
Indirect Prompt Injection in the Wild: An Empirical Study of Prevalence, Techniques, and Objectives
Source: arXiv:2604.27202 · Published 2026-04-29 · By Soheil Khodayari, Xuenan Zhang, Bhupendra Acharya, Giancarlo Pellegrino
TL;DR
This paper presents the first large-scale empirical study of indirect prompt injection attacks embedded in web content, which are instructions inserted by site owners or adversaries into webpages or HTTP responses that attempt to influence large language models (LLMs) consuming that data. By analyzing 1.2 billion URLs across 24.8 million hosts, the authors identify over 15,000 validated prompt injection instances spanning 11,700+ pages, revealing that indirect prompt injection is already widespread and organized around a small set of recurring lexical templates. The injected prompts serve diverse objectives including system disruption, reputation manipulation, data protection, and AI-bot identification, prominently targeting automated agents like crawlers, search engines, customer support, and hiring workflows. Most prompts are machine-targeted and hidden in non-rendered HTML contexts. Controlled experiments on 13 LLMs with 5,200 trials found compliance rates up to 8% with plain-text inputs, dropping significantly with structured page representations that preserve semantic cues. Overall, this research uncovers a heterogeneous and persistent ecosystem of web-based prompt injections, showing practical risk of unintended LLM behavior from untrusted web data ingestion.
Key findings
- Analyzed 1.2 billion URLs from 24.8 million hosts, finding 15,387 validated prompt injection instances across 11,722 pages and 2,042 hosts
- A small set of 54 lexical templates accounts for 95% of all prompt injection cases, showing high reuse and structural regularity
- About 70% of prompt injections appear in non-rendered HTML such as headers, metadata, or comments, often hidden using CSS (display:none, font size zero) or rendering tricks
- Prompt injection objectives cluster into six categories: System Disruption/Degradation (largest, 8,894 instances), Reputation Manipulation (1,521), Data Protection (4,093), AI Bot Identification (3,096), Data Exfiltration (rare, 13), and Generic Content Override (2,632)
- Automated crawlers and data scrapers are the dominant agents targeted by prompt injections, especially for data protection and disruption; search agents are targeted mainly by reputation manipulation prompts
- Controlled experiments across 13 LLMs and four page input formats show prompt compliance peaks at 8% for smaller models on plain-text inputs but falls to 0.2%–1.1% when structural webpage cues are preserved
- Prompt injections are unevenly distributed, concentrated heavily on certain hosts (max 2,180 injections on a single host) and topics such as job listings and marketplaces
- Nearly all injections try direct task overrides, with 43% incorporating jailbreak-style language to subvert model instructions
Threat model
The adversary is a webpage or internet resource owner, contributor, or attacker who can embed arbitrary prompt-like instructions into HTTP responses or webpage content. They seek to influence downstream LLM-based web agents that ingest this data as input combined with developer instructions. The adversary cannot break cryptographic or sandboxing protections to modify trusted developer prompts themselves but relies on the LLM's inability to distinguish trusted instructions from untrusted web content. The adversary depends on techniques like direct task overrides, jailbreak language, or role-playing within the untrusted data to subvert the agent. They cannot (generally) control the model architecture or inference process but exploit weak boundaries between data and instruction in prompt composition.
Methodology — deep read
The study begins by defining the threat model as large language model (LLM) web agents that combine trusted developer instructions with untrusted third-party web content, making them vulnerable to indirect prompt injection from malicious or adversarial web inputs. The adversary includes website owners, contributors, or attackers who embed prompt-like instructions into webpages or HTTP response headers aimed to manipulate LLM behavior. The authors aim to measure prevalence, objectives, deployment, and effectiveness of prompt injections at web scale.
Data was collected primarily from three sources: Common Crawl (a public web corpus covering 1.2 billion unique URLs from 24.8 million hosts), plus Shodan and Censys internet asset scanning datasets, which add 3,346 additional snapshots. Processing was distributed over 50 parallel workers to handle the magnitude of data (~200 TiB uncompressed). For Common Crawl, they used the October 2025 snapshot.
Identifying prompt injections started from a large manual seed set of 3,963 prompt injection indicators (key phrases and stylistic variants of known injection patterns like "ignore previous instructions"). Instead of expensive ML-based detection, they used the efficient multi-pattern Aho-Corasick algorithm to find occurrences of these indicators across the web corpus. This yielded 31,206 candidate matches.
To confirm true injections among these candidates, a semi-automated validation pipeline grouped matches by string and context, then involved manual review steps: conservative acceptance of HTTP header matches, inspection of random samples of groups to exclude benign uses (tutorials, code samples), propagation of labels by structural similarity and topic, review of rendering visibility (including hidden content), and individual instance validation by two annotators in disjoint partitions. Inter-annotator agreement was established via repeated sampling and discussion. This process produced 15,387 validated prompt injection instances.
For downstream analysis, the authors extracted clean prompt strings and normalized them (HTML decoding, lowercasing, punctuation removal), replacing variables with placeholders to form lexical templates. Clustering on token overlap with a threshold of 0.75 identified 363 distinct templates, with heavy skew: 54 templates cover 95% of injections.
Semantic clustering used MiniLM embeddings and DBSCAN clustering with manual coding to assign objective and target labels, supported by a natural language inference (NLI) model to detect prompting techniques (e.g., jailbreak, role play).
For effectiveness evaluation, the study ran 5,200 controlled experiments involving 13 diverse LLMs, across four webpage input representations (raw text, markup-preserving, etc.) measuring compliance rates to injected instructions.
Evaluation involved aggregating injection counts per host, per web topic category, and checking temporal persistence across snapshots. Limitations in coverage (missed unlinked resources), approximate initial filtering, and subjective manual validation are acknowledged. No closed-source data or final code release is indicated; reproducibility would rely on access to Common Crawl and annotation guidelines.
Technical innovations
- Web-scale identification of indirect prompt injection via efficient multi-pattern string matching on 1.2B URLs with extensive manual validation
- Lexical template extraction combining string normalization and token overlap clustering to reveal prompt injection reuse patterns at scale
- Semantic clustering of prompt injection objectives and targets using MiniLM embeddings and DBSCAN with manual qualitative coding
- Use of natural language inference (NLI) model to detect nuanced prompting techniques like jailbreak and role-play beyond surface keywords
- Controlled multi-model evaluation of prompt injection compliance across varied webpage input representations to quantify practical impact
Datasets
- Common Crawl CC-MAIN-2025-43 — 1.2 billion URLs from 24.8 million hosts — public
- Shodan snapshots — 541 candidate pages — non-public
- Censys snapshots — 2,805 candidate pages — non-public
Baselines vs proposed
- Baseline: raw plain-text page input compliance to prompt injection — max 8% compliance for smaller models
- Baseline: structured representations preserving page markup — compliance drops to 0.2%–1.1%
- Baseline: detection via previous naive ML or perplexity-based methods — rejected due to computational cost, replaced with keyword filtering
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.27202.
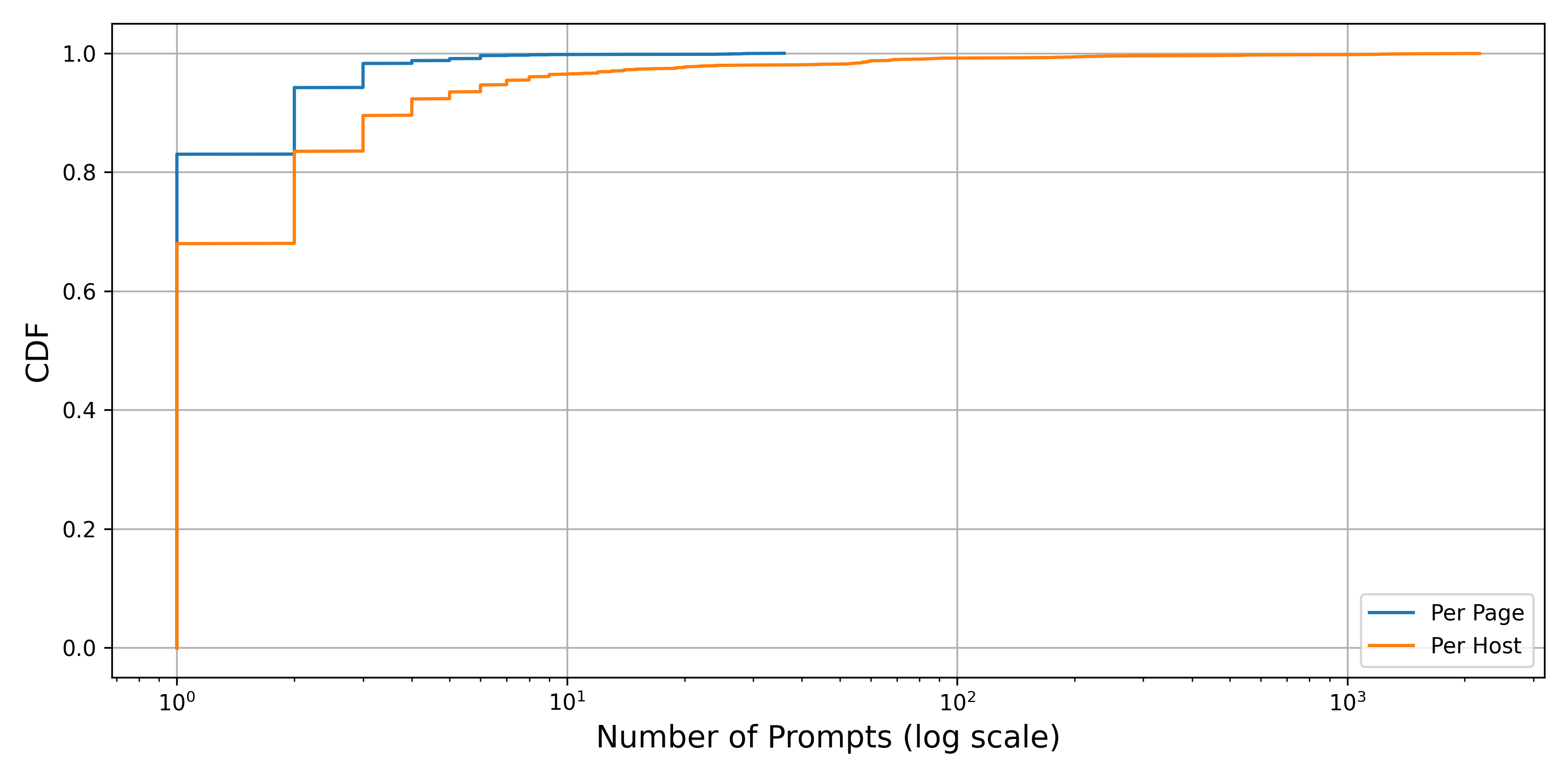
Fig 3: Distribution of prompt injections per page and host.
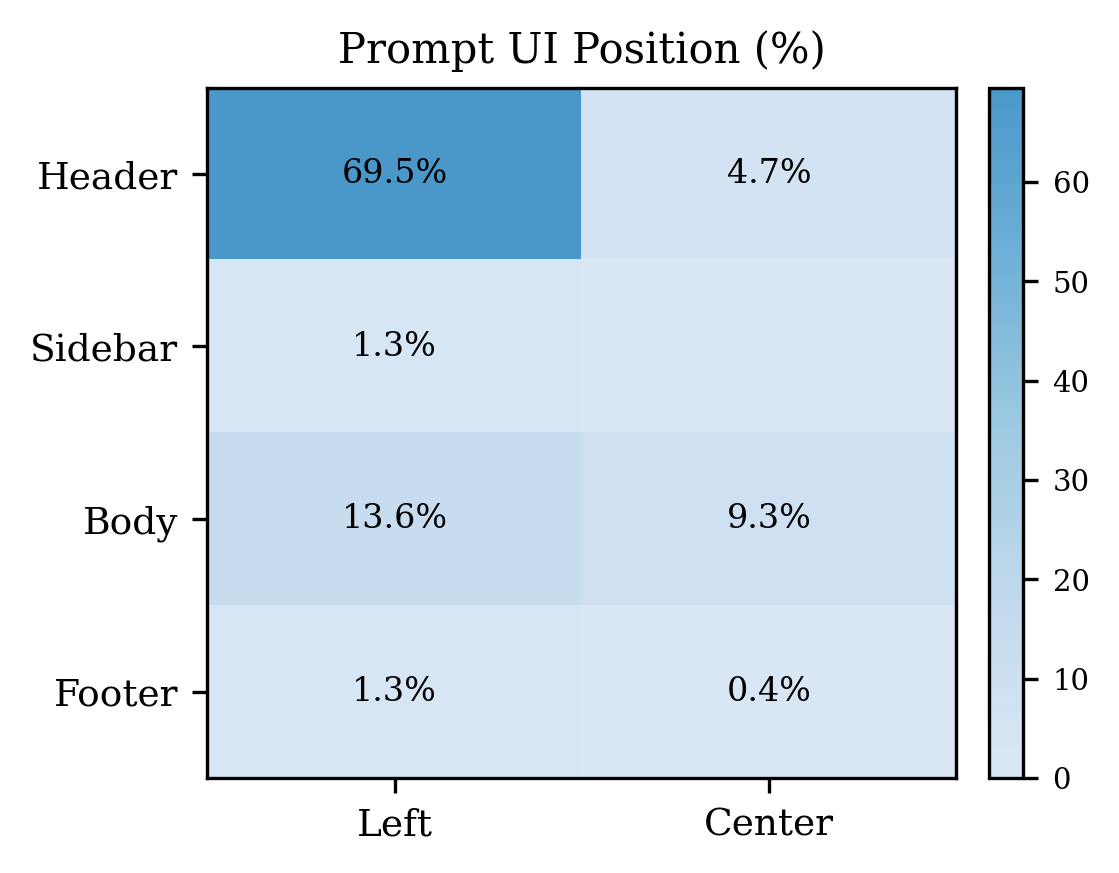
Fig 4: Spatial distribution of visible prompt injections
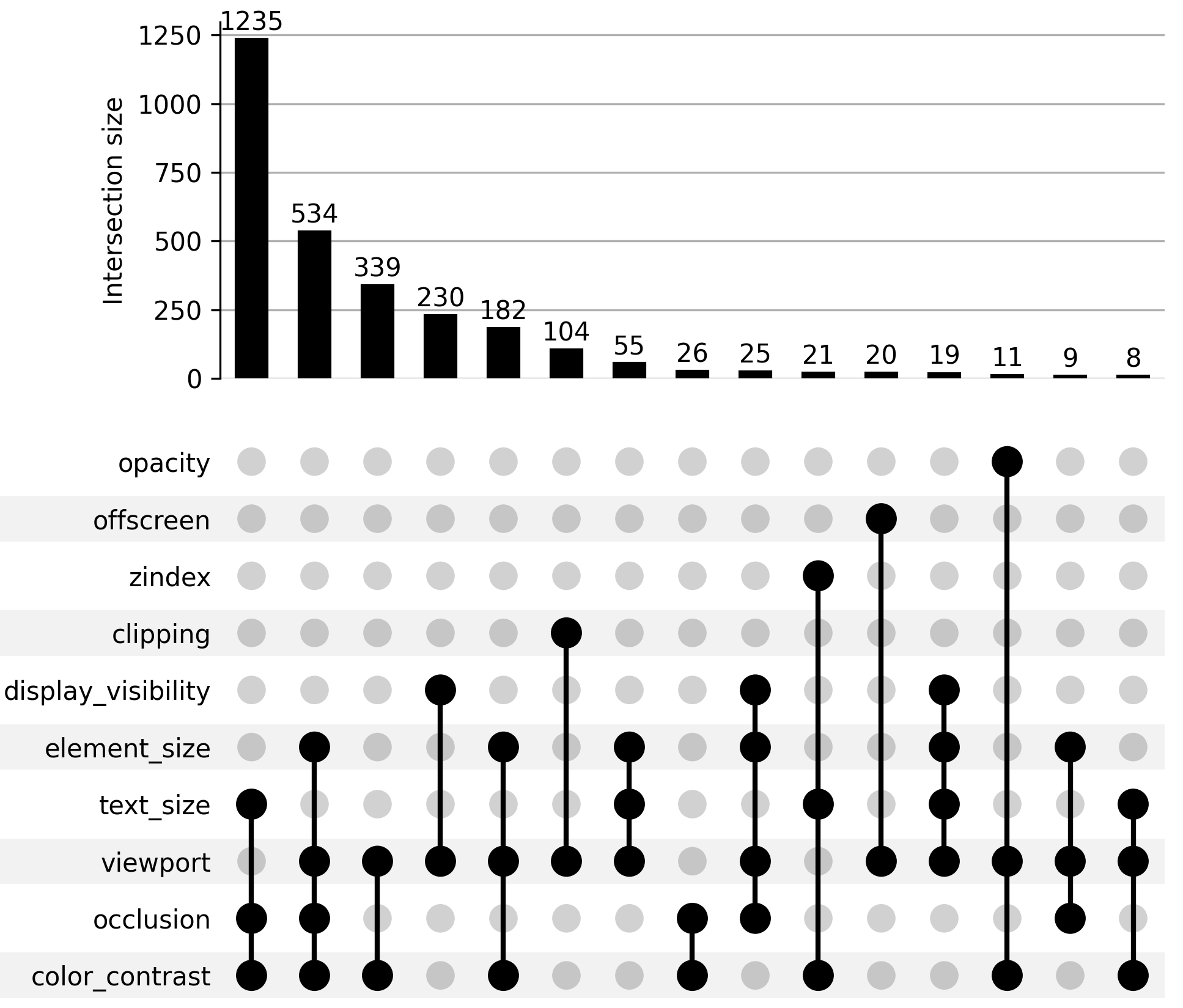
Fig 5: Top technique combinations for hiding prompt
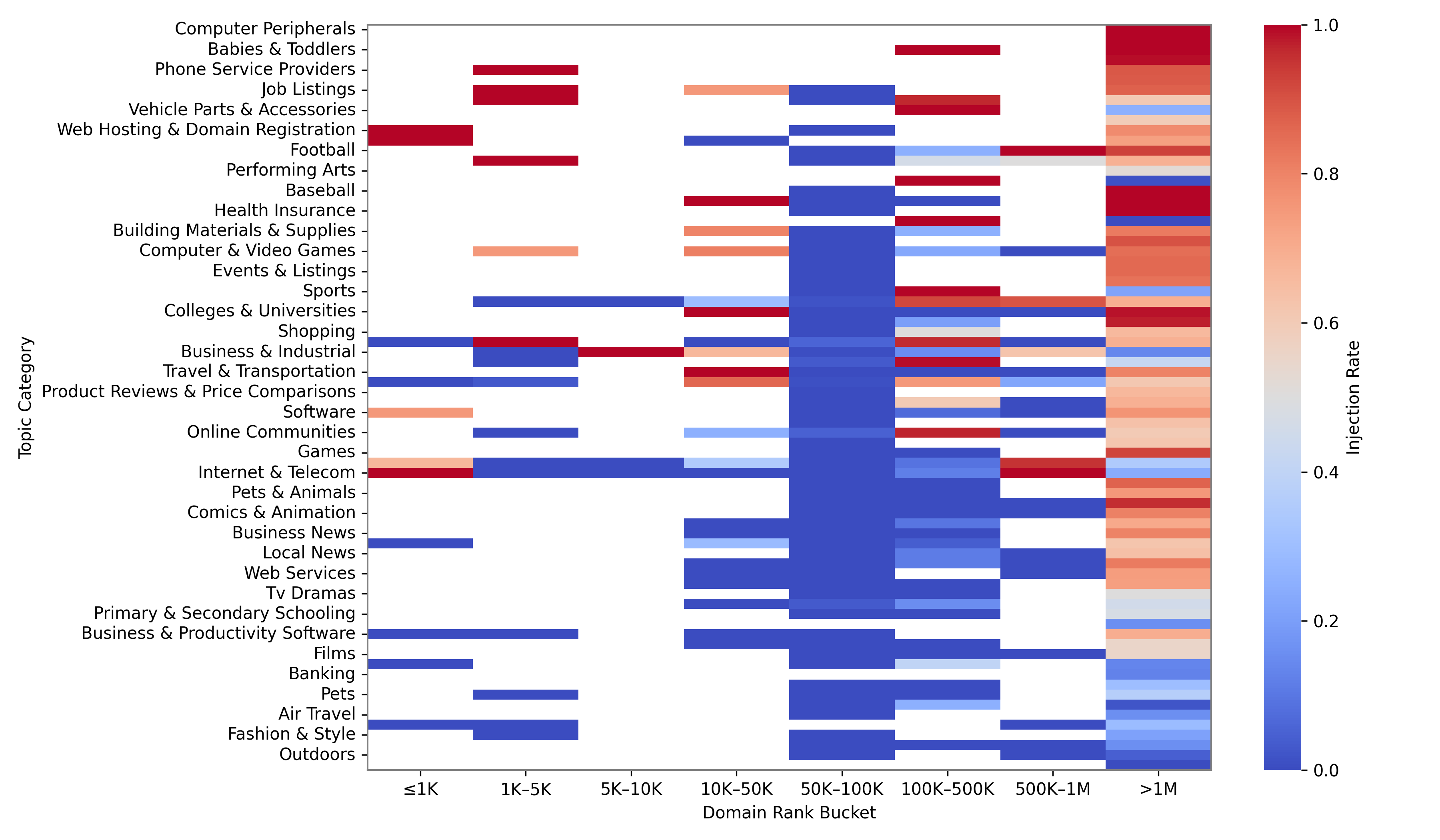
Fig 6: Prompt injection rate across domain topic categories and Tranco rank buckets.
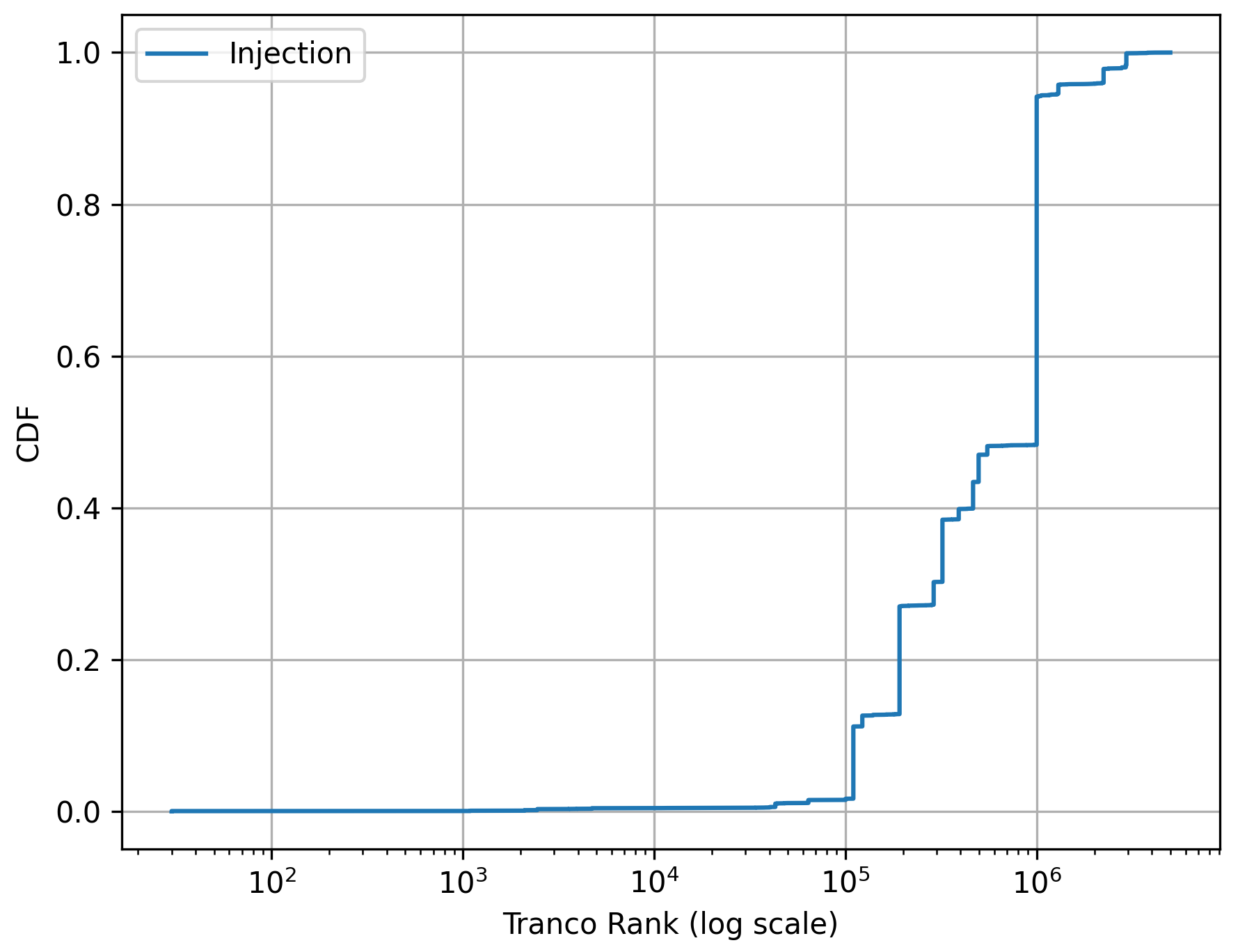
Fig 8: Cumulative distribution function (CDF) of Tranco
Limitations
- Keyword-based filtering risks false negatives as it may miss injection variations outside known indicator patterns
- Validation depends on manual review, introducing subjectivity and potential inconsistency despite inter-annotator agreement efforts
- Dataset coverage limited to Common Crawl, Shodan, and Censys snapshots, may miss private, behind-auth, or low-link pages
- Effectiveness evaluation limited to 13 LLMs and four input variants; results may vary with other models or updated prompt injection techniques
- No adversarial testing of adaptive attackers who may change injection styles dynamically
- No longitudinal measurement beyond one crawl snapshot; persistence over longer time is uncertain
Open questions / follow-ons
- How can LLM-based web agents robustly separate trusted developer instructions from untrusted web content to prevent indirect prompt injection?
- What representations or architectural changes can improve LLM robustness to hidden or obfuscated prompts within markup-rich web inputs?
- Can automated detection and mitigation systems identify and filter prompt injections in live web crawling pipelines at scale?
- How do evolving adversarial prompt injection techniques adapt in response to defenses such as structural preservation or prompt sanitization?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper highlights a novel, emerging vector of manipulation where LLM-based automated web agents ingest instructions clandestinely embedded in webpages, beyond traditional interaction metrics. Understanding the characteristics of indirect prompt injection—its prevalence, template reuse, and targeting of crawlers, search pipelines, or customer support bots—provides insight into how adversaries might deform or bias automated responses or data collection. This suggests that defense strategies might include incorporating structural page representations that preserve semantic cues or applying detection filters on retrieved web content before feeding it to LLMs. Moreover, prompt injection may complicate automated bot detection or reputation systems embedded in web content, necessitating multi-layered defense combining input sanitation with behavior-level CAPTCHAs or interaction constraints. Practitioners should consider indirect prompt injection as a vector for attacker influence that can cause subtle, non-human-visible shifts in automated workflows, requiring holistic mitigation beyond standard CAPTCHA challenges.
Cite
@article{arxiv2604_27202,
title={ Indirect Prompt Injection in the Wild: An Empirical Study of Prevalence, Techniques, and Objectives },
author={ Soheil Khodayari and Xuenan Zhang and Bhupendra Acharya and Giancarlo Pellegrino },
journal={arXiv preprint arXiv:2604.27202},
year={ 2026 },
url={https://arxiv.org/abs/2604.27202}
}