
GIFGuard: Proactive Forensics against Deepfakes in Facial GIFs via Spatiotemporal Watermarking
Source: arXiv:2604.26519 · Published 2026-04-29 · By Shupeng Che, Zhiqing Guo, Changtao Miao, Dan Ma, Gaobo Yang
TL;DR
GIFGuard addresses a gap in proactive forensics: existing watermarking-based defenses are mostly built for static images, so they do not model the temporal structure of GIFs and they break under deepfake-style semantic reconstruction. The paper’s core idea is to treat a GIF as a spatiotemporal volume and embed a watermark into regions that remain stable through both GIF compression and face-reconstruction attacks. To do that, the authors introduce STARE, a 3D convolutional encoder with channel recalibration for embedding, and DIRD, a 3D hourglass-style decoder for recovery.
The second major contribution is GIFfaces, a new face-centric GIF benchmark built from multiple video sources and converted into GIF format with a controlled preprocessing pipeline. Using this dataset, the authors train the system with a realistic distortion simulator that includes signal degradation, geometric perturbations, and frozen deepfake generators (SimSwap, MobileFaceSwap, Ghost) as differentiable attack proxies. On their reported tests, GIFGuard preserves visual quality better than prior baselines and dramatically lowers bit error rate under both standard distortions and deepfake attacks, with the strongest claim being approximately 0.01% BER under deepfakes at 128-bit payload.
Key findings
- GIFfaces contains 50,000 samples, and the reported train/val/test split is identity-disjoint: 10,000 / 3,000 / 3,000 samples for experiments.
- At 128-bit payload, GIFGuard reports average BER = 0.0343% under signal/geometric distortions and 0.0105% under deepfake attacks (Table 3).
- Against deepfake attacks, VideoSeal’s average BER is 19.3245% and REVmark’s is 22.9785%, versus GIFGuard’s 0.0105% (Table 3).
- Under frame dropping, RivaGAN’s BER rises to 24.4643% at a 32-bit payload, showing temporal desynchronization sensitivity; GIFGuard reports 0.0167% on the same distortion (Table 3).
- Visual quality is reported at PSNR = 49.54 dB, SSIM = 0.9960, LPIPS = 0.0035 for GIFGuard, outperforming VideoSeal’s PSNR = 48.02 dB and LPIPS = 0.0130 (Table 1).
- Removing the 3D SE module increases average BER under deepfake attacks from 0.0105% to 0.0240% (Table 4).
- The decoding-head ablation shows a severe failure mode when using naive global pooling: BER is ~49.98% on average, versus 0.0105% for the full DIRD design (Table 5).
Threat model
The adversary can apply common post-processing and transformation attacks to a published GIF, including compression, blur, noise, cropping, frame dropping/shuffling, and semantic face replacement via deepfake generators. The attacker may cause severe facial reconstruction that preserves visual plausibility while destroying low-level watermark traces. The method assumes the attacker does not have direct access to the embedded secret message or the training pipeline at attack time, and it does not claim immunity to a fully adaptive white-box attacker who can specifically optimize against the watermarking system beyond the simulated attack family.
Methodology — deep read
Threat model and assumptions: the paper’s adversary is a deepfake generator or post-processing pipeline that can alter facial appearance in a GIF while preserving apparent realism, plus common transmission-time distortions such as compression, blur, cropping, frame dropping, and frame shuffling. The defense assumes the attacker does not know the embedded watermark bits or model parameters at inference time, but the system is trained against frozen surrogate attack models and differentiable approximations of non-differentiable distortions. The goal is proactive forensics: embed a watermark before publication so later tampering can be detected or traced. The paper does not claim resistance to a fully adaptive attacker who knows the exact model and can optimize specifically to erase the watermark beyond the simulated attack set.
Data provenance and preprocessing: GIFfaces is built from five public benchmarks plus web-crawled content. The sources named in the paper are Celeb-DF-v2, DFEW, CAER, DFDC, FaceForensics++, and 1,500 YouTube video clips. The preprocessing pipeline extracts 10 consecutive frames starting from the first frame where a face is detected, crops them to 256×256 around the face, converts the sequence into GIF format with 256-color palette quantization, applies Floyd-Steinberg dithering to reduce banding, and uses LZW lossless encoding. Each subject is assigned a consistent ID, enabling identity-disjoint splits; the experiment section reports 10,000 training, 3,000 validation, and 3,000 test samples. The paper also says GIFfaces is the first large-scale GIF face forensics dataset, but the full construction details beyond the source list and preprocessing steps are not fully enumerated in the provided text.
Architecture and algorithm: GIFGuard has three main components. STARE (Spatiotemporal Adaptive Residual Encoder) takes the cover GIF tensor G_co in C×T×H×W form and a binary message M∈{0,1}^L (here L=128) and expands the message into a spatiotemporal feature volume using a fully connected projection plus trilinear upsampling. STARE then concatenates the cover and message features and passes them through a 3D squeeze-and-excitation module to compute channel-wise importance over the whole video cube. A 3D U-Net backbone produces a residual map, and the final watermarked GIF is G_w = G_co + α·tanh(F_out(X_dec)), where α controls embedding strength. The novelty is that the watermark is not inserted independently per frame; it is spread across the entire spatiotemporal cube and adaptively concentrated into channels/regions that are judged more stable under semantic reconstruction. DIRD (Deep Integrity Restoration Decoder) performs the inverse task: it uses 3D convolutions with SE-based denoising, a spatiotemporal restoration path with transposed convolutions, and a dynamically instantiated projection head that infers the flattened feature dimension at runtime. That dynamic head is a practical detail: instead of hard-coding a final linear layer size, the model runs a profiling pass with dummy input to infer the tensor shape, then instantiates W_fc accordingly.
Training regime and optimization: the total loss is L_total = L_imp + λ_adv L_adv + λ_msg L_msg. Imperceptibility loss combines pixel MSE and an LPIPS-style feature loss using AlexNet features. Adversarial loss is a standard non-saturating GAN objective where a discriminator learns to classify original vs. watermarked GIFs. Message loss is binary cross-entropy between the original bitstring and the recovered bits. The paper says λ_msg is increased linearly over training to prioritize bit recovery later. Training uses PyTorch with AMP on NVIDIA A40 GPUs, batch size 8, input size 5D (B,C,T,H,W), T fixed at 10, frames resized to 256×256, Adam with initial learning rate 1e-4, and a four-stage curriculum: epochs 1–3 clean identity mapping; epochs 4–10 add signal degradation and temporal perturbations; epochs 11–20 add deepfake attacks and random crop with sampling probability p=0.3; epochs 21–50 increase the deepfake/crop probability to p=0.6. The RDS attack proxies include Gaussian noise (σ=0.05), Gaussian blur (5×5 kernel, σ=1.0), salt-and-pepper noise (0.5%), 3×3 median filtering, JPEG quality 75, random crop with scale 0.8–1.0, frame dropping with probability about 0.7, frame shuffling, and frozen SimSwap, MobileFaceSwap, and Ghost models as differentiable layers. One concrete end-to-end example: a 10-frame face GIF is encoded with a 128-bit payload; STARE spreads the bits over the volume, the RDS applies a simulated crop plus a SimSwap-style semantic rewrite during training, and DIRD is trained to reconstruct the 128-bit string from the distorted output so that at inference the watermark survives after real manipulations.
Evaluation protocol and reproducibility: the paper compares GIFGuard on visual fidelity and bit recovery against GIFMarking, RivaGAN, REVmark, and VideoSeal. For visual quality it reports PSNR, SSIM, and LPIPS; for watermark recovery it reports BER across identity, blur, noise, salt-and-pepper, median, JPEG, frame drop, crop, and deepfake attacks. GIFMarking is retrained with deepfake data for a fairer comparison, and the authors explicitly note that RivaGAN is constrained to a 32-bit payload, while GIFGuard and the other baselines are evaluated at 128 bits. The paper also includes ablations for the 3D SE module and decoding head choice. Reproducibility is partially supported: the authors state that code and dataset will be released, but the provided text does not include a repository, frozen weights, or exact random seed strategy. Some implementation details are clear (PyTorch, AMP, A40, 50 epochs), but others such as discriminator architecture, exact λ values, and full optimizer schedule are not specified in the excerpt.
Technical innovations
- STARE embeds a binary watermark as a spatiotemporal feature volume with 3D SE-guided residual learning, rather than frame-wise spatial watermarking used by earlier image-centric methods.
- RDS treats deepfake generators as differentiable distortion proxies during training, which is different from prior proactive forensics that mostly model compression or geometric noise.
- DIRD reframes extraction as spatiotemporal restoration with 3D denoising, restoration, and a dynamically instantiated projection head to handle varying GIF tensor shapes.
- GIFfaces is a new identity-disjoint GIF benchmark built from multiple face/video sources and converted through a GIF-specific preprocessing pipeline.
- The training curriculum explicitly increases the probability of hard attacks over time, which is a form of difficulty scheduling for robustness under semantic tampering.
Datasets
- GIFfaces — 50,000 samples — constructed from Celeb-DF-v2, DFEW, CAER, DFDC, FaceForensics++, and 1,500 YouTube clips
- Celeb-DF-v2 — size not restated in paper excerpt — public dataset
- DFEW — size not restated in paper excerpt — public dataset
- CAER — size not restated in paper excerpt — public dataset
- DFDC — size not restated in paper excerpt — public dataset
- FaceForensics++ — size not restated in paper excerpt — public dataset
- YouTube clips — 1,500 video clips — manually collected
Baselines vs proposed
- GIFMarking: PSNR = 40.37 vs proposed: 49.54
- GIFMarking: SSIM = 0.9913 vs proposed: 0.9960
- GIFMarking: LPIPS = not reported vs proposed: 0.0035
- VideoSeal: PSNR = 48.02 vs proposed: 49.54
- VideoSeal: LPIPS = 0.0130 vs proposed: 0.0035
- RivaGAN: average BER under signal/geometric distortions = 3.1983% at 32-bit payload vs proposed: 0.0343% at 128-bit payload
- VideoSeal: average BER under signal/geometric distortions = 11.7178% vs proposed: 0.0343%
- REVmark: average BER under signal/geometric distortions = 22.8075% vs proposed: 0.0343%
- RivaGAN: average BER under deepfake attacks = 2.6317% at 32-bit payload vs proposed: 0.0105%
- VideoSeal: average BER under deepfake attacks = 19.3245% vs proposed: 0.0105%
- REVmark: average BER under deepfake attacks = 22.9785% vs proposed: 0.0105%
- GIFMarking: VIF under deepfake attacks = 0.0032 vs proposed: not reported for the watermark-image baseline comparison
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.26519.

Fig 1: Comparison of proactive forensics paradigms. (a)

Fig 2: Overview of the GIFGuard framework. The architecture consists of three key modules: (1) STARE, an encoder that

Fig 3: Visualization of visual imperceptibility and robustness against mixed attacks. Rows 1-3 illustrate the high fidelity of
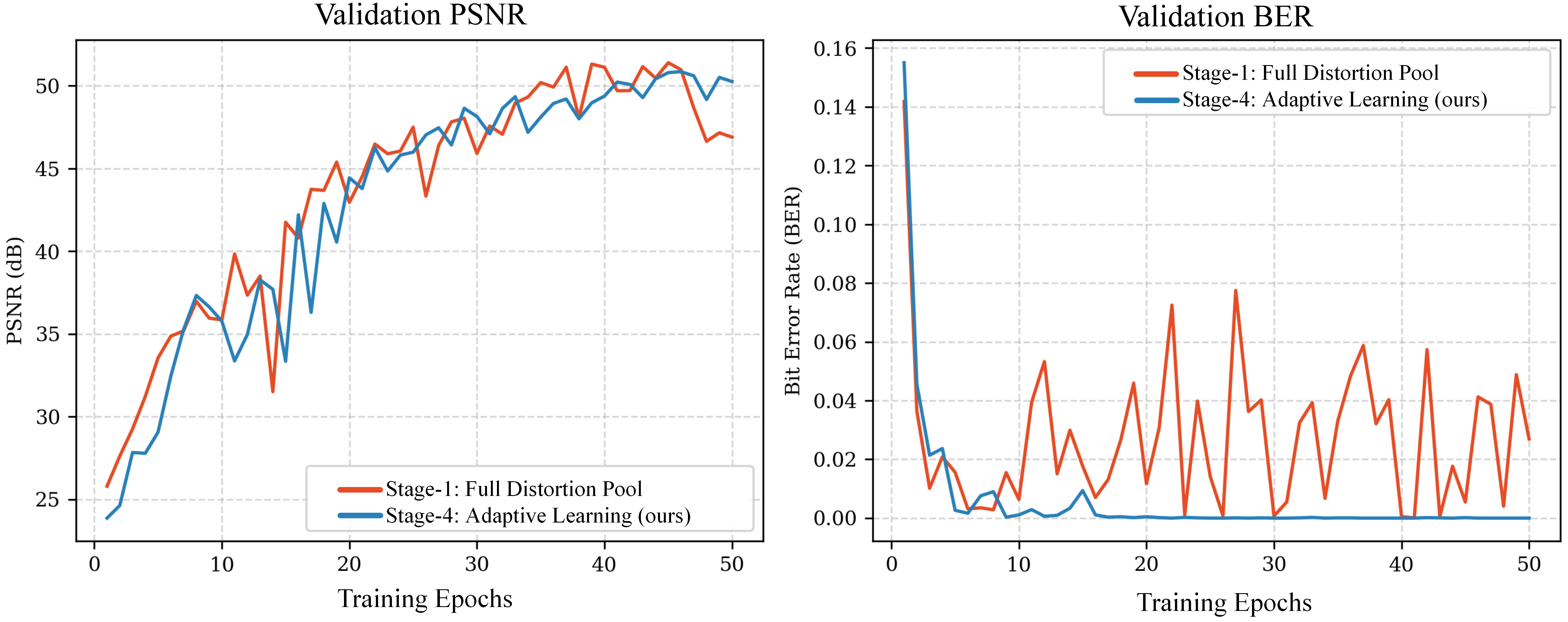
Fig 4: Ablation study on the efficacy of the learning strat-
Limitations
- The paper relies on surrogate deepfake models (SimSwap, MobileFaceSwap, Ghost) and differentiable approximations of GIF compression; robustness to unseen generators or more adaptive attacks is not established in the excerpt.
- GIFGuard is evaluated on a curated 10-frame, 256×256 face-centric GIF setting, so generalization to longer clips, non-face GIFs, or different lengths/qualities is unclear.
- The comparison to video baselines is somewhat uneven because RivaGAN is limited to 32 bits while GIFGuard is tested at 128 bits; that highlights capacity differences, but it complicates direct apples-to-apples interpretation.
- The excerpt does not report statistical significance, confidence intervals, or multiple-seed variance.
- Some key implementation details are missing from the provided text, including discriminator architecture, exact loss weights, and whether the released code/dataset are already public.
- GIFMarking is retrained with deepfake data, but the degree of hyperparameter tuning parity across baselines is not fully documented here.
Open questions / follow-ons
- How well does the scheme generalize to unseen deepfake generators, especially diffusion-based face editors that may not resemble SimSwap/MobileFaceSwap/Ghost?
- Can the GIFfaces benchmark be extended to non-face GIFs, variable-length GIFs, or different palette/quantization settings without retraining from scratch?
- What is the minimal temporal context needed for robust watermark recovery: is T=10 essential, or can the model operate on shorter clips or streamed GIF chunks?
- Can a simpler temporal coding scheme achieve similar robustness with fewer than 400M decoder parameters, or is the 3D restoration capacity truly necessary?
Why it matters for bot defense
For bot-defense engineers, the main takeaway is that the authors are not trying to detect deepfakes after the fact; they are embedding provenance information that is supposed to survive later manipulation. That is relevant if you care about media authenticity signals inside user-generated content, but less directly useful for CAPTCHA-solving detection unless you are building a provenance layer for uploads or identity-verified media. The important design lesson is the shift from frame-wise watermarking to sequence-aware embedding and from generic noise augmentation to attack simulation that includes semantic generators. If you were evaluating a similar defense, you would want to test against unseen generators, stronger adaptive attacks, and distribution shifts in GIF length, palette quantization, and face pose—because the paper’s strongest results are on a curated 10-frame face-GIF regime, not on arbitrary social-media media.
Cite
@article{arxiv2604_26519,
title={ GIFGuard: Proactive Forensics against Deepfakes in Facial GIFs via Spatiotemporal Watermarking },
author={ Shupeng Che and Zhiqing Guo and Changtao Miao and Dan Ma and Gaobo Yang },
journal={arXiv preprint arXiv:2604.26519},
year={ 2026 },
url={https://arxiv.org/abs/2604.26519}
}