
Are DeepFakes Realistic Enough? Exploring Semantic Mismatch as a Novel Challenge
Source: arXiv:2604.28022 · Published 2026-04-30 · By Sharayu Nilesh Deshmukh, Kailash A. Hambarde, Joana C. Costa, Hugo Proença, Tiago Roxo
TL;DR
This paper tackles a nuanced and underexplored challenge in audio-visual DeepFake detection: semantic mismatch between authentic audio and video streams. Existing detectors typically assume all real audio–real video pairs are semantically consistent, focusing instead on detecting signal-level manipulations or source integrity discrepancies. However, attackers can realistically compose misleading forged multimedia by pairing genuine audio and video from different events or speakers, which contain no synthesis artifacts or lip-sync errors but create semantically false evidence. The authors extend the common four-class DeepFake detection setup by introducing a new class: Real Audio–Real Video with Semantic Mismatch (RARV-SMM), explicitly modeling cross-modal semantic inconsistency.
They create three variants of increasing semantic difficulty by mixing authentic audio-video pairs with differing identity or gender, sourced from VoxCeleb2 and integrated with FakeAVCeleb. Evaluating three state-of-the-art models with distinct detection philosophies—FGMDF (graph attention), FGI (distance-based), and AVDF (lip-sync/self-supervised)—the authors show that models trained only on four-class data fail drastically on the RARV-SMM class, often misclassifying these realistic forgeries as genuine. Training explicitly on the five-class setup improves detection for architectures capable of semantic cross-modal reasoning (FGMDF and FGI), but AVDF relying on lip-sync features gains little. To further enhance semantic reasoning, they introduce a model-agnostic semantic reinforcement strategy by integrating ImageBind embeddings measuring audio-video semantic similarity, which consistently boosts performance on challenging variants and datasets (FakeAVCeleb and LAV-DF). This marks semantic inconsistency as a critical, previously unaddressed vulnerability in current DeepFake detectors.
Key findings
- In the standard 4-class detection setup (RARV, RAFV, FARV, FAFV), FGMDF achieves 99.46% accuracy and near-perfect 99.98% macro AUC on FakeAVCeleb.
- When tested without retraining on 5-class data including RARV-SMM, accuracy drops sharply, e.g., FGMDF accuracy drops from 99.46% to 80.07%, with RARV F1 falling from 92.23% to 17.73%.
- Training explicitly on the 5-class setup recovers performance: FGMDF achieves 98.80% accuracy and 99.88% AUC on FakeAVCeleb, with RARV-SMM F1 of 98.34%.
- The semantic mismatch variants V1 (same identity, different context), V2 (different identity, same gender), and V3 (different gender) progressively reduce performance; FGMDF accuracy drops from 98.80% (V1) to 93.58% (V3).
- AVDF, relying on lip-sync features, cannot significantly improve with 5-class training, maintaining accuracy around 68%, and struggles with semantic mismatches.
- Adding the semantic reinforcement score from pretrained ImageBind embeddings consistently improves results across models and variants, e.g., AVDF accuracy rises from ~68% to ~73%, and FGMDF reaches 98.93% on the hardest variant (V3).
- On the LAV-DF dataset, the 5-class training and semantic reinforcement yields accuracy improvements from ~72% to 92.8%, confirming cross-dataset generalization.
- Misclassification patterns reveal architectural vulnerability types: graph-based models confuse RARV with RARV-SMM, distance-based models confuse RARV and RAFV, and lip-sync models confuse broadly across classes in semantic mismatch.
Threat model
An adversary capable of producing DeepFake content by semantically mismatching authentic audio and video streams—e.g., pairing real audio of one event or person with real video from another, without introducing any synthetic artifacts or lip-sync errors. The adversary cannot modify signals to produce classical detectable artifacts but aims to mislead forensic detectors by exploiting semantic incoherence. The detector’s task is to detect semantic level inconsistency despite source-level authenticity in each modality.
Methodology — deep read
Threat Model & Assumptions: The adversary can create realistic DeepFake manipulations not by signal-level synthesis but by mismatching semantically authentic audio and video from genuine recordings of different events, identities, or genders. The attacker uses no direct signal manipulations, so detection relying solely on artifact or lip-sync inconsistencies will fail. The detector must discern semantic coherence between audio and video content, beyond classical artifact detection or synchronicity checks.
Data: The authors use the VoxCeleb2 dataset as the source to construct the new RARV-SMM samples, harvesting over 5,996 semantically mismatched pairs by pairing authentic audio and video under controlled identity/gender/context constraints. Audio is standardized to 16kHz mono, loudness normalized; video resized to 224x224 at 25fps; durations aligned by truncation or minor speed adjustments preserving authenticity. These new samples merge with the FakeAVCeleb dataset (500 real videos, 19,500 fakes across 500 celebrities) to create a unified five-class dataset.
Three semantic mismatch variants are created: V1 (same identity, different context), V2 (different identity, same gender), and V3 (different gender), with increasing semantic divergence.
- Architectures: They evaluate three state-of-the-art models with fundamentally different detection philosophies:
- FGMDF: graph attention network representing audio and video as heterogeneous nodes with dual cross-graph attention to capture structural and synchrony relations.
- FGI: distance-based detector computing spatial audio-video feature discordance, adapted here from binary to 4-class/five-class detection.
- AVDF: self-supervised model pretrained for audio-visual speech recognition via AV-HuBERT backbone, relying on lip-sync and source-data integrity cues.
For semantic reinforcement, they augment each model’s final classifier by concatenating a precomputed semantic coherence score, computed as the normalized cosine similarity between frozen ImageBind audio and video embeddings (each 1024 dimensional). ImageBind is not fine-tuned; scores are fixed features added to model embeddings before classification.
- Training Regime: Training is done separately for 4-class and 5-class settings using PyTorch on NVIDIA GPUs. Specifics:
- FGMDF: 20 epochs, batch size 16, Adam optimizer at lr=1.1e-3, StepLR decay, class-weighted cross-entropy.
- FGI: Up to 100 epochs, batch size 32, Adam at lr=1e-4, early stopping.
- AVDF: Up to 30 epochs, batch size 64, Adam at lr=2e-4, early stopping. Random seed fixed at 42.
- Evaluation Protocol: Metrics include overall accuracy, macro-averaged AUC (one-vs-rest), and per-class precision, recall, and F1-score to capture class imbalance effects. They evaluate:
- Baseline 4-class detection accuracy on FakeAVCeleb.
- Zero-shot testing of 4-class trained models on 5-class test data (RARV-SMM) revealing performance degradation and misclassification patterns.
- Full 5-class retraining to assess models’ capacity to learn semantic mismatch.
- Performance analyzed on the three semantic mismatch variants (V1, V2, V3).
- Semantic reinforcement effectiveness by adding ImageBind similarity.
- Cross-dataset validation on LAV-DF to test generalization.
- Reproducibility: Source code and data are provided publicly (GitHub link in paper) allowing replication. ImageBind embeddings are fixed and precomputed, model weights and training protocols are described clearly.
Technical innovations
- Introduction of a novel five-class audio-visual DeepFake detection formulation that explicitly models semantic mismatch between authentic audio and video (RARV-SMM), extending beyond signal-level manipulation detection.
- Construction of three semantic mismatch variants (V1, V2, V3) using VoxCeleb2 authentic pairs with controlled identity and gender variations to systematically evaluate semantic divergence challenges.
- Proposal of a model-agnostic semantic reinforcement strategy that incorporates frozen ImageBind audio-video embeddings cosine similarity as an explicit semantic coherence score augmenting existing model classifiers.
- Comprehensive diagnostic evaluation revealing how different DeepFake detection architectures (graph-based, distance-based, lip-sync-based) exhibit distinct vulnerabilities to semantic mismatch manipulations.
Datasets
- FakeAVCeleb — 20,000+ samples (500 real + 19,500 fake videos) — public benchmark constructed from VoxCeleb
- VoxCeleb2 — >1 million utterances from 6,112 speakers — source for authentic semantic mismatch pairs (5,996 RARV-SMM samples generated)
- LAV-DF — ~136,000 clips (36,431 real + 99,873 fake) — public content-driven audio-visual forgery benchmark
Baselines vs proposed
- FGMDF: 4-class ACC = 99.46%, AUC = 99.98% vs proposed 5-class ACC = 98.80%, AUC = 99.88%
- FGI: 4-class ACC = 95.15%, AUC = 98.98% vs 5-class ACC = 91.18%, AUC = 98.15%
- AVDF: 4-class ACC = 87.00%, AUC = 97.47% vs 5-class ACC = 67.65%, AUC = 90.44%
- With semantic reinforcement: FGMDF ACC on V3 rises from 93.58% to 98.93%; AVDF ACC on V3 rises from 61.61% to 73.0%
- On LAV-DF: Baselines achieve ACC ~65-72%; proposed 5-class + semantic FGMDF achieves 92.80% ACC, 99.15% AUC
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.28022.
Fig 1: Illustration of the proposed threat: a four-class DeepFake
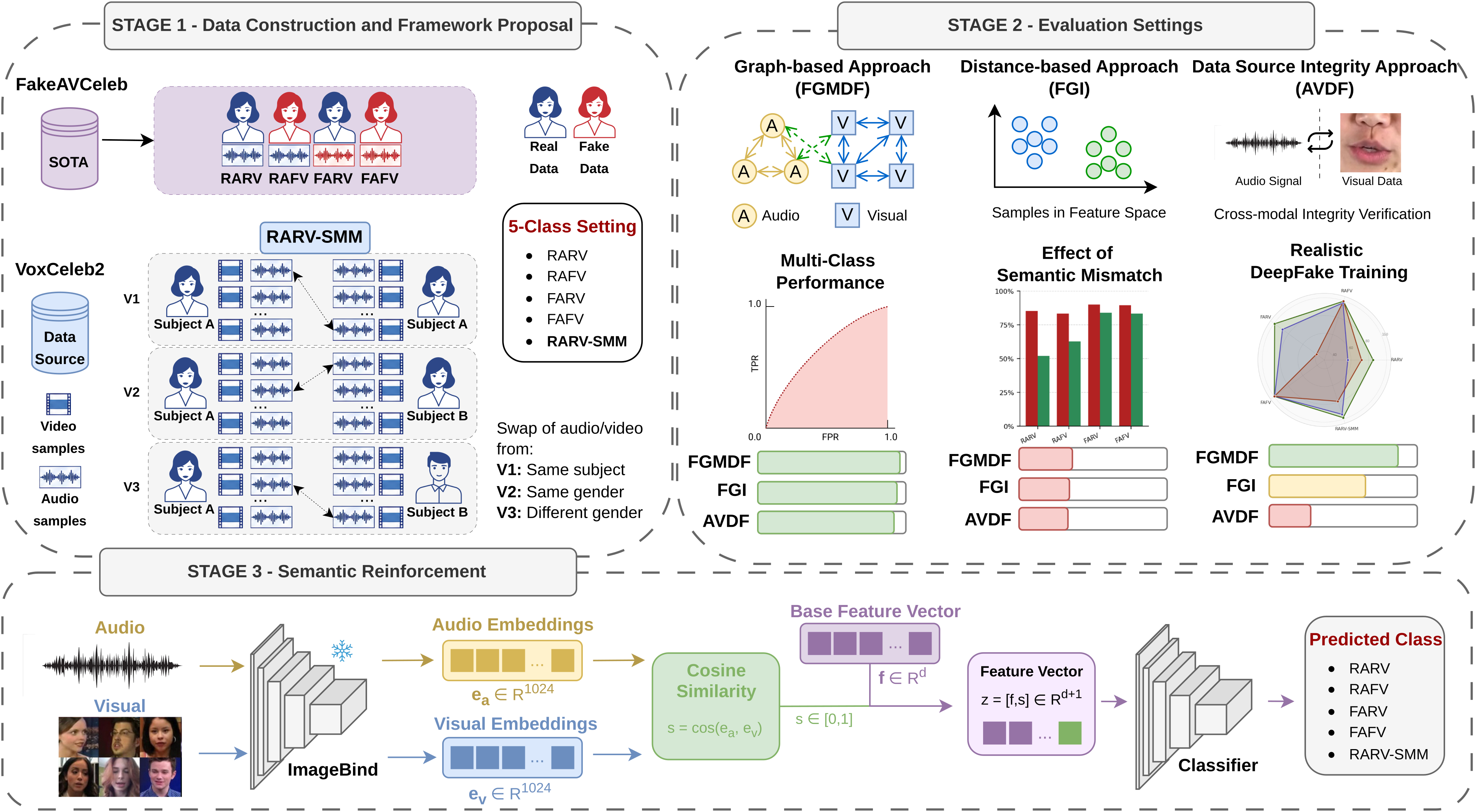
Fig 2: Overview of the proposed five-class audio-visual DeepFake detection framework. Stage 1 constructs RARV-SMM samples

Fig 3: Illustration of the proposed RARV-SMM variants. V1:
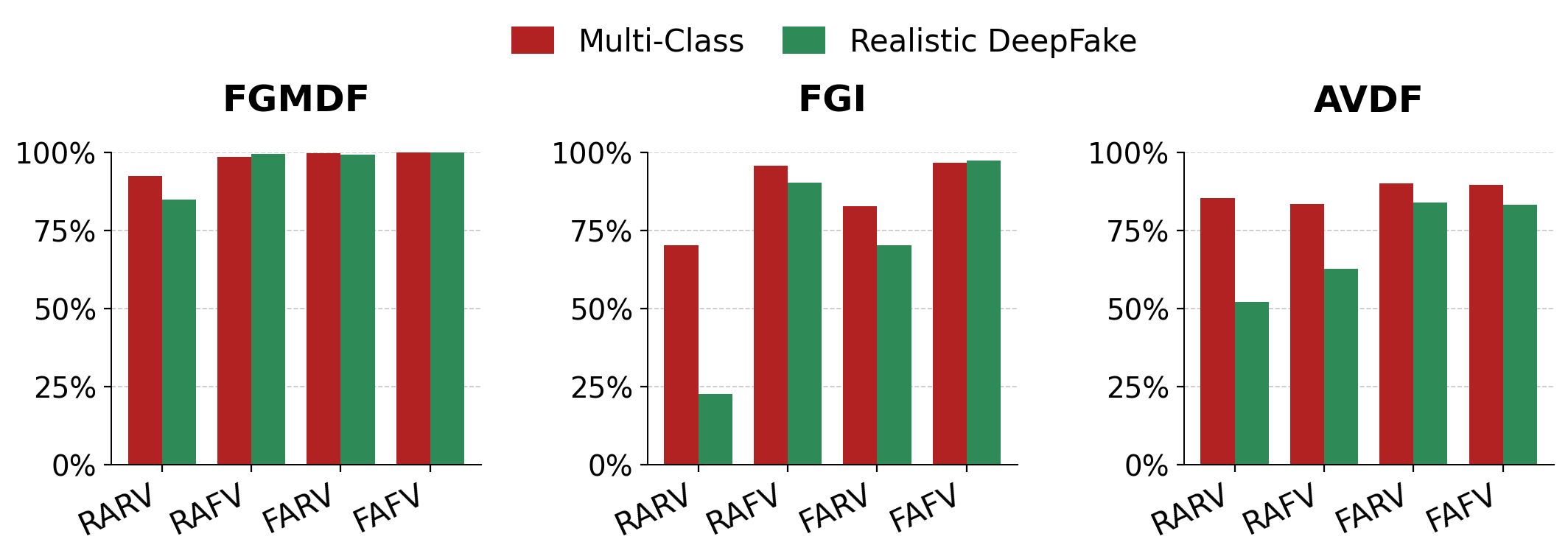
Fig 4: Per-class F1 comparison between Multi-Class and Real-
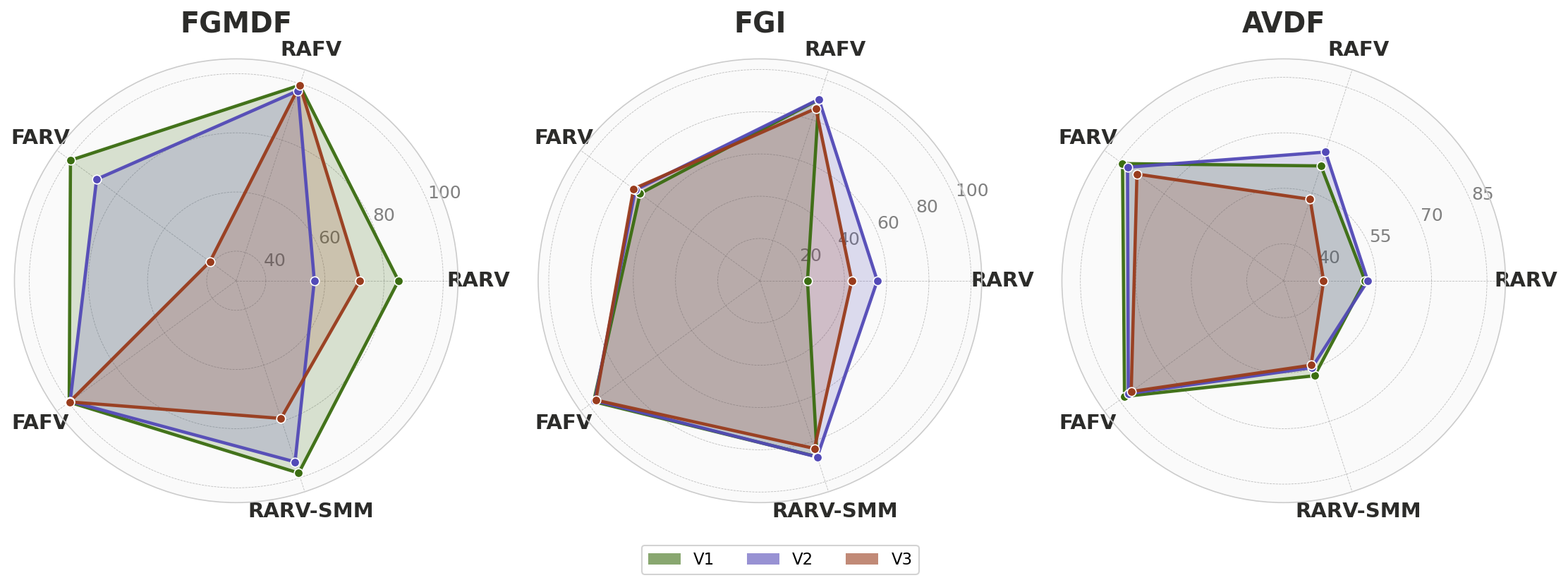
Fig 5: Per-class F1 profiles across V1, V2 and V3 for FGMDF, FGI, and AVDF. Each axis represents one class; a larger polygon
Limitations
- Semantic mismatch detection capacity relies on the model’s architecture: AVDF’s lip-sync based approach inherently cannot reliably detect semantic inconsistencies even with supervision.
- The semantic reinforcement strategy uses frozen ImageBind embeddings, which may limit adaptability and full exploitation of semantic features in end-to-end learning.
- Experimentation is restricted to two datasets (FakeAVCeleb and LAV-DF) and VoxCeleb2 samples for semantic mismatch construction; generalization to other naturalistic datasets remains to be tested.
- The semantic mismatch class variants are synthetic constructs (pairing audio and video from different times, identities, or genders) rather than naturally occurring semantic forgeries; real-world adversaries may use more subtle or different tactics.
- No explicit adversarial attacks or robustness testing against adaptive attackers attempting to evade semantic detectors were conducted.
- The approach focuses on classification metrics without exploration of interpretability or explicit reasoning over semantic content, which remains an open architectural challenge.
Open questions / follow-ons
- How can architectures be designed to explicitly reason about narrative coherence, identity consistency, and cross-modal semantics beyond current graph or distance-based approaches?
- Can self-supervised or contrastive pretraining be adapted to encode semantic alignment between audio and video to improve semantic mismatch detection?
- How robust are semantic mismatch detection models to adversarial attacks that attempt to subtly hide inconsistencies or mimic semantic coherence artificially?
- What is the impact of incorporating semantic mismatch detection into deployed binary DeepFake detectors on real-world datasets featuring naturally occurring semantic manipulations?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners aiming to detect manipulated multimedia used for impersonation or misinformation, this paper highlights a critical and overlooked class of DeepFake threats: semantic mismatches between authentic audio and video. Traditional artifact or lip-sync based detectors will fail to flag such content as manipulated, elevating the risk of wrongful acceptance of falsified evidence.
Integrating semantic-level inconsistency detection—ideally through cross-modal embeddings like ImageBind or architectures capable of semantic reasoning—can substantially raise the bar against realistic forgery strategies. The introduced five-class formulation and semantic reinforcement strategy provide practical pathways to enhance model robustness and forensic fidelity beyond existing binary or four-class systems. However, challenges remain for simpler architectures reliant on signal-level cues. This work suggests future bot-defense solutions should incorporate semantic alignment signals and develop architectures capable of cross-modal narrative coherence assessment to detect sophisticated DeepFakes that evade classical methods.
Cite
@article{arxiv2604_28022,
title={ Are DeepFakes Realistic Enough? Exploring Semantic Mismatch as a Novel Challenge },
author={ Sharayu Nilesh Deshmukh and Kailash A. Hambarde and Joana C. Costa and Hugo Proença and Tiago Roxo },
journal={arXiv preprint arXiv:2604.28022},
year={ 2026 },
url={https://arxiv.org/abs/2604.28022}
}