
Understanding the Limits of Automated Evaluation for Code Review Bots in Practice
Source: arXiv:2604.24525 · Published 2026-04-27 · By Veli Karakaya, Utku Boran Torun, Baykal Mehmet Uçar, Eray Tüzün
TL;DR
This paper tackles a very practical measurement problem: if an industrial team deploys an LLM-powered automated code review (ACR) bot, can we reliably evaluate whether its comments are useful by using automated judges instead of expensive human review? The authors argue that the common proxy labels used in practice — developer actions like fixed or wontFix — are not clean ground truth because they are entangled with release pressure, ownership, timing, and other workflow constraints. They test this in a real industrial setting at Beko using 2,604 bot-generated PR comments originally collected by Cihan et al., and compare two automated evaluation schemes: G-Eval and a plain LLM-as-a-Judge pipeline.
The main result is that neither evaluator comes close to cleanly reproducing the developer labels. Across Gemini-2.5-pro, GPT-4.1-mini, and GPT-5.2, agreement ratios are only moderate, ranging from about 0.44 to 0.62 depending on model and rubric formulation. A repeated pattern is that a 0–4 Likert-style rubric mapped back to binary labels outperforms a direct binary rubric, but even the best configuration still shows weak correlation once class imbalance is considered. The paper’s interview with a software engineering director reinforces the quantitative result: in practice, developer labels reflect workflow realities as much as technical merit, which makes fully automated evaluation of ACR usefulness intrinsically noisy.
Key findings
- The industrial dataset contains 2,604 bot-generated PR comments; after excluding active, pending, and closed labels, the evaluation set used in the paper is 1,733 fixed and 871 wontFix comments (about 66% vs 34%).
- Across all three backends, the Likert-to-binary G-Eval variant outperforms the direct binary rubric: GPT-5.2 improves from 0.45 to 0.59 agreement, GPT-4.1-mini from 0.48 to 0.62, and Gemini-2.5-pro from 0.51 to 0.57.
- For LLM-as-a-Judge, the Likert variant again beats the binary rubric on every model: GPT-5.2 goes from 0.44 to 0.58, GPT-4.1-mini from 0.57 to 0.61, and Gemini-2.5-pro from 0.53 to 0.55.
- Best overall agreement in the paper is G-Eval + Likert + GPT-4.1-mini at 0.62 agreement ratio; the best LLM-as-a-Judge result is GPT-4.1-mini at 0.61.
- For the best-performing configuration (G-Eval + Likert + GPT-4.1-mini), F1 is 0.76, precision is 0.66, recall is 0.90, and MCC is -0.0590, showing that high recall does not translate to reliable balanced discrimination.
- The paper reports that 227 PRs, or about 8.7% of the dataset, required truncation because the combined prompt inputs exceeded the model context window.
- The authors state that both automated evaluation strategies achieve only moderate alignment, with agreement ratios roughly in the 0.44-0.62 range, and that this is sensitive to both backend model choice and rubric design.
- The interview with the software engineering director corroborates the central claim that developer labels are shaped by workflow pressure and organizational constraints, not just comment quality.
Threat model
The relevant adversary is not an external attacker but the mismatch between automated evaluators and the real industrial process they are supposed to approximate. The judges only see local PR artifacts — title, description, diff, and the bot comment — and cannot observe hidden workflow constraints, organizational priorities, release pressure, ownership boundaries, or other external reasons that may determine whether a developer marks a comment fixed or wontFix. Under that assumption, any automated label can only be an approximation of the workflow outcome, not definitive truth.
Methodology — deep read
The study is framed as a measurement-validity problem under an industrial code review workflow. The adversary in the abstract sense is not a malicious attacker but the mismatch between what the researchers want to measure — comment usefulness — and what the available labels actually encode. The authors explicitly assume that developer labels such as fixed and wontFix are imperfect proxies because they can be influenced by prioritization, deadlines, ownership, release pressure, and whether a change is worth making now. Their research question is therefore not “can a judge be made perfect,” but “how far can automated evaluation go when the ground truth itself is context-laden?”
Data come from Beko and were previously collected by Cihan et al. The original industrial dataset contains 2,604 bot-generated PR comments, each associated with workflow labels over five states: active, pending, resolved (fixed), wontFix, and closed. The authors exclude active and pending because those are intermediate states rather than final judgments, and they exclude closed because the paper treats that label as reflecting non-technical or external reasons rather than an explicit usefulness decision. After filtering, they evaluate 1,733 fixed comments and 871 wontFix comments. For each PR/comment instance they extract PR title, PR description, PR diff, the bot-generated comment, and — when available — a Jira issue description. Importantly, they do not provide repository-wide artifacts such as coding guidelines, historical discussions, or broader project context, so the evaluators operate on a compact local snapshot of the PR. The paper says the human labels are treated as ground truth for the study, but also repeatedly argues that this “ground truth” is only a pragmatic label source, not a perfect proxy for usefulness.
The two evaluation methods are G-Eval and LLM-as-a-Judge, both run on the same inputs and with the same usefulness criteria, so differences are meant to isolate the judge style rather than the evidence. G-Eval uses a rubric-driven prompting scheme inspired by prior rubric-based reference-free evaluation work. LLM-as-a-Judge uses a more direct evaluator prompt but is otherwise given the same task. Both are tested in two rubric formulations: a binary rubric and a 0–4 Likert scale. In the Likert setup, scores represent increasing usefulness from 0 (not useful) to 4 (fully useful); the authors then map scores to binary labels using a threshold of 1, so any score >=1 counts as useful. In the binary setup, the judge directly outputs useful/not useful, with 1 meaning useful and 0 meaning not useful. The paper’s rationale is that graded scoring may let the model express borderline cases more consistently than forcing an immediate binary decision. The models used as backends are Gemini-2.5-pro, GPT-4.1-mini, and GPT-5.2. No task-specific fine-tuning is used.
The implementation is intentionally close to a practical deployment setting rather than a highly controlled lab setup. All LLM calls use default temperature and a fixed system prompt. The authors do not do repeated sampling; each comment is judged once per model and setting. They justify keeping default stochasticity because industrial deployments commonly rely on vendor defaults instead of deterministic decoding. To handle context limits, PR diffs are truncated only when necessary, preserving the original order of content until the maximum context window is reached; this affects 227 PRs, about 8.7% of the data. The paper states that intermediate artifacts — prompts, reasonings, and raw outputs — are logged per comment, which helps auditability, but it does not describe code release or frozen weights beyond a replication package link.
Evaluation is done at the single-comment level. The primary metric is agreement ratio between the automated binary prediction and the human label: agreement = correct predictions / total comments. They report results aggregated across the full dataset and across backend models. For the best-performing configuration, they additionally report F1, precision, recall, and MCC because the dataset is class-imbalanced and MCC is more robust in that setting. There is no mention of cross-validation, held-out attacker sets, or statistical significance testing; instead, the paper compares models and rubric variants descriptively. One concrete end-to-end example of the protocol is: a PR comment plus its title/description/diff is passed into the G-Eval rubric prompt, the model outputs a Likert score, the score is thresholded to useful/not useful, and that label is compared against the developer’s fixed/wontFix annotation to compute agreement. The follow-up interview with a Beko software engineering director is used as qualitative triangulation to interpret why these labels are noisy.
Technical innovations
- Applies two generic LLM evaluation paradigms, G-Eval and LLM-as-a-Judge, to industrial ACR usefulness judging with the same PR evidence and label mapping.
- Introduces a controlled comparison between direct binary judging and a 0–4 Likert rubric thresholded back to binary usefulness labels for bot comments.
- Uses an industrial Beko dataset with workflow labels and a qualitative director interview to probe whether developer actions can function as objective ground truth for ACR evaluation.
Datasets
- Beko industrial PR-comment dataset — 2,604 bot-generated PR comments total; evaluation subset 1,733 fixed and 871 wontFix after filtering active/pending/closed — source: Beko Azure DevOps and Jira, originally from Cihan et al. (industrial, non-public)
Baselines vs proposed
- G-Eval (binary), GPT-5.2: agreement = 0.45 vs proposed: 0.59 with Likert
- G-Eval (binary), GPT-4.1-mini: agreement = 0.48 vs proposed: 0.62 with Likert
- G-Eval (binary), Gemini-2.5-pro: agreement = 0.51 vs proposed: 0.57 with Likert
- LLM-as-a-Judge (binary), GPT-5.2: agreement = 0.44 vs proposed: 0.58 with Likert
- LLM-as-a-Judge (binary), GPT-4.1-mini: agreement = 0.57 vs proposed: 0.61 with Likert
- LLM-as-a-Judge (binary), Gemini-2.5-pro: agreement = 0.53 vs proposed: 0.55 with Likert
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.24525.
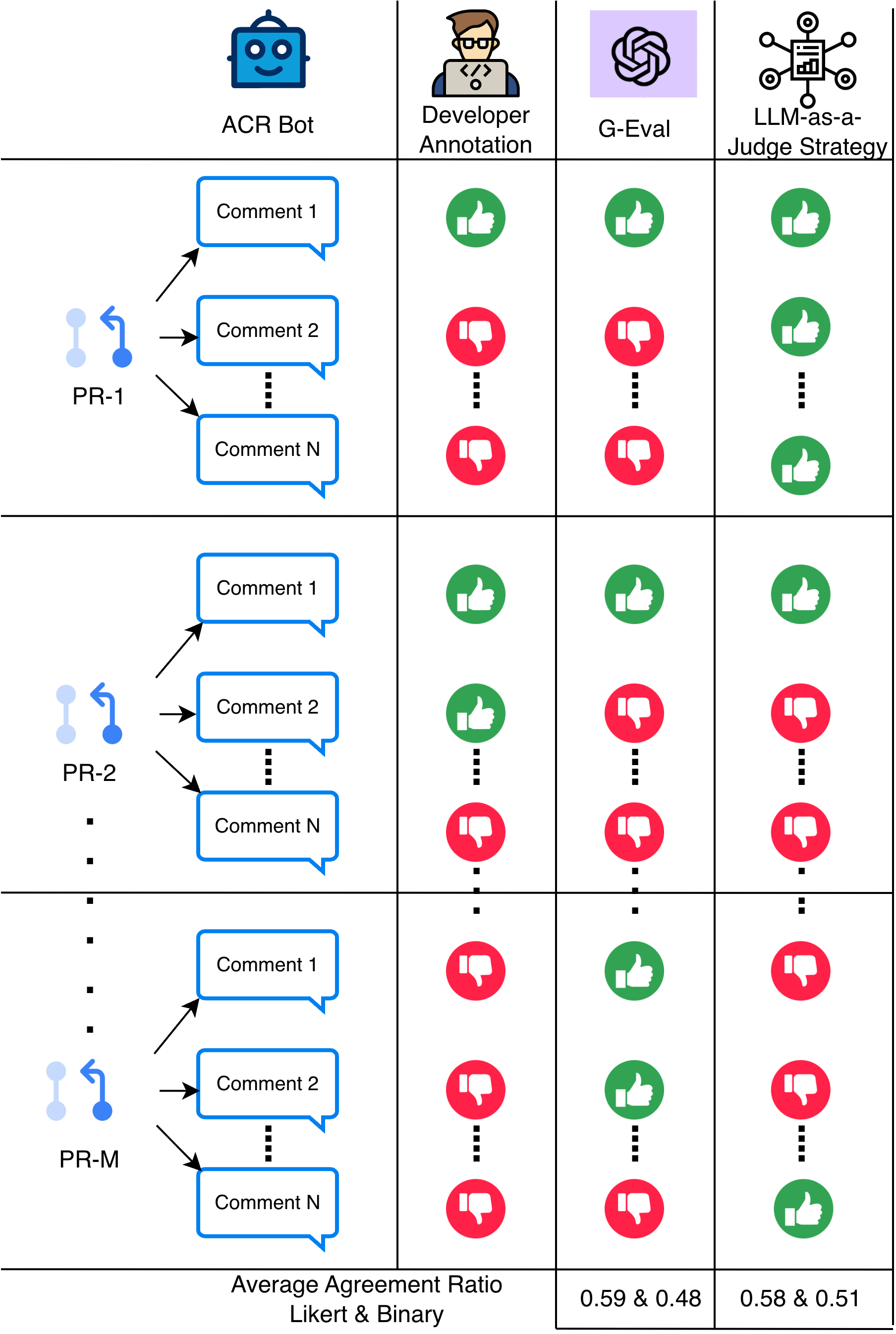
Fig 1: This figure illustrates how multiple evaluation
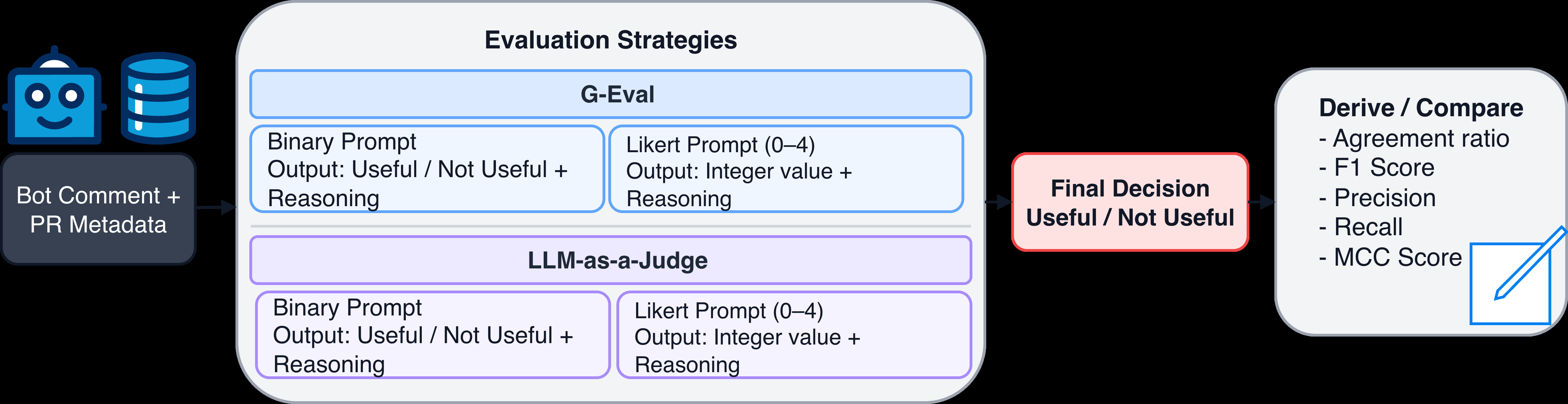
Fig 2: Evaluation setup comparing G-Eval and LLM-as-a-
Limitations
- The ground truth is not a pure usefulness label: fixed and wontFix are shaped by workflow, prioritization, ownership, and timing, which the paper itself emphasizes.
- The evaluation is descriptive rather than inferential; no confidence intervals, significance tests, or repeated-sampling variance estimates are reported in the provided text.
- Only a compact PR-local context is supplied to the judges; repository-wide conventions, historical discussion, and organizational context are omitted, which likely limits alignment.
- 227 PRs (8.7%) required diff truncation due to context limits, so some comments were judged with incomplete PR evidence.
- The study uses one industrial organization’s workflow and one dataset lineage (via Cihan et al.), so generalization to other teams, codebases, or review cultures is uncertain.
- The paper does not report cross-validation or a held-out adversarial test of robustness to prompt changes, model randomness, or distribution shift.
Open questions / follow-ons
- Can a richer evaluator that includes repository history, team conventions, or workflow metadata materially improve alignment with developer judgments?
- Would repeated sampling, calibration, or ensemble judging reduce variance enough to make automated evaluation operationally useful?
- Can we design labels that separate technical usefulness from workflow feasibility, instead of collapsing both into fixed/wontFix?
- How stable are these alignment results across different organizations, repos, languages, or bot types?
Why it matters for bot defense
For a bot-defense or CAPTCHA practitioner, the main takeaway is methodological rather than domain-specific: proxy labels produced by real users or operators are often contaminated by workflow context, so automated evaluation can look better or worse depending on what the label actually encodes. If you are validating a bot-detection or human-verification system, this paper is a reminder not to treat operational outcomes as clean ground truth without checking whether they reflect user intent, friction, timing, or process constraints.
More concretely, the paper suggests that rubric design matters. The fact that Likert-style judging outperformed direct binary judging, even modestly, implies that intermediate scores can capture borderline cases better than forcing a crisp decision. For CAPTCHA or bot-defense evaluation, that means a scoring rubric that distinguishes confidence, actionability, and contextual relevance may be more informative than a single accept/reject label. At the same time, the weak MCC values are a warning: a model can show decent agreement or F1 while still being poorly calibrated under class imbalance. In practice, you would want to validate automated evaluators against multiple signal sources, not just one operational label stream.
Cite
@article{arxiv2604_24525,
title={ Understanding the Limits of Automated Evaluation for Code Review Bots in Practice },
author={ Veli Karakaya and Utku Boran Torun and Baykal Mehmet Uçar and Eray Tüzün },
journal={arXiv preprint arXiv:2604.24525},
year={ 2026 },
url={https://arxiv.org/abs/2604.24525}
}