
HadAgent: Harness-Aware Decentralized Agentic AI Serving with Proof-of-Inference Blockchain Consensus
Source: arXiv:2604.18614 · Published 2026-04-15 · By Landy Jimenez, Mariah Weatherspoon, Bingyu Shen, Yi Sheng, Jianming Liu, Boyang Li
TL;DR
HadAgent tackles a specific mismatch in decentralized systems: blockchain consensus consumes computation, while modern LLM-agent serving desperately needs computation that is actually useful. The paper’s core idea is Proof-of-Inference (PoI), where nodes earn block-creation rights by executing deterministic inference tasks instead of mining hashes. The system is built around a master/secondary node split, a three-lane block format (DATA, MODEL, PROOF), and a harness layer that monitors node behavior and adjusts trust over time.
What is new here is not just “use AI work for consensus,” but the coupling of consensus to real-time inference serving and the attempt to make verification cheap enough for operational use. Trusted nodes can answer requests optimistically, while non-trusted nodes are forced through full verification. The reported prototype results are strong on paper: 100% detection of tampered records, 0% false positives, sub-millisecond validation latency for record and hub operations, and harness convergence that excludes adversarial nodes within two rounds while promoting honest nodes within five rounds. However, these results are from a single-node Python prototype rather than a distributed deployment, so the claims are best read as a design validation rather than an end-to-end systems proof.
Key findings
- The prototype reports 100% detection rate for tampered records and 0% false positive rate in the baseline correctness tests.
- Validation latency for record and hub operations is reported as sub-millisecond in the prototype evaluation.
- The harness excludes adversarial nodes within two rounds, according to the reported convergence behavior.
- Honest nodes are promoted to trusted status within five rounds after sustained correct behavior.
- PoI verification is described as requiring only a single deterministic forward pass, rather than a full training run.
- The block format uses three independent Merkle roots for DATA, MODEL, and PROOF lanes, enabling lane-specific tamper detection.
- The evaluation was run on a local macOS machine with Python 3.14 and pytest in a single-node environment, not a distributed cluster.
Threat model
HadAgent assumes a Byzantine adversary with up to f of N nodes able to submit forged proofs, collude with dishonest masters, or attempt Sybil attacks. The system assumes deterministic inference under fixed weights/input/decoding settings, and it assumes an honest majority among master nodes for cross-master voting. The prototype does not claim to fully defend against network-level attacks such as message delay, reordering, selective dropping, or eclipse attacks, and it relies on off-chain availability of the same model/data artifacts to all participants.
Methodology — deep read
HadAgent assumes a Byzantine fault model in which up to f of N nodes may behave arbitrarily. The adversary can submit forged PROOF records, try to manipulate master-node decisions, or flood the network with Sybil identities. The defense strategy is split across consensus, block structure, and a harness layer: deterministic recomputation detects forged inference outputs; multi-master voting is meant to prevent a single compromised master from censoring or fabricating records; and the two-tier trust system is intended to keep untrusted or newly joined nodes on the fully verified path until they prove consistent behavior. The paper explicitly states that it does not fully address network-level attacks such as eclipse attacks, and that bounded clock drift, cryptographic hardness, and dynamic membership are additional assumptions/constraints rather than fully solved problems.
The data model is not a conventional supervised learning dataset in the ML sense, but a blockchain record pipeline with three record types: DATA, MODEL, and PROOF. DATA records bind an off-chain dataset or data artifact through a content hash plus metadata and signature. MODEL records bind a model configuration or artifact via model_hash, model_version, and related metadata. PROOF records capture dataset_hash, model_hash, validation_score, identifiers, timestamp, and signature. The paper says raw datasets, full model weights, and full inference outputs stay off-chain; only hashes, metadata, validation scores, and signatures are stored on-chain. For inference auditing, the paper references standardized benchmarks such as MMLU and HellaSwag as sources for randomly selected verification tasks during cross-master verification intervals, but it does not provide a full benchmark table, dataset sizes, or train/validation/test splits because the system is not training models in the reported experiments.
Architecturally, the novelty is a deterministic-inference consensus loop. A request enters the Agent Interaction Layer, a master node routes it to secondary nodes, and those nodes run inference under fixed weights, inputs, decoding parameters, and numerical settings so that outputs are intended to be bit-identical across compliant nodes. The master node recomputes the result, scores it, and creates a PROOF record; records then pass schema validation and signature verification before entering the mempool. Every block has a header with block height, previous hash, and three Merkle roots, one each for DATA, MODEL, and PROOF. The three-lane separation is meant to localize tamper detection and auditing. A second mechanism, the two-tier node architecture, changes service behavior: trusted nodes can serve results optimistically to users immediately, while non-trusted nodes must go through full verification before their responses are accepted. The harness layer adds heartbeat probes, anomaly detection via deterministic recomputation, and trust management that demotes nodes after repeated failures and promotes them after sustained correctness.
The experimental methodology is mostly prototype validation. The authors implemented the system in Python 3.14 on a local macOS machine, using pytest for automated checks and asyncio for asynchronous components. They split evaluation into three phases: baseline correctness, scale evaluation, and combined evaluation. Baseline tests included malformed blocks, incorrect block heights, bad previous-hash links, tampered Merkle roots, and forged signatures. Scale tests processed large numbers of valid records to simulate workload. Combined tests mixed correctness and load. Latency was measured with high-resolution timestamps around individual validation operations, and results were logged to structured JSON. Crucially, the entire evaluation was single-node and non-distributed; the paper explicitly says this was done to validate logic, correctness, and performance under controlled conditions. That means the reported sub-millisecond validation times reflect local software overhead, not WAN latency, gossip overhead, or adversarial network behavior.
One concrete end-to-end example in the paper’s logic is: an agent submits an inference request, a secondary node executes a deterministic task, the master recomputes the same task and generates a PROOF record containing hashes and the validation score, the record is schema-checked and signature-checked, and then it is admitted into the mempool and later committed into a block after cross-master verification. If the node is trusted, the agent receives the response immediately on the optimistic path; if not, the response waits for full verification. If a proof is tampered with, the harness’s anomaly detector recomputes the expected score and flags deviations, which can trigger demotion after repeated failures. The paper describes thresholds such as demotion after two consecutive failures and promotion after five clean rounds, but it does not fully specify all hyperparameters, seeds, or whether these thresholds were tuned empirically or chosen heuristically. Reproducibility is partial: there is a prototype implementation, but the excerpt does not mention a public code release, frozen weights, or a public dataset bundle.
Technical innovations
- Proof-of-Inference (PoI): a consensus mechanism where deterministic LLM inference, not model training or hashing, is the useful work that earns block-creation rights.
- Three-lane block body: separate DATA, MODEL, and PROOF lanes with independent Merkle roots to support fine-grained tamper detection and provenance auditing.
- Two-tier serving architecture: trusted secondary nodes can use optimistic execution for real-time responses, while non-trusted nodes remain on a fully verified path.
- Harness layer: heartbeat monitoring, deterministic recomputation, and automated trust management create a feedback loop that demotes unreliable nodes and promotes consistent ones.
Datasets
- MMLU — not specified — standardized benchmark referenced for random verification tasks
- HellaSwag — not specified — standardized benchmark referenced for random verification tasks
Baselines vs proposed
- Tampered-record detection: baseline = not reported vs proposed = 100% detection rate
- False positive rate on tampered-record tests: baseline = not reported vs proposed = 0%
- Record and hub validation latency: baseline = not reported vs proposed = sub-millisecond
- Harness convergence on adversarial nodes: baseline = not reported vs proposed = exclusion within 2 rounds
- Harness convergence on honest nodes: baseline = not reported vs proposed = promotion to trusted within 5 rounds
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.18614.
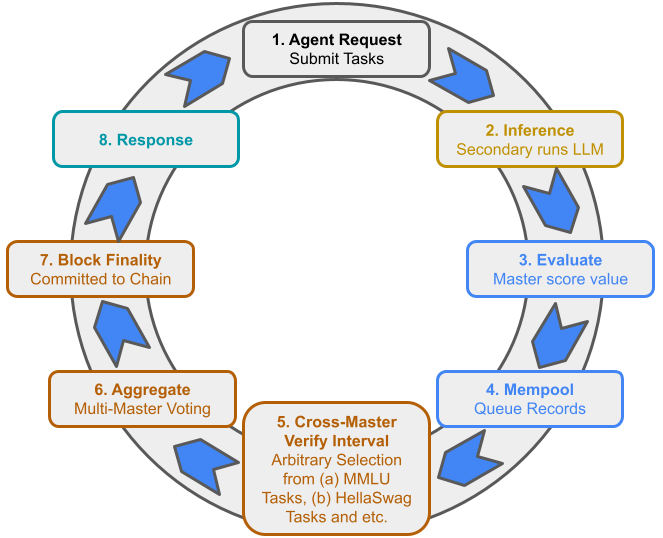
Fig 3: Consensus Flow with Interval Verification. The cycle proceeds in
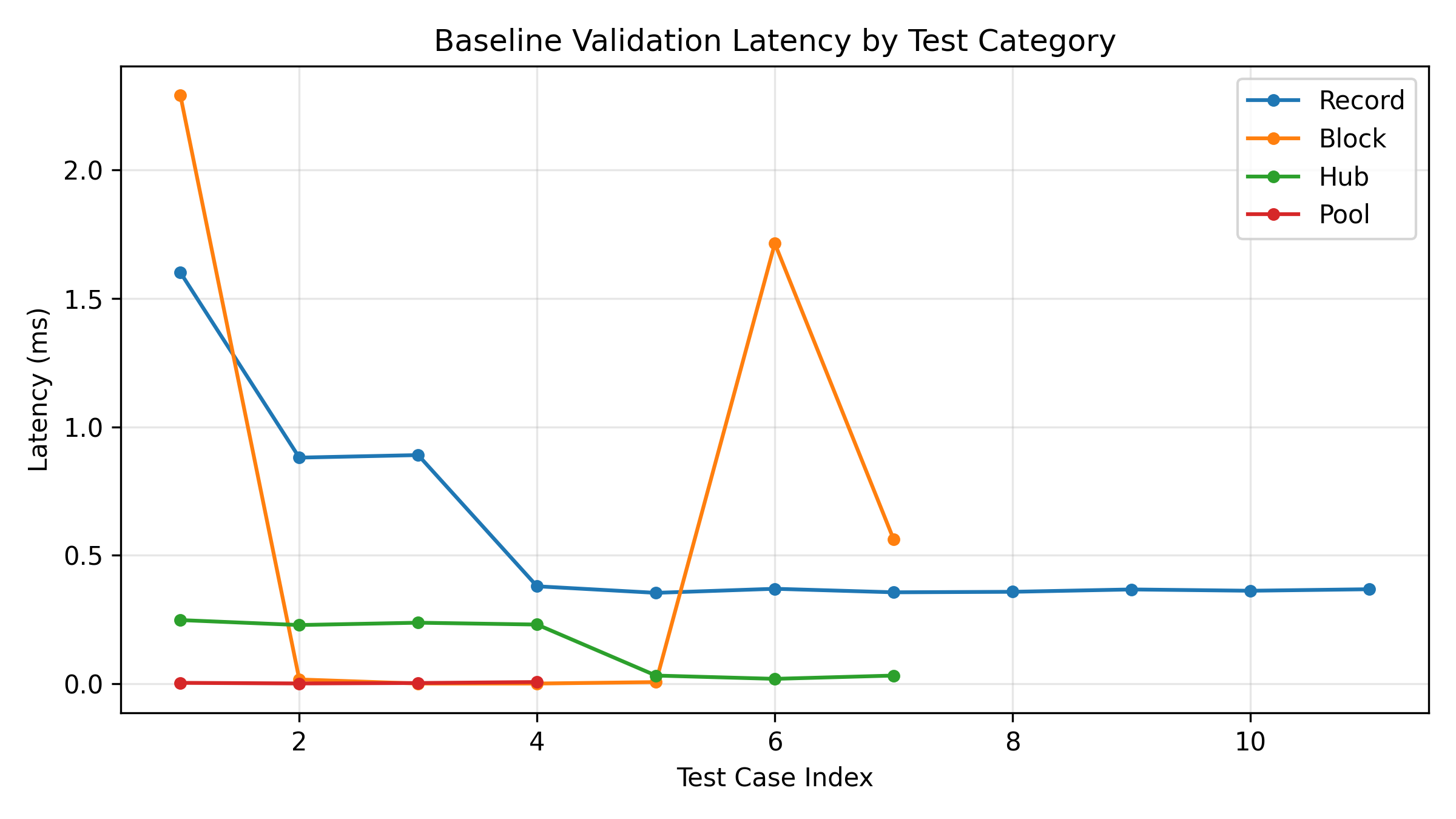
Fig 5: Consensus Latency Performance
Limitations
- The evaluation is single-node and non-distributed, so it does not measure real consensus behavior under network delay, churn, or contention.
- The excerpt does not report a public code release, frozen model weights, or exact reproduction instructions beyond the prototype stack.
- Several key settings are underspecified, including exact dataset sizes, batch sizes, optimizer choices, seeds, and detailed verification thresholds.
- The paper relies on deterministic inference assumptions that can be fragile across hardware, frameworks, and numerical precision settings.
- Network-level attacks such as eclipse attacks are acknowledged but not solved in the prototype.
- The results are reported as aggregate prototype outcomes; the excerpt does not show confidence intervals, statistical tests, or per-case error analysis.
Open questions / follow-ons
- How stable is PoI under realistic heterogeneity in GPUs, driver versions, and floating-point nondeterminism?
- Can the trust/harness mechanism be made robust against adaptive adversaries that behave honestly until they gain trust?
- What is the end-to-end throughput/latency tradeoff once a real gossip layer and multi-node WAN deployment are added?
- How should PoI be secured when model updates are frequent and multiple model versions are active simultaneously?
Why it matters for bot defense
For bot-defense engineers, the main takeaway is the system’s use of deterministic recomputation plus trust tiering as a way to separate fast-path service from fully verified service. That maps conceptually to CAPTCHA or abuse-mitigation stacks that try to reserve expensive checks for suspicious traffic while letting known-good clients move quickly. The important caution is that HadAgent’s validation depends on strong determinism assumptions; in practical bot defense, client diversity, network jitter, and partial observability make exact recomputation much harder than the paper’s prototype suggests.
More broadly, the paper is relevant as a design pattern for “progressive trust” systems: start all participants in a fully scrutinized path, then promote them after repeated consistency, and demote them immediately on anomalies. A CAPTCHA practitioner could adapt that idea to risk scoring, challenge escalation, or trust decay, but should not assume the blockchain framing transfers directly. The main engineering challenge is that unlike the paper’s controlled prototype, real-facing anti-abuse systems must handle noisy environments, adversarial adaptation, and ambiguous ground truth at scale.
Cite
@article{arxiv2604_18614,
title={ HadAgent: Harness-Aware Decentralized Agentic AI Serving with Proof-of-Inference Blockchain Consensus },
author={ Landy Jimenez and Mariah Weatherspoon and Bingyu Shen and Yi Sheng and Jianming Liu and Boyang Li },
journal={arXiv preprint arXiv:2604.18614},
year={ 2026 },
url={https://arxiv.org/abs/2604.18614}
}