
Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction
Source: arXiv:2604.27221 · Published 2026-04-29 · By Yuxuan Huang, Yihang Chen, Zhiyuan He, Yuxiang Chen, Ka Yiu Lee, Huichi Zhou et al.
TL;DR
This paper addresses the challenge of agentic web search that must handle two distinct modes: deep reasoning over individual targets and broad, structured aggregation across many entities from heterogeneous web sources. Existing systems struggle to balance these competing demands, especially at internet scale. The authors propose Web2BigTable, a bi-level multi-agent framework where an upper-level orchestrator decomposes complex queries into subtasks, and a pool of lower-level worker agents execute these subtasks in parallel. These agents coordinate asynchronously via a shared, human-readable Markdown workboard, enabling dynamic adaptation to coverage gaps, redundancy avoidance, and conflict resolution. Both the orchestrator's decomposition strategies and the workers' execution skills self-evolve over time via a closed-loop run–verify–reflect process using persistent external memory, all while keeping the underlying LLM weights frozen. Evaluation on two benchmarks—WideSearch for broad entity coverage and XBench-DeepSearch for multi-hop reasoning—shows state-of-the-art improvements, with WideSearch Success Rate of 38.50 (7.5× better than previous best), Row F1 of 63.53 (+25.03), and Item F1 of 80.12 (+14.42). The approach also generalizes effectively to deep search with 73.0 accuracy on XBench-DeepSearch. The released code facilitates further research.
Key findings
- On WideSearch, Web2BigTable achieves Avg@4 Success Rate of 38.50, a 7.5× improvement over the second-best system at 5.10.
- Row F1 on WideSearch is 63.53, surpassing the second-best result by 25.03 points.
- Item F1 on WideSearch reaches 80.12, improving on the second-best baseline by 14.42 points.
- Generalizes to deep reasoning tasks, achieving 73.0 accuracy on XBench-DeepSearch without task-specific adaptation.
- The bi-level architecture enables decomposition and parallel execution without context window saturation by partitioning subtasks and histories.
- The shared Markdown-format workboard supports asynchronous coordination, reducing redundant exploration and enabling dynamic coverage gap detection.
- Self-evolving skill banks for orchestrator decomposition and worker execution skills are updated via an LLM-driven run–verify–reflect pipeline over multiple training episodes.
- The underlying LLM weights remain frozen; adaptation happens entirely through the monotone addition of human-readable skill files.
Threat model
The system assumes a benign environment of open web search and information extraction. The adversary is not explicitly modeled, but the task must handle heterogeneous, noisy, and contradictory information from internet-scale sources. The attackers cannot alter the internal memory or skill files during inference, as the model weights and skill banks are frozen. Thus, the threat model centers around robustness to imperfect web data rather than active adversarial inputs.
Methodology — deep read
The paper studies web-to-table search, where given a natural-language query and a target schema, the system must autonomously search the open web and return a structured table whose rows correspond to entities and columns to attributes, with each cell grounded in verified web evidence. This task requires breadth (wide entity coverage) and/or depth (multi-hop reasoning) depending on the query. The threat model is not explicitly adversarial but assumes internet-scale, heterogeneous, noisy data. The system is a two-level multi-agent framework:
The upper-level orchestrator LLM decomposes the user query into subtasks using learned decomposition strategies (skills). This step evaluates the query type and complexity, and partitions it into self-contained subtasks (e.g., by entity segments or temporal slices). The orchestrator conditions this decomposition on long-term skill memory (So), representing accumulated successful structural strategies.
A pool of lower-level worker agents run asynchronously and in parallel, each receiving a subtask and executing it using shared worker skills (Sw). Each worker operates using a ReAct style reasoning loop with LLM plus tool use, invoking external retrieval and parsing the web. Their contexts are isolated to reduce context window saturation.
Workers interact through a shared short-term working memory called the workboard (me), a Markdown-based document partitioned into tagged sections per worker plus shared context and a global checklist. Workers read all partial results and update their own sections under file locks, enabling asynchronous coordination. This facilitates redundancy avoidance (workers skipping covered entities), coverage gap detection (finding missing attributes), and evidence reconciliation.
Training proceeds episodically on a small split of queries with gold tables. For each episode, an inference run produces a candidate output table. This is compared cell-wise against ground truth, using exact, numeric tolerance, normalized URL, and semantic LLM judgement depending on attribute type. An error report is distilled capturing missing entities, low-accuracy columns, and trajectory anomalies.
Two separate LLM-driven reflect pipelines then generate updated orchestrator decomposition skills (So) and worker execution skills (Sw), both stored as human-readable SKILL.md files appended monotonically. This runs over multiple episodes, incrementally improving strategies without any gradient updates or fine-tuning of the underlying frozen LLMs.
At inference time, the frozen skill banks are used, and a single forward pass decomposes the query and concurrently executes subtasks to produce the final table.
To illustrate one example end-to-end: a complex query is input and first sent to the orchestrator, which chooses one of several structural decomposition skills to split into, say, 10 subtasks covering temporal slices of entities. These subtasks are dispatched to 10 parallel workers, each using relevant execution skills to search the web tools and construct their partial table segment. Workers frequently check the shared workboard to avoid overlap and patch gaps. Once all workers complete, results are aggregated into a global table output. During training, any discrepancies trigger reflection to update skill banks.
Evaluation uses WideSearch for broad coverage and XBench-DeepSearch for deep reasoning. Metrics include Avg@4 Success Rate, Row F1, and Item F1 for wide search, and accuracy for deep search. The system is compared to prior SOTA multi-agent and end-to-end baselines. No cross-validation or adversarial robustness tests are reported. Code and frozen skill files are released publicly to enable reproducibility, though full training details on hardware and random seeds are not fully enumerated in the paper.
Technical innovations
- Bi-level multi-agent architecture with an upper-level LLM orchestrator that decomposes queries and lower-level LLM-powered worker agents executing subtasks in parallel using shared external memory.
- Closed-loop run–verify–reflect learning pipeline that self-evolves both task decomposition and worker execution skills through monotone updates to human-readable skill files, without fine-tuning underlying LLM weights.
- Shared Markdown-format workboard enabling asynchronous, non-destructive coordination among concurrent workers for visibility into partial findings, redundancy avoidance, conflict resolution, and dynamic coverage adaptation.
- Memento-Skills mechanism integrating exact skill matching, semantic retrieval over a large skill catalog, and on-demand LLM synthesis of new skills at runtime with automatic AST validation and error-driven autonomous self-repair.
Datasets
- WideSearch — size unspecified — public benchmark for broad-coverage web-to-table search
- XBench-DeepSearch — size unspecified — public benchmark for deep multi-hop web search
Baselines vs proposed
- Second-best WideSearch system: Avg@4 Success Rate = 5.10 vs Web2BigTable: 38.50
- Second-best WideSearch system: Row F1 = 38.50 vs Web2BigTable: 63.53
- Second-best WideSearch system: Item F1 = 65.70 vs Web2BigTable: 80.12
- Baseline on XBench-DeepSearch: accuracy unspecified vs Web2BigTable: 73.0
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.27221.
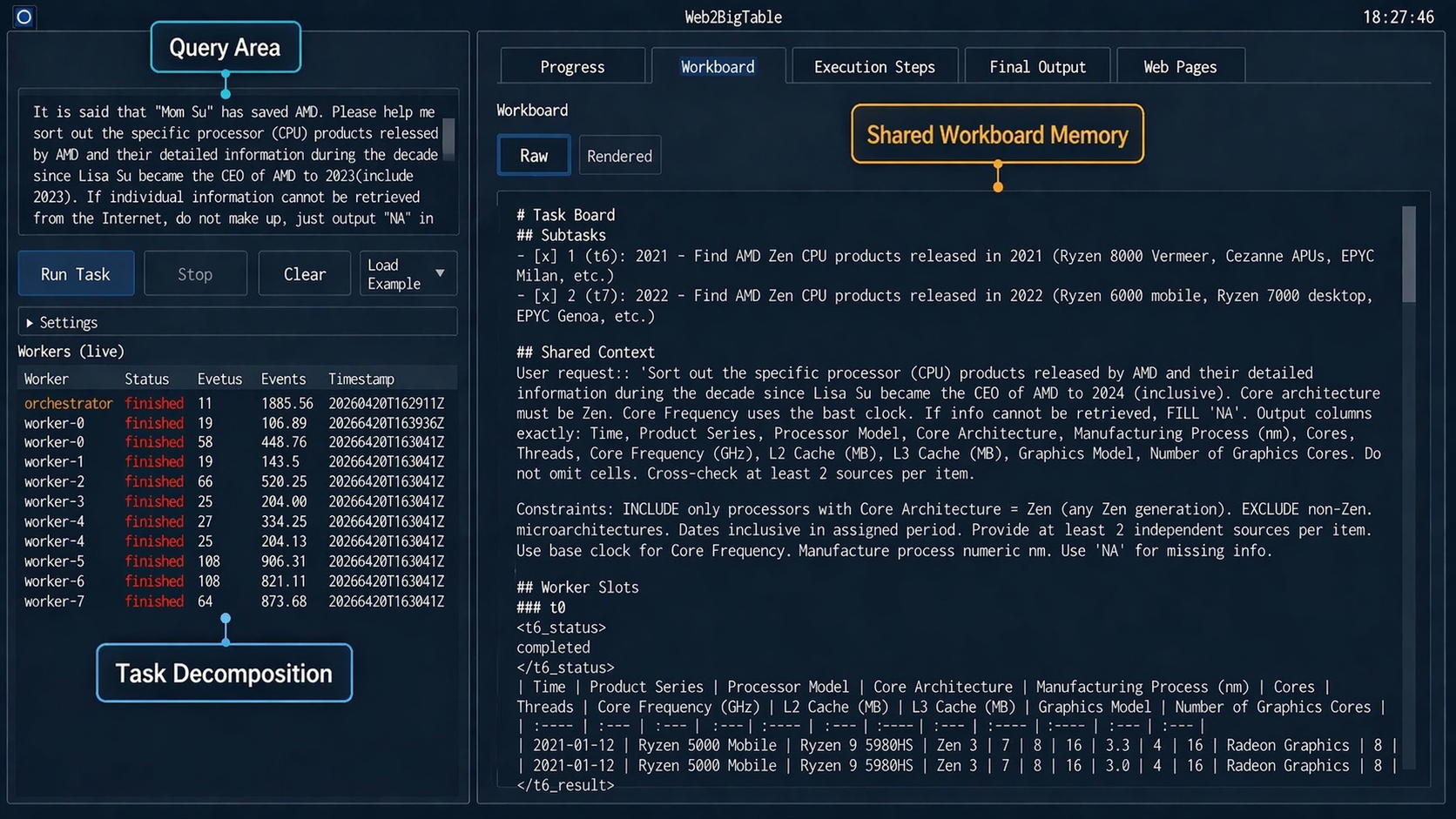
Fig 1: Web2BigTable interface during query execution. The left panel displays the user query

Fig 2: Architecture of Web2BigTable, a unified training and inference framework. The

Fig 3 (page 3).

Fig 4 (page 3).
Fig 5 (page 3).

Fig 6 (page 3).

Fig 7 (page 3).
Limitations
- Training relies on a small set of queries paired with gold tables, which may limit generalization to truly open-ended web queries.
- No explicit evaluation under adversarial conditions or input perturbations was reported.
- The skill bank update mechanism adds monotone skills which could grow unbounded without pruning or compression strategies.
- Detailed hardware specs, random seeds, and hyperparameter tuning protocols are not fully disclosed, potentially impacting reproducibility.
- No user study or latency/throughput analysis for practical deployment scenarios was provided.
- Evaluation focuses on accuracy metrics; resource and cost efficiency remain unexplored.
Open questions / follow-ons
- How to scale skill bank maintenance long-term without unmanageable growth or redundancy?
- What are the robustness limits under adversarial or intentionally misleading web content?
- Can the self-evolving skill mechanisms be extended to online learning with user feedback in real time?
- What are the computational and latency trade-offs for deploying such multi-agent systems at internet scale?
Why it matters for bot defense
Bot-defense and CAPTCHA systems often require structured verification of user interactions and the detection of automation over complex web tasks. Web2BigTable’s bi-level multi-agent approach offers new insights into how large language models can decompose and coordinate complex tasks via external memory without fine-tuning, which could inspire more adaptive, scalable bot-detection pipelines. The shared workboard mechanism for asynchronous coordination could also be adapted to orchestrate multiple detection signals or agents verifying user behavior at scale.
Moreover, the run–verify–reflect self-improvement loop clarifies a pathway for continually refining detection heuristics or puzzle generation strategies based on real-world feedback without retraining core models. However, the paper focuses on information retrieval accuracy rather than adversarial robustness or latency, so further adaptations would be needed before direct application in security-sensitive CAPTCHA or bot mitigation contexts.
Cite
@article{arxiv2604_27221,
title={ Web2BigTable: A Bi-Level Multi-Agent LLM System for Internet-Scale Information Search and Extraction },
author={ Yuxuan Huang and Yihang Chen and Zhiyuan He and Yuxiang Chen and Ka Yiu Lee and Huichi Zhou and Weilin Luo and Meng Fang and Jun Wang },
journal={arXiv preprint arXiv:2604.27221},
year={ 2026 },
url={https://arxiv.org/abs/2604.27221}
}