
How Developers Adopt, Use, and Evolve CI/CD Caching: An Empirical Study on GitHub Actions
Source: arXiv:2604.13129 · Published 2026-04-13 · By Kazi Amit Hasan, Yuan Tian, Safwat Hassan, Steven H. H. Ding
TL;DR
This paper asks a practical, under-studied question: once teams turn on CI/CD caching in GitHub Actions, how do they actually keep it working over time? The authors treat caching as a maintenance problem, not just a performance toggle, and study how cache adoption, usage patterns, and cache-related edits differ across repositories and job types. Their dataset is broad for a workflow-metadata study: 952 GitHub Actions repositories, of which 266 are cache adopters and 686 are non-adopters, with 1,556 workflow files, 10,373 commits, and 17,185 workflow configuration changes reconstructed up to May 5, 2025.
The main contribution is a cache-centric empirical characterization of workflow evolution. They show that adopters tend to be more active and popular, that caching is used in multiple job types through several mechanisms rather than one standard pattern, and that cache configs undergo repetitive maintenance with different dynamics by job type. They also connect changes to likely causes using commit messages and pull-request context: parameter changes are usually human-driven issue fixes, while version bumps are more often bot-driven dependency maintenance. The result is a concrete picture of caching as ongoing operational work, with implications for tooling, defaults, and diagnostics.
Key findings
- 266/952 repositories (27.9%) adopted caching at some point; the remaining 686 were non-adopters.
- Cache adopters have more contributors, commits, closed PRs, stars, forks, and issues than non-adopters; Fig. 3 reports higher medians on these repository activity/popularity measures.
- Within language categories, PHP (54.2%) and Java (50.7%) have the highest caching adoption rates, while Ruby (17.6%) and Python (22.3%) are much lower (Table 3); the association with language is significant (chi-square, p < 0.001).
- Cache prevalence is highest in build jobs (37.31%), integration jobs (36.58%), lint jobs (27.84%), and test jobs (25.96%), and lowest in sync jobs (5.08%) (Table 5).
- At the step level, explicit caching via actions/cache dominates with 637/898 cache-related steps (70.9%), followed by package-manager caching with 220/898 (24.5%) and Docker layer caching with 2/898 (0.2%) (Table 6).
- Across the 266 adopters, the authors identify 2,494 cache-related maintenance activities, which they say are 14.53% of all workflow changes; on average that is 9.37 cache-related changes per repository.
- The evolution analysis finds frequent repetitive patterns such as remove-then-readd and rapid parameter edits in build/test jobs, while release-type jobs change more slowly; Fig. 4–Fig. 11 visualize job-specific transition graphs.
- Cache parameter updates are mainly human-driven and aimed at fixing problems, whereas cache version updates are often bot-driven and appear later as part of dependency maintenance, based on sampled commits, diffs, messages, and PR context.
Methodology — deep read
The threat model is implicit rather than adversarial in the security sense: the “adversary” is really workflow drift, cache invalidation, and configuration complexity. The paper assumes developers are trying to preserve CI/CD performance by reusing artifacts safely, but they face changing dependencies, changing job structure, and cache mechanisms whose behavior differs by action/version. It does not model a malicious attacker trying to poison caches or exploit them; instead, it studies maintenance burden under ordinary collaborative development. For RQ3, the authors also distinguish human-authored changes from bot-authored changes, but only as a label for the source of maintenance activity, not as an attack model.
The data originate from a previously curated dataset by Bouzenia and Pradel (2024) containing 952 GitHub repositories using GitHub Actions. The authors enrich this with repository metadata via the GitHub GraphQL API: stars, forks, contributors, commits, closed pull requests, issues, and primary language. They then reconstruct workflow histories for the 266 cache-adopting repositories using Gigawork, collecting historical versions of workflow files plus commit hash, timestamp, and path, up to May 5, 2025. This yields 1,556 workflow files, 10,373 commits, and 17,185 workflow configuration changes. They identify 2,494 cache-related changes (14.53% of all workflow changes) by filtering workflow diffs for cache configuration edits. For RQ1, they analyze both adopters and non-adopters at the repository level, while for RQ2 and RQ3 they restrict to the 266 adopters because only those histories contain cache configuration to track longitudinally. They also normalize job names into eight CI/CD job types: build, test, integration, lint, release, linux, analyze, and sync.
Methodologically, the paper’s core abstraction is a taxonomy of seven cache-related maintenance activities: cache enablement (EC), cache version update (C up), adding a new cache (C add), removing a cache (C rm), parameter update (P up), parameter addition (P add), and parameter removal (P rm). This taxonomy is applied to diffs at the workflow level. A cache adopter is defined as a repository that enables caching at any point in its lifecycle. They identify caching in three ways: explicit actions/cache steps, package-manager caching exposed by setup actions (setup-go, setup-node, setup-python, ruby/setup-ruby, setup-java), and Docker layer caching through docker/build-push-action. Importantly, they treat caching as present only when it is actually enabled in the version/configuration observed; for example, setup-go@v4 enables caching by default, while earlier versions do not. This distinction matters because they do not simply search for action names; they check whether the relevant caching option is really active.
For the architecture/algorithmic side, RQ2 models cache maintenance as a first-order Markov chain. For each job type, they reconstruct chronological sequences of cache maintenance activities and then build a transition graph where nodes are the seven maintenance categories and directed edges represent observed consecutive transitions. They compute transition probabilities and time-to-transition in days for each edge, then prune edges with probability below 0.05 to focus on recurring patterns. The paper does not report a train/test split or predictive objective here; the Markov model is descriptive, used to summarize recurrent evolution patterns rather than to forecast them. In RQ3, the quantitative transition patterns are paired with qualitative sampling: for each target change type, they sample commits, inspect workflow diffs, commit messages, and linked PRs when available, and tag each change as human- or bot-introduced based on author identity and automation signals.
A concrete end-to-end example appears in the workflow illustration around Fig. 1. A single job named test on ubuntu-latest checks out code, sets up Java, and then includes two cache steps using actions/cache: one for Gradle cache files under ~/.gradle/caches and another for Maven’s local repository under ~/.m2. The cache keys include the runner OS and a hash of dependency files, so the cache is reused when dependencies are unchanged and refreshed when lockfiles change. This example is used to ground the taxonomy: the job has multiple caches, multiple paths, and a key strategy tied to dependency definitions. The analysis then generalizes across all adopters to count such steps, classify them into mechanism types, and trace how they evolve over time. Reproducibility is partly supported: the authors say the replication package is publicly available on GitHub. The source dataset and Gigawork are cited, but the excerpt does not specify frozen artifacts, exact seeds, or whether all intermediate labels are released; for the qualitative samples, the sampling procedure is described but the exact sample sizes are said to appear in the RQ3 section not present in the excerpt.
Technical innovations
- A cache-centric taxonomy of workflow maintenance that separates cache enablement, version updates, additions/removals, and parameter edits, rather than treating caching as a binary feature.
- A broader operational definition of CI/CD caching in GitHub Actions that includes explicit actions/cache, package-manager caching via setup actions, and Docker layer caching.
- A first-order Markov transition analysis of cache maintenance activity sequences, with per-job-type transition graphs and time-to-transition statistics.
- A mixed-methods link between quantitative change sequences and qualitative commit/PR evidence to explain why cache-related edits occur.
Datasets
- 952 GitHub Actions repositories (266 cache adopters, 686 non-adopters) — curated by Bouzenia and Pradel (2024)
- 1,556 workflow files — reconstructed from Git history for the 266 adopters
- 10,373 commits — reconstructed workflow history up to May 5, 2025
- 17,185 workflow configuration changes — 2,494 cache-related changes identified by the authors
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.13129.
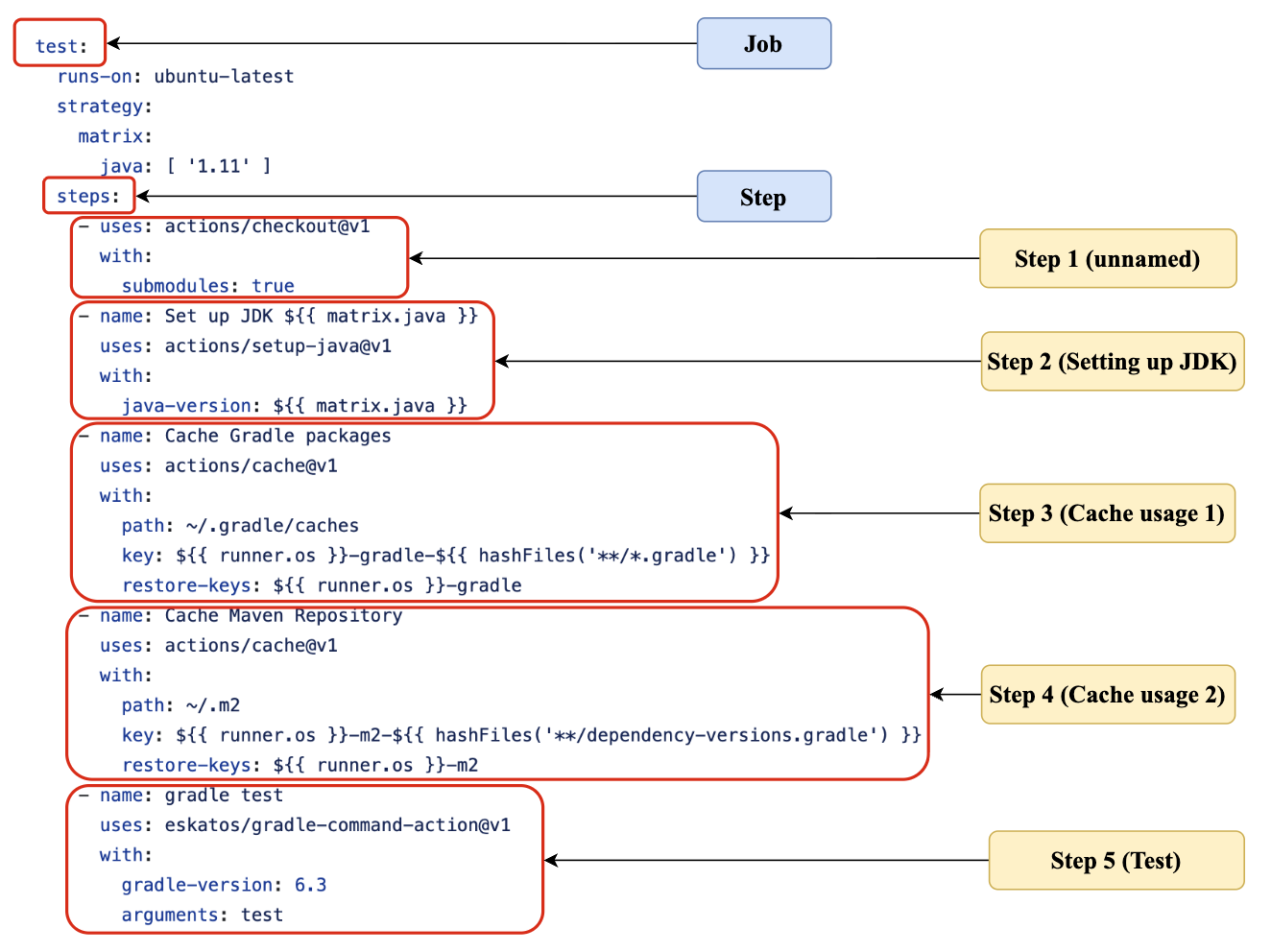
Fig 1: An example of GitHub Actions workflow illustrating jobs, steps, and
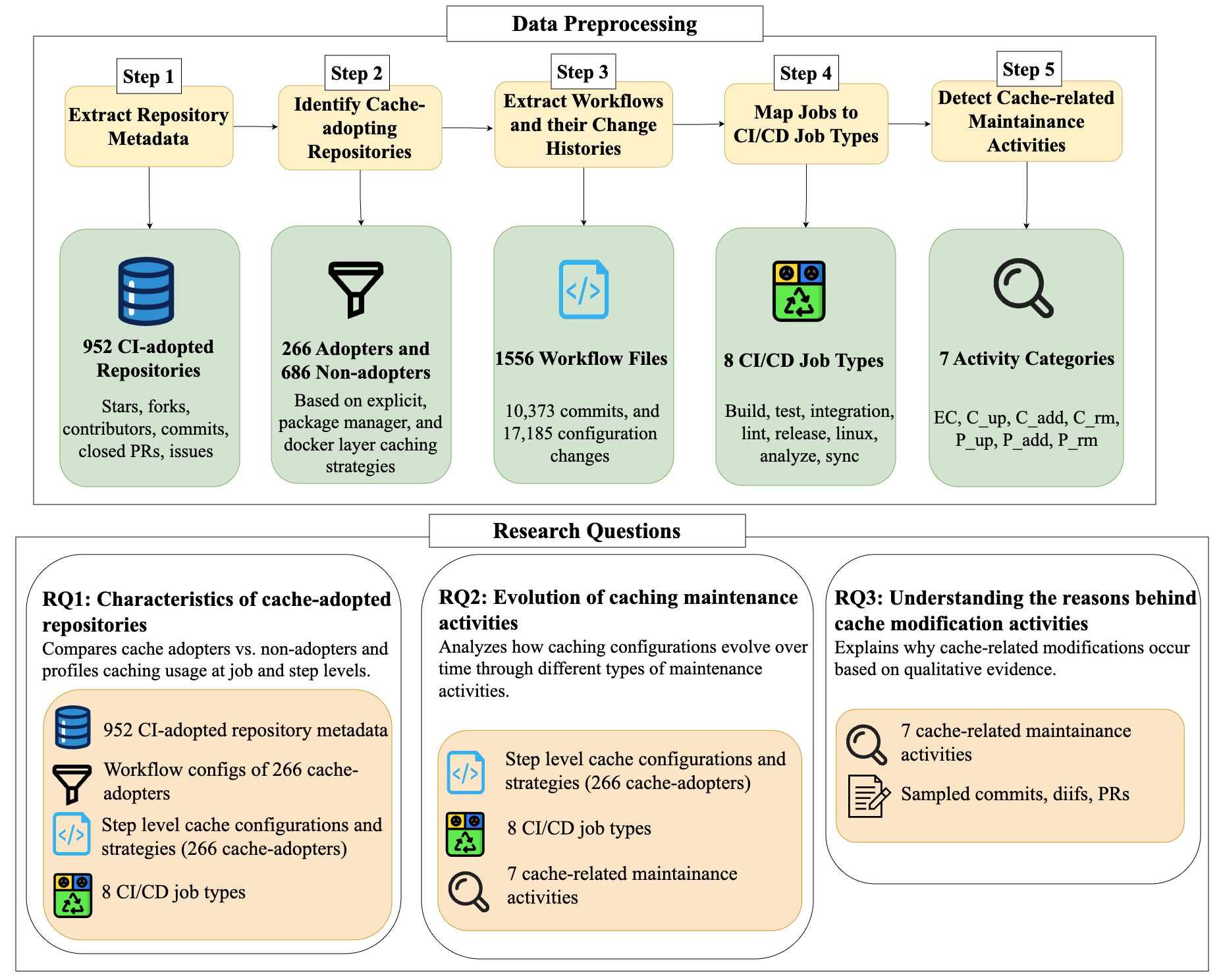
Fig 2: Overview of our study.
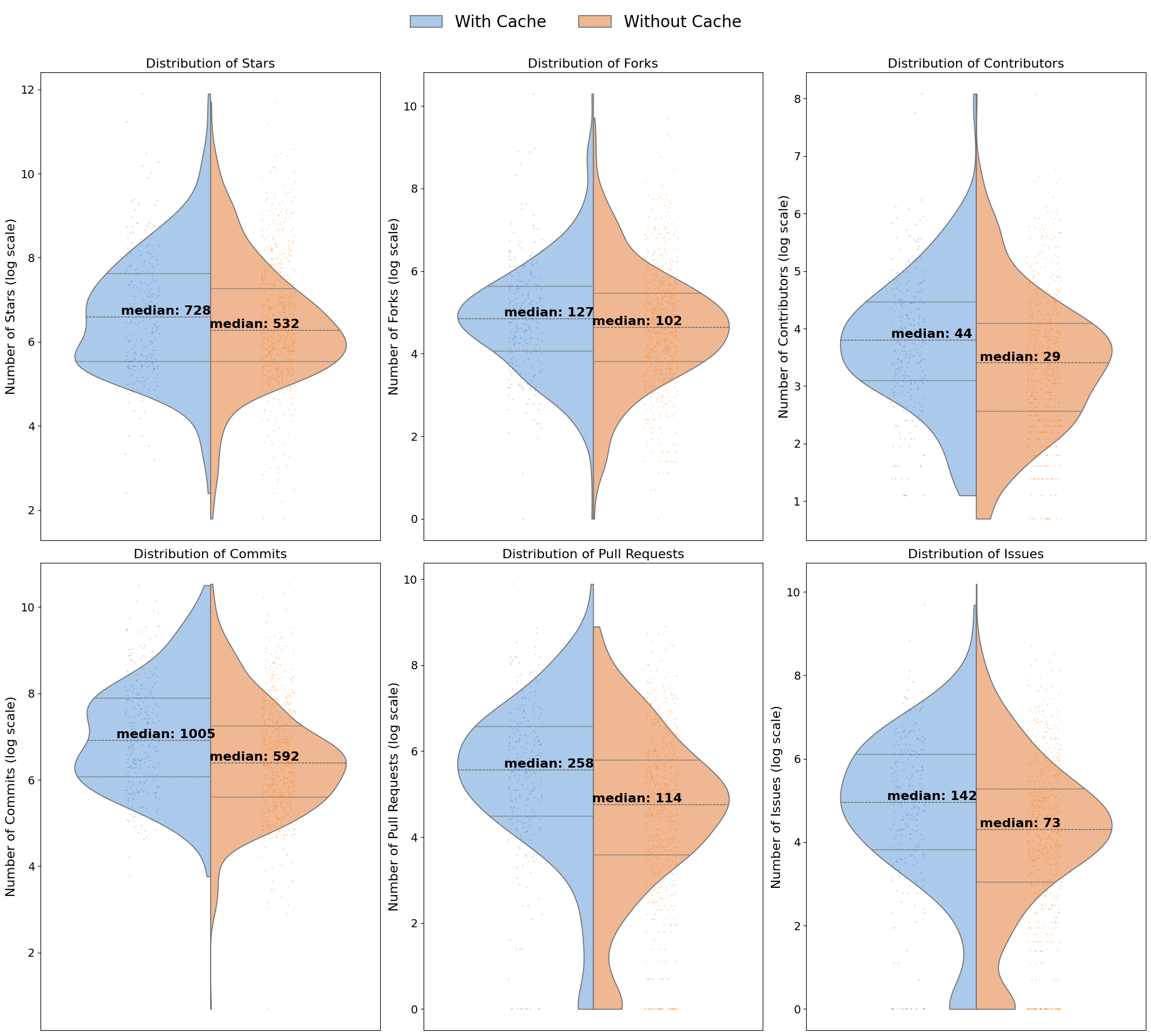
Fig 3: Distributions of repository characteristics for cache-adopting (with) and
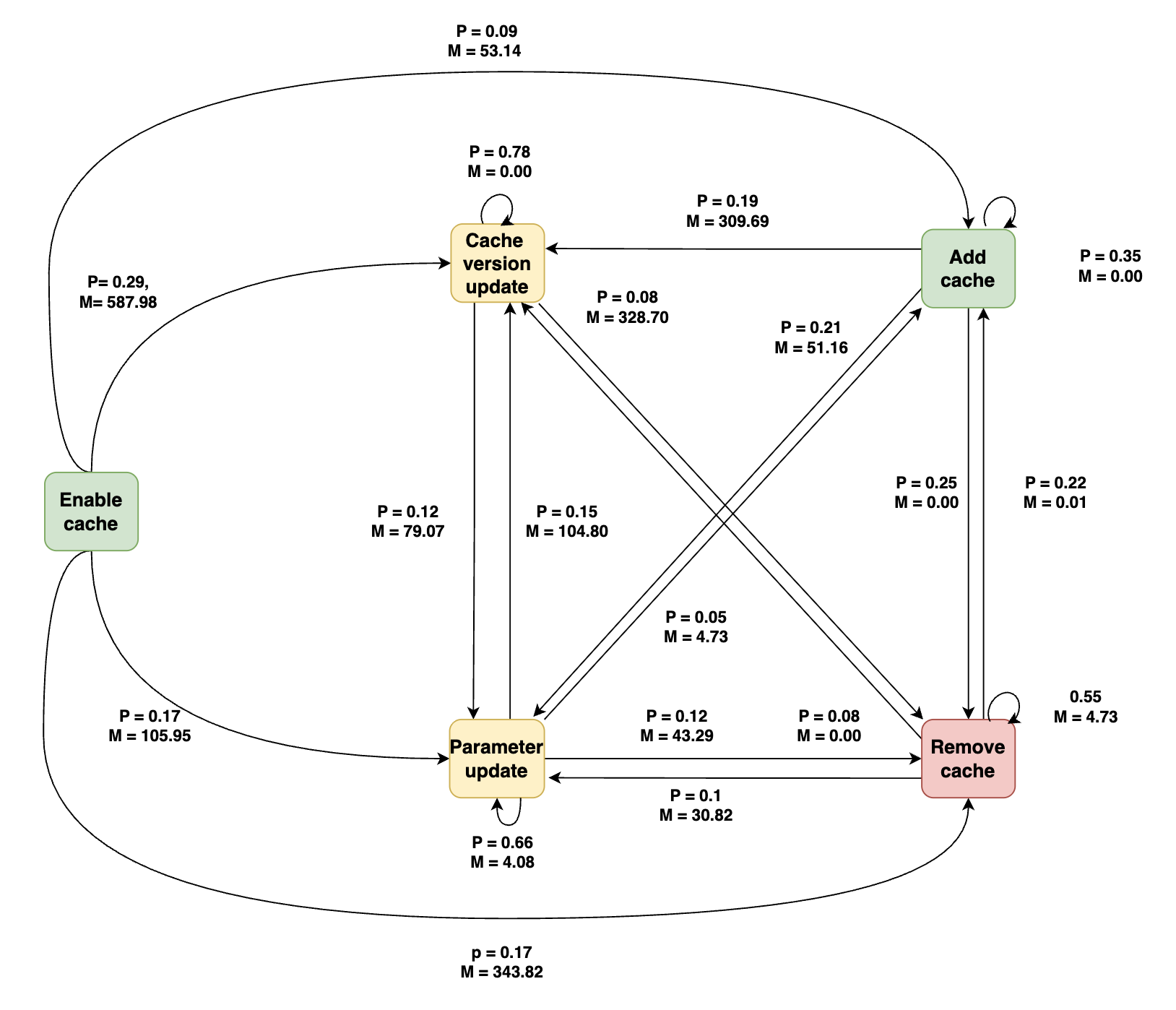
Fig 4: Cache-related maintenance activities in build jobs after enabling caching.
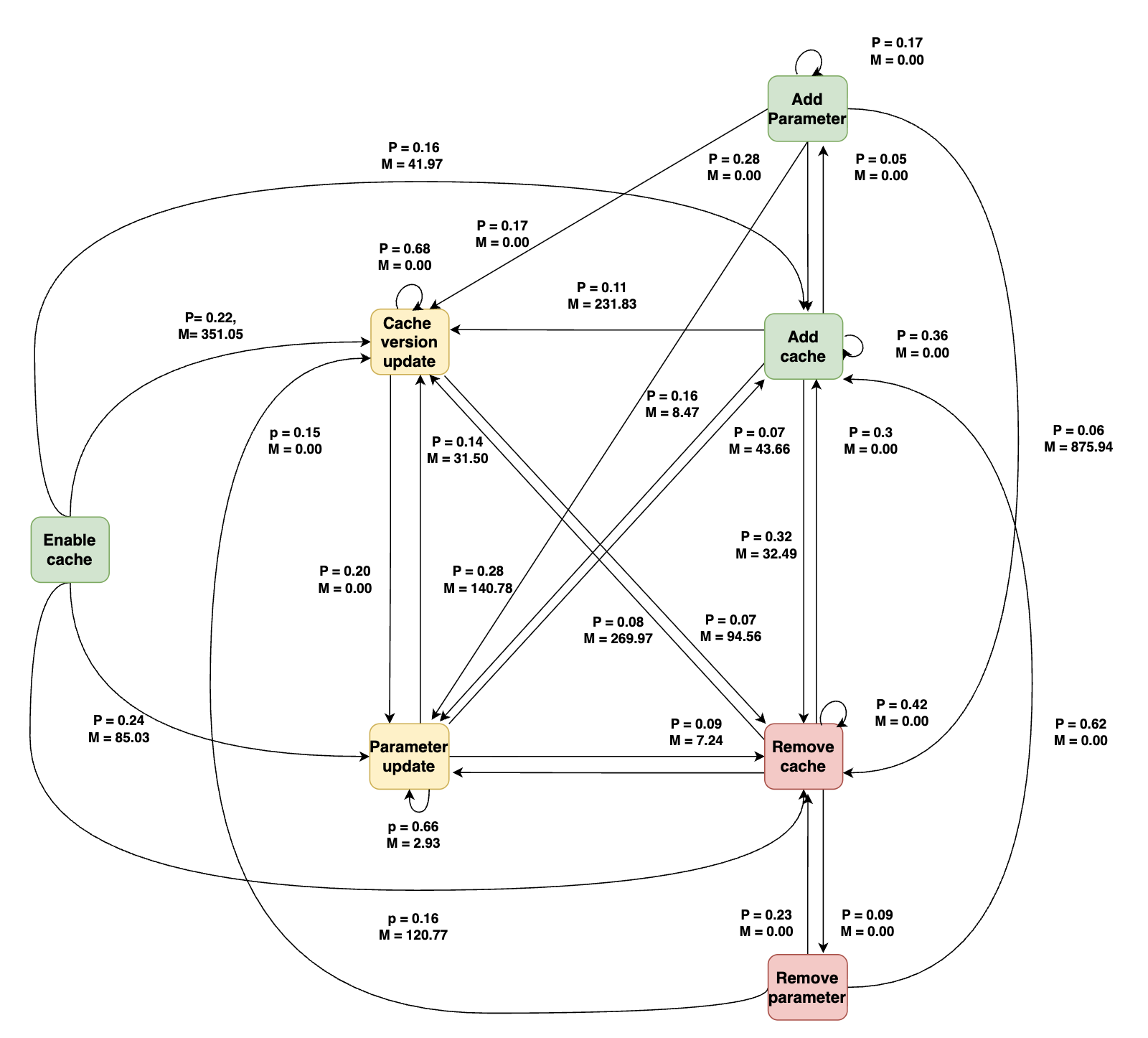
Fig 5: Cache-related maintenance activities in test jobs after enabling caching.
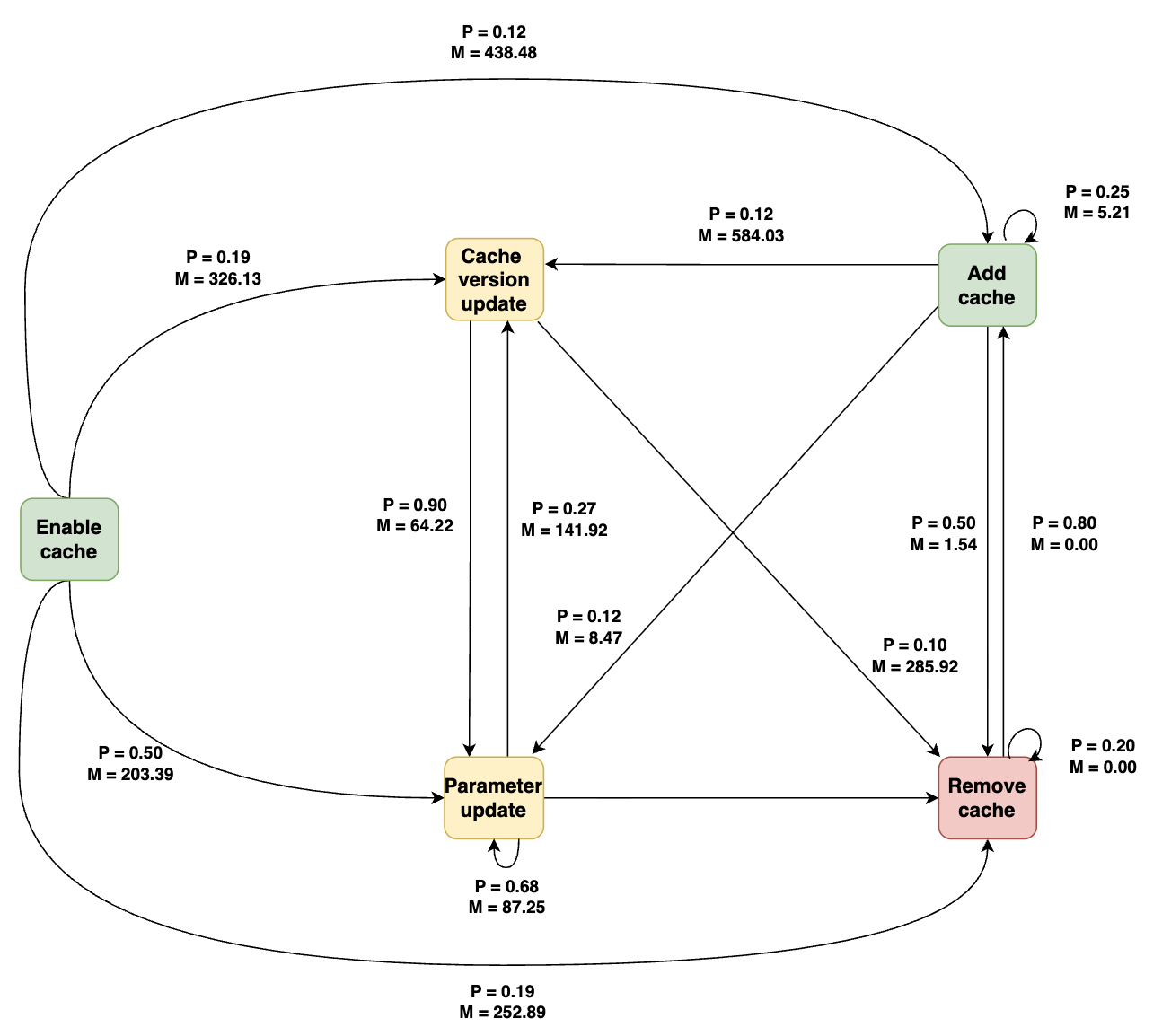
Fig 6: Cache-related maintenance activities in integration jobs after enabling
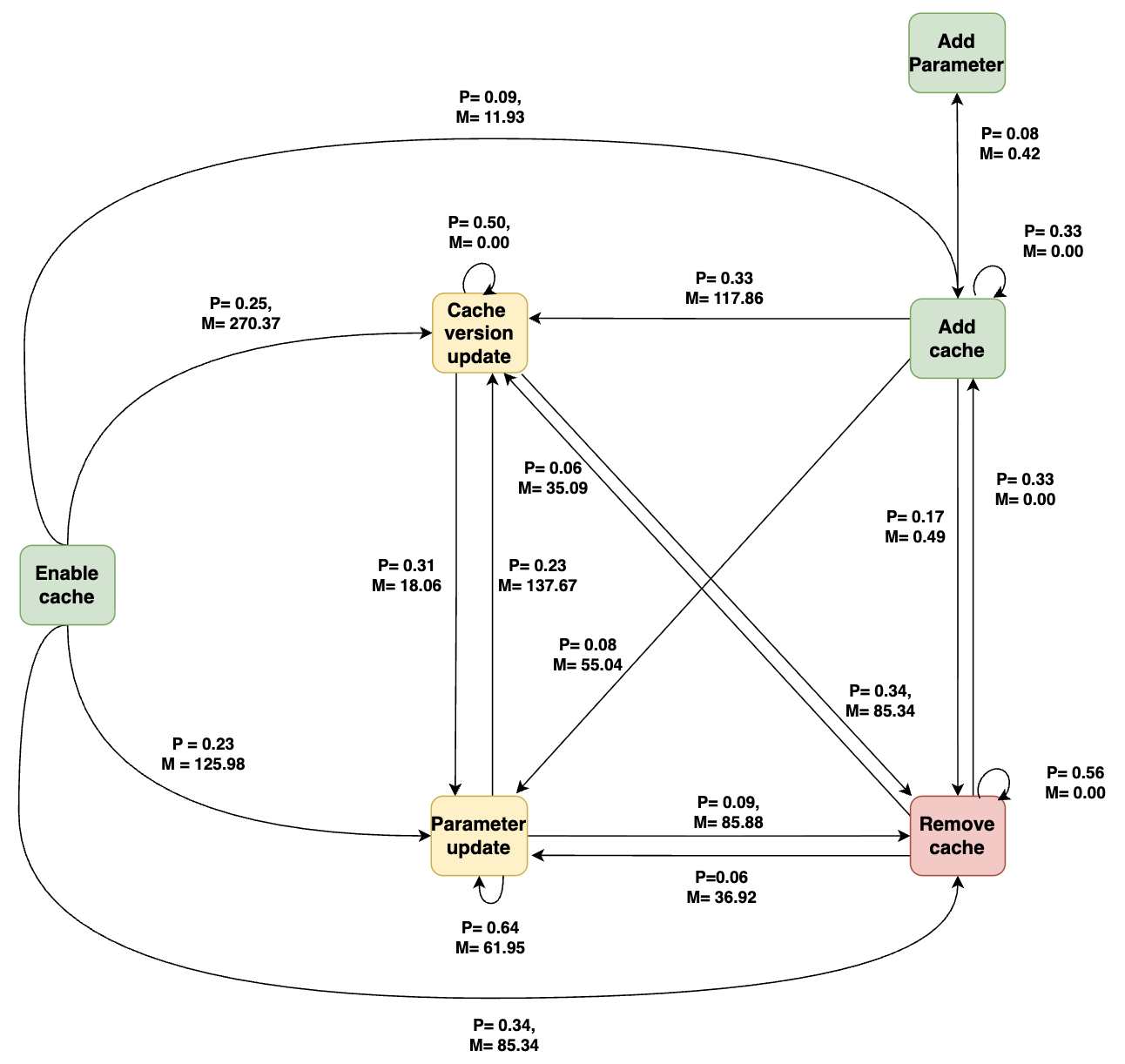
Fig 7: Cache-related maintenance activities in release jobs after enabling
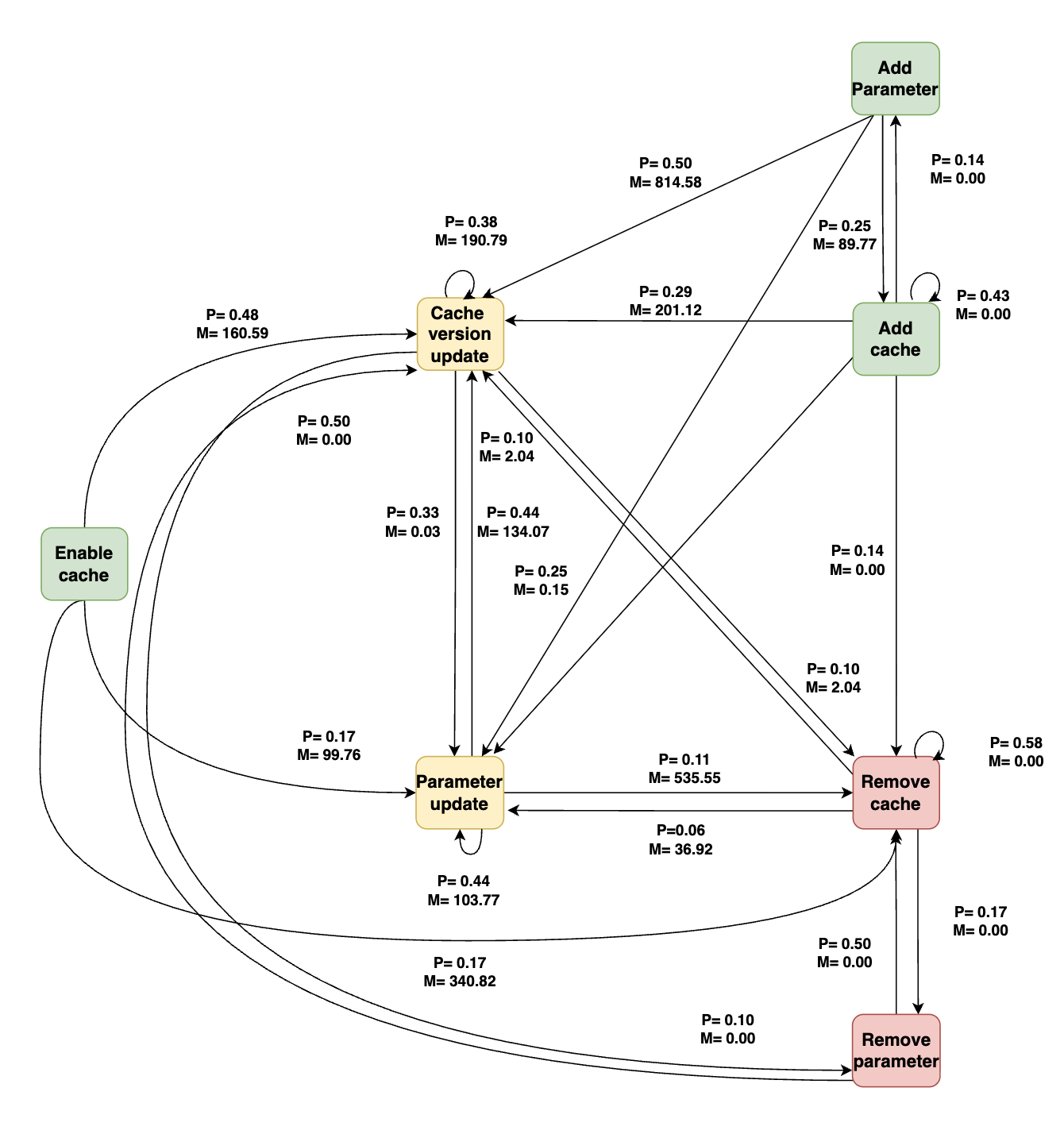
Fig 8: Cache-related maintenance activities in lint jobs after enabling caching.
Limitations
- This is an observational study on GitHub Actions only, so the findings may not transfer cleanly to other CI/CD systems such as Jenkins, CircleCI, or Travis CI.
- The adopter/non-adopter comparison is correlational; the paper does not establish that higher activity causes caching adoption or vice versa.
- The evolution model is descriptive (first-order Markov) and prunes low-probability transitions below 0.05, so rarer but potentially important maintenance paths may be underrepresented.
- RQ3 relies on sampled commits, diffs, commit messages, and PR context; if messages are sparse or bots are misclassified, the inferred reasons for changes may be noisy.
- The excerpt does not report inter-rater agreement, so it is unclear whether manual coding or taxonomy assignment was independently validated.
- The study focuses on workflow configuration histories, not runtime outcomes such as actual speedups, cache hit rates, or failure rates after changes.
Open questions / follow-ons
- How do cache-related maintenance patterns differ when measured against runtime outcomes such as cache hit rate, job duration, or flaky build frequency?
- Would a tool that suggests cache-key/path changes reduce the high volume of human-driven parameter updates observed here?
- How often do cache configurations fail silently or regress when dependencies or runner environments change, and can those failures be detected automatically?
- Do the same adoption and evolution patterns hold in other CI/CD systems, or are they specific to GitHub Actions’ caching primitives and ecosystem integrations?
Why it matters for bot defense
For a bot-defense or CAPTCHA engineer, this paper is useful less as a direct anti-bot technique and more as a maintenance-pattern study for automation-heavy systems. It shows that once an optimization is embedded into a workflow, developers spend real effort continuously tuning parameters, responding to failures, and absorbing bot-generated dependency updates. That is a good reminder that any anti-abuse or challenge mechanism integrated into CI/CD or developer tooling should be designed for low-maintenance operation, clear diagnostics, and safe updates; otherwise, the operational burden can become the bottleneck.
The job-type breakdown is also relevant: build and test phases are where repeated work is most common and where maintenance churn is fastest. If a bot-defense component were inserted into those stages, it would need stable defaults and strong compatibility guarantees, because the study suggests teams already do iterative edits there. More broadly, the human-versus-bot distinction in cache updates highlights an engineering pattern common in automation systems: some changes are reactive fixes by developers, while others arrive later as machine-driven dependency maintenance. A defense or verification system should probably expect both rhythms and instrument them separately.
Cite
@article{arxiv2604_13129,
title={ How Developers Adopt, Use, and Evolve CI/CD Caching: An Empirical Study on GitHub Actions },
author={ Kazi Amit Hasan and Yuan Tian and Safwat Hassan and Steven H. H. Ding },
journal={arXiv preprint arXiv:2604.13129},
year={ 2026 },
url={https://arxiv.org/abs/2604.13129}
}