
Syn-TurnTurk: A Synthetic Dataset for Turn-Taking Prediction in Turkish Dialogues
Source: arXiv:2604.13620 · Published 2026-04-15 · By Ahmet Tuğrul Bayrak, Mustafa Sertaç Türkel, Fatma Nur Korkmaz
TL;DR
Syn-TurnTurk tackles a very practical bottleneck in spoken dialogue systems: deciding when a Turkish user has actually finished a turn, instead of relying on crude silence thresholds that often misfire on natural pauses. The paper’s core move is to sidestep the lack of Turkish turn-taking corpora by synthesizing a dataset of two-person dialogues with several Qwen LLMs, explicitly instructing them to produce overlaps, silences, and interjections that resemble real conversational timing.
What’s new here is not a novel predictor architecture, but a synthetic data pipeline plus a benchmark-style evaluation of standard classifiers on that data. The authors report that the resulting corpus supports strong performance from relatively simple models, with BI-LSTM reaching 0.839 accuracy and an Ensemble (LR+RF) reaching 0.910 AUC on the full dataset. The work is best read as a dataset paper plus a feasibility study: can synthetic Turkish dialogue teach models to recognize turn boundaries? Their answer is yes, at least on in-distribution synthetic evaluation.
Key findings
- The final Syn-TurnTurk corpus contains 1,625 dialogues and 12,560 individual speaker changes, with 5,305 overlap instances totaling 2,213.50 seconds of concurrent speech.
- The dataset is generated from five Qwen variants: qwen3-max-2026-01-23 (675 dialogues, 41.5%), qwen3.5-35b-a3b (283), qwen3.5-flash-2026-02-23 (270), qwen3.5-397b-a17b (228), and qwen3.5-plus-2026-02-15 (169).
- Across the full dataset, BI-LSTM achieved the best accuracy at 0.839, while the LR+RF soft-vote ensemble achieved the best AUC at 0.910.
- On the full dataset, Logistic Regression reached 0.816 accuracy and 0.898 AUC; Random Forest reached 0.802 accuracy and 0.890 AUC; Decision Tree lagged at 0.721 accuracy and 0.687 AUC.
- The qwen3.5-397b-a17b subset was slightly harder to classify than the others: BI-LSTM reached 0.816 accuracy / 0.889 AUC there, versus 0.839 / 0.907 on qwen3-max-2026-01-23.
- The paper labels the final one-third of each turn-transition text sequence as positive and samples two random segments from the earlier portion as negative, producing 12,560 positive and 25,120 negative samples before downsampling.
- Using intfloat/multilingual-e5-large embeddings, the authors report that LSTM-family models are consistently stronger than DT/RF alone on both accuracy and AUC across all model subsets.
- The authors use 5-fold cross-validation; no held-out real Turkish dialogue set is reported, so all reported scores are on synthetic in-distribution evaluation.
Threat model
The implicit adversary is conversational uncertainty, not a malicious actor: a voice assistant must infer whether a Turkish speaker has finished a turn despite pauses, overlaps, and irregular timing. The system is assumed to observe dialogue text/timing features derived from the conversation and to lack access to a perfect endpoint oracle. The paper does not consider an attacker who intentionally manipulates timing, injects adversarial content, or attempts to evade detection; it is focused on modeling natural turn-taking rather than security against abuse.
Methodology — deep read
The threat model is mostly implicit rather than formally stated. The practical adversary is the conversational timing failure mode of a voice bot: the system must decide whether the user is mid-turn or done speaking, under irregular pauses, overlaps, and language-specific syntactic cues. The paper frames this as a turn-taking prediction problem for Turkish, where standard silence-based endpointing is brittle. There is no explicit malicious attacker model, and the paper does not study prompt injection, spoofing, or deliberate adversarial timing behavior; it is primarily a spoken-dialogue modeling paper, not an anti-abuse paper.
Data generation is synthetic and entirely LLM-driven. The authors call five Qwen APIs — qwen3-max-2026-01-23, qwen3.5-35b-a3b, qwen3.5-plus-2026-02-15, qwen3.5-397b-a17b, and qwen3.5-flash-2026-02-23 — and ask them to generate natural two-person Turkish dialogues. They seed generation with a pool of 79 unique topics, sampled at random per request, to reduce topical repetition. Prompts also instruct the models to include overlaps, strategic silences, and everyday interjections. Temperature varies, but the paper says most generations used 0.7 to balance coherence and spontaneity. The resulting dataset is published on Hugging Face as Syn-TurnTurk. The corpus totals 1,625 dialogues and 12,560 speaker changes; the paper further reports 5,305 overlap instances, 2,213.50 seconds of overlapping speech, mean FTO 0.286 s, median FTO 0.743 s, max negative FTO -2.500 s, and max positive FTO 0.880 s. The large mean/median gap suggests a skewed timing distribution with many short transitions and a tail of longer pauses.
The labeling scheme is a key methodological choice and also the main place where the paper departs from a real annotation pipeline. For each turn transition, the final one-third of the text sequence is labeled positive (1), while two randomly selected segments from the earlier portion are labeled negative (0). This yields a class-balanced raw count of 12,560 positive and 25,120 negative samples, but the training set is downsampled so that subsets are comparable, ending up with 1,306 positive and 2,696 negative samples in training. The paper does not fully spell out whether evaluation preserves the original imbalance or how the splits are stratified beyond 5-fold cross-validation. Representation is handled with the intfloat/multilingual-e5-large embedding model, which they choose for semantic and structural capture in Turkish. On top of those embeddings they train four model families: Decision Tree, Random Forest, Logistic Regression, and Bi-LSTM, plus a soft-vote ensemble of LR and RF. Hyperparameters are simple and mostly standard: DT uses Gini and best split with min split 2; LR uses L2, lbfgs, max_iter 1000, C=1.0; RF uses 100 trees, Gini, unlimited depth, bootstrap on; LSTM and BI-LSTM both use hidden size 384, Adam, learning rate 0.001; the ensemble uses equal weights.
Evaluation is done with 5-fold cross-validation and the main metrics are precision, recall, F1, accuracy, and AUC. The authors report results for the full dataset and separately for each Qwen subset, which is useful because it exposes how generation style affects downstream classification difficulty. On the full dataset, BI-LSTM and the ensemble are the strongest overall: BI-LSTM reaches 0.839 accuracy / 0.905 AUC, while the ensemble reaches 0.836 accuracy / 0.907 AUC. Logistic Regression is surprisingly competitive at 0.816 accuracy / 0.898 AUC, while Decision Tree is clearly weakest at 0.721 accuracy / 0.687 AUC. A concrete end-to-end example, as implied by the pipeline, is: a Turkish dialogue transition is embedded with multilingual-e5-large, the last third of the transition text is treated as the positive class, earlier segments as negatives, and the resulting vector is passed to the classifier; the classifier then predicts whether the current segment is a true turn-completion point or just a mid-turn pause. The paper does not report statistical significance tests, calibration, or external validation on human-recorded Turkish speech.
Reproducibility is partial. The dataset is hosted on Hugging Face, and the paper lists the five Qwen model IDs and the classifier hyperparameters, which helps. However, the full prompting templates, exact random seeds, exact fold splits, and any code for the generation/labeling pipeline are not described in the excerpt. More importantly, the evaluation is entirely on synthetic data produced by the same generation process that created the corpus, so there is no held-out real-world Turkish dialogue benchmark to test transfer. That means the reported metrics are best understood as an internal sanity check on whether the synthetic corpus is learnable, not as proof of deployment readiness.
Technical innovations
- Synthetic Turkish turn-taking corpus built from multiple Qwen LLMs with explicit prompts for overlaps, silences, and conversational fillers.
- Temporal characterization of synthetic dialogues using Floor Transfer Offset statistics, overlap counts, and silence-gap summaries to justify suitability for turn prediction.
- Benchmarking a multilingual embedding plus classical/deep classifier stack on synthetic turn-completion prediction in Turkish, rather than proposing a new model architecture.
- Per-subset evaluation by source LLM, showing that generation style changes classification difficulty and performance consistency.
Datasets
- Syn-TurnTurk — 1,625 dialogues; 12,560 speaker changes; 5,305 overlaps; 79 topics — Hugging Face (tugrulbayrak/Syn-TurnTurk)
Baselines vs proposed
- Decision Tree: accuracy = 0.721 vs proposed: 0.839 (BI-LSTM on full dataset)
- Random Forest: AUC = 0.890 vs proposed: 0.910 (Ensemble LR+RF on full dataset)
- Logistic Regression: accuracy = 0.816 vs proposed: 0.839 (BI-LSTM on full dataset)
- LSTM: accuracy = 0.838 vs proposed: 0.839 (BI-LSTM on full dataset)
- qwen3.5-397b-a17b subset, BI-LSTM: accuracy = 0.816 vs proposed: 0.839 (full-dataset BI-LSTM)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.13620.
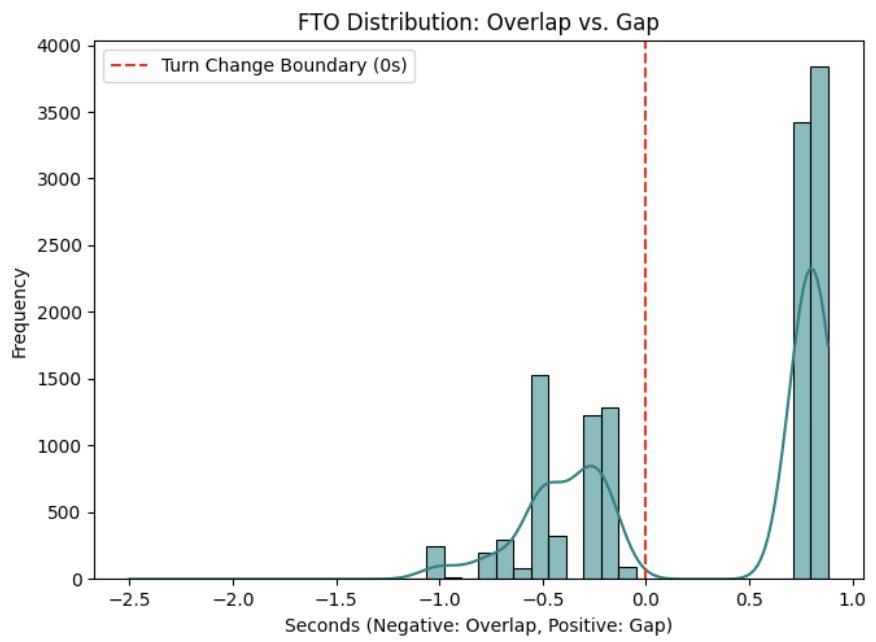
Fig 1: FTO distribution histogram
Limitations
- No evaluation on human-recorded Turkish speech is reported, so generalization from synthetic to real dialogue remains unproven.
- The label construction is heuristic: the final one-third of a sequence is treated as positive, which may encode the annotation rule more than genuine turn-completion semantics.
- The paper does not describe strong distribution-shift testing, adversarial probing, or held-out topic/model splits to measure robustness.
- Cross-validation is reported, but exact fold stratification, random seeds, and confidence intervals are not given in the excerpt.
- The synthetic corpus may reflect Qwen stylistic artifacts rather than Turkish conversational behavior, especially because all dialogues are LLM-generated.
- No ablation isolates the value of overlaps vs silences vs topic diversity vs model diversity in the synthetic-generation prompt.
Open questions / follow-ons
- Would a model trained on Syn-TurnTurk transfer to human Turkish speech transcripts or audio-derived features, and how much performance drops under that shift?
- Which generation factors matter most: topic diversity, model diversity, temperature, or explicit overlap/silence prompting?
- Can the synthetic labels be replaced with linguistically grounded annotations such as IPU/PCOMP-style labeling for a closer match to dialogue theory?
- Would acoustic or multimodal features add measurable gains over text embeddings alone on Turkish turn-taking?
Why it matters for bot defense
For a bot-defense engineer, this paper is interesting less as a defense artifact and more as a reminder that synthetic data can be useful when real conversational data is scarce, but only if the evaluation target matches deployment. If you are building voice-bot gating, human verification flows, or conversational friction controls, Syn-TurnTurk suggests that timing-sensitive language phenomena can be learned from generated corpora — but the absence of real-user validation means you should treat it as pretraining or prototyping data, not as evidence of production robustness.
The practical lesson is to separate “learns the synthetic task” from “solves the real operational problem.” For CAPTCHA or bot-detection adjacent systems that depend on dialogue timing, you’d want to pair any synthetic corpus with held-out real telemetry, adversarial stress tests, and calibration checks. Otherwise, a model may just learn the generator’s habits, not genuine human conversational cues.
Cite
@article{arxiv2604_13620,
title={ Syn-TurnTurk: A Synthetic Dataset for Turn-Taking Prediction in Turkish Dialogues },
author={ Ahmet Tuğrul Bayrak and Mustafa Sertaç Türkel and Fatma Nur Korkmaz },
journal={arXiv preprint arXiv:2604.13620},
year={ 2026 },
url={https://arxiv.org/abs/2604.13620}
}