
TRAVELFRAUDBENCH: A Configurable Evaluation Framework for GNN Fraud Ring Detection in Travel Networks
Source: arXiv:2604.21093 · Published 2026-04-22 · By Bhavana Sajja
TL;DR
TravelFraudBench (TFG) addresses a critical gap in fraud detection benchmarks by providing a configurable synthetic evaluation framework specifically designed for fraud ring detection in travel platform graphs. Unlike existing benchmarks that focus on single node types or domain-general fraud patterns without ring-level ground truth, TFG simulates three structurally distinct travel-specific fraud ring types—ticketing fraud (star topology with shared devices/IPs), ghost hotel schemes (reviewer-hotel bipartite cliques), and account takeover rings (loyalty point transfer chains)—within a large heterogeneous graph containing 9 node types and 12 edge relations. This configurability enables fine-grained control over ring size, count, fraud rate, and graph scale, supporting difficulty-controlled evaluations that existing datasets cannot.
The benchmark evaluates multiple GNN architectures (MLP baseline, GraphSAGE, RGCN variants, HAN, PC-GNN) under a ring-based split that avoids transductive leakage, demonstrating that graph structure confers substantial detection advantages beyond tabular features alone. For example, GraphSAGE achieves AUC=0.992 and recovers 100% of fraud rings (with ≥80% member recall), vastly outperforming the MLP baseline (AUC=0.938, ring recovery 17–88%). Edge-type ablation further confirms that device and IP co-occurrence relations are key fraud signals. TFG is released as an open-source Python package with pre-generated datasets and multiple graph exporters, designed as a reproducible, realistic, and pressure-tested benchmark for fraud ring detection in travel networks.
Key findings
- GraphSAGE achieves 0.992 AUC (std 0.002), outperforming MLP baseline's 0.938 AUC by +5.5 percentage points on medium-scale TFG dataset.
- GraphSAGE recovers 100% of fraud rings (≥80% member recall) across all three ring types; MLP recovers only 17–88% depending on ring type.
- RGCN-proj (AUC=0.987) outperforms full heterogeneous RGCN (AUC=0.973), isolating graph projection as a key design element.
- HAN performs near MLP baseline (AUC=0.935), indicating meta-path attention is ineffective on this task.
- PC-GNN, a domain-specific GNN with focal loss and camouflage-suppressing neighbor picking, achieves 0.982 AUC but underperforms GraphSAGE by 1.05 points.
- Removing uses_device or uses_ip edge relations drops AUC by 5.2 and 5.7 percentage points respectively, identifying them as primary discriminative signals.
- Detection difficulty varies by ring topology and size: ticketing rings show declining AUC as ring size grows, ATO rings are robust, ghost hotel rings degrade sharply at large sizes.
- MLP baseline with tabular user features achieves high AUC (0.938) but low ring recovery (especially ghost hotel: 17%), confirming that node features alone cannot capture ring structure.
Threat model
The adversary is a financially motivated fraud ring operator in travel platforms creating coordinated, multi-account fraud schemes such as ticketing fraud rings, ghost hotel review cliques, and account takeover chains. They have access to multiple node and edge types but fraud rings are assumed structurally isolated (no cross-ring overlaps). The adversary does not adapt or evade detection algorithms explicitly and timing patterns are not exploited. The threat model does not include active adversarial attacks or model poisoning.
Methodology — deep read
Threat Model & Assumptions: The adversary consists of fraud rings operating in travel platforms creating suspicious relational patterns across users, devices, IPs, bookings, hotels, reviews, payment cards, and loyalty accounts. Rings have distinct topologies (star, bipartite clique, chain) and share infrastructure but rings are structurally isolated from one another. The attacker does not adapt to detection models (no adversarial evasion considered) and temporal burst patterns are not modeled in v1.0.
Data: TFG generates fully synthetic heterogeneous property graphs with 9 node types and 12 edge types, simulating real-world fraud by configuring ring count, size, fraud rate, and scale (500 to 200,000+ nodes). Key distribution parameters are calibrated to empirical travel fraud reports (Forter, Sift, FTC, IATA, SEON). Legitimate user behavior is simulated using agent-based sampling of feature distributions such as account age, booking lead time, and cancellation rates. The graph schema covers the full transaction lifecycle with rich tabular node features.
Architecture/Algorithm: The evaluation includes six models: (1) MLP baseline on user node features only (no graph), (2) GraphSAGE on a projected homogeneous user-user co-occurrence graph built from shared devices and IPs with mean aggregation, (3) RGCN-proj—a relational GCN variant applied to the same projected graph for architectural disentanglement, (4) full heterogeneous RGCN applying relation-specific weights over all nodes and edges, (5) HAN applying semantic-level attention over selected meta-paths (user-device-user, user-ip-user, user-hotel-user), and (6) PC-GNN, a fraud-domain-specific GNN incorporating focal loss to emphasize hard fraud samples and label-aware neighbor picking to suppress camouflage connections.
Training Regime: Models use 2-layer architectures with 128 hidden units, ReLU activations, dropout 0.3, and Adam optimizer (lr=0.001, weight_decay=5e-4). Trained for 200 epochs with early stopping based on validation AUC. Class imbalance handled via inverse-frequency weighting except PC-GNN which uses focal loss (γ=2) with α-weights.
Evaluation Protocol: Node classification AUC, average precision (AP), and macro F1 are measured under a ring-based 60/20/20 train/val/test split where each fraud ring appears in exactly one partition (no transductive leakage of devices/IPs). Ring recovery task defines success as ≥80% of ring members flagged above threshold=0.5 simultaneously, measuring operationally critical ring-level recall. Multiple seeds (mostly 5) support mean and standard deviation reporting.
Ablations and analyses include edge-type removals, feature masking, motif fingerprinting, homophily analyses, and ring-size difficulty studies. Dataset scale presets enable controlled difficulty experiments at multiple graph sizes.
Reproducibility: TFG is publicly released as an open-source Python package under MIT license. The codebase includes exporters for PyTorch Geometric, DGL, NetworkX, and CSV formats. Five pre-generated datasets at various scales are published on HuggingFace with machine-readable metadata including Responsible AI fields. Exact seeds and parameters are documented to support replication.
Technical innovations
- A synthetic heterogeneous graph generator modeling three distinct travel fraud ring topologies with ring-level ground truth and full configurability (ring size, count, fraud rate, scale).
- A ring-based train/val/test split strategy that eliminates transductive label leakage by ensuring entire fraud rings lie within single partitions.
- Disentangling graph projection effects from GNN architecture by comparing homogeneous projected user–user graphs versus full heterogeneous graph schemes.
- Operationally meaningful ring recovery metric requiring ≥80% ring member recall simultaneously, going beyond node-level metrics.
- Edge-type ablation demonstrating infrastructure co-occurrence edges (uses_device, uses_ip) as critical fraud signals, while others (reviews, loyalty transfers) add negligible detection power.
Datasets
- TravelFraudBench (TFG) — synthetic configurable heterogeneous graph dataset with 9 node types and 12 edge types, scales from 500 to 200,000 nodes — publicly released on HuggingFace datasets
Baselines vs proposed
- MLP baseline: AUC = 0.938 vs GraphSAGE: AUC = 0.992 (+5.5 pp)
- MLP baseline: Average Precision = 0.816 vs GraphSAGE: Average Precision = 0.977 (+16.1 pp)
- RGCN-proj: AUC = 0.987 vs GraphSAGE: AUC = 0.992 (+0.49 pp)
- Full heterogeneous RGCN: AUC = 0.973 vs GraphSAGE: AUC = 0.992 (+1.9 pp)
- HAN: AUC = 0.935 vs MLP: AUC=0.938 (-0.003 pp)
- PC-GNN: AUC = 0.982 vs MLP: AUC=0.938 (+4.4 pp), vs GraphSAGE: -1.05 pp
- Ring recovery (≥80% members flagged): MLP recovers 17–88% rings vs GraphSAGE recovers 100% rings
- Edge ablation: Removing uses_device drops AUC by 5.2 pp; removing uses_ip drops AUC by 5.7 pp
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.21093.
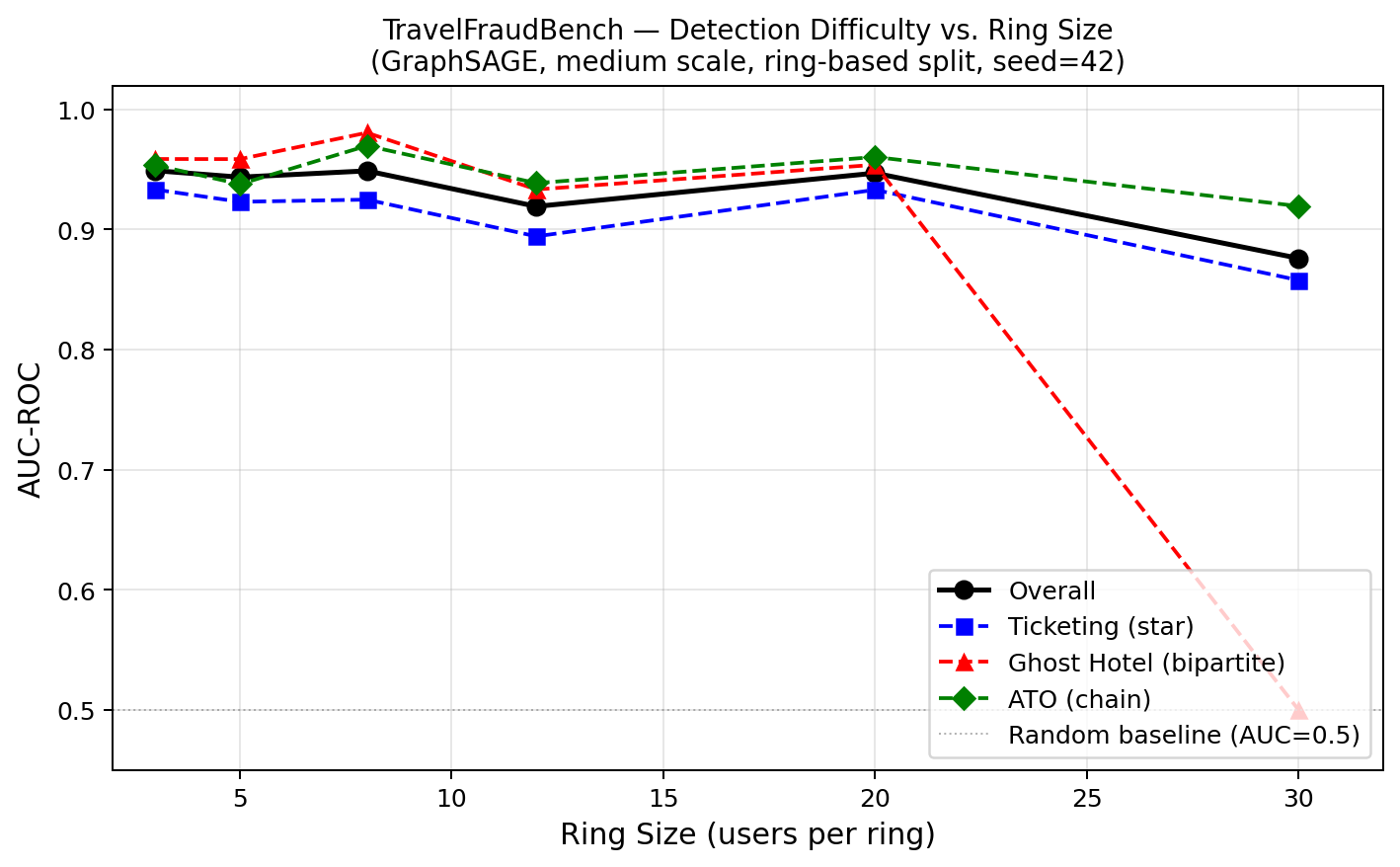
Fig 1: Controlled difficulty study (Evaluative Claims E2 and E3, GraphSAGE, medium scale, seed = 42,
Limitations
- TFG does not model temporal burst behaviors of fraud rings; timestamps are sampled uniformly, limiting evaluation of temporal GNN models.
- Fraud rings are structurally isolated with no cross-ring contamination, which is unrealistic as fraudsters often operate across rings sharing infrastructure.
- Adversarial fraudster adaptation and model evasion tactics are not evaluated; robustness under attacker feedback is unexplored.
- Real-world class imbalance is not fully represented; default fraud rates (~13%) exceed typical travel fraud rates (<1%), complicating direct operational translation of probability calibration metrics.
- Architecture versus graph representation confound complicates isolating the architecture effect; GraphSAGE benefits both from projection and architecture simultaneously.
- Only a limited set of meta-paths are evaluated for HAN; longer or alternative meta-paths are unexplored.
- Evaluations focus on static snapshots; no longitudinal or evolving fraud ring dynamics are tested.
Open questions / follow-ons
- How do temporal burst patterns and dynamic ring evolution affect detection performance, and can temporal GNN models leverage such signals effectively?
- What is the impact of cross-ring contamination and overlapping fraud ring membership on detection accuracy and operational utility?
- How would adversarially adaptive fraud rings, including active camouflage and evasion strategies, influence robustness of GNN-based detectors in TFG?
- Can more expressive heterogeneous GNN architectures or advanced meta-path designs outperform projection-based approaches under fair graph input conditions?
Why it matters for bot defense
TFG provides a nuanced and domain-specific benchmark for evaluating graph-based fraud ring detection methods, directly relevant to bot-defense and CAPTCHA research aiming to identify coordinated malicious clusters rather than isolated nodes. The explicit modeling of multiple ring topologies in realistic heterogeneous travel graphs highlights the need to consider structural diversity in fraud attacks, a concept analogous to adversarial bot clusters in CAPTCHA systems. The ring-based train/test split avoiding transductive leakage is an important methodological point ensuring robust, generalizable evaluation. Moreover, the use of edge-type ablation to identify critical relational signals informs which graph features carry discriminative power, a valuable insight for designing graph-aware bot detection models. Finally, the ring recovery metric aligns with operational needs in human-in-the-loop defenses where identifying coordinated attacker groups is paramount. However, TFG's limitations—including lack of adversarial evasion, temporal dynamics, and extreme class imbalance—should be carefully considered when extrapolating results to real-world bot-defense contexts.
Cite
@article{arxiv2604_21093,
title={ TRAVELFRAUDBENCH: A Configurable Evaluation Framework for GNN Fraud Ring Detection in Travel Networks },
author={ Bhavana Sajja },
journal={arXiv preprint arXiv:2604.21093},
year={ 2026 },
url={https://arxiv.org/abs/2604.21093}
}