
Reliability of AI Bots Footprints in GitHub Actions CI/CD Workflows
Source: arXiv:2604.18334 · Published 2026-04-20 · By Syed Muhammad Ashhar Shah, Sehrish Habib, Muizz Hussain, Maryam Abdul Ghafoor, Abdul Ali Bangash
TL;DR
This paper asks a practical reliability question that most AI-code discussions skip: once an agentic bot opens a pull request, how often does the repository’s CI/CD actually survive the resulting GitHub Actions workflow? The authors connect the AIDev dataset to GitHub Actions metadata and study workflow outcomes for PRs attributed to five agents: Claude, Devin, Cursor, Copilot, and Codex. The core unit of analysis is not code quality in the abstract, but the observed success/failure of CI runs triggered by agentic PRs across 2,355 open-source repositories.
The main result is that workflow reliability is highly agent-dependent. Copilot and Codex have the highest observed success rates, while Claude is lowest; Devin contributes the most runs but lands in the middle. They also find a weak negative repository-level association between how frequently agentic PRs appear and workflow success rate, suggesting that heavier agent use correlates with more CI fragility. For failed workflows, they build a 13-category taxonomy over PR titles and find that failures are concentrated in functional change types like bug fixes and new features, with visually suggestive but statistically non-significant shifts toward non-functional categories over time.
Key findings
- Across 61,837 GitHub Actions workflow runs from 2,355 repositories, agent-specific success rates differ substantially; Copilot reaches 93.28% and Codex 94.44%, while Claude is 64.86% and Cursor 72.39%.
- A chi-square test finds workflow success rates differ significantly across agents overall (p < 0.01), with Cramer's V = 0.177; pairwise Fisher tests with Benjamini–Hochberg correction show Copilot has higher odds of success than Claude (OR = 7.53), Cursor (OR = 5.29), and Devin (OR = 4.05).
- Language level has only a small effect: low-level-language repos show 86.7% success versus 82.4% for high-level-language repos, despite statistical significance (p < 0.01, Cramer's V = 0.028).
- At the repository level, agentic PR frequency is weakly negatively correlated with workflow success rate (Spearman ρ = -0.34, p < 0.01).
- The failure taxonomy is built over 3,067 PRs that triggered failing workflows, and the paper’s failure-focused subset for RQ2 covers 2,519 PRs and 9,012 failed workflows.
- Failures are unevenly distributed across PR categories: Bug Fixes account for 17.57%, UI/UX 11.64%, New Features & Enhancements 10.26%, Refactoring 10.04%, and Configuration & Infrastructure 8.04%.
- The category labeling pipeline reports strong agreement between human validation and GPT-5.0 assignment, with Cohen’s κ = 0.88 on a 334-PR manual validation sample.
- Temporal trend analysis over Dec 2024–Jul 2025 shows visually increasing shares for some non-functional categories (e.g., Documentation & Examples, UI/UX), but Mann–Kendall tests with Benjamini–Hochberg correction find no statistically significant monotonic trends.
Threat model
The implicit adversary is not a malicious attacker but the operational risk posed by agentic AI contributions to CI/CD reliability. The agents are assumed to be normal code-generation systems making PRs in open-source repositories; the authors observe only GitHub-visible metadata and workflow outcomes, not private prompts or internal tool state. The study does not model attackers who intentionally sabotage CI, nor does it assume the agents can manipulate the analysis pipeline. What they cannot do, within the study, is hide from the repository metadata used to attribute authorship or alter the GitHub Actions outcomes after the fact.
Methodology — deep read
Threat model and scope: this is not an active adversarial attack study; the implicit “threat” is operational unreliability of agent-generated code landing in CI/CD. The authors treat agentic PRs as the treatment condition and ask whether the resulting GitHub Actions workflows succeed or fail. They attribute agent activity from commit authorship metadata in the AIDev dataset, which means the analysis assumes commit authorship is a reasonable proxy for AI contribution. They do not claim to measure malicious intent, prompt injection, or adversarial bot behavior; the concern is reliability under normal open-source use.
Data provenance and filtering: they start from the AIDev dataset, described as a large-scale collection of GitHub repositories curated for AI-driven software development. First, they load the dataset into PostgreSQL. They begin with 2,807 repositories in the pr_repositories table and then search each repository for GitHub Actions YAML files under .github/workflows. After that filter, 2,355 repositories remain. From pull_request and pr_commits they extract 33,596 PRs and 88,576 commits in repositories with at least one valid CI/CD workflow. For each commit–PR pair they query the GitHub Actions API and collect workflow metadata including trigger type, final job status, and duration. This yields 208,843 workflow runs overall. They then filter to runs triggered by PRs made by five agentic bots—Claude, Devin, Cursor, Copilot, and Codex—giving 71,241 runs, and finally restrict to runs with explicit success or failure outcomes, producing the final quantitative set of 61,837 workflow runs. The paper also says 3,067 PRs triggered failed workflows; for RQ2 they further focus on 2,519 PRs that triggered 9,012 failed workflows. There is a mild inconsistency in the counts between the abstract and body (the abstract says 3,067 failed-PRs and 3,067 categories are defined; the RQ2 section narrows to 2,519 PRs for the category analysis), and the paper does not fully reconcile that difference.
Feature construction and tagging: for RQ1, they tag each workflow by the repository’s language type using the language metadata in the AIDev pr_repository table. They collapse languages into two groups following standard compiler-convention style grouping: low-level (C, C++, C#, Rust, Zig, Assembly) and high-level (Python, Java, JavaScript, TypeScript, Ruby, PHP, Go, Kotlin, Swift, R, Dart, HTML, CSS, Shell, and others). This produces 53,087 workflows in high-level repos, 8,192 in low-level repos, and 558 with no language specified. For the primary reliability metric, they compute repository-level workflow success rate as successful runs divided by total runs, then relate that to agent contribution frequency. This lets them ask whether repositories with more agentic PR activity have lower CI success.
PR categorization pipeline for failures: for RQ2, they classify PRs that led to failing workflows. They sample 548 PRs from the failing-PR set using a stated 99% confidence level and 5% margin of error, then apply semantic clustering on PR titles using GPT-5.0. Two authors refine the clusters by manual sorting and negotiated agreement, producing 13 categories: Bug Fixes; Testing & Quality Assurance; New Features & Enhancements; APIs, SDKs & Integrations; User Interface & User Experience; Configuration & Infrastructure; Refactoring & Code Quality; Documentation & Examples; Security & Authentication; Performance & Optimization; Regular Maintenance & Miscellaneous; Tools, Utilities & CLI; and Continuous Integration & Continuous Deployment. They then use GPT-5.0 in a close-card sorting setup to assign the remaining PRs to these categories. To validate the labels, they manually sample 334 PRs out of 2,519 and report Cohen’s κ = 0.88 between human coders and GPT-5.0, suggesting the label set is reasonably stable. A concrete end-to-end example from the paper’s pipeline would be: an agent-authored PR in a JavaScript repository opens a GitHub Actions run; the run is retrieved via the API, the repo is tagged as high-level language, the final status is marked failed, the PR title is later categorized by GPT-5.0 into one of the 13 failure types, and that failure contributes both to agent-level reliability statistics and to the category distribution for RQ2.
Evaluation protocol and statistics: the authors answer two RQs. For RQ1 they compare success rates across agents and language groups. They use chi-square tests for association, report Cramer's V for effect size, and use pairwise post-hoc Fisher’s exact tests with Benjamini–Hochberg correction. For repository-level frequency analysis, they use Spearman correlation between number of agentic PRs and workflow success rate, visualized in a logarithmic scatter plot (Fig. 2). For RQ2 they compute category shares among failed PRs and test whether failures are uniformly distributed using chi-square goodness-of-fit. For trends across months (Fig. 3, Dec 2024–Jul 2025), they use Mann–Kendall trend tests with Benjamini–Hochberg correction. The paper explicitly notes that the apparent upward trends for some non-functional categories are not statistically significant. No cross-validation, predictive modeling, or held-out attacker setup is used; this is observational analytics rather than a classifier paper.
Reproducibility and reporting: the authors state that they released data, scripts, and artifacts in a Zenodo replication package. The paper does not mention code for querying the GitHub Actions API in detail, frozen model weights for GPT-5.0 labeling, or whether the exact prompt used for semantic clustering is publicly archived. Because the categorization uses GPT-5.0 plus manual refinement, reproducibility of the label assignments depends on the shared artifacts and the availability of the same model behavior; the paper does not fully specify deterministic seeds or hyperparameters, since there is no learned model training loop in the conventional sense.
Technical innovations
- Connects AIDev agent-attributed PR metadata to live GitHub Actions run outcomes, making CI/CD reliability measurable at the workflow level rather than just at the commit or PR level.
- Introduces a repository-language-level comparison of agentic workflow reliability, splitting analysis into high-level versus low-level language projects.
- Builds a 13-class taxonomy of failure-triggering PRs using GPT-5.0-assisted semantic clustering plus human refinement and validation (Cohen’s κ = 0.88).
- Uses repository-level agent contribution frequency as a predictor-like explanatory variable and reports a weak negative Spearman association with workflow success.
- Applies month-by-month trend analysis to failure categories to look for shifts in the kinds of agentic changes that break CI/CD, even though trends are not statistically significant.
Datasets
- AIDev dataset — 2,807 repositories initially; 2,355 after workflow-file filtering; 33,596 PRs; 88,576 commits; 208,843 workflow runs overall; 71,241 agent-triggered runs; 61,837 success/failure-labeled runs — public dataset (source: AIDev repository / challenge dataset)
- Failed-PR category sample — 548 PRs for initial clustering; 334 PRs for manual validation; 3,067 failing PRs mentioned in the taxonomy phase — derived from AIDev + GitHub Actions API; not a separate public dataset
Baselines vs proposed
- Agent comparison: Claude success rate = 64.86% vs Copilot = 93.28% and Codex = 94.44% (table values; no external baseline beyond other agents).
- Claude vs Copilot: odds ratio for workflow success = 7.53 in favor of Copilot (post-hoc Fisher’s exact test with BH correction).
- Cursor vs Copilot: odds ratio for workflow success = 5.29 in favor of Copilot (post-hoc Fisher’s exact test with BH correction).
- Devin vs Copilot: odds ratio for workflow success = 4.05 in favor of Copilot (post-hoc Fisher’s exact test with BH correction).
- Low-level repos vs high-level repos: success rate = 86.7% vs 82.4% (chi-square significant, Cramer's V = 0.028).
- Repository-level activity vs success: Spearman ρ = -0.34, p < 0.01 (negative correlation; no predictive baseline).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.18334.
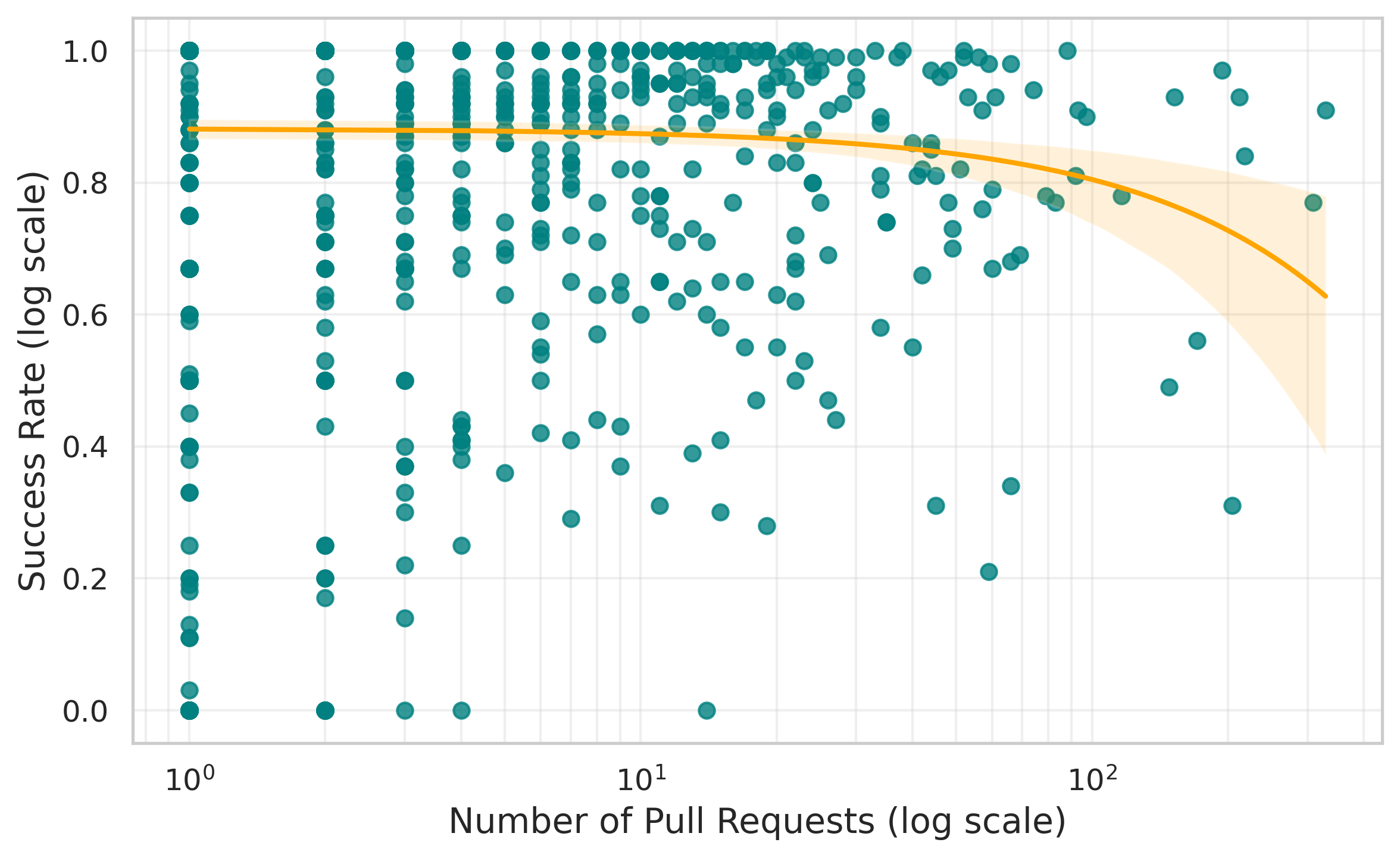
Fig 1: Overview of the CI/CD Reliability Analysis Workflow

Fig 2: Scatter plot of Agentic PRs vs. workflow success
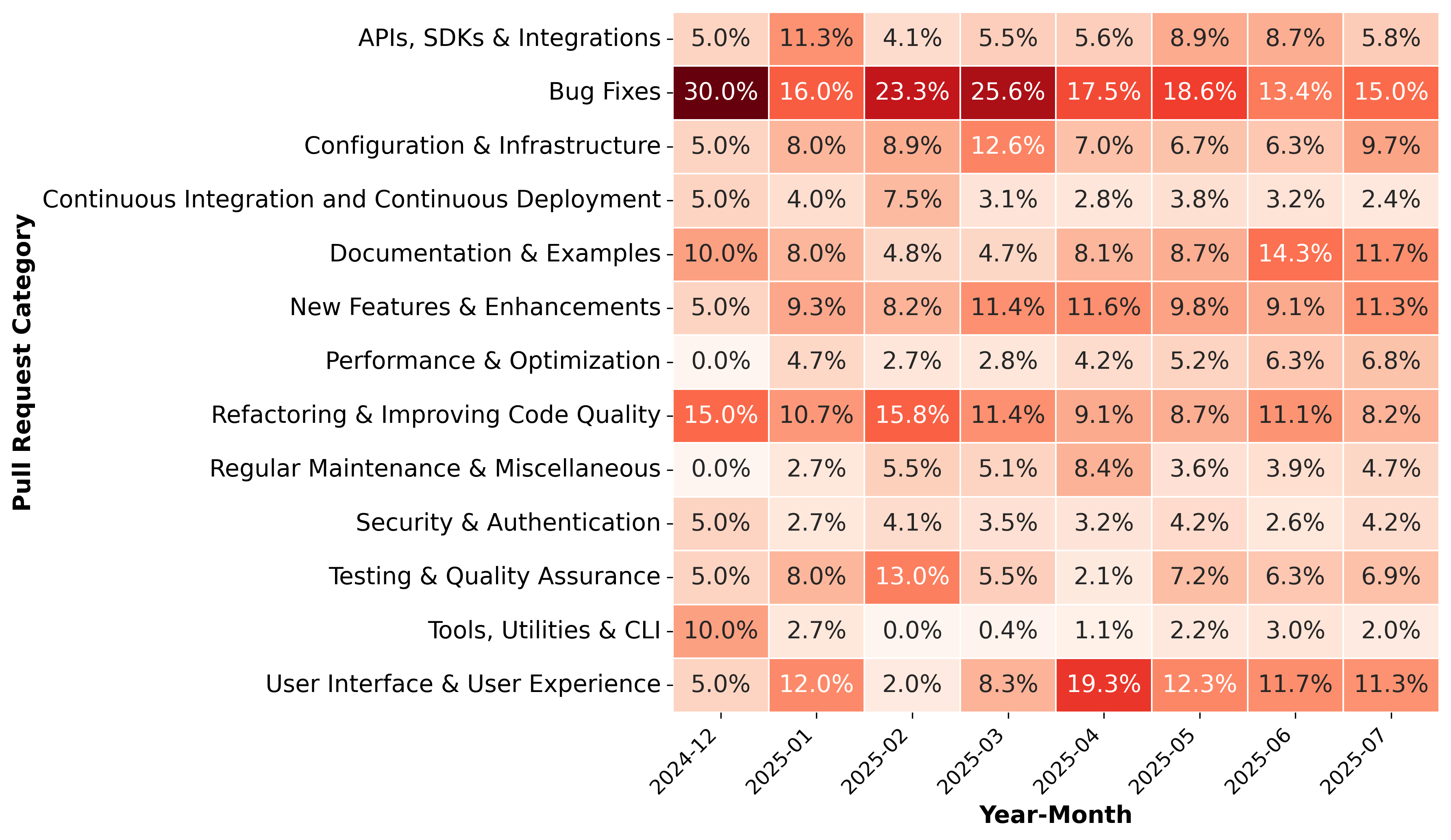
Fig 3: Month-by-Month Trends in PR Categories Leading
Limitations
- The analysis is observational, so it cannot establish that agentic PR frequency causes lower CI success; confounding by repository complexity, maintenance burden, or CI configuration is plausible.
- Agent attribution relies on commit authorship metadata, so hybrid human-AI PRs may be misclassified or partially misattributed.
- PR categorization is title-based and single-label, which can oversimplify multi-faceted PRs and miss the actual code-change semantics.
- The category trends over time are visually suggestive but statistically non-significant, so the paper should not over-interpret month-to-month shifts.
- The dataset is mostly public GitHub OSS, so results may not transfer to private or enterprise CI/CD pipelines with different review and workflow norms.
- Workflow runs are treated as independent in the statistical tests, but repeated runs within repositories may be correlated; the authors acknowledge hierarchical/mixed-effects models would be more appropriate.
Open questions / follow-ons
- What repository or workflow properties explain the large agent-to-agent gaps in success rate, especially between Copilot/Codex and Claude/Cursor?
- Would a mixed-effects model or per-repository causal design preserve the negative association between agentic PR frequency and CI success after controlling for repository size, language, and CI complexity?
- Can failure-prone PR categories be predicted before merge using PR text, diff stats, and workflow configuration features rather than only post hoc title taxonomy?
- Do these findings hold in private enterprise repos, where workflow policies, secrets, and deployment gates differ materially from public OSS?
Why it matters for bot defense
For bot-defense engineers, the useful takeaway is not that one agent is “better” than another in the abstract, but that agent-generated contributions have measurable and uneven reliability footprints once they enter automation. If a CI/CD pipeline is also a trust boundary for release gating, then agent identity, contribution frequency, and PR type can be treated as risk signals. This paper suggests that workflows consuming high-frequency agentic PRs may deserve stricter validation gates, especially for categories that historically fail more often, such as bug fixes, refactoring, and new-feature changes.
For CAPTCHA or anti-bot practitioners, the paper is relevant as a reminder that automation systems can be profiled by downstream reliability traces, not just by interaction patterns. In a broader bot-defense setting, engineers could use similar methodology to separate benign automation from brittle or risky automation: attribute actor type, measure outcome quality, and watch for shifts in failure modes over time. The main caution is methodological—repository-level correlations and title-based categories are informative, but they are not enough on their own to build enforcement policy without controlling for workload complexity and workflow structure.
Cite
@article{arxiv2604_18334,
title={ Reliability of AI Bots Footprints in GitHub Actions CI/CD Workflows },
author={ Syed Muhammad Ashhar Shah and Sehrish Habib and Muizz Hussain and Maryam Abdul Ghafoor and Abdul Ali Bangash },
journal={arXiv preprint arXiv:2604.18334},
year={ 2026 },
url={https://arxiv.org/abs/2604.18334}
}