
On the Capacity of Distinguishable Synthetic Identity Generation under Face Verification
Source: arXiv:2604.10641 · Published 2026-04-12 · By Behrooz Razeghi
TL;DR
This paper asks a verifier-centered question that prior synthetic-face work usually avoids: given a fixed face-recognition threshold, how many latent identities can a generator produce so that same-identity pairs still match and different-identity pairs still reject? The main contribution is a formal definition of “distinguishable identity generation capacity” for a generator-plus-recognizer pipeline, where capacity is measured in the embedding space used by the verifier, not in latent space or in visual realism metrics. The paper then shows that this capacity becomes a spherical-code packing problem when each identity maps deterministically to a single embedding, and it develops analogous lower bounds for stochastic identities concentrated around class centers.
The second half of the paper extends the same geometry to random latent sampling, which is closer to how many synthetic identity pipelines actually operate. In that setting, the key quantity is the probability that two sampled identity centers fall too close together; a union bound turns this into a high-probability lower bound on the number of admissible identities. Under a uniform center distribution, the author derives an explicit asymptotic growth exponent in embedding dimension. The reported validation is synthetic and geometric, not an end-to-end benchmark on a production face system, so the results are primarily theorem-driven rather than empirical performance claims.
Key findings
- Deterministic view-invariant capacity is exactly a spherical-code packing number over the realizable embedding set: CD(τ,0,0;g,ϕ)=A(Vg,ϕ, arccos τ), and under full angular expressivity it reduces to the classical AD(arccos τ) (Proposition 7).
- For centered stochastic identities, a sufficient admissibility condition is center separation by arccos(τ)+2ρ, where ρ is the within-identity cap radius; Theorem 10 maps this to admissibility with error tolerances inflated to 1-(1-η)^2 on both same- and different-identity constraints.
- Under full (ρ,η)-angular expressivity, the achievable restricted capacity satisfies C^{(ρ,η)}_D(τ,1-(1-η)^2,1-(1-η)^2;g,ϕ) ≥ A_D(ψ_τ(ρ)) with ψ_τ(ρ)=arccos(τ)+2ρ (Theorem 15).
- The spherical-code packing number is sandwiched by cap-volume bounds: 1/V_D(ψ) ≤ A_D(ψ) ≤ 1/V_D(ψ/2) (Propositions 12 and 19).
- For fixed ψ in (0,π/2), the asymptotic spherical-code exponent obeys liminf_{D→∞} (1/D) log A_D(ψ) ≥ -log(sin ψ) (Theorem 20), giving exponential growth in embedding dimension.
- In the random-code model, the capacity cannot exceed the deterministic fixed-code capacity: C^{rnd}_{D,δ}(τ,ε_in,ε_out;g,ϕ,PC) ≤ C_D(τ,ε_in,ε_out;g,ϕ) (Proposition 5).
- A union bound yields Pr[admissible] ≥ 1 - (M choose 2) q_Q(ψ_τ(ρ)), where q_Q is the pairwise separation-failure probability of identity centers (Theorem 23).
- Under uniform induced centers Q on S^{D-1}, q_Q(ψ)=V_D(ψ), and the asymptotic random-code exponent lower bound is half the deterministic exponent: liminf (1/D) log C^{rnd}_{D,δ} ≥ -(1/2) log(sin ψ_τ(ρ)) (Theorem 25).
Threat model
The adversary is a generator/user who can choose or sample latent codes and wants to maximize the number of synthetic identities that remain separable under a fixed face-verification threshold τ. They know the pipeline g and ϕ and the decision rule, and they may sample nuisance variables to create multiple views per identity; in the random-code setting they are constrained by a latent prior P_C. They cannot alter the verifier threshold, and the paper does not consider an adaptive attacker who fine-tunes the recognizer or performs adversarial optimization against the embedding map.
Methodology — deep read
The paper’s threat model is implicit and verifier-centered rather than attack-centric. The adversary is effectively a capacity-seeker: someone who can choose latent identities for a generator and wants those identities to remain mutually distinguishable under a fixed cosine-similarity threshold τ in a normalized embedding space. The system under study is a pipeline g followed by a recognition map ϕ, with outputs on the unit sphere S^{D-1}. The paper assumes the verifier is fixed and known, and that identity samples are evaluated only through the induced embedding distributions. What the adversary cannot do, in the formalism, is change the verifier threshold or the recognition map; the paper is analyzing the geometry of what the pipeline can realize, not a learned defense against active spoofing.
Data are not drawn from a real face dataset in the main theory. Instead, the “data” are induced embedding distributions P_c = Law(ϕ(g(c,U))) for latent code c and nuisance variable U, plus synthetic points sampled directly on S^{D-1} in the validation section. The paper distinguishes two operational regimes. In the fixed-code regime, latent codes c_1,…,c_M are deterministic design variables and admissibility requires that same-identity pairs exceed τ with probability at least 1-ε_in while different-identity pairs stay below τ with probability at least 1-ε_out. In the prior-constrained random-code regime, codes C_i are sampled i.i.d. from a prior P_C, and capacity is the largest M such that admissibility holds with probability at least 1-δ over the sampled codebook. The excerpt does not report a real dataset split, preprocessing pipeline, or train/validation/test split because the core results are analytic, not supervised learning results.
The key algorithmic object is geometric, not a trainable network: identity capacity is re-expressed as a packing problem on the sphere. In the deterministic view-invariant case, each identity i maps almost surely to a single unit vector u_i, and admissibility reduces to requiring pairwise angular separation ≥ arccos(τ). The relevant feasible set is V_{g,ϕ}, the set of realizable unit vectors under the pipeline. Capacity becomes A(V_{g,ϕ}, ψ_τ), and with “deterministic full angular expressivity” V_{g,ϕ}=S^{D-1}, giving the classical spherical-code number A_D(ψ_τ). In the stochastic case, each identity distribution is assumed (ρ,η)-centered: most of its mass lies in a spherical cap Cap(u_i,ρ) around some center u_i. Theorem 10 shows that if centers are separated by arccos(τ)+2ρ and 2ρ ≤ arccos(τ), then all genuine pairs and impostor pairs satisfy the threshold constraints with error terms 1-(1-η)^2. Theorem 15 uses a stronger “full (ρ,η)-angular expressivity” assumption—every direction on the sphere can be realized as a class center—to turn the spherical-code lower bound into an achievability result. The paper also defines a prior-constrained random-code capacity and proves that it is upper-bounded by the fixed-code capacity (Proposition 5), then lower-bounds it by a union bound over pairwise center collisions (Theorem 23). Under a uniform center prior, the pairwise failure probability equals the spherical cap measure V_D(ψ), yielding Theorem 25’s asymptotic exponent.
The training regime is largely inapplicable because there is no end-to-end training algorithm in the core theory. There are no epochs, batch sizes, optimizers, or random seeds reported in the provided text for the main theorems. The only “implementation-like” assumption is that the generator supports identity-preserving resampling of nuisance/style variables so one can empirically approximate P_c by repeatedly sampling U_i^{(k)} for a fixed latent identity c_i. That assumption is explicitly called out as necessary for empirical estimation of same-identity behavior. The paper is also careful to separate idealized assumptions from practical realizability: “full angular expressivity” is described as a theoretical benchmark, not a claim about current face generators. For a concrete end-to-end example, consider a centered identity with center u_i and ρ small enough that its mass lies mostly in Cap(u_i,ρ). If two such identities have centers separated by at least arccos(τ)+2ρ, then any sample from the first cap and any sample from the second cap remain below the verifier threshold τ, while two samples from the same identity stay above τ with probability at least (1-η)^2. This is the mechanism by which geometric separation translates into verification admissibility.
Evaluation is analytical plus a controlled synthetic illustration on S^{D-1}. The paper derives cap-volume upper and lower bounds for spherical codes, asymptotic lower bounds on the exponential growth rate, and a union-bound guarantee for random-code capacity. The synthetic validation section (only partially visible in the excerpt) operates directly on the unit sphere rather than on images or a learned face model. Figure captions indicate: finite-dimensional cap-volume bounds at (τ,ρ)=(0.80,8°); fixed-code asymptotic lower bounds R_LB; fixed-code and random-code asymptotic lower bounds for τ∈{0.55,0.7,0.85}; and finite-dimensional center-separation success under uniform induced centers for D∈{40,80}. The excerpt does not mention statistical hypothesis tests, cross-validation, or held-out attacker evaluation, and it does not report a benchmark against real face-verification baselines in the usual sense. Reproducibility is limited in the excerpt: the paper is an arXiv preprint, but no code release, frozen weights, or public dataset are described in the provided text. Overall, the paper’s methodology is a chain of definitions and geometric reductions: fixed threshold → admissibility constraints → spherical packing in deterministic settings → cap-radius separation in stochastic settings → random-code union bound under a prior.
Technical innovations
- Defines a verifier-centered capacity notion for synthetic identity generation that is tied directly to a fixed cosine threshold τ rather than to realism or latent diversity.
- Reduces deterministic distinguishable-identity capacity to a spherical-code problem over the realizable embedding set V_{g,ϕ}, with the classical spherical-code quantity recovered under full angular expressivity.
- Introduces a centered stochastic identity model with a clean sufficient separation rule arccos(τ)+2ρ between identity centers.
- Formulates a prior-constrained random-code capacity for identities drawn i.i.d. from a latent prior and bounds it via pairwise center-collision probabilities.
- Derives an exact spherical-code characterization under a stronger full-cap-support model (mentioned in the abstract and contributions, though the excerpted main text only fully details the centered and random-code lower bounds).
Datasets
- No public dataset used in the main theory — analytic results on S^{D-1} — n/a
- Synthetic sphere validation — not specified in excerpt — direct numerical illustration on S^
Baselines vs proposed
- Deterministic full angular expressivity baseline: CD(τ,0,0;g,ϕ) = A_D(arccos τ) vs proposed: CD(τ,0,0;g,ϕ) = A(V_{g,ϕ}, arccos τ) (Proposition 7)
- Spherical-code cap upper bound: A_D(ψ) ≤ 1/V_D(ψ/2) vs proposed lower-bound regime: A_D(ψ) ≥ 1/V_D(ψ) (Propositions 12 and 19)
- Deterministic asymptotic rate: liminf (1/D)log A_D(ψ) ≥ -log(sin ψ) vs random-code uniform-center rate: liminf (1/D)log C^{rnd}_{D,δ} ≥ -(1/2)log(sin ψ_τ(ρ)) (Theorems 20 and 25)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.10641.
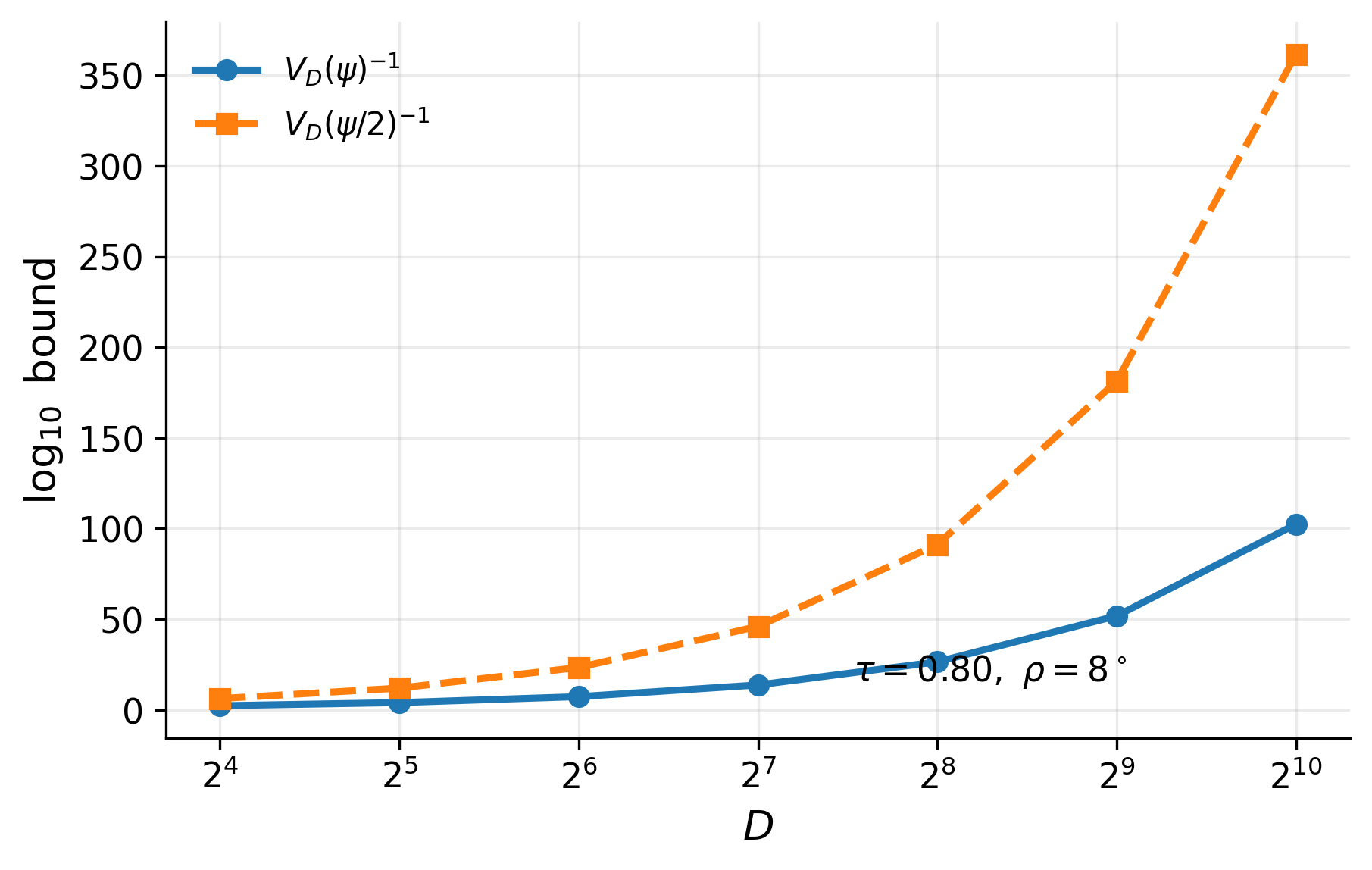
Fig 2: Finite-dimensional cap-volume bounds for (τ, ρ) = (0.80, 8◦).
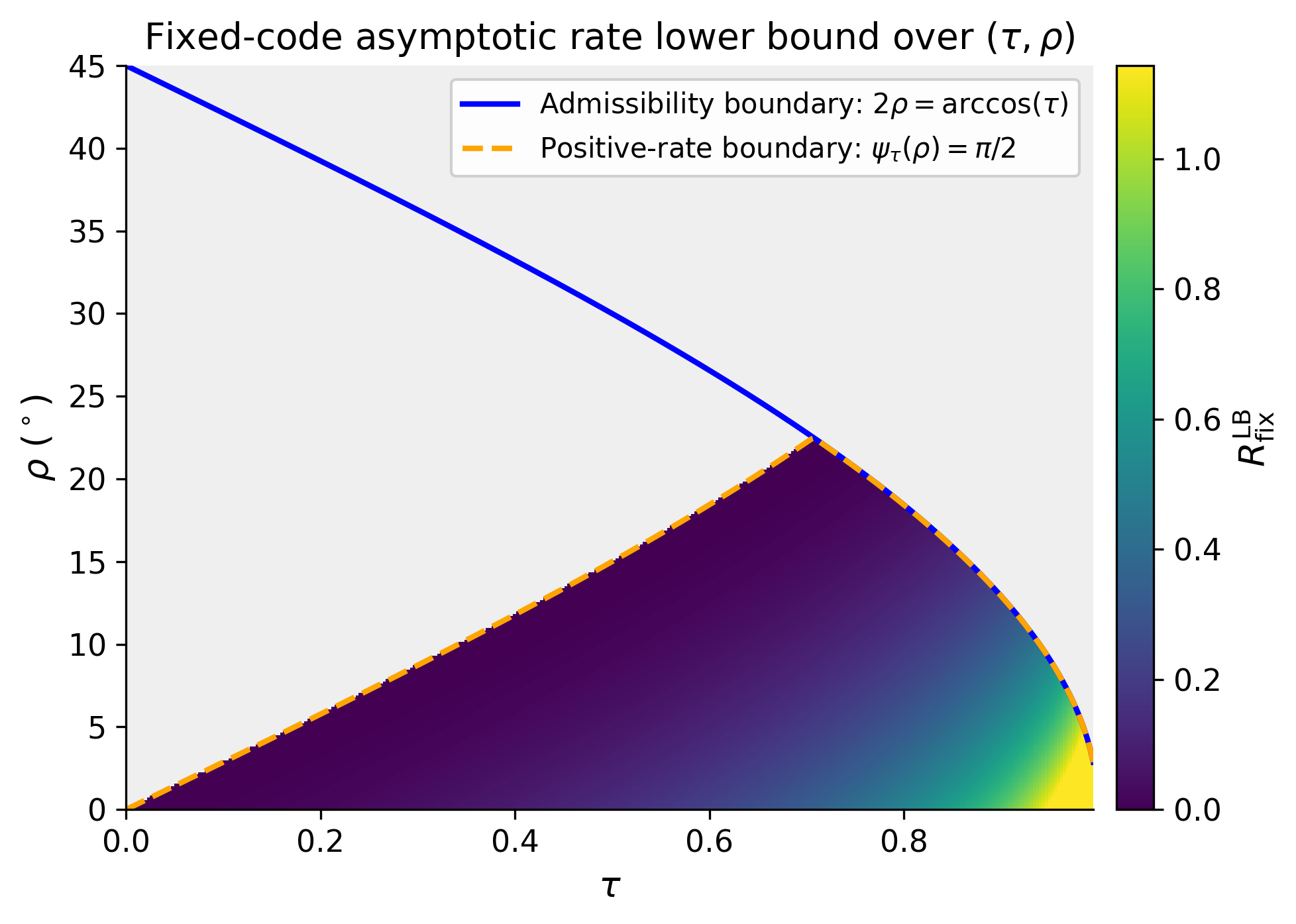
Fig 3: Fixed-code asymptotic lower bound RLB
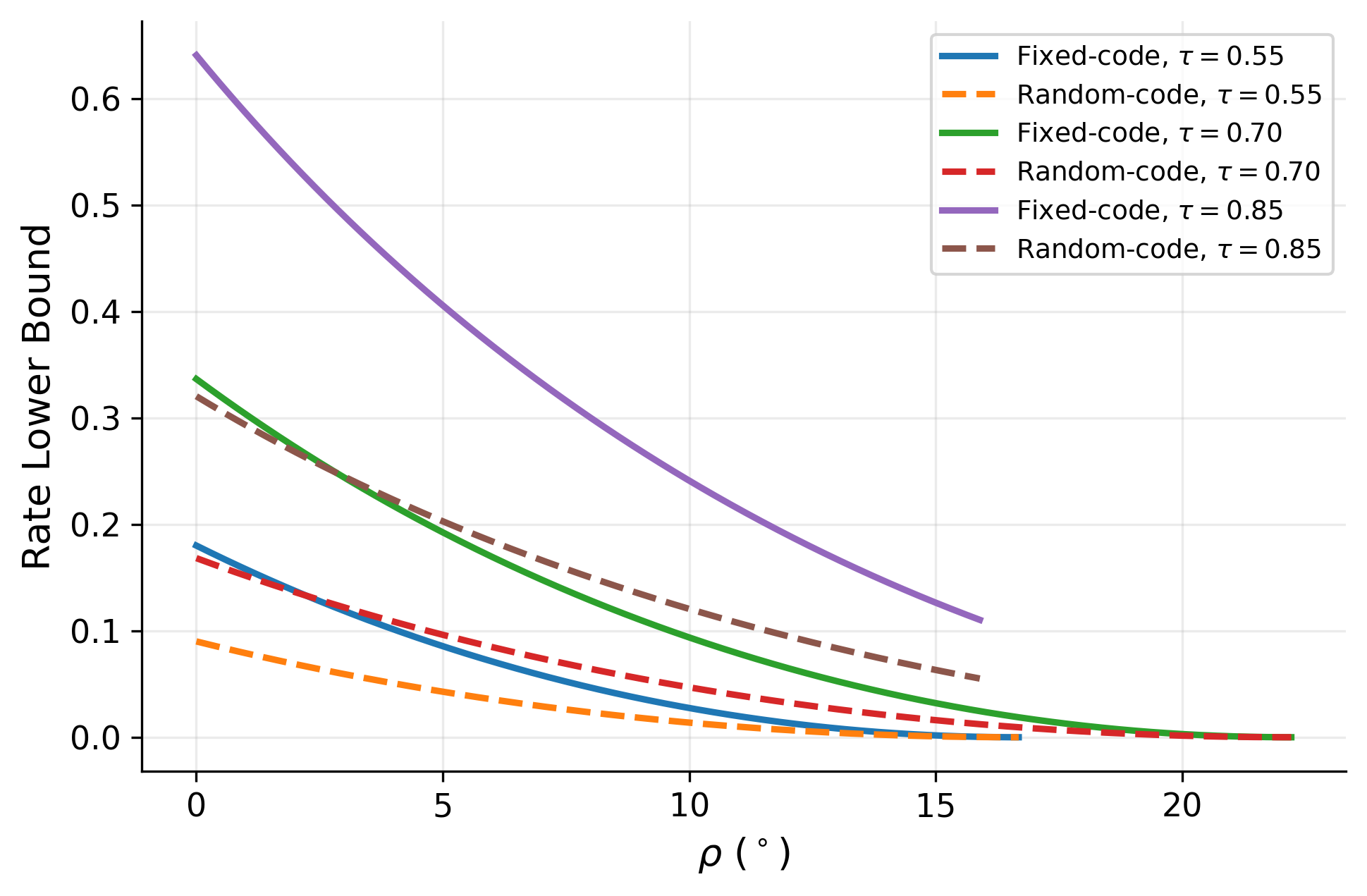
Fig 4: Fixed-code and random-code asymptotic lower bounds for τ ∈{0.55, 0.7, 0.85}. Under uniform
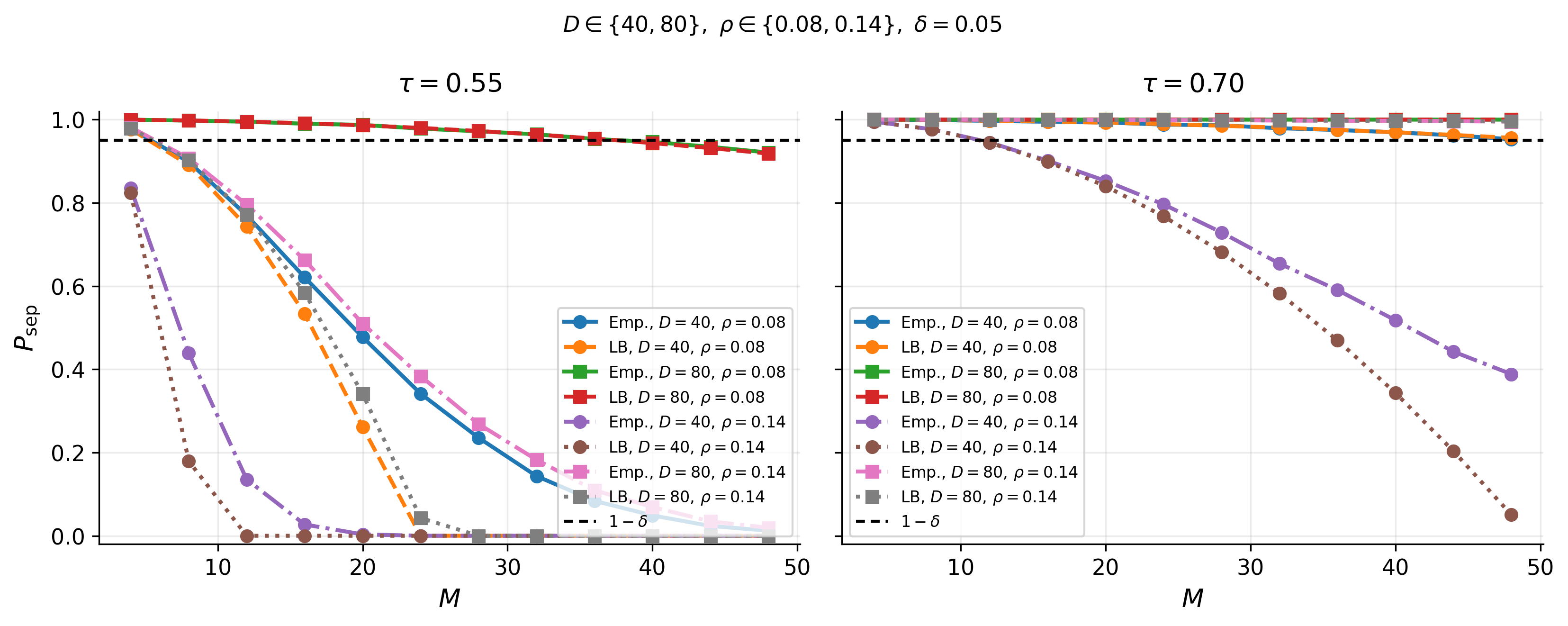
Fig 5: Finite-dimensional center-separation success under uniform induced centers for D ∈{40, 80},
Limitations
- The main results are theoretical; the excerpt does not report end-to-end experiments on a real face-recognition benchmark or a production generator/recognizer pair.
- The key expressivity assumptions (“full angular expressivity” and “full (ρ,η)-angular expressivity”) are idealized and may not hold for actual synthetic face generators.
- The centered-model admissibility condition is sufficient, not necessary; the paper explicitly notes that admissibility could hold even when the separation condition fails.
- The random-code lower bound is driven by a union bound over (M choose 2) pairs, which is generally loose and yields a factor-of-two loss in the asymptotic exponent under uniform centers.
- The excerpt does not provide code release details, frozen model checkpoints, or a full reproducibility package.
- The synthetic validation section is limited to geometric experiments on the sphere, so it cannot validate robustness to image-level artifacts, recognition-model bias, or distribution shift in real face data.
Open questions / follow-ons
- How tight are the spherical-code lower/upper bounds for realistic face embedding distributions where the realizable set V_{g,ϕ} is a strict subset of S^{D-1}?
- Can the sufficient centered-model condition be strengthened to a near-necessary characterization for common generator families, especially when identity distributions are anisotropic or multimodal?
- What happens under non-uniform or clustered latent priors Q on S^{D-1}, where pairwise collision probabilities are highly inhomogeneous rather than spherical-symmetric?
- Can the theory be extended to multi-threshold or score-calibrated verification settings that model operating curves instead of a single τ?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the paper is useful as a geometry-first reminder that “diversity” is not the same as distinguishability under the verifier actually used at deployment. If you are trying to detect synthetic identities, the relevant object is not just visual realism or average embedding spread; it is the packing capacity of the generator’s induced embeddings under the face model and threshold you care about. In other words, an attacker with a strong generator may still be limited by spherical packing if their identity centers cluster too tightly in embedding space, but if a generator has enough angular expressivity, the number of distinct identities can grow exponentially with embedding dimension. The random-code analysis is especially relevant if an attacker samples identities from a prior rather than hand-designing them: then the collision probability of class centers becomes the key quantity, and a defender may want to estimate or regularize that collision structure rather than only monitoring pairwise similarity averages.
Cite
@article{arxiv2604_10641,
title={ On the Capacity of Distinguishable Synthetic Identity Generation under Face Verification },
author={ Behrooz Razeghi },
journal={arXiv preprint arXiv:2604.10641},
year={ 2026 },
url={https://arxiv.org/abs/2604.10641}
}