
BRIDGE and TCH-Net: Heterogeneous Benchmark and Multi-Branch Baseline for Cross-Domain IoT Botnet Detection
Source: arXiv:2604.11324 · Published 2026-04-13 · By Ammar Bhilwarawala, Likhamba Rongmei, Harsh Sharma, Arya Jena, Kaushal Singh, Jayashree Piri et al.
TL;DR
BRIDGE is presented as a response to two intertwined problems in IoT botnet detection: most papers only report single-dataset results, and the available IoT security datasets use incompatible feature spaces that make principled multi-dataset training hard. The authors propose a 46-feature canonical vocabulary grounded in CICFlowMeter semantics, then map five heterogeneous datasets into that shared space using genuine-equivalence-only matching and explicit zero-filling for missing fields. They pair that benchmark with a leave-one-dataset-out (LODO) protocol so generalization across capture environments is measurable rather than anecdotal.
On top of BRIDGE, they introduce TCH-Net, a multi-branch detector that combines temporal, contextual, and statistical views of each flow window. The temporal path itself has three subpaths to capture local, coarse, and global patterns; fusion happens through Cross-Branch Gated Attention Fusion (CB-GAF), which uses learnable sigmoid gates to modulate how much each branch can influence the others. The reported result is that BRIDGE exposes a severe domain-shift problem—evaluated architectures land around mean LODO F1 of 0.39 to 0.47, while the strongest community baseline reaches 0.5577—and TCH-Net becomes the best reported model on BRIDGE, with F1 0.8296 ± 0.0028, AUC 0.9380 ± 0.0025, and MCC 0.6972 ± 0.0056 across five seeds, beating twelve baselines with p < 0.05 under a paired Wilcoxon test.
Key findings
- BRIDGE unifies five heterogeneous datasets—CICIDS-2017, CIC-IoT-2023, Bot-IoT, Edge-IIoTset, and N-BaIoT—into a 46-feature canonical vocabulary with disclosed per-dataset coverage ranging from 15% to 93%.
- The benchmark is genuinely heterogeneous: CICIDS-2017 covers 43/46 canonical slots (93%), CIC-IoT-2023 covers 40/46 (87%), Bot-IoT covers 18/46 (39%), Edge-IIoTset covers 10/46 (22%), and N-BaIoT covers 7/46 (15%).
- Under the leave-one-dataset-out protocol, the five evaluated deep learning architectures achieve mean LODO F1 only in the 0.39–0.47 range, showing large cross-dataset degradation.
- The paper reports a community generalization baseline of mean LODO F1 = 0.5577, which is substantially below TCH-Net’s reported overall performance and is positioned as the first formally quantified cross-dataset baseline for this setting.
- TCH-Net reports F1 = 0.8296 ± 0.0028, AUC = 0.9380 ± 0.0025, and MCC = 0.6972 ± 0.0056 across five random seeds.
- The authors state TCH-Net outperforms all twelve baselines with statistical significance under a paired Wilcoxon signed-rank test (p < 0.05).
- Component ablation indicates CB-GAF is necessary; removing it degrades F1 by about 0.054 relative to the full model, and removing the multi-scale temporal encoding (MSTE) also costs about 0.054 F1.
- The preprocessing pipeline uses a strict 1:1 benign-to-attack balance, a shared RobustScaler fit only on training data, and leakage checks that confirm zero identical feature vectors between train and test partitions.
Threat model
The adversary is implicit and environmental rather than interactive: the detector must generalize across different IoT datasets, capture tools, device categories, and attack scenarios without assuming the test environment matches training. The attacker can change network behavior by using different botnet toolkits or operating in a different capture environment, but the paper does not assume the attacker can tamper with the benchmark labels, poison the training set, or adaptively probe the model in a white-box manner. The core threat is distribution shift across domains, not deliberate feature-space adversarial manipulation.
Methodology — deep read
The security problem is framed as cross-domain IoT botnet detection under domain shift. The adversary is not modeled as a white-box evader of the detector; instead the key challenge is that the deployment environment differs from the training environment, so a detector that looks excellent on one benchmark may fail when the capture tool, device population, or attack toolkit changes. The benchmark is explicitly designed to measure generalization when one entire dataset is held out. The paper does not claim an active adversary who manipulates features to bypass the model, nor does it discuss adversarial machine-learning attacks in the classic evasion/poisoning sense.
BRIDGE uses five publicly available datasets: CICIDS-2017, CIC-IoT-2023, Bot-IoT, Edge-IIoTset, and N-BaIoT. They were chosen for structural diversity: CICFlowMeter-based flow datasets, Argus session-level records, Wireshark packet-level captures, and Kitsune statistical fingerprints. The authors define a 46-feature canonical vocabulary, grouped into four semantic families: flow dynamics, packet-size/IAT statistics, TCP flag indicators, and header/window features. Mapping is constrained by “genuine equivalence only,” meaning a source field is only aligned to a canonical slot if it measures the same quantity with the same computational definition. They use a three-stage alias procedure: exact case-insensitive match, exact alias match, then substring match of at least five characters. If no true equivalent exists, the slot is explicitly zero-filled. Coverage is highly uneven: 93% for CICIDS-2017, 87% for CIC-IoT-2023, 39% for Bot-IoT, 22% for Edge-IIoTset, and 15% for N-BaIoT. This matters because it lets the reader see where the benchmark is semantically dense versus structurally sparse, rather than hiding missingness inside projection methods like PCA.
After mapping, all values are converted to 32-bit floats, non-numeric/NaN/infinite values are set to zero, and the datasets are class-balanced to a 1:1 benign-to-attack ratio. The paper says pilot experiments with 3:1 and 1:3 ratios led to class collapse in low-attack datasets, so they preserve at least 5,000 samples per class. A shared RobustScaler is fit on the training data only, using the median and the 5th-to-95th percentile range, and the scaled values are clipped to [-10, 10]. The authors intentionally use one shared scaler across datasets to avoid normalizing away inter-dataset differences that are important for domain generalization. They then sort flows by arrival time and apply a sliding window of length 32 and stride 4, assigning each window a majority-vote label. Sequences are capped at 800,000 for training and 200,000 for testing. They also create a context vector containing the source dataset ID and inferred device category, which later feeds the contextual branch.
The evaluation protocol has two layers. First, there is a general train/test preprocessing split with leakage checks: the scaler is fitted before any test access, hash-based overlap detection confirms no identical feature vectors appear in both partitions, and the benign/attack ratio is similar in train and test. Second, the benchmark uses a leave-one-dataset-out setup to measure generalization: train on four datasets, test on the held-out fifth, and repeat across all five datasets. The paper reports that under this protocol, five evaluated deep learning architectures only reach mean LODO F1 between 0.39 and 0.47, whereas the authors’ “community baseline” reaches 0.5577 mean LODO F1. The paper also compares TCH-Net against twelve baselines and reports statistical significance using a paired Wilcoxon signed-rank test over five random seeds. The metrics emphasized are F1, AUC, and MCC, which is appropriate because accuracy would be misleading under the class imbalance and domain shift they are trying to expose.
TCH-Net consumes a 32-step sequence of 46-dimensional canonical flow vectors plus the context vector. Before branching, a shared projection module applies a two-layer residual feed-forward block: Linear(46→92) → LayerNorm → GELU → Dropout(δ/2) → Linear(92→46) → LayerNorm, wrapped in a residual connection so the network can learn feature interactions like ratios and cross-feature products without losing the raw semantics. The architecture then splits into three branches. The Temporal branch is the most complex: Path 1 is a residual depthwise-separable convolutional stack with squeeze-excitation followed by a two-layer BiGRU; Path 2 is a stride-2 convolution followed by a one-layer BiGRU; Path 3 is a two-layer pre-LayerNorm Transformer over the full 32-step window. All three paths are aligned to a shared 8-step temporal grid and fused via multi-head self-attention. The Contextual branch embeds dataset identity and device category so the model can condition on provenance. The Statistical branch handles distributional summaries. The three branches are combined through Cross-Branch Gated Attention Fusion (CB-GAF), where each branch attends to the others and a learnable sigmoid gate suppresses unhelpful cross-branch information. A residual classification head and an auxiliary reconstruction decoder complete the model. The paper’s own concrete example is DDoS-like traffic: short bursty patterns are expected to be captured by the local Conv-SE-BiGRU path, periodic C&C-like behavior by the medium-scale BiGRU path, and longer-range ordering by the Transformer path; the gate then decides which view should dominate given the dataset provenance and coverage profile.
Technical innovations
- A formally specified heterogeneous multi-dataset benchmark for IoT intrusion detection with explicit semantic feature alignment and disclosed coverage statistics, instead of ad-hoc feature matching or single-dataset evaluation.
- A 46-feature canonical vocabulary grounded in CICFlowMeter semantics, with genuine-equivalence-only mapping and explicit zero-filling for missing features.
- A leave-one-dataset-out evaluation protocol that makes cross-dataset generalization measurable on five structurally distinct IoT security datasets.
- Cross-Branch Gated Attention Fusion (CB-GAF), which uses learnable sigmoid gates to control cross-branch information flow across temporal, contextual, and statistical representations.
- A three-path temporal encoder that combines residual Conv-SE-BiGRU, strided BiGRU, and pre-LayerNorm Transformer paths to cover local, coarse, and global temporal scales.
Datasets
- CICIDS-2017 — 33,671 post-balanced records — public dataset
- CIC-IoT-2023 — 6,965 post-balanced records — public dataset
- Bot-IoT — 38 post-balanced records in the reported test subset — public dataset
- Edge-IIoTset — 54,386 post-balanced records — public dataset
- N-BaIoT — 23,612 post-balanced records — public dataset
Baselines vs proposed
- Community generalization baseline: mean LODO F1 = 0.5577 vs proposed: mean LODO F1 reported above 0.8296 overall (LODO-specific per-dataset values not fully enumerated in the excerpt).
- Evaluated deep learning architectures (5 models): mean LODO F1 = 0.39–0.47 vs proposed: highest LODO F1 overall (exact per-model values not provided in the excerpt).
- All twelve baselines: statistical comparison p < 0.05 (paired Wilcoxon signed-rank test) vs proposed: F1 = 0.8296 ± 0.0028, AUC = 0.9380 ± 0.0025, MCC = 0.6972 ± 0.0056.
- TCH-NovAbl without CB-GAF: F1 drops by approximately 0.054 vs proposed: full-model F1 reported above.
- TCH-NovAbl without multi-scale temporal encoding (MSTE): F1 drops by approximately 0.054 vs proposed: full-model F1 reported above.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.11324.
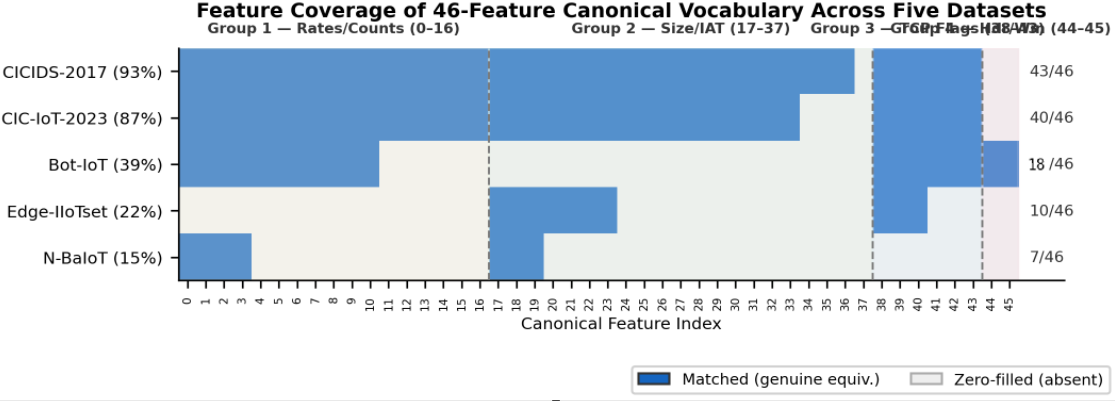
Fig 1: Feature coverage of the 46-feature canonical vocabulary across five BRIDGE datasets. Blue cells indicate a genuinely matched feature; grey cells indicate
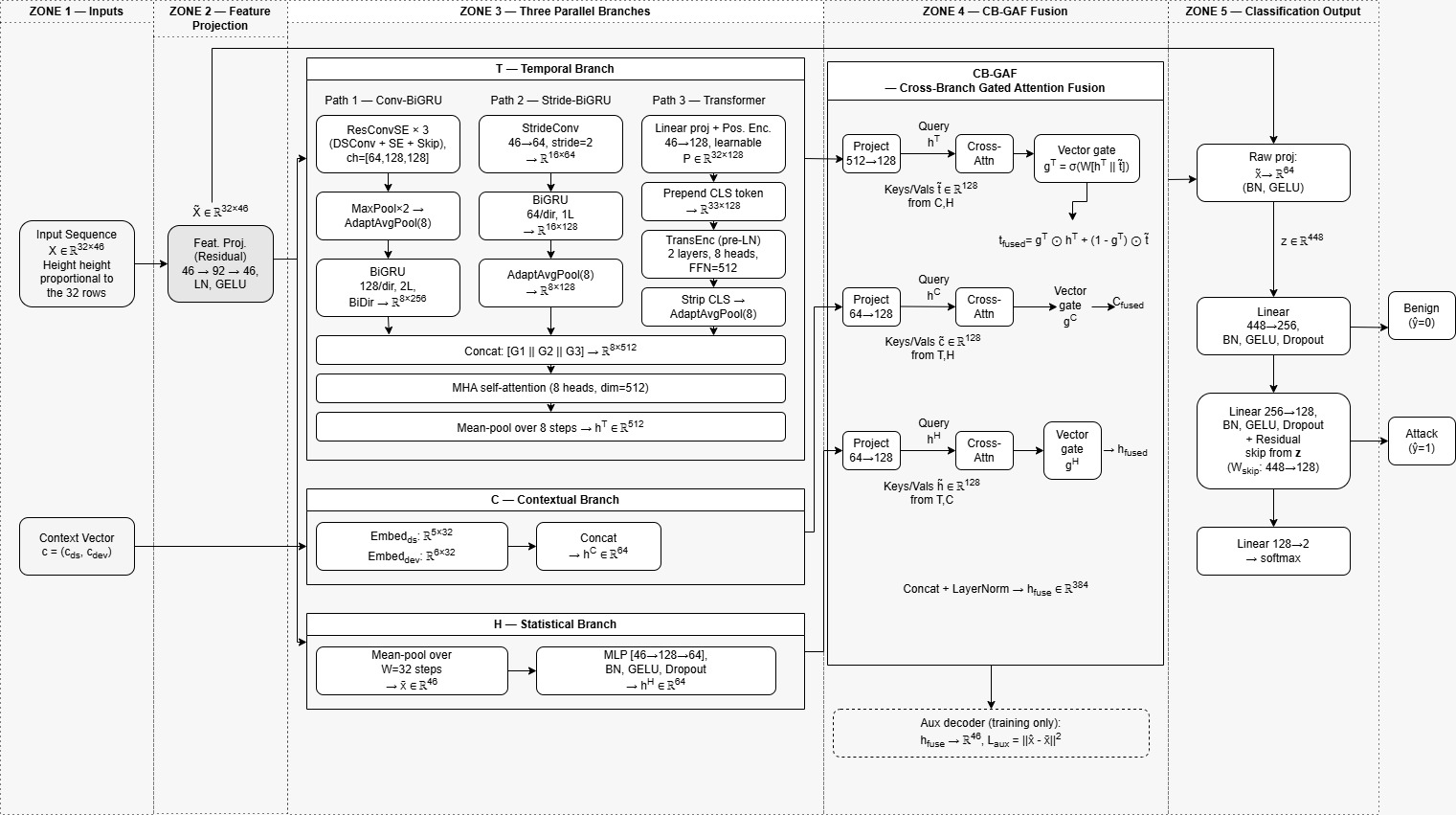
Fig 2: Full TCH-Net architecture overview across five zones: inputs, shared feature projection, three parallel branches (T, C, H), CB-GAF fusion, and classification
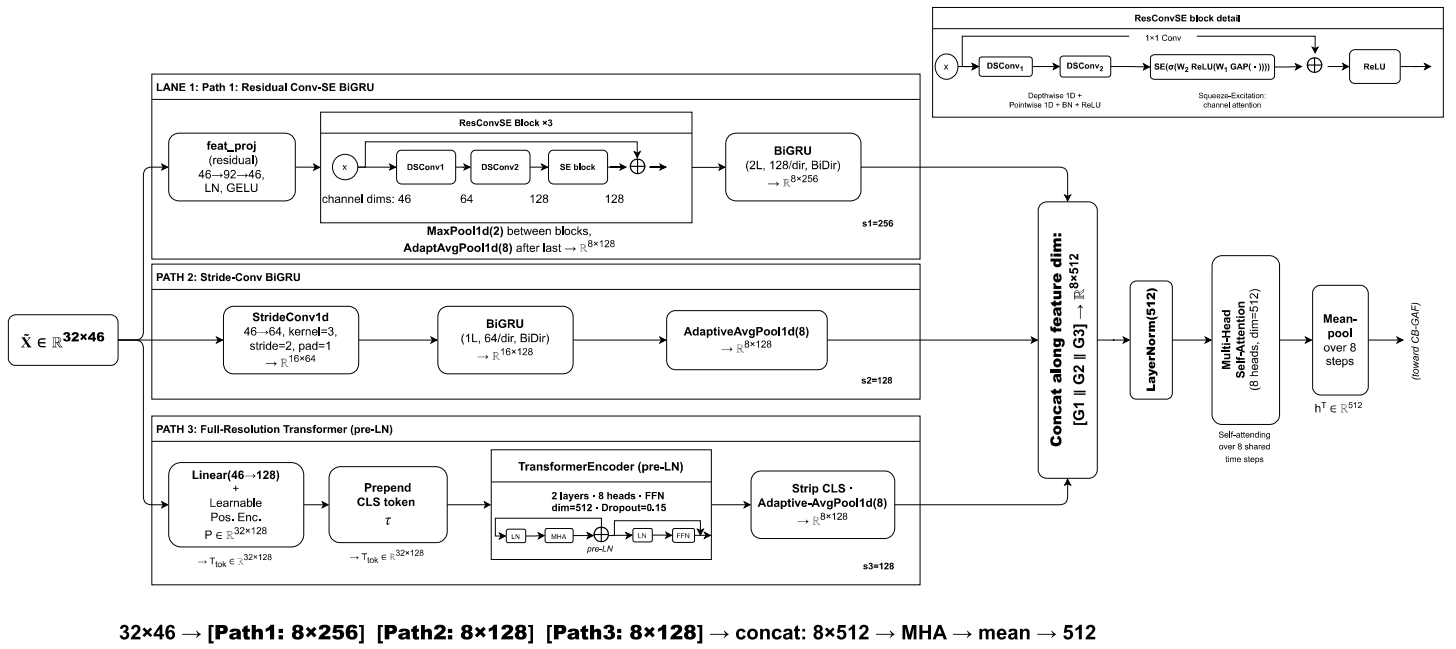
Fig 3: T-branch three-path architecture detail. Path 1: Residual Conv-SE BiGRU (local and medium-range patterns). Path 2: Stride-Conv BiGRU (coarse-scale
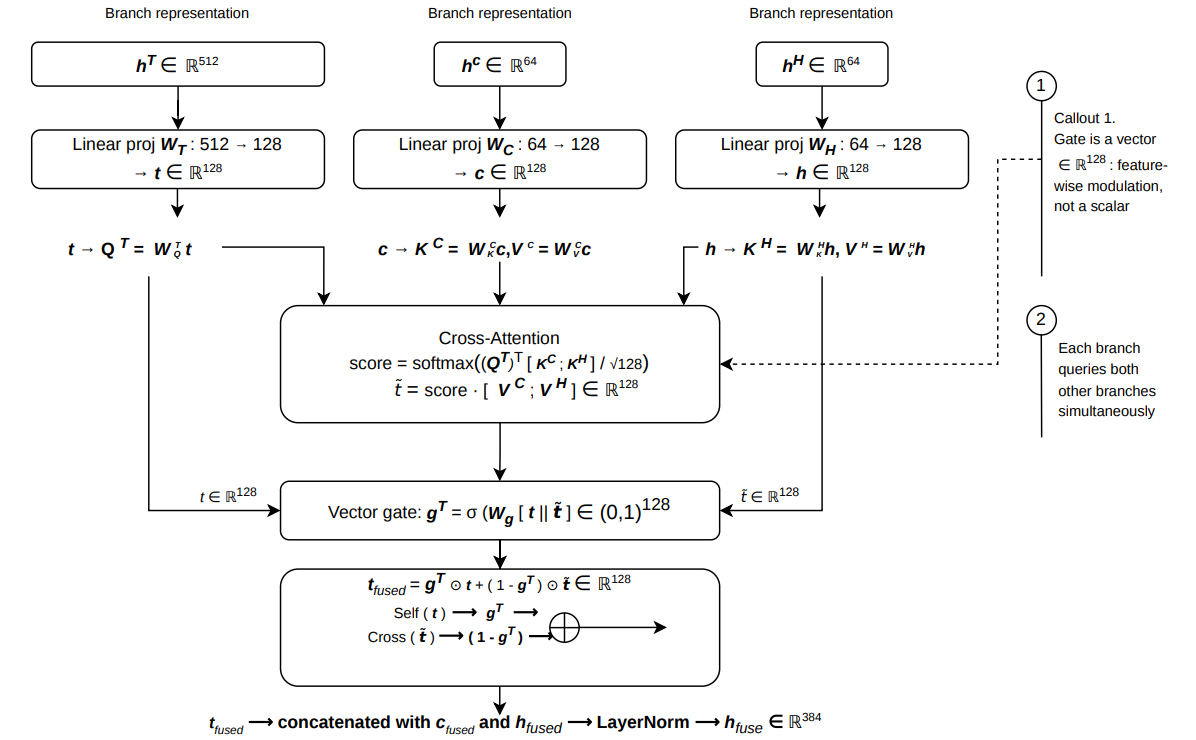
Fig 4: CB-GAF mechanism detail for branch T as a representative example. Each branch projects to a common dimension df = 128, queries other two branches
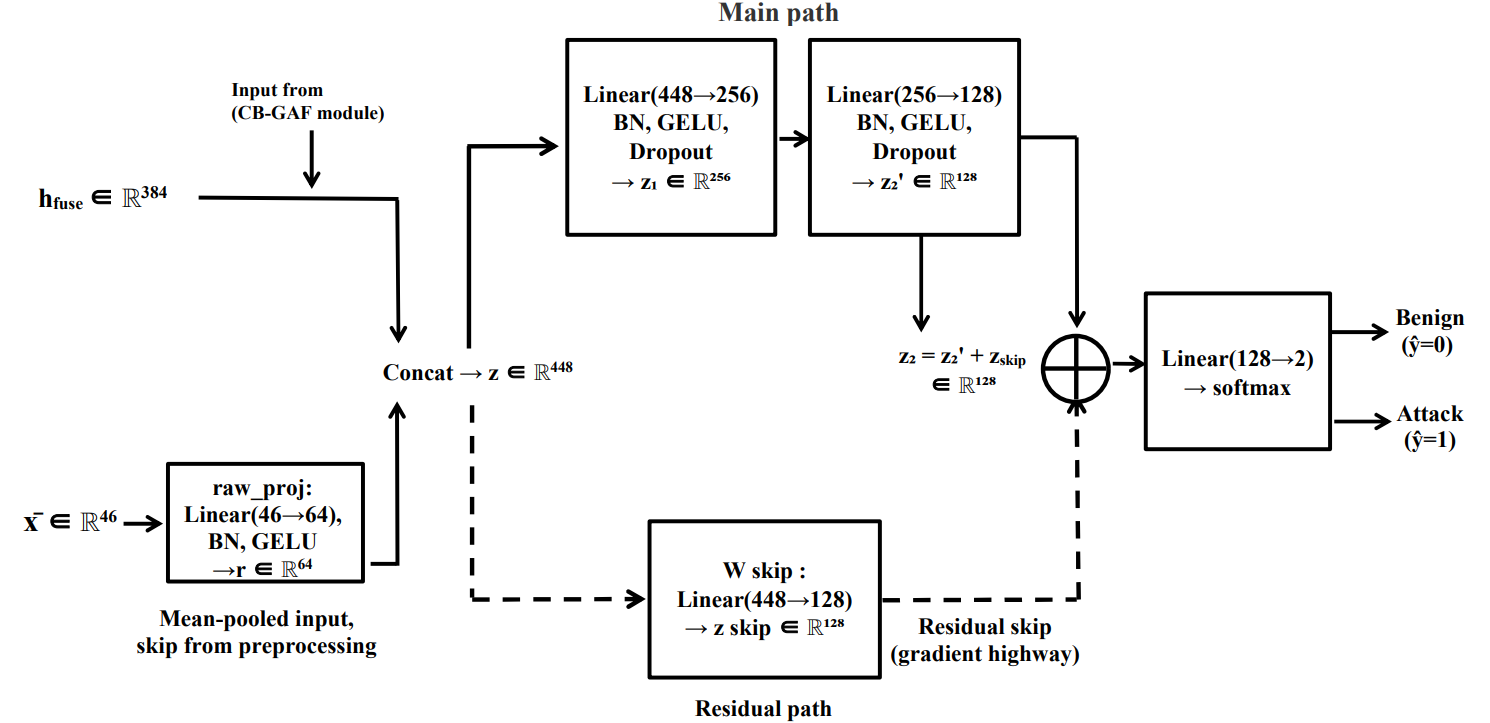
Fig 5: Classification head with residual skip connection detail. The mean-pooled input ¯x ∈R46 is projected to r ∈R64 and concatenated with hfuse to form
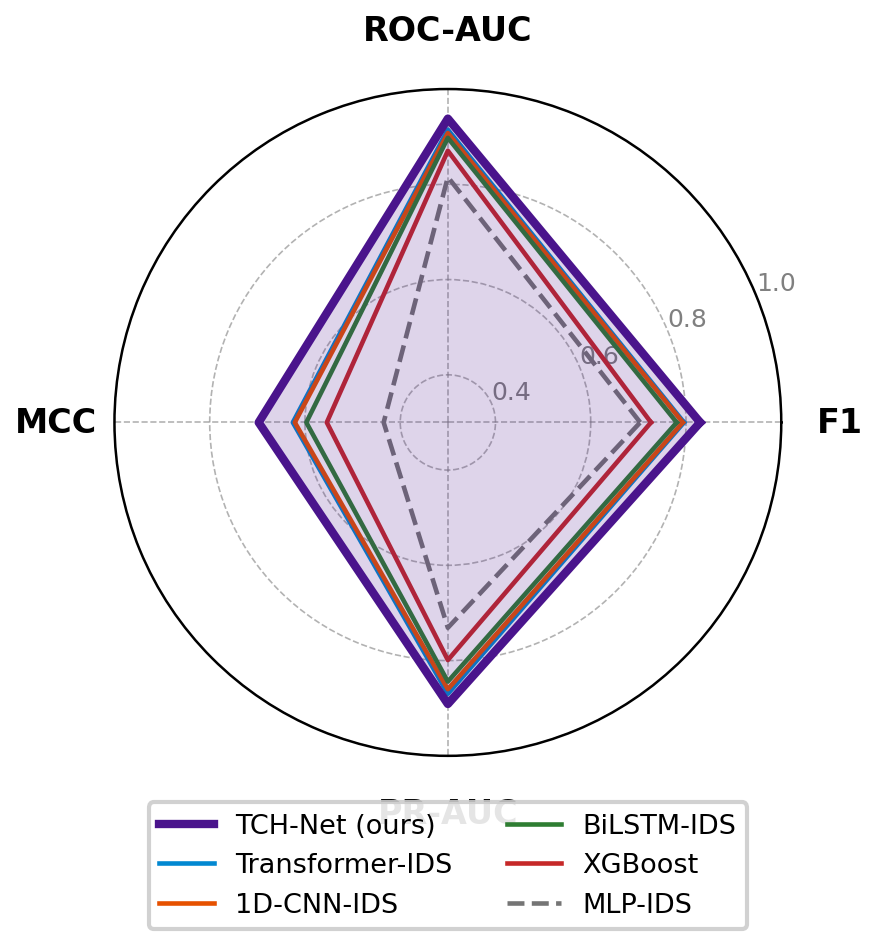
Fig 6: Radar chart comparing TCH-Net against the five strongest baselines
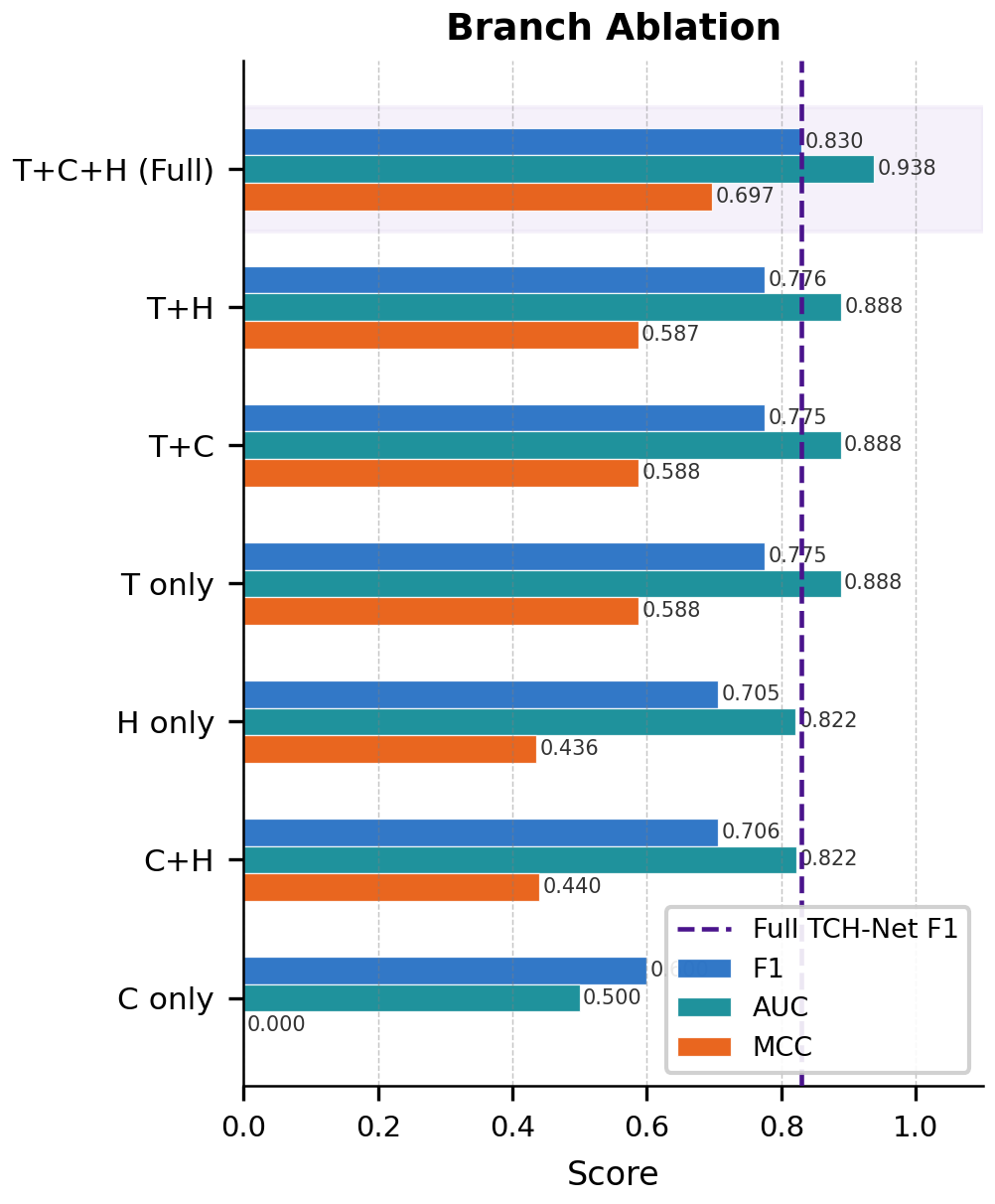
Fig 7: Branch ablation F1, AUC, and MCC scores for all seven branch subsets.
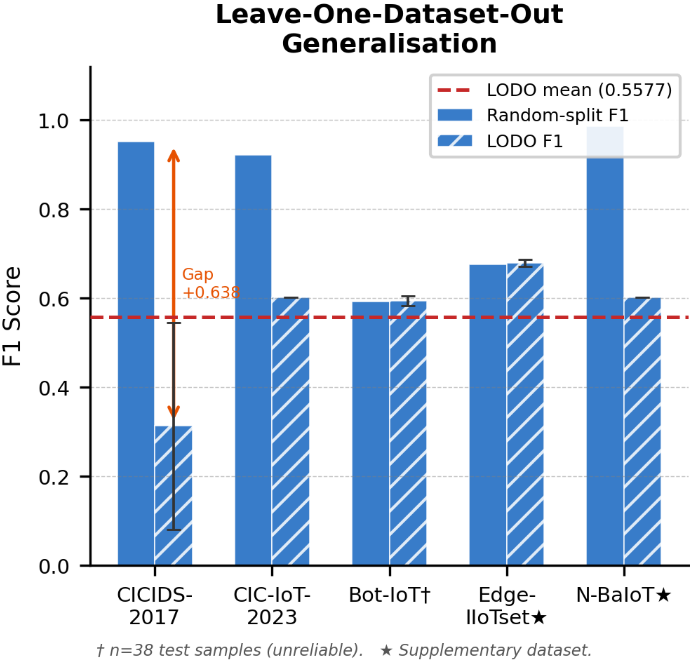
Fig 8: Leave-one-dataset-out (LODO) F1 compared to in-distribution random-
Limitations
- The excerpt does not provide full per-dataset LODO metrics for TCH-Net, so it is hard to see whether the gain is uniform or driven by one or two datasets.
- Bot-IoT has only 38 post-balancing test samples in the reported setup, which is too small for stable per-dataset estimates; the authors explicitly exclude per-dataset metrics there.
- Coverage is extremely uneven across datasets, and the lowest-coverage sources (Edge-IIoTset and N-BaIoT) rely heavily on zero-filling, which may encode dataset identity more than traffic semantics.
- The paper does not show an external validation on a completely new dataset outside BRIDGE, so “generalization” is still bounded by the five selected benchmarks.
- The excerpt mentions statistical testing but does not report effect sizes or confidence intervals for the baseline comparisons beyond the mean ± std over five seeds.
- The model includes dataset ID as an explicit contextual input; that can help calibration, but it also raises the question of how the model would behave if provenance is unknown or mislabeled at deployment.
Open questions / follow-ons
- How well does the BRIDGE canonical vocabulary transfer to additional datasets with even less flow-level structure, or to payload-free encrypted traffic where only timing and header features remain?
- Can the same LODO protocol be extended to a true unseen-capture-tool setting with a held-out tool family rather than just a held-out dataset?
- Does CB-GAF still help if dataset identity is removed at test time or if provenance labels are noisy, missing, or adversarially incorrect?
- What is the smallest canonical feature subset that preserves most of the cross-dataset gain, and does that subset remain stable across held-out datasets?
Why it matters for bot defense
For a bot-defense engineer, the useful takeaway is not the architecture itself so much as the evaluation discipline. BRIDGE shows how easy it is to overestimate a detector when training and testing come from the same capture ecosystem, and the LODO protocol is a direct template for measuring whether a bot signal still works after the environment changes. The canonical-vocabulary idea is also relevant beyond IoT: any bot-defense stack that aggregates heterogeneous signals across products, regions, or telemetry sources should make missingness and semantic mismatch explicit instead of hiding them inside feature engineering.
For practical deployment, the paper argues for two design habits. First, keep provenance and coverage visible to the model, because a detector may need to condition on which signals are present rather than pretending all sources are equivalent. Second, validate against held-out domains, not just held-out rows. For CAPTCHA or bot-mitigation systems, that means testing across different device populations, browser versions, network paths, and traffic captures, because a detector that excels on one source often collapses when the environment shifts.
Cite
@article{arxiv2604_11324,
title={ BRIDGE and TCH-Net: Heterogeneous Benchmark and Multi-Branch Baseline for Cross-Domain IoT Botnet Detection },
author={ Ammar Bhilwarawala and Likhamba Rongmei and Harsh Sharma and Arya Jena and Kaushal Singh and Jayashree Piri and Raghunath Dey },
journal={arXiv preprint arXiv:2604.11324},
year={ 2026 },
url={https://arxiv.org/abs/2604.11324}
}