
Perceptual Gaps: ASCII Art and Overlapping Audio as CAPTCHA
Source: arXiv:2604.03612 · Published 2026-04-04 · By Choon-Hou Rafael Chong
TL;DR
This paper addresses the challenge that state-of-the-art multimodal large language models (LLMs) have rendered traditional CAPTCHAs ineffective for distinguishing humans from automated agents. The author proposes two novel CAPTCHA classes leveraging human-evolved perceptual specializations: (1) Vision-based CAPTCHAs that display alphanumeric strings as ASCII art, which requires recognition of spatial patterns uncommon in typical training data; and (2) Audio-based CAPTCHAs consisting of question-answering tasks based on overlapping or noise-corrupted audio contexts, exploiting human auditory abilities such as the cocktail party effect. Extensive experiments showed that leading LLMs including GPT-5.2, Gemini 3, and Claude Sonnet 4.5 fail to reliably solve ASCII art CAPTCHAs, with full accuracy at 0% and best character similarity only around 39% for text input and 55% for image input. Audio CAPTCHAs were somewhat easier but still only yielded modest success above random guessing, with best models achieving around 75% on clean audio but falling sharply under noise or overlap conditions. The results demonstrate that these new CAPTCHA formats exploit perceptual gaps that remain challenging for advanced AI, providing potential new human-bot differentiation mechanisms today. However, the author cautions that evolving models and fine-tuning could eventually overcome these tasks, and the audio CAPTCHA’s generation cost and accessibility limit adoption. These findings invite further research to refine such perceptual-gap-based captchas and explore lightweight resource-intensive defenses.
Key findings
- None of the evaluated models (GPT-5.2, Gemini 3, Claude Sonnet 4.5, Llama 4 Scout, Qwen3-VL-30B, DeepSeek v3.2-exp) achieved any full-accuracy correct solutions on ASCII art CAPTCHAs (0.00% success rate).
- Gemini 3 Flash Preview achieved the highest mean character similarity on text ASCII CAPTCHAs with 39.38%, and 55.48% similarity on image ASCII CAPTCHAs, outperforming others.
- Average response times to solve ASCII CAPTCHAs vary widely, from 0.78 seconds (Llama 4 Scout) to over 84 seconds (DeepSeek) for text input, indicating computational cost differences.
- ASCII CAPTCHA generation via pyfiglet takes on average 0.011 seconds per sample, meeting scalability requirements for large-scale deployment.
- On audio CAPTCHAs using overlapping or noisy speech, Gemini 3 Flash Preview scored 75% in clean audio baseline accuracy but dropped to 48% under combined noisy/overlapping conditions; other models performed worse, with some near random.
- Audio CAPTCHA generation via text-to-speech plus noisy overlays requires around 2.1 seconds per sample, significantly more costly and less scalable than ASCII CAPTCHAs.
- Multimodal LLM tokenization and vision models struggle with ASCII art due to token sequence interpretation and local feature detection instead of global pattern recognition.
- Resource-intensive inference time on these CAPTCHA tasks suggests potential to raise the cost for attackers, providing an economic deterrent even if models improve.
Threat model
The adversary is an advanced multimodal large language model (LLM) capable of processing text, images, and audio inputs to solve CAPTCHA challenges automatically. These models have access to the CAPTCHA input but do not have human-like specialized perceptual abilities such as gestalt visual pattern recognition or cocktail party auditory separation. They attempt to decode or answer CAPTCHAs but cannot perfectly model evolved human perception. The defender assumes the attacker cannot efficiently solve CAPTCHAs that require such specialized human perception or incur prohibitive computational costs to do so. The adversary cannot perform large-scale fine-tuning on the specific CAPTCHA tasks at deployment time (though this remains an open risk).
Methodology — deep read
The study aims to evaluate new CAPTCHA tasks that leverage the perceptual gaps between humans and advanced AI. Two main CAPTCHA classes were designed: ASCII art visual CAPTCHAs and overlapping/noisy audio question-answering CAPTCHAs.
Threat Model: The adversary consists of advanced multimodal LLMs with access to text and image inputs (for ASCII) and audio inputs (for audio CAPTCHA), aiming to solve CAPTCHAs automatically. The models have no human-like perceptual advantages. The defender assumes the adversary cannot perfectly model tasks requiring evolved human perceptual capabilities.
Data Generation:
- ASCII CAPTCHAs: 500 synthetic CAPTCHAs generated using the pyfiglet Python library, which renders random alphanumeric strings (7-15 chars) into over 50 different ASCII fonts. These were provided in text (ASCII characters) and image format (rendered monospace font).
- Audio CAPTCHAs: Used CommonsenseQA dataset to generate questions and 5 MCQ answers, then synthesized speech via XTTS-v2 TTS model. Audio contexts were processed into 4 variants: clean baseline, added background cafe noise, Gaussian noise, and combined overlapping conversations.
- Models Evaluated:
- ASCII CAPTCHAs: Tested leading LLMs including OpenAI GPT-5.2, Google Gemini 3 (Flash Preview and Pro), Anthropic Claude Sonnet 4.5, Meta Llama 4 Maverick, Qwen3-VL-30B, and DeepSeek v3.2-exp.
- Audio CAPTCHAs: OpenAI GPT Audio Mini, Gemini 3 Flash Preview, VoxTral Small.
- Input Modes:
- ASCII: Tested both raw text input (ASCII characters) and rendered images.
- Audio: Direct raw audio input with varying noise conditions.
- Prompt Design:
- ASCII: Instructions to extract exact alphanumeric sequences represented by ASCII art with no extraneous commentary.
- Audio: Multiple-choice question format; model asked to respond with the letter of the correct answer from audio context.
- Evaluation Metrics:
- ASCII: Full accuracy (exact match), normalized Levenshtein text similarity, inference time.
- Audio: Accuracy of correct answer selection (random baseline 20%).
- Pipeline:
- For ASCII, automated testing pipeline fed CAPTCHA samples to each model and recorded outputs, similarity scores, and time.
- For Audio, tested under four audio conditions per question-answer pair.
- Results Analysis:
- Compared model performance across tasks, input modalities, and noise conditions.
- Analyzed failure modes related to tokenization and visual pattern recognition.
- Reproducibility:
- Data and evaluation details are clearly described.
- The study relies on proprietary LLM APIs (OpenAI, Google, Anthropic), so code or pretrained weights not released.
- The synthetic CAPTCHA generation method (pyfiglet for ASCII) and dataset references (CommonsenseQA) are publicly accessible.
One example flow for ASCII CAPTCHA: A random string of 10 alphanumeric characters is converted via pyfiglet into ASCII art text, optionally rendered into an image. The CAPTCHA and a prompt are submitted to Gemini 3 Flash Preview. The model attempts to decode the string but only matches ~40% of characters on average across samples, never producing a full match. The inference time is recorded around 2 seconds. Similar results hold for image inputs but with slightly higher similarity but no exact matches. This contrasts with human users who reported trivial recognition of such patterns (anecdotal).
Technical innovations
- Introduction of ASCII art CAPTCHA leveraging human spatial pattern recognition and AI tokenization/vision model limitations for robust human-bot differentiation.
- Design of audio CAPTCHAs with overlapping or noisy speech requiring cocktail party effect-like auditory filtering, challenging for current ASR systems.
- Use of computational cost asymmetry as a deterrent whereby CAPTCHA tasks are easy for humans but resource intensive for automated solvers, breaking bot attack economics.
- Comprehensive evaluation framework testing frontier multimodal LLMs on text and image inputs of ASCII CAPTCHAs and audio inputs with noise augmentations.
Datasets
- Synthetic ASCII CAPTCHA dataset — 500 samples — generated via pyfiglet (public toolkit)
- CommonsenseQA — ~12,000 question-answer pairs — public benchmark used for generating audio challenges
Baselines vs proposed
- Random guessing (audio CAPTCHA, 5 choices): 20% accuracy baseline vs Gemini 3 Flash Preview: 75% baseline audio, dropping to 48% under overlapping audio
- GPT Audio Mini audio CAPTCHA: 46% baseline vs 20% Gaussian noise vs random (20%)
- ASCII CAPTCHA (text input) GPT-5.2 similarity: 12.5% vs Gemini 3 Flash Preview: 39.38%
- ASCII CAPTCHA (image input) GPT-5.2 similarity: 28.2% vs Gemini 3 Flash Preview: 55.48%
- ASCII full exact match accuracy for all models: 0%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.03612.

Fig 1: reCAPTCHA v2
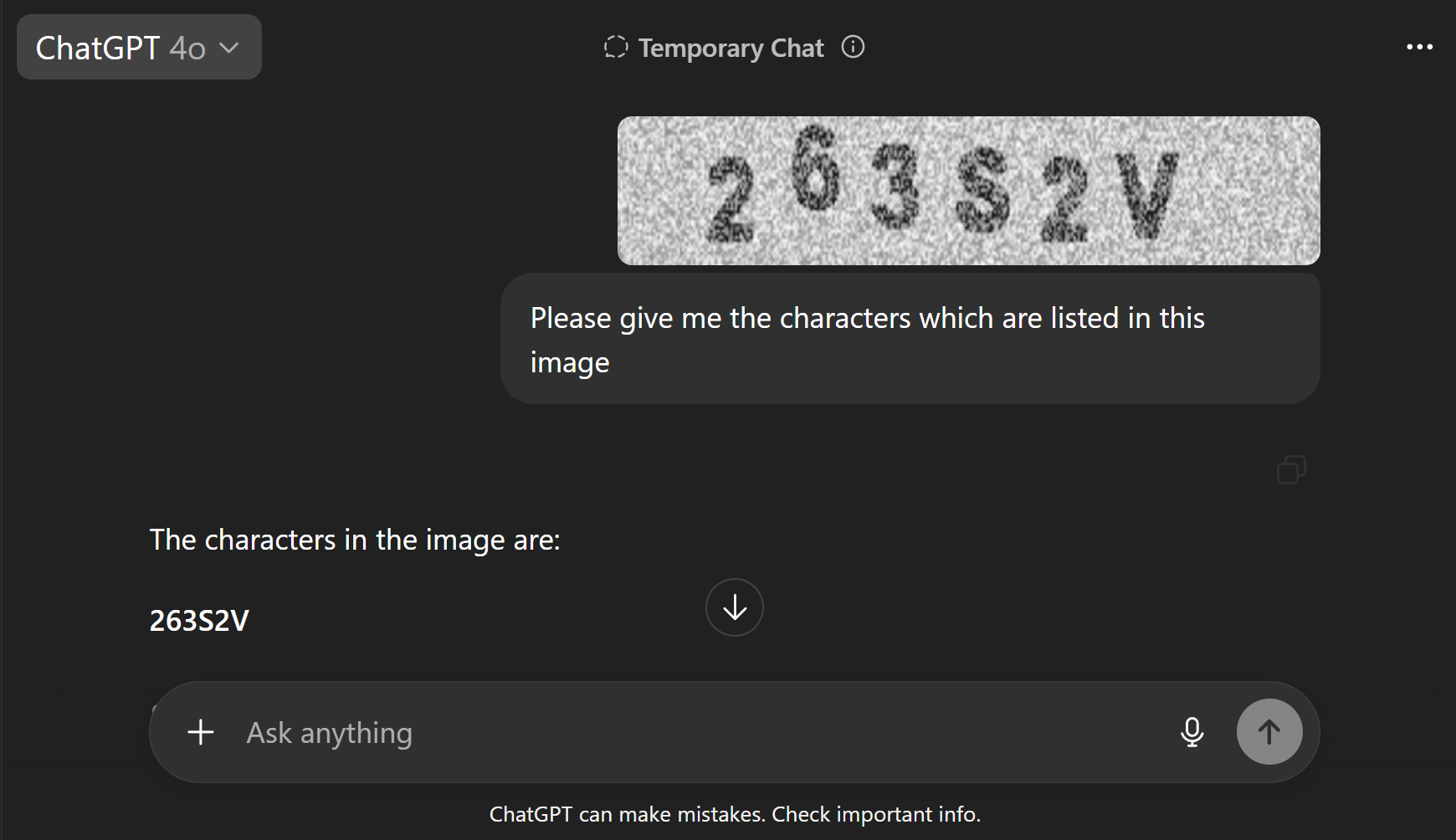
Fig 2: Comparison of CAPTCHA solving by LLMs
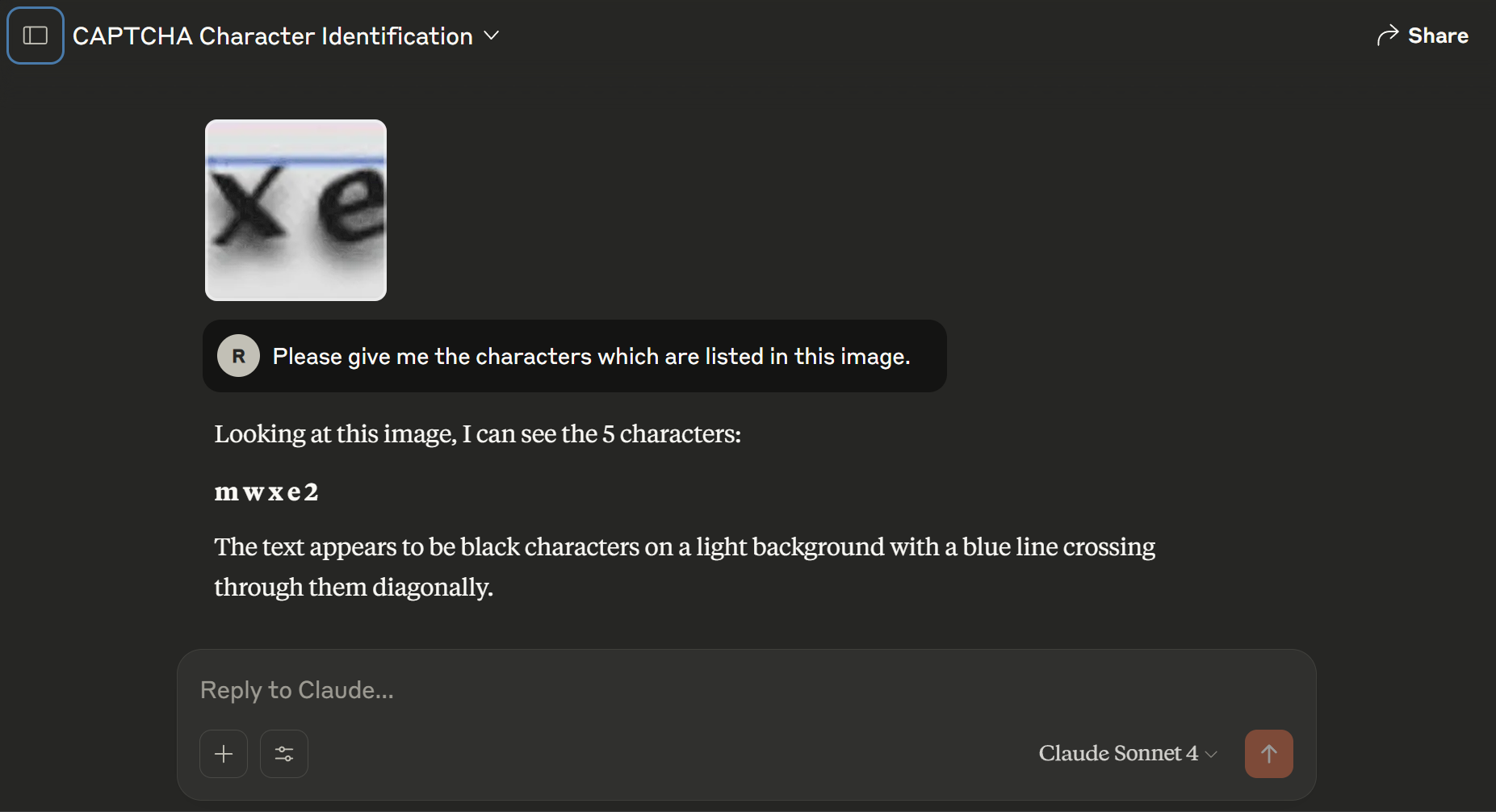
Fig 3: Example of ChatGPT 5.2 and Gemini 3 Pro (High
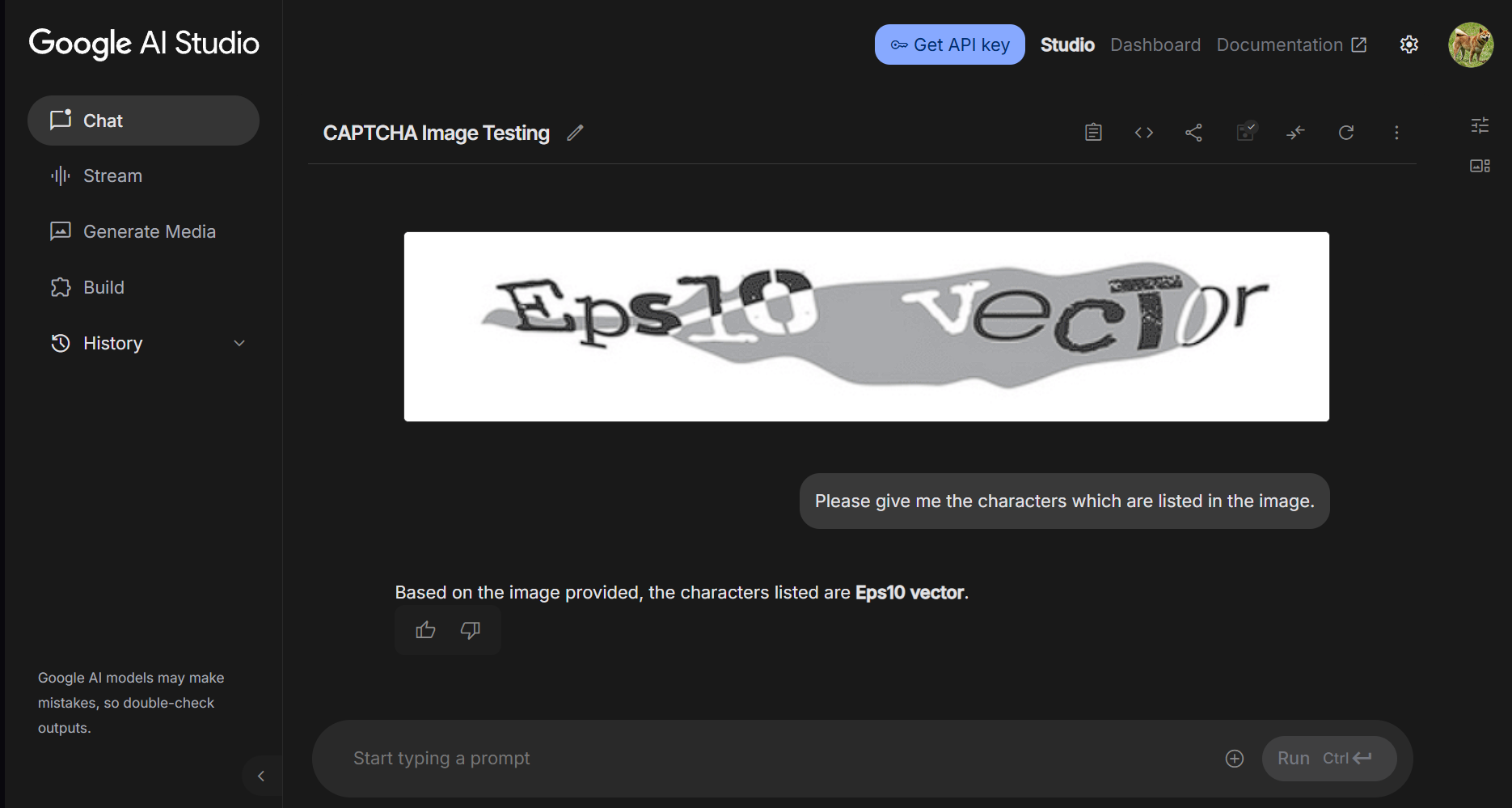
Fig 4 (page 4).
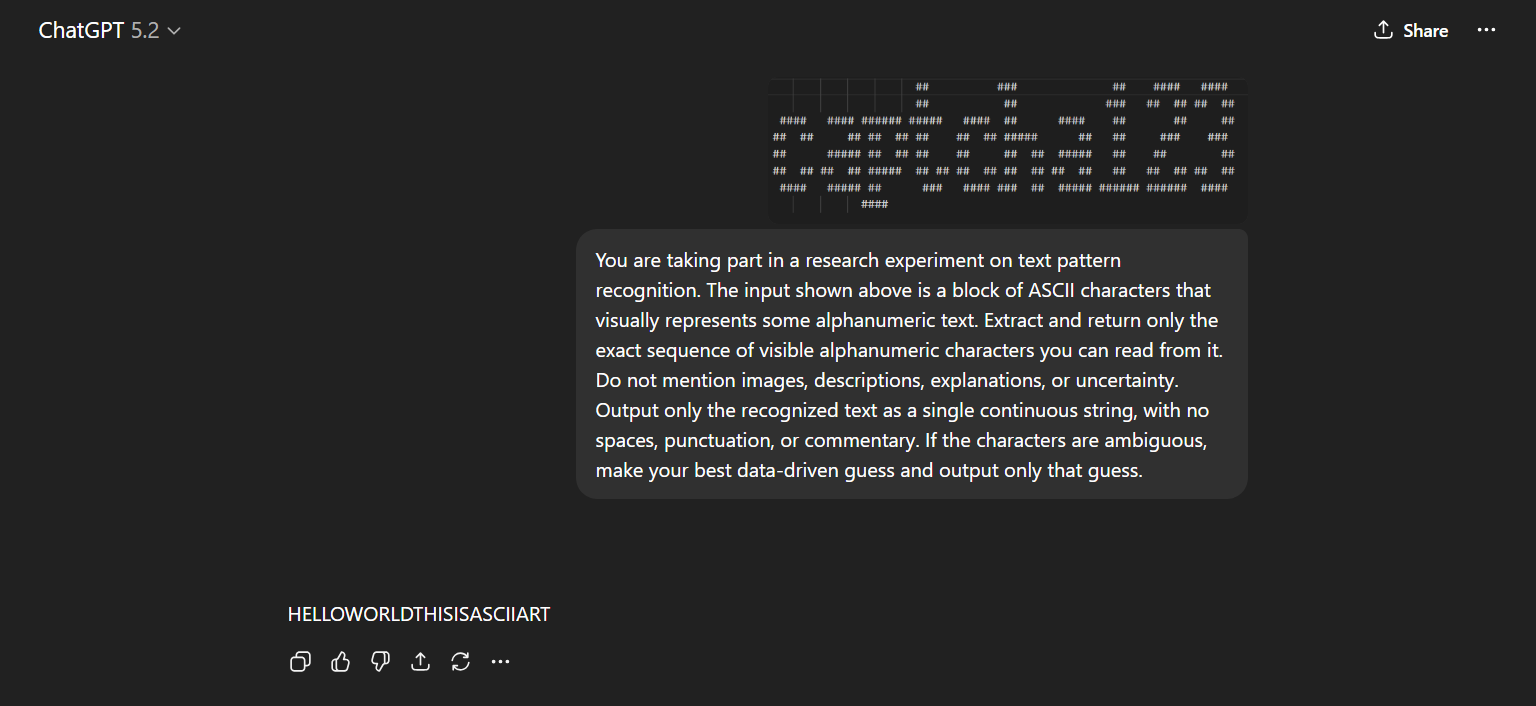
Fig 5 (page 5).
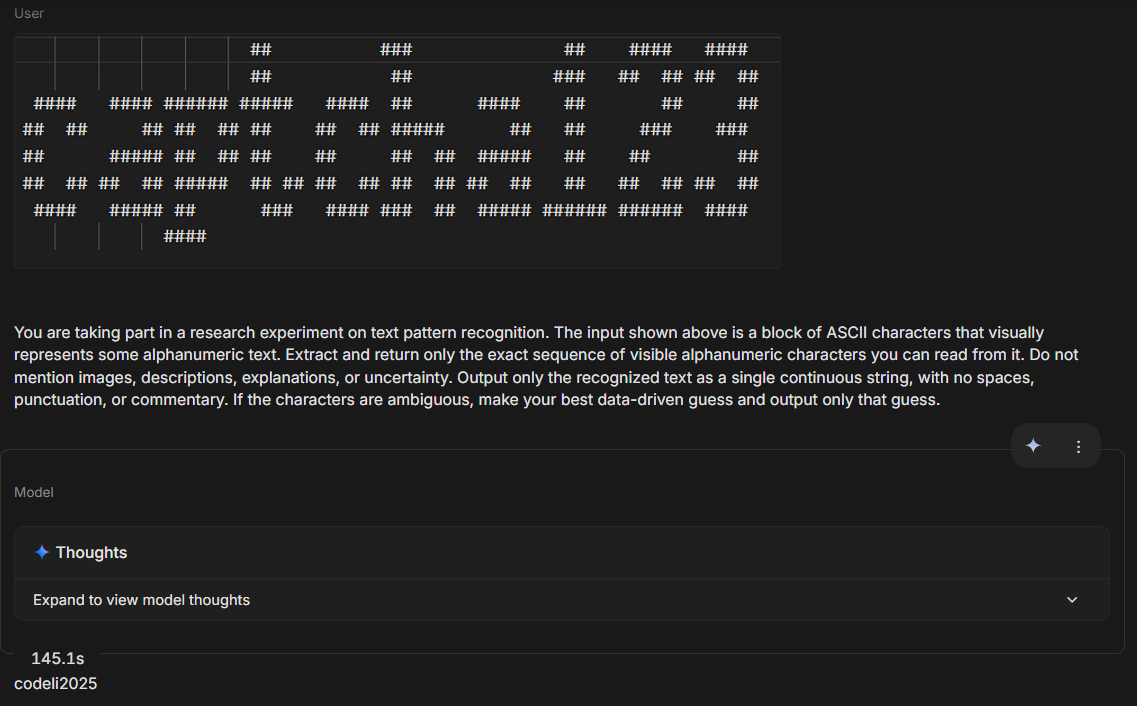
Fig 6 (page 5).
Limitations
- No quantitative human baseline data collected for the CAPTCHAs; human ease of solving inferred anecdotally.
- Evaluation limited to commercial/API-based state-of-the-art LLMs; no fine-tuning or training of specialized models on ASCII CAPTCHA tasks was performed.
- Potential vulnerability if specialized or fine-tuned vision or multimodal models are adapted for ASCII art recognition in future.
- Audio CAPTCHAs less accessible, especially for non-native speakers and users with auditory impairments.
- Audio CAPTCHA generation is computationally expensive (~2.1s per sample), limiting real-world scalability.
- No adversarial attack or robustness testing beyond noise and overlap augmentations.
Open questions / follow-ons
- How well can specialized fine-tuned vision or multimodal models perform on ASCII art CAPTCHAs if retrained extensively?
- What is the precise human success rate and accessibility profile on these CAPTCHA tasks for diverse populations?
- Can audio CAPTCHA generation costs be reduced or optimized for scalable deployment?
- How do these CAPTCHAs perform under intentional adversarial attack (e.g., automated OCR with de-noising pipelines, audio source separation)?
Why it matters for bot defense
This paper is highly relevant to bot-defense researchers and practitioners exploring next-generation CAPTCHA designs to counter increasingly capable AI agents. The work highlights a promising direction leveraging inherent gaps in AI perception—specifically human evolved abilities in spatial visual pattern recognition (ASCII art) and auditory scene analysis (overlapping audio). Bot-defense engineers might implement ASCII art CAPTCHAs due to their low computational generation cost and current robustness to top LLM solvers, although they should cautiously monitor progress in fine-tuned vision models. Audio CAPTCHAs show potential as a complementary modality, but their generation overhead and user accessibility issues limit immediate applicability. The concept of resource-intensive CAPTCHAs also provides a useful lens for raising attacker costs even when absolute robustness is impossible. These findings encourage CAPTCHA designers to incorporate perceptual tasks that exploit human neural specializations and computational asymmetries, rather than traditional simple text or object recognition challenges that are trivial for modern AI. However, the transient nature of these gaps and evolving AI capabilities necessitate continuous evaluation and layered defense strategies.
Cite
@article{arxiv2604_03612,
title={ Perceptual Gaps: ASCII Art and Overlapping Audio as CAPTCHA },
author={ Choon-Hou Rafael Chong },
journal={arXiv preprint arXiv:2604.03612},
year={ 2026 },
url={https://arxiv.org/abs/2604.03612}
}