
Continuous-tone Simple Points: An $\ell_0$-Norm of Cyclic Gradient for Topology-Preserving Data-Driven Image Segmentation
Source: arXiv:2604.28159 · Published 2026-04-30 · By Wenxiao Li, Faqiang Wang, Yuping Duan, Li Cui, Liqiang Zhang, Jun Liu
TL;DR
This paper addresses a specific gap in topology-aware image segmentation: classical simple-point topology is defined on binary images and is non-differentiable, which makes it awkward to use with modern deep networks that output probabilities. The authors’ core idea is to extend simple-point detection to continuous-valued images by recasting local topology as a smooth approximation of the cyclic-gradient crossing number. That lets them compute “simple points” directly on soft prediction maps, so topology constraints can participate in gradient-based training instead of being bolted on after thresholding.
On top of that theory, they build two applications: a topology-preserving skeleton extraction algorithm and a variational segmentation module (TCSP) that can be plugged into networks with sigmoid/softmax outputs, including SAM-style architectures. The experimental claim is that this gives better topological integrity and structure preservation than morphology-based skeletonization and an STE/reparameterization-based prior (SRSP), while also reducing runtime. The paper reports qualitative segmentation improvements and quantitative topological metrics across several tubular/reticular datasets, but the excerpted text only exposes the full numeric skeletonization table; segmentation numbers are described more qualitatively in the provided material.
Key findings
- On the DCA dataset, morphology-based skeletonization had β0 = 18.00 and χerror = 18.88 on continuous-valued images, while the proposed method reports β0 = 0.00, β1 = 0.00, χerror = 0.00.
- On DRIVE, the proposed method reports 0.00 for β0, β1, and χerror on continuous-valued images, compared with Morph [14] at β0 = 212.25, β1 = 27.75, χerror = 240.00.
- On MASS, the proposed method reports 0.00/0.00/0.00 for (β0, β1, χerror), while Morph [14] reports 70.22/4.26/74.48 on continuous-valued images.
- On UBW, the proposed method reports 0.00/0.00/0.00, while Morph [14] reports β0 = 5.46, β1 = 0.97, χerror = 6.43 on continuous-valued images.
- Runtime on DCA is 33.40 ms for the proposed method versus 144.52 ms for SRSP [37] and 4.09 ms for Morph [14] on binary images; on continuous-valued DCA, the proposed method is also 33.40 ms versus 74.27 ms for SRSP [37].
- Runtime on DRIVE is 16.82 ms for the proposed method versus 74.27 ms for SRSP [37] (continuous-valued) and 5.14 ms for Morph [14] (binary), showing a speed/accuracy trade-off relative to morphology and a large win over the STE-based approach.
- In the table note, SRSP without added logical noise yields topological metrics of 0, but the authors state that omitting noise can inhibit learning; with logical noise intensity 0.1 (SRSP*), topology errors reappear (e.g., DCA β0 = 2.21, β1 = 0.68, χerror = 2.00).
Threat model
The adversary in this paper is not a malicious attacker but the inherent mismatch between topology-aware objectives and differentiable learning: a segmentation network can produce pixel-accurate outputs that still fragment objects, create holes, or violate connectivity. The method assumes the model has access to standard soft outputs (sigmoid/softmax) and that topology can be enforced through local continuous-tone simple-point constraints; it does not address an adaptive adversary trying to evade the detector, nor does it assume any special threat beyond structural/topological inconsistency in predictions.
Methodology — deep read
The paper’s threat model is not a cybersecurity threat model but a geometric/topological one: the adversary is effectively the failure mode of standard segmentation pipelines that optimize pixelwise accuracy while breaking object connectivity, creating holes, spurs, or disconnected components. The authors assume a supervised segmentation setting where the network outputs continuous probabilities (sigmoid/softmax), and they want a topology constraint that is differentiable and can be optimized end-to-end. They also explicitly position their method against prior topology-preserving strategies that depend on binary images, STE/reparameterization, morphology, or other non-differentiable post-processing.
Data-wise, the experiments use four benchmark datasets aimed at thin, connected structures. DRIVE has 40 retinal images with blood-vessel annotations, split into 20 train and 20 test images. DCA has 134 coronary angiography images from the Mexican Social Security Institute (UMAET1-León), split 100 train / 34 test. MASS has 1,171 Massachusetts road images at 1500×1500; the authors crop each to 800×800 patches and randomly select 1,600 training patches, using official validation/test splits. UBW contains 1,281 MRI slices of the urinary bladder wall, center-cropped to 320×320 and split 904 / 185 / 192 by patient slices. The excerpt does not fully specify label preprocessing, normalization, or whether skeleton labels are generated from ground truth versus manually annotated; for skeleton evaluation they clearly compare extracted skeletons against topology-derived quantities rather than a direct pixelwise skeleton annotation pipeline.
The main algorithmic contribution is a reformulation of simple-point detection for continuous-valued images. In binary topology, a pixel is simple if flipping it does not change the object’s global topology, formally requiring one connected foreground component and one connected background component in the relevant neighborhoods. The paper simplifies the binary criterion by using the crossing number: for non-boundary points, simple-point status can be determined by a crossing number of 2. They define a cyclic neighborhood around each pixel and a cyclic gradient vector of adjacent intensity differences. The binary crossing number becomes the ℓ0 norm of that cyclic gradient, i.e., the number of transitions around the 8-neighborhood cycle. To extend this to continuous-valued images, they introduce a thresholded connectivity notion and replace the hard indicator with a sigmoid-based smooth approximation, yielding a smooth crossing number C_{α,τ}(u)[x]. They then wrap this in a Gaussian-shaped topological detection operator W_{α,τ,σ}(u)[x], which approximates the indicator of simple points while remaining differentiable. The intended novelty is not a new topology concept per se, but a differentiable relaxation that can be applied directly to soft network outputs without reparameterization or STE.
For skeletonization, they use the standard iterative thinning paradigm: repeatedly remove simple points until only the skeleton remains. The implementation is made practical by partitioning pixels into four subfields M1–M4 based on coordinate parity and updating them sequentially, which is meant to avoid simultaneous removal of adjacent points that could alter topology. They also define an endpoint detector so that endpoints are preserved and the object does not collapse to a single pixel. Algorithm 1 (CSPS) takes an input image u in [0,1], iteration count T, and hyperparameters α, τ, σ; for each iteration it first identifies endpoints, then in each of the four subfields computes W_{α,τ,σ}(u) and updates S(u) ← (1 − P(u)·W_{α,τ,σ}(u))·S(u). The authors explicitly contrast this with SRSP [37], which uses reparameterization plus the straight-through estimator; their claim is that CSP avoids injected noise and gradient mismatch.
For segmentation, they first define a skeleton-based loss. Given prediction u and ground truth g, they compute skeletons S(u) and S(g), then define Tprec and Tsens as precision/recall-like measures over skeleton pixels. The CSP loss LCSP is a harmonic-style penalty 1 − 2·Tprec·Tsens / (Tprec + Tsens), and the final training loss is BCE + λLCSP. This is an auxiliary training regularizer only; they separately argue that loss shaping alone does not guarantee topology at inference time. To address that, they introduce a variational model TCSP: min_u ⟨−o,u⟩ + εH(u) + ηT(u,v), where o is the network’s segmentation feature, H(u) is an entropy regularizer, and T(u,v) penalizes putting topologically non-removable points in the background. The auxiliary variable v is learned to identify points whose removal would alter topology, then a morphological connected-component extraction operator M(S(v)) restores the geometric extent of those points. Because the objective is strongly convex in u, they derive a closed-form update u* = sigmoid((o + η v·M(S(v)))/ε). They then embed this in a SAM-like architecture Nθ(I,p,m) producing both the segmentation u* and the topology auxiliary output v, and train it with BCE(u*,g) + λLCSP(v,g).
Training details in the excerpt are incomplete. The authors state that all experiments use Python 3.11.11, PyTorch 2.4.0, and an NVIDIA 4090 GPU, and that the smooth-crossing parameters are fixed at α = 16, σ = 0.2, τ = 0.5. They also mention identical preprocessing across methods, including random cropping, horizontal and vertical flips, and presumably other standard augmentations, but the excerpt cuts off before the full preprocessing list and does not specify optimizer, batch size, number of epochs, learning rate schedule, seed control, or early stopping. The same applies to the TCSP-SAM implementation details: the paper provides the mathematical network decomposition, but not the exact backbone choice beyond the SAM-style formulation in the excerpt.
Evaluation uses topology metrics on skeletons: Betti numbers β0 and β1 plus χerror (Euler-characteristic error). The skeletonization comparison is against Morph [14], SRSP [37], and SRSP* (SRSP with logical noise intensity 0.1, matching the prior paper’s setup). The excerpted Table I reports exact values and runtime for DCA, DRIVE, MASS, and UBW, on both binary and continuous-valued image cases. A key detail is the note that SRSP without noise trivially yields zero topological change, but the authors argue this can suppress learning; hence they report SRSP* as a more realistic comparison. The text also mentions segmentation figures comparing “Baseline” versus the proposed loss and TCSP module, but the excerpt does not expose the exact segmentation metrics or statistical tests. Reproducibility is partial: the code is publicly available on GitHub (CSP), but the full training recipe, frozen checkpoints, and exact dataset preprocessing scripts are not fully present in the provided text.
Technical innovations
- A differentiable extension of simple-point detection from binary images to continuous-valued probability maps using a smooth crossing-number surrogate of the cyclic gradient.
- A topology-preserving skeletonization algorithm (CSPS) that iteratively removes continuous-tone simple points with four subfield updates and explicit endpoint preservation.
- A topology regularizer and variational module (TCSP) that can be inserted into sigmoid/softmax segmentation models and yields a closed-form u* update.
- A SAM-compatible topology-preserving architecture (TCSP-SAM) that learns both the segmentation and an auxiliary topological non-removability map.
Datasets
- DRIVE — 40 images (20 train / 20 test) — public benchmark
- DCA — 134 images (100 train / 34 test) — Mexican Social Security Institute, UMAET1-León
- MASS — 1,171 images; 1,600 training patches after cropping to 800×800 — public benchmark
- UBW — 1,281 MRI slices (904 / 185 / 192 split) — ISICDM 2019 challenge dataset
Baselines vs proposed
- Morph [14] on DCA (continuous-valued): β0 = 18.00, β1 = 0.88, χerror = 18.88, runtime = 4.09 ms vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 33.40 ms
- SRSP [37] on DCA (continuous-valued): β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 144.52 ms vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 33.40 ms
- SRSP* [37] on DCA (continuous-valued, noise 0.1): β0 = 2.21, β1 = 0.68, χerror = 2.00 vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00
- Morph [14] on DRIVE (continuous-valued): β0 = 212.25, β1 = 27.75, χerror = 240.00 vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 16.82 ms
- SRSP [37] on DRIVE (continuous-valued): β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 74.27 ms vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 16.82 ms
- Morph [14] on MASS (continuous-valued): β0 = 70.22, β1 = 4.26, χerror = 74.48 vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 17.15 ms
- Morph [14] on UBW (continuous-valued): β0 = 5.46, β1 = 0.97, χerror = 6.43 vs proposed: β0 = 0.00, β1 = 0.00, χerror = 0.00, runtime = 33.39 ms
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.28159.
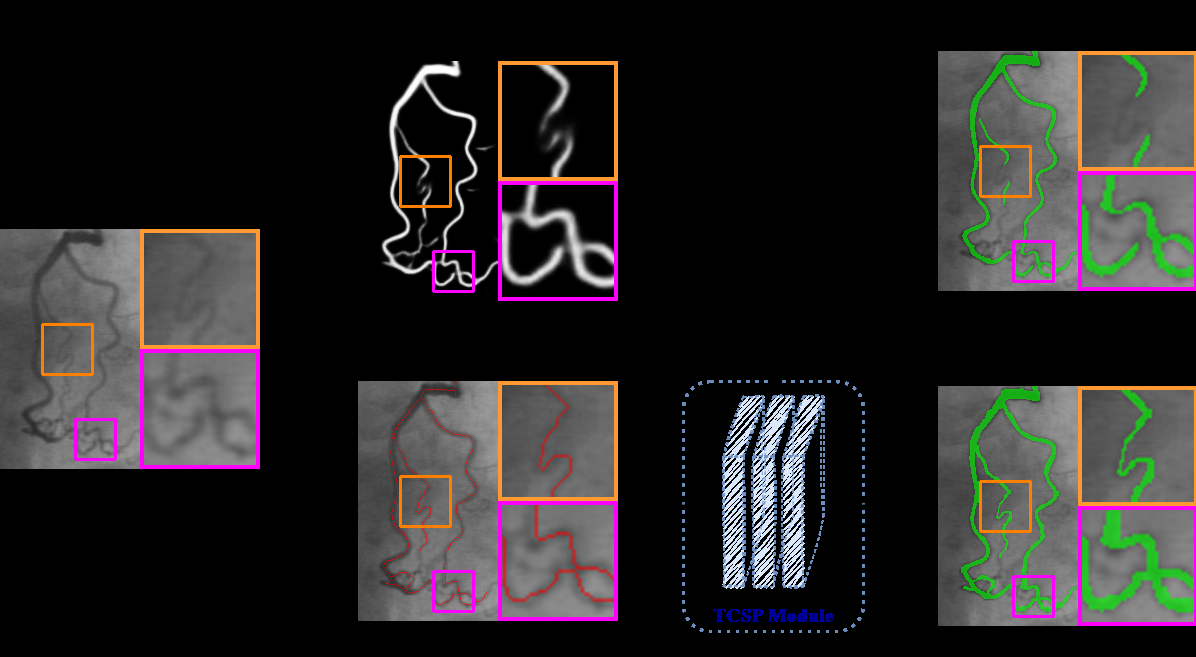
Fig 1: Comparison of segmentation results from SAM2 [1] without and with
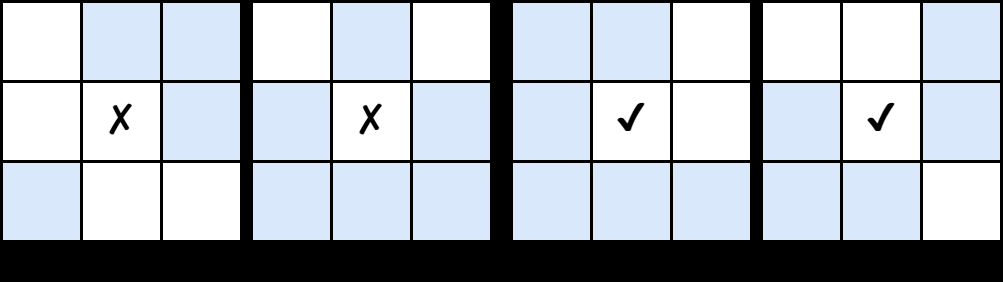
Fig 2: Examples of non-simple and simple points. The solid grids means
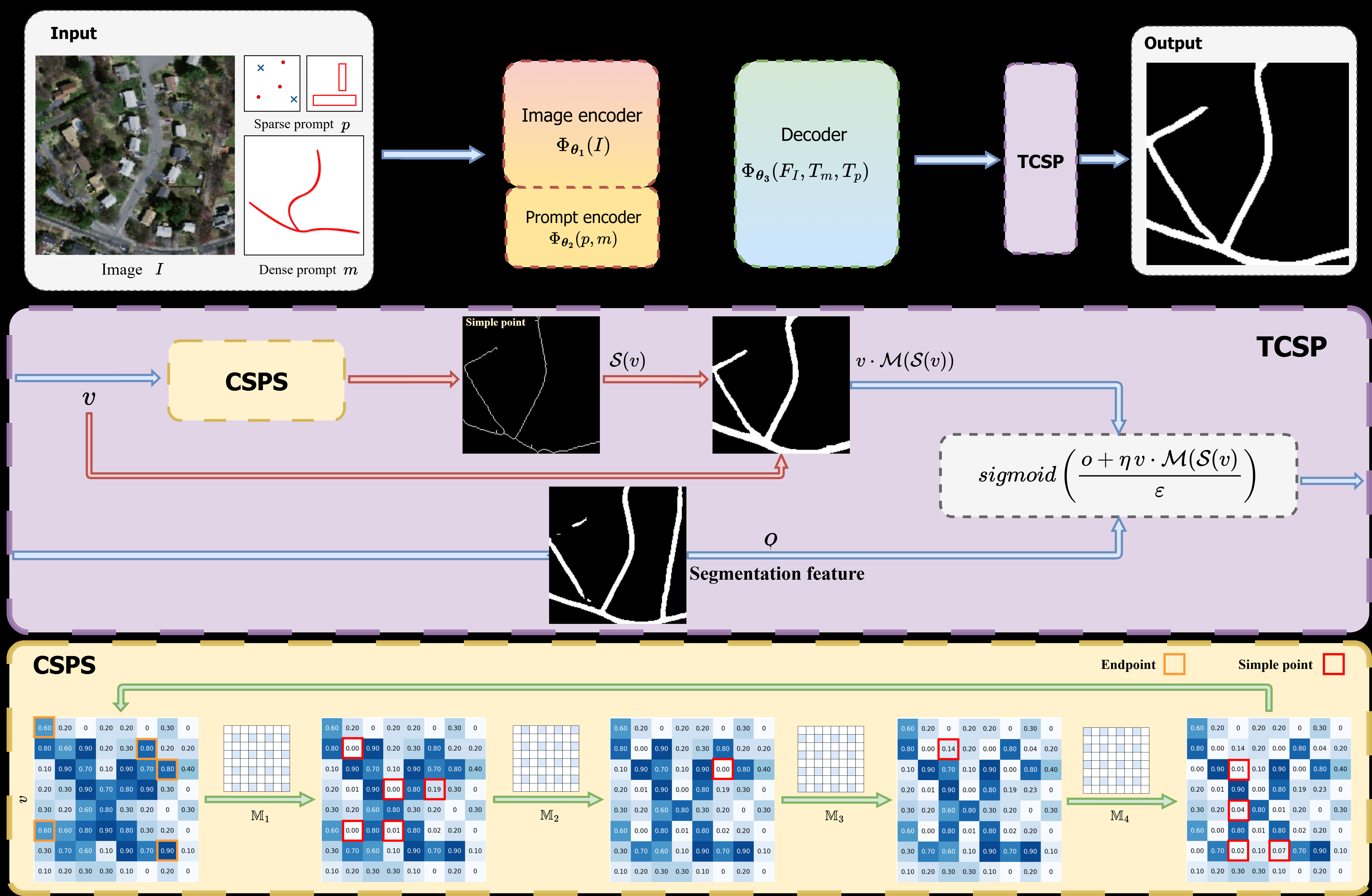
Fig 3: Overview of proposed TCSP-SAM network Nθ defined in Eq. (6). TCSP denotes the topology-preserving variational model (5), and CSPS corresponds
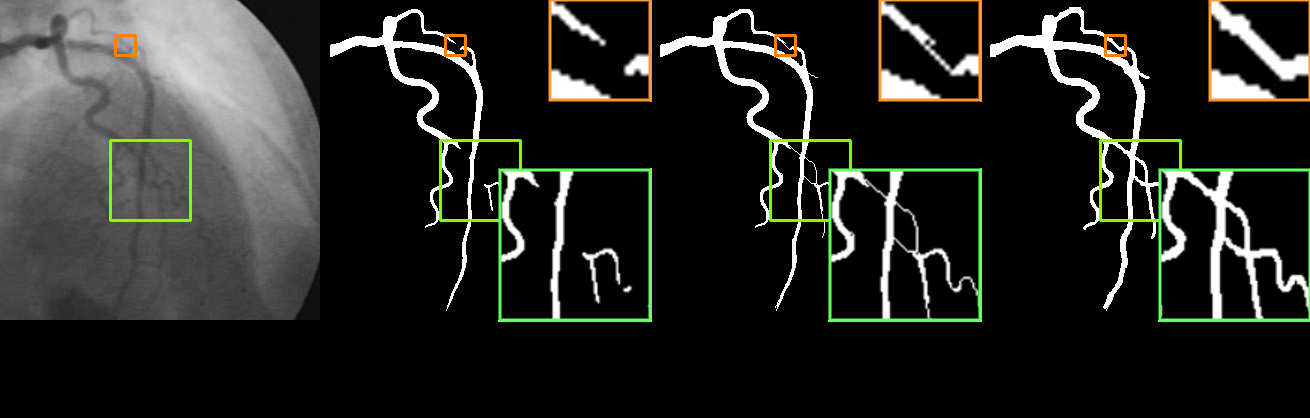
Fig 4: Visualization of results with the regularization term T (u, v) and the
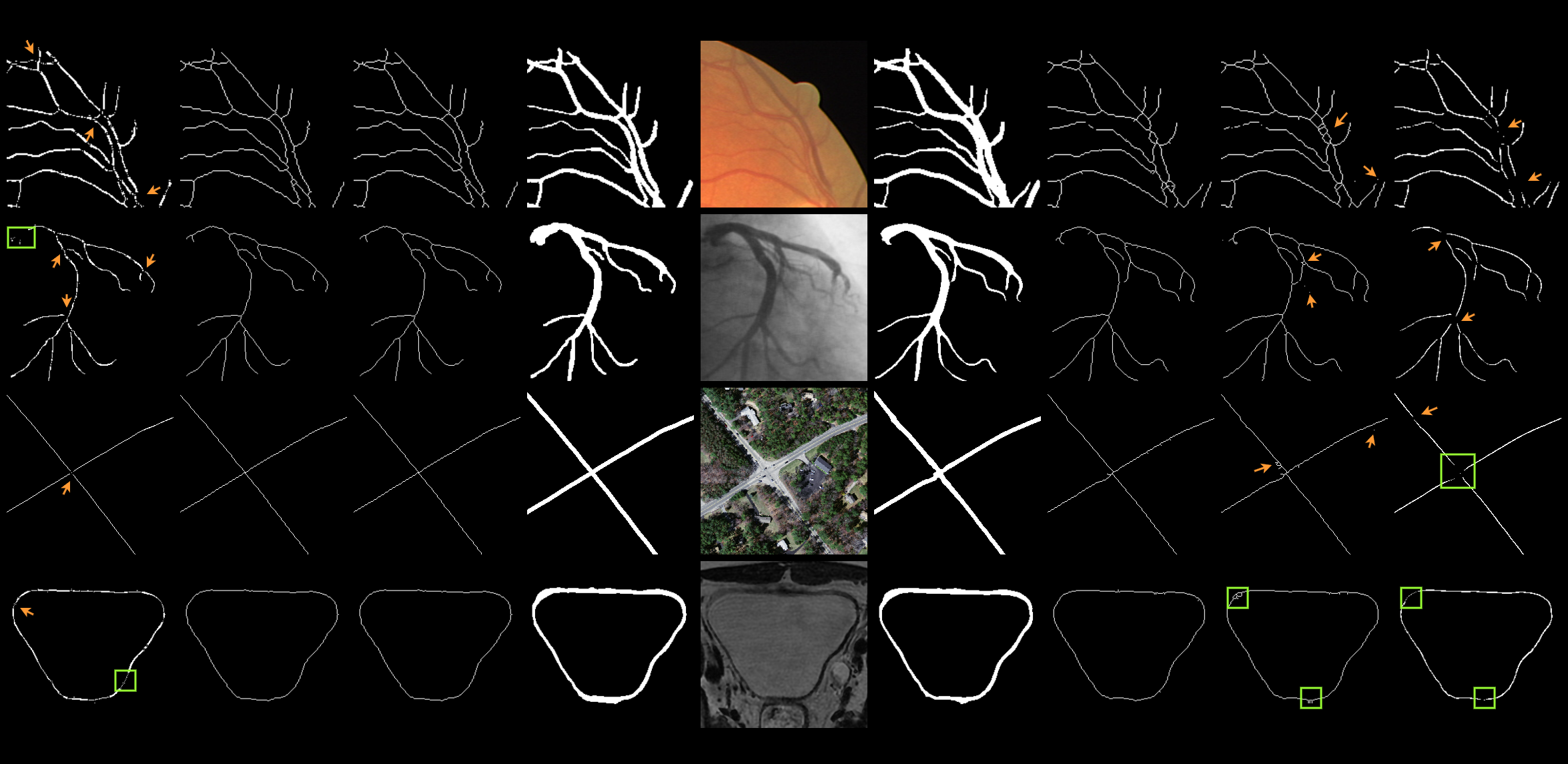
Fig 5: Visualization of skeleton extraction results from binary and continuous-valued images using three methods. SRSP denotes the addition of logical*

Fig 6: Segmentation results of different loss functions. “Baseline” denotes
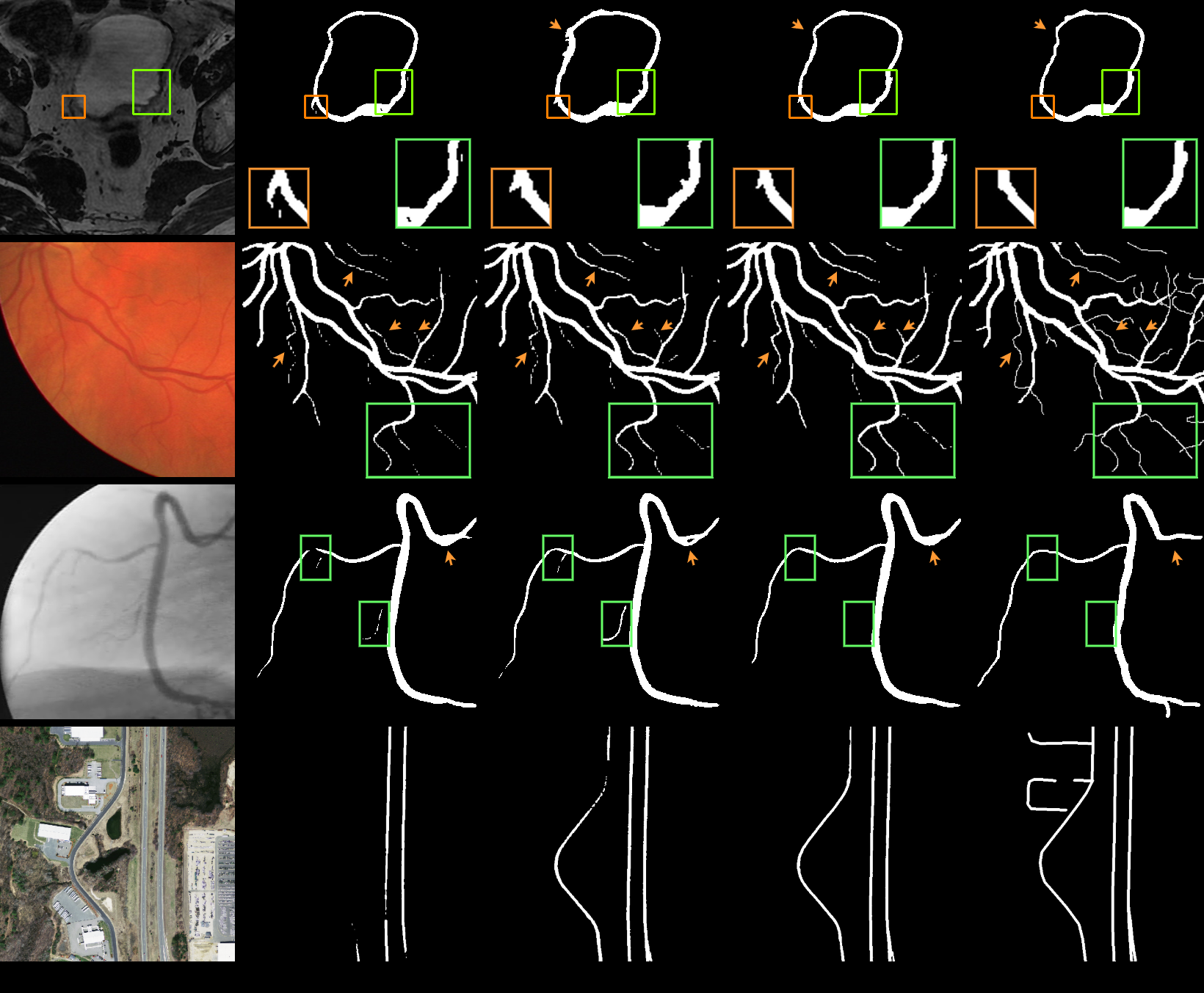
Fig 7: Visualization results of the CSP loss and the topology-preserving
Limitations
- The excerpted text does not provide the full segmentation-result table, so the claimed improvement in segmentation accuracy is not numerically verifiable from the provided material.
- Training details are under-specified: optimizer, learning rate, batch size, number of epochs, seed strategy, and full augmentation pipeline are not given in the excerpt.
- The continuous-tone simple-point theory depends on hyperparameters α, τ, and σ; the paper fixes them globally in experiments, but no sensitivity analysis is shown in the provided text.
- The topology metrics are reported for benchmark structures where connectivity matters, but there is no evidence in the excerpt of robustness under severe distribution shift, adversarial perturbation, or mislabeled topology.
- The TCSP variational module assumes an auxiliary topological feature map v is learnable and meaningful; the excerpt does not show failure cases where v is noisy or mislocalized.
- For skeletonization, the comparison includes SRSP and morphology, but not all likely alternatives in topology-preserving thinning or differentiable skeleton extraction are discussed in the provided excerpt.
Open questions / follow-ons
- How stable is the continuous-tone simple-point surrogate under different α, τ, σ settings, and can these parameters be learned rather than fixed?
- Can the same cyclic-gradient/simple-point relaxation be extended cleanly to 3D volumes, where connectivity and neighborhood topology are more complex?
- How does TCSP interact with modern multi-class segmenters where topology constraints should be class-specific and potentially mutually coupled?
- Can the auxiliary topological map v be supervised more directly, or is there a better way to infer non-removable points without an extra branch?
Why it matters for bot defense
For a bot-defense practitioner, the main lesson is not the segmentation application itself but the design pattern: replace hard, non-differentiable structural constraints with a smooth surrogate that preserves the intended combinatorial property locally. In CAPTCHA or abuse-detection pipelines, that can matter when you want a model to preserve connected strokes, digit topology, or symbol integrity while still training end-to-end on probabilistic outputs.
The caution is equally important: topology-preserving losses can improve structural plausibility without guaranteeing correctness under distribution shift. If you apply the idea to CAPTCHA recognition, document the exact failure modes, especially where the model may overfit to expected stroke connectivity and become brittle to distortions, rotation, blur, or adversarial rendering. The paper’s strongest contribution is the differentiable local-topology construction; the engineering takeaway is to validate it against the hardest realistic shifts, not just aggregate pixel metrics.
Cite
@article{arxiv2604_28159,
title={ Continuous-tone Simple Points: An $\ell_0$-Norm of Cyclic Gradient for Topology-Preserving Data-Driven Image Segmentation },
author={ Wenxiao Li and Faqiang Wang and Yuping Duan and Li Cui and Liqiang Zhang and Jun Liu },
journal={arXiv preprint arXiv:2604.28159},
year={ 2026 },
url={https://arxiv.org/abs/2604.28159}
}