
AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery
Source: arXiv:2604.25256 · Published 2026-04-28 · By Lei Xiong, Kun Luo, Ziyi Xia, Wenbo Zhang, Jin-Ge Yao, Zheng Liu et al.
TL;DR
Empirical evaluation of state-of-the-art LLMs and AI agent systems reveals the extraordinary difficulty of these tasks. Even flagship models like Claude-Opus-4.6 and Gemini-3.1-Pro achieve under 10% accuracy on Deep Research and under 10% IoU on Wide Research, far below scores (>80%) seen in general web browsing benchmarks such as BrowseComp. Models struggle with multi-hop scientific reasoning, fine-grained verification of complex constraints embedded in full paper content, and iterative search completeness. Longer trajectories and additional reasoning do not significantly improve performance, highlighting fundamental capability gaps in scientific domain reasoning and evidence integration. The authors release the dataset, evaluation pipeline, and code to foster progress.
Key findings
- Top-performing models attain only 9.39% accuracy on Deep Research and 9.31% IoU on Wide Research tasks in AutoResearchBench.
- Majority of strong LLMs and open-source baselines score below 5% on both task metrics.
- Increasing the number of reasoning steps or search tool calls (turns) does not guarantee improved accuracy; some models with fewer turns outperform those with many iterative steps.
- DeepXiv full-text search tool significantly outperforms open-web search tools for these tasks, e.g. Deep Research accuracy improved from 3.97% (open-web) to 7.93% with DeepXiv for Gemini-3.1-pro.
- Explicit THINK mode (extra reasoning steps without new evidence acquisition) did not improve performance, often prolonging runtime and reducing Wide Research IoU.
- Wide Research queries average 33 candidates per query, trimmed to about 9 true papers, requiring effective filtering for precision and recall.
- Deep Research includes 10% no-answer queries, testing agent capacity to recognize unsatisfiable constraints robustly.
- Current agents frequently fail due to incomplete multi-hop reasoning, weak integration of fragmented full-text evidence, and inability to precisely verify conjunctive constraints.
Threat model
The adversary is an autonomous AI research agent tasked with identifying or exhaustively retrieving scientific papers matching complex and obfuscated conjunctive constraints derived from full text and citations. The agent has access to full-text search tools over a large academic corpus but cannot directly know the target paper a priori. It cannot perform arbitrary computations or experiments outside literature search. The threat model assumes no adversarial tampering with the corpus or results.
Methodology — deep read
The paper's methodology centers on creating a robust, realistic benchmark assessing AI agents' autonomous scientific literature discovery capabilities through two key task paradigms: Deep Research and Wide Research.
Threat Model & Assumptions: The adversary is framed as an AI agent requiring autonomous capability to search, browse, and reason over a vast corpus of scientific papers to find precise evidence. The agent interacts with the controlled DeepXiv search environment but cannot rely on memorization or surface metadata. They must understand and verify subtle conjunctions of constraints from full text, citations, and appendices. Agents cannot cheat by direct answer lookup; they must truly demonstrate comprehension and multi-hop reasoning.
Data: The benchmark corpus comprises over three million arXiv computer science papers with full text extracted and indexed by DeepXiv. The dataset contains 1,000 queries: 600 Deep Research queries requiring identification of a unique paper or no answer, and 400 Wide Research queries requiring exhaustive retrieval of multiple papers. Each Deep Research query involves a complex conjunction of obfuscated constraints derived from full-text evidence and citation chains, verified manually and via LLM ensembles. Wide Research queries are constructed from domain-specific entity graphs representing multidimensional constraints over groups of papers with stringent human verification.
Architecture / Algorithm: Agents utilize a standardized ReAct agent framework combining reasoning and action with the DeepXiv tool backend providing search and paper retrieval APIs. The ReAct agent plans queries, retrieves documents, extracts evidences from full text, and iteratively refines hypotheses. The paper evaluates many underlying LLMs within this framework (Qwen3.5 variants, GPT-5.4, Claude-Opus, Gemini-3.1-Pro, etc.) but the benchmark is independent of a particular model architecture.
Training Regime: The benchmark is an evaluation dataset; models used are pre-trained large language models accessed either open-source or via API. Experiments run standard ReAct inference with maximum turn limits around 30, reporting accuracy and IoU metrics. Hyperparameters like max turn count, timeout thresholds, and search call limits are held constant across models.
Evaluation Protocol: Deep Research queries are evaluated by strict accuracy (exact match of single target paper or correct recognition of no answer). Wide Research adopts Intersection over Union (IoU) of predicted vs gold paper sets, capturing balance of recall and precision without ranking bias. Benchmarks include ablations testing different tool backends (DeepXiv vs open-web), reasoning modes (with or without THINK), and test-time scaling. Error analyses cover reasoning failures, reflection inefficiencies, and recall vs precision trade-offs.
Reproducibility: The authors publicly release the full dataset, the evaluation pipeline, and code to support standardized benchmarking. Training details of underlying LLMs are outside their scope, but the benchmark framework and data are openly accessible for future scientific literature search agent research.
Example end-to-end Deep Research instance involves querying for a uniquely identified paper by decomposing a convoluted natural language description referencing prior preprints, specific statistical components, algorithmic measures, and author trajectory. The agent executes multi-hop citation searches, verifies technical algorithms across candidate papers via full-text readings including appendix details, and iteratively refines constraints to isolate a single correct paper or confirm its non-existence.
Technical innovations
- Design of two complementary task paradigms (Deep Research and Wide Research) that capture discrete paper identification and exhaustive literature coverage under complex, conjunctive, full-text-embedded scientific constraints.
- A full-text-first human–machine pipeline for task generation that mines verifiable constraints from fine-grained paper content including appendices and citation graphs, with iterative fuzzification and minimal sufficiency pruning.
- Integration and evaluation over a controlled academic corpus of over three million arXiv papers with up-to-date full-text search APIs enabling realistic scientific evidence retrieval rather than superficial metadata matching.
- Novel evaluation protocols matching research needs: strict accuracy for unique-paper identification and IoU for set discovery, both reflecting research workflows better than traditional web QA metrics.
- Empirical finding that current flagship LLM-based agents achieve below 10% performance highlighting a distinct research frontier beyond general web exploration.
Datasets
- AutoResearchBench dataset — 1,000 queries (600 Deep, 400 Wide) with corresponding gold paper sets — constructed from a DeepXiv 3M+ arXiv paper corpus
Baselines vs proposed
- Claude-Opus-4.6: Deep Research accuracy = 9.39% vs best 9.39%
- Gemini-3.1-Pro-Preview: Wide Research IoU = 9.31% vs best 9.31%
- Qwen3.5-397B-A17B: Deep Research accuracy = 6.97% vs proposed best 9.39%
- Seed-2.0-Pro: Wide Research IoU = 7.87% vs proposed best 9.31%
- Alphaxiv end-to-end system: Deep Research accuracy 0/50 queries (0%) showing current systems struggle on real tasks
- Open-web search vs DeepXiv search backend reduces Deep Research accuracy from 7.93% to 3.97% for Gemini-3.1-Pro
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.25256.
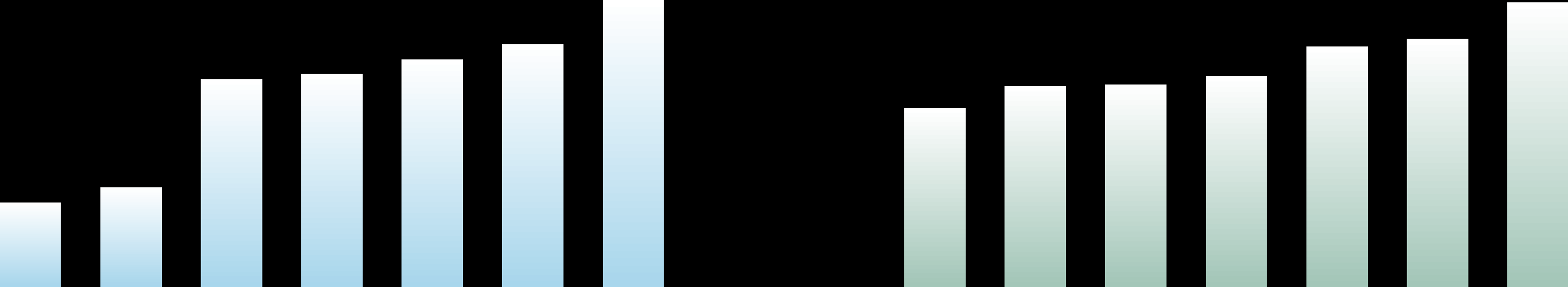
Fig 1: All Flagship models Struggle on AutoReasearchBench. Two representative (Deep

Fig 2: Overview of the benchmark construction pipeline. The construction pipeline comprises 2

Fig 3 (page 2).

Fig 4 (page 2).

Fig 3: Category distribution of two tasks across major computer science domains.

Fig 6 (page 4).

Fig 7 (page 4).

Fig 8 (page 4).
Limitations
- The benchmark currently covers only computer science domains from arXiv, limiting generalization to other scientific fields.
- The tasks rely on a controlled corpus with full-text extraction; agents with only metadata access would perform worse, limiting relevance to less well-indexed data sources.
- No adversarial evaluation of agents against actively deceptive or adversarial queries was performed.
- Models evaluated were evaluated in zero-shot or few-shot settings within a fixed agent framework; training specialized models was not investigated.
- Current evaluation does not assess real-time interaction with authors or external experiments—purely literature-based search.
- Some failure modes are hard to disambiguate (e.g., reasoning vs retrieval error) as full logs and agent internals for closed-source models are unavailable.
Open questions / follow-ons
- How can agents improve multi-hop scientific reasoning and effectively integrate fragmented full-text evidence including numeric tables, proofs, and citations?
- What architectural or training modifications could improve agents' ability to precisely verify complex conjunctive constraints in literature?
- Can iterative reflection and active search termination policies be learned to improve completeness and precision in Wide Research queries?
- How generalizable are these results to other scientific domains beyond computer science and to multi-lingual literature?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, AutoResearchBench highlights a new dimension of AI agent capability evaluation beyond typical general-purpose web browsing: deep domain-specific scientific reasoning and evidence verification. The benchmark underscores that even cutting-edge LLM-based agents struggle significantly on tasks requiring multi-step, fine-grained comprehension and logical verification over large-scale technical documents. Applying these insights, bot-defense teams should consider that autonomous agents capable of sophisticated literature discovery remain immature. This informs expectations about AI capabilities for scientific content scraping or misuse. Moreover, the benchmark's approach to evaluating iterative search completeness and precision under conjunctive constraints could inspire more rigorous challenge designs in bot and human verification systems aimed at distinguishing between shallow pattern matching and genuine deep reasoning behaviors.
Cite
@article{arxiv2604_25256,
title={ AutoResearchBench: Benchmarking AI Agents on Complex Scientific Literature Discovery },
author={ Lei Xiong and Kun Luo and Ziyi Xia and Wenbo Zhang and Jin-Ge Yao and Zheng Liu and Jingying Shao and Jianlyu Chen and Hongjin Qian and Xi Yang and Qian Yu and Hao Li and Chen Yue and Xiaan Du and Yuyang Wang and Yesheng Liu and Haiyu Xu and Zhicheng Dou },
journal={arXiv preprint arXiv:2604.25256},
year={ 2026 },
url={https://arxiv.org/abs/2604.25256}
}