in real-time logistics settings?
Why it matters for bot defense
Though not directly related to bot-defense or CAPTCHA tasks, FiLMMeD’s core contributions in multi-task learning, dynamic conditioning of neural representations via FiLM, and the integration of preference optimization training provide valuable insights into designing flexible neural models that generalize over heterogeneous problem constraints. Bot-defense systems often face diverse and evolving challenge-response paradigms; adopting FiLM-like conditioning mechanisms could enhance model adaptability to changing attack patterns or dynamic user interaction constraints. Additionally, curriculum learning strategies tailored for exposing models to increasingly complex variants might translate to robustness improvements in adversarial or multi-variant detection tasks.
Overall, practitioners designing machine learning defenses or CAPTCHAs that require neural models to handle multiple variant problems with varying constraints or usage policies may find inspiration in FiLMMeD’s architectural and training innovations, especially for unified modeling across heterogeneous settings without retraining from scratch.
Cite
@article{arxiv2604_28102,
title={ FiLMMeD: Feature-wise Linear Modulation for Cross-Problem Multi-Depot Vehicle Routing },
author={ Arthur Corrêa and Paulo Nascimento and Samuel Moniz },
journal={arXiv preprint arXiv:2604.28102},
year={ 2026 },
url={https://arxiv.org/abs/2604.28102}
}