
SFDemorpher: Generalizable Face Demorphing for Operational Morphing Attack Detection
Source: arXiv:2603.28322 · Published 2026-03-30 · By Raul Ismayilov, Luuk Spreeuwers
TL;DR
SFDemorpher tackles a practical gap in face demorphing research: most prior methods are trained and evaluated as if every document image is a morph, which is not how border control or document enrollment actually looks in deployment. The paper’s core idea is to combine StyleGAN-based inversion/editing in both latent space and a higher-dimensional feature space, then train the system in two passes so it learns both bona fide reconstruction and morph disentanglement. That matters because a usable D-MAD demorpher must preserve bona fide identity well enough not to inflate false alarms, while still separating identities in morphed documents.
What is new here is not just a bigger generator, but a deployment-oriented training regime: a hybrid corpus with predominantly synthetic identities, paired with bona fide/morphed dual-pass supervision, and evaluation across unseen identities, capture conditions, and 13 morphing techniques. The authors report state-of-the-art generalizability and better separation between bona fide and morph score distributions, with visually plausible reconstructions that can be inspected by humans. The paper’s claim is strongest on operational robustness, not on raw reconstruction novelty alone.
Key findings
- The training set is intentionally synthetic-majority: 80% FLUXSynID synthetic identities and 20% real DemorphDB identities, which the authors frame as the first face-demorphing setup to rely predominantly on synthetic training data.
- DemorphDB contributes 1,653 real identities and two used morphing methods, UTW-NS and UTW-StyleGAN, with 36,983 morphs each; the third method (UTW) was excluded because explicit component swapping makes reconstruction ill-posed.
- FLUXSynID contributes 14,889 synthetic identities; after generating and filtering morphs, the paper reports 75,810 UTW-NS morphs and 78,569 UTW-StyleGAN morphs for training.
- Evaluation spans three held-out datasets separated from training identities and capture conditions: FRLL-Morphs-UTW (102 identities), HNU-FM (63 identities), and FEI Morph V2 (200 identities).
- The authors evaluate across 13 morphing algorithms total, with only one seen in training (UTW-StyleGAN), and explicitly include both accomplice-restoration and criminal-restoration scenarios on FEI Morph V2.
- SFDemorpher introduces new separability metric BMS as a 1-Wasserstein distance between bona fide and morph score distributions, arguing threshold metrics alone miss margin quality.
- The system uses a frozen StyleGAN generator and a frozen Style-Feature encoder, training only the demorphing modules plus discriminator; the paper sets the inverse-identity margin to m = -0.5 for the morphed pass.
- The paper states that criminal identity restoration is not used for training because splicing-based morphs lack the criminal’s outer facial data, making that target ill-posed and training unstable.
Threat model
The adversary is a morphing attacker who can create a document image by blending two identities and then use that image either during enrollment to get a fraudulent document or at border control to impersonate one of the contributors. The system assumes access to a trusted reference image for the live subject being compared against, and assumes the attacker cannot alter the trusted reference or the face recognition backend directly. The paper does not model an adaptive adversary that specifically learns to evade SFDemorpher or the downstream FRS.
Methodology — deep read
The threat model is operational morphing attack detection in document issuance and automated border control. An attacker can submit a morphed document image that blends two people, or later present a issued morph at a gate; the system is assumed to have a trusted reference image for the live subject being compared against. The adversary knows that face demorphing and FRS-based comparison are used, but the paper does not model adaptive attackers who optimize specifically against SFDemorpher or a fixed downstream recognizer. The system is also assumed to have access to a trusted reference capture for the same person as the live probe/document reference pair, which is the standard D-MAD assumption.
Data-wise, the training corpus is a hybrid of DemorphDB and FLUXSynID. DemorphDB is the real-data component with 1,653 identities and two included morphing methods: UTW-NS (landmark-based) and UTW-StyleGAN (deep-learning-based), each contributing 36,983 morphs. The authors exclude UTW because it explicitly swaps facial components and destroys information needed for stable reconstruction. FLUXSynID supplies 14,889 synthetic identities with paired document and live captures; for each identity they generate six morphs, split into random-pair and look-alike-pair protocols, and then do this under both UTW-NS and UTW-StyleGAN to get 12 morphs per identity before filtering low-quality morphs. After filtering, they report 75,810 UTW-NS and 78,569 UTW-StyleGAN morphs from the synthetic pool. Preprocessing includes background removal with BiRefNet, alignment using the FFHQ protocol, and resizing to 256×256.
Architecturally, SFDemorpher is built around a frozen Style-Feature Encoder E and a frozen StyleGAN generator G. The encoder maps both document and reference images into two representations: the extended StyleGAN latent W+ and the feature map space Fk, here specifically the 9th convolutional-layer features with shapes w ∈ R18×512 and F ∈ R512×64×64. The key novelty is that SFDemorpher does not rely only on W+ inversion; it uses a joint style-feature design. One branch concatenates the document/reference feature maps and sends them through a Feature Demorphing Module MFDM to produce FFDM. A second branch concatenates the raw images and feeds them into an Image Demorphing Module MIDM, which outputs both a demorphed latent code wout and feature map FIDM. A Feature Fusion Module MFFM then merges FFDM and FIDM into the final feature tensor Fout, which is injected into the frozen generator at layer 9. In plain terms: one branch tries to disentangle identity using spatially rich features, the other uses pixel-level context, and the fusion module learns which information to trust for the final reconstruction.
Training is explicitly dual-pass. In the bona fide pass, the input pair is (IB, IB′) and the target is the original bona fide document IB; in the morphed pass, the input pair is (IAC, IC′) and the target is the accomplice IA, i.e. the missing contributor to the morph. The authors alternate these passes to keep the model from becoming biased toward assuming every input is a morph. They exclude criminal-restoration samples from training because splicing-based morphs often remove the criminal’s outer-face information, making that task too ill-posed for stable optimization, but they still evaluate it later. Optimization combines image reconstruction losses (L2, MS-SSIM, LPIPS, and AdaFace identity loss), a morphed-only inverse-identity margin loss with margin m = -0.5, a feature-space L2 regularizer on Fout versus the encoded ground-truth features, and a non-saturating adversarial loss with an R1-regularized discriminator. Loss weights are different for bona fide versus morphed passes; for example λid, λL2, λlpips, λms-ssim, and λfeat are all an order of magnitude larger in the morphed pass than the bona fide pass, while λadv remains 0.01 in both cases.
Evaluation is set up to test both reconstruction quality and operational D-MAD utility. Reconstruction is assessed using DTI and DNTI: DTI measures how much the target identity remains in the output relative to a threshold τ, while DNTI measures residual similarity to the non-target identity. For D-MAD, they use MACER, BSCER, and EER based on cosine similarity between AdaFace embeddings of the reconstruction and the trusted reference. They also introduce BMS, the Wasserstein-1 distance between bona fide and morphed score distributions, to quantify class margin rather than just threshold errors. The downstream D-MAD decision rule is simple: if similarity between reconstruction and reference is above τ, classify bona fide; otherwise classify morphed. A concrete end-to-end example is the accomplice-restoration case: given a suspected morph and the criminal’s live reference at border control, SFDemorpher reconstructs the missing accomplice face; AdaFace then compares the reconstruction to the criminal reference, and a low similarity score indicates the input was a morph. The paper’s reproducibility story is only partial from the excerpt: it mentions a frozen generator, explicit preprocessing, and appendix-reported implementation details, but no code-release or frozen-weight package is stated in the provided text.
Technical innovations
- Joint latent-and-feature demorphing: the method combines StyleGAN W+ inversion with high-dimensional feature-space editing (Fk) rather than relying on lossy W+ alone, building on and extending StyleFeatureEditor-style inversion/editing.
- Dual-pass training for operational realism: the model is trained on both bona fide and morphed document-reference pairs, instead of the common morph-only assumption used by prior demorphers.
- Synthetic-majority hybrid training corpus: the paper uses mostly synthetic identities from FLUXSynID to scale identity diversity while retaining a smaller real-data component from DemorphDB.
- Inverse-identity margin loss: for morphed samples, the model explicitly penalizes similarity between the reconstruction and the non-target reference beyond a margin m = -0.5.
- BMS metric: the authors add a 1-Wasserstein score-separation measure to assess how far bona fide and morph similarity distributions are separated, not just how often a threshold is crossed.
Datasets
- DemorphDB — 1,653 real identities; 36,983 UTW-NS morphs and 36,983 UTW-StyleGAN morphs used — public dataset from prior work [17]
- FLUXSynID — 14,889 synthetic identities with paired document/live captures — synthetic dataset [21]
- FRLL-Morphs-UTW — 102 identities — derived from Face Research Lab London dataset [43]
- HNU-FM — 63 identities — public dataset [62]
- FEI Morph V2 — 200 identities; 2,000 morphs per included method — public dataset [22, 63]
Baselines vs proposed
- StyleDemorpher [17]: the paper claims SOTA generalizability over unseen identities, capture conditions, and morphing methods, but the exact numeric deltas are not present in the provided excerpt.
- diffDeMorph [16]: compared as a recent generalizable demorphing baseline; exact metric values are not present in the provided excerpt.
- Prior morph-only demorphing approaches [11,13–16]: reported to degrade bona fide preservation; exact EER/MACER/BSCER values are not present in the provided excerpt.
- Artifact-based D-MAD methods [22,23,32,55]: discussed as less robust to unseen morphing techniques; the excerpt does not include direct numeric comparisons.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.28322.
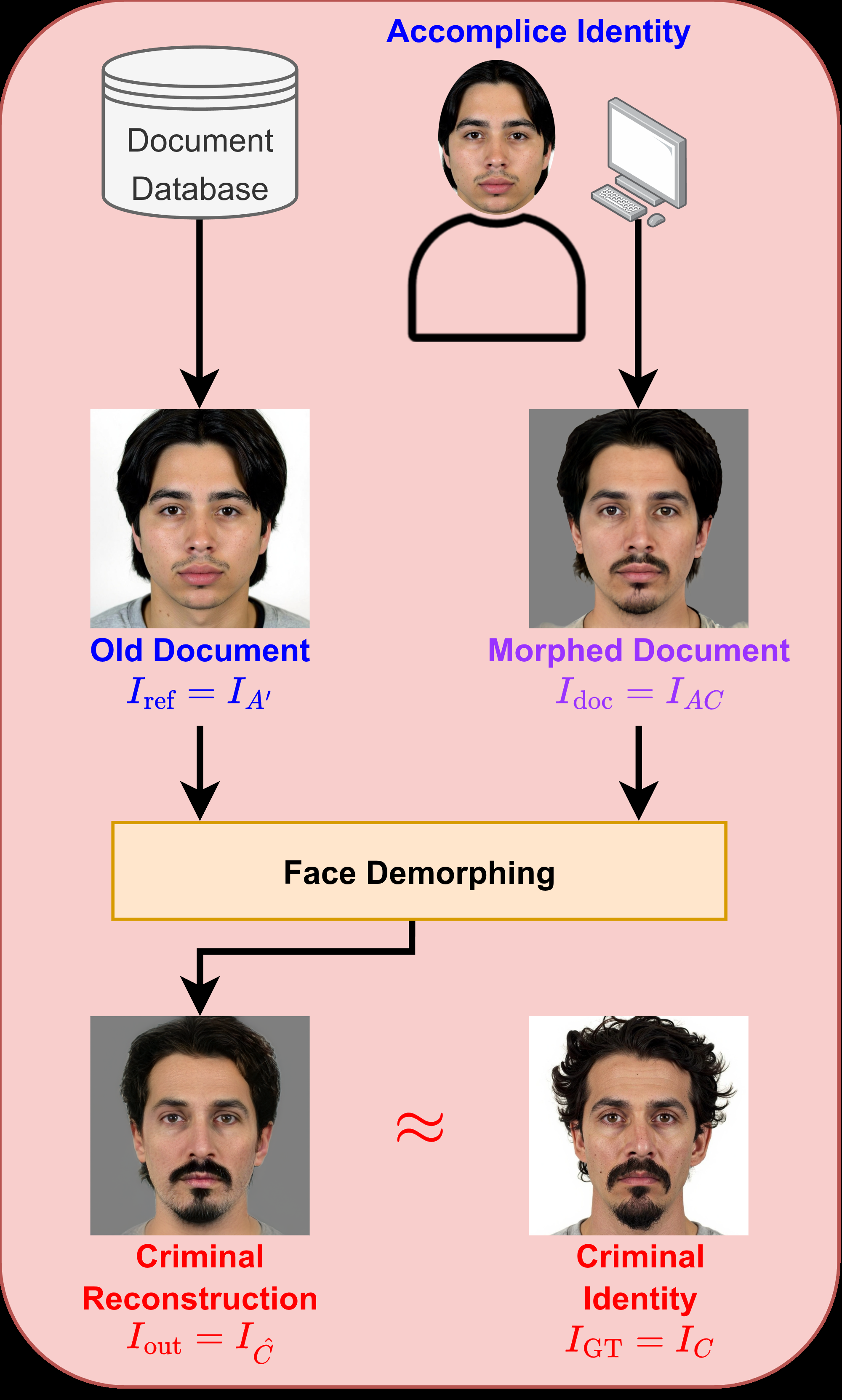
Fig 1: Visualization of the three primary operational face demorphing scenarios. In each case, face
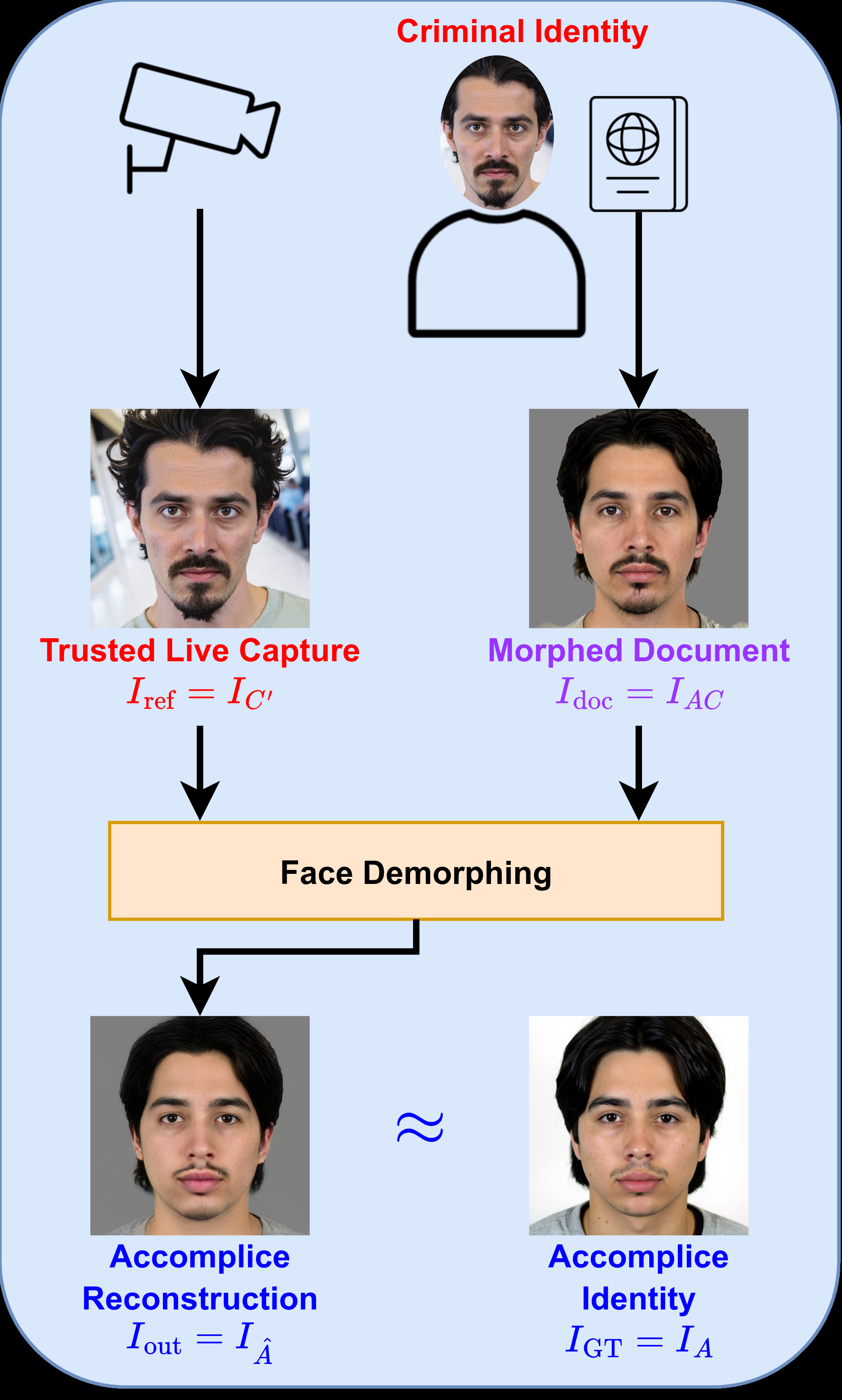
Fig 2: The training pipeline of the SFDemorpher framework utilizing a dual-pass strategy. The bona
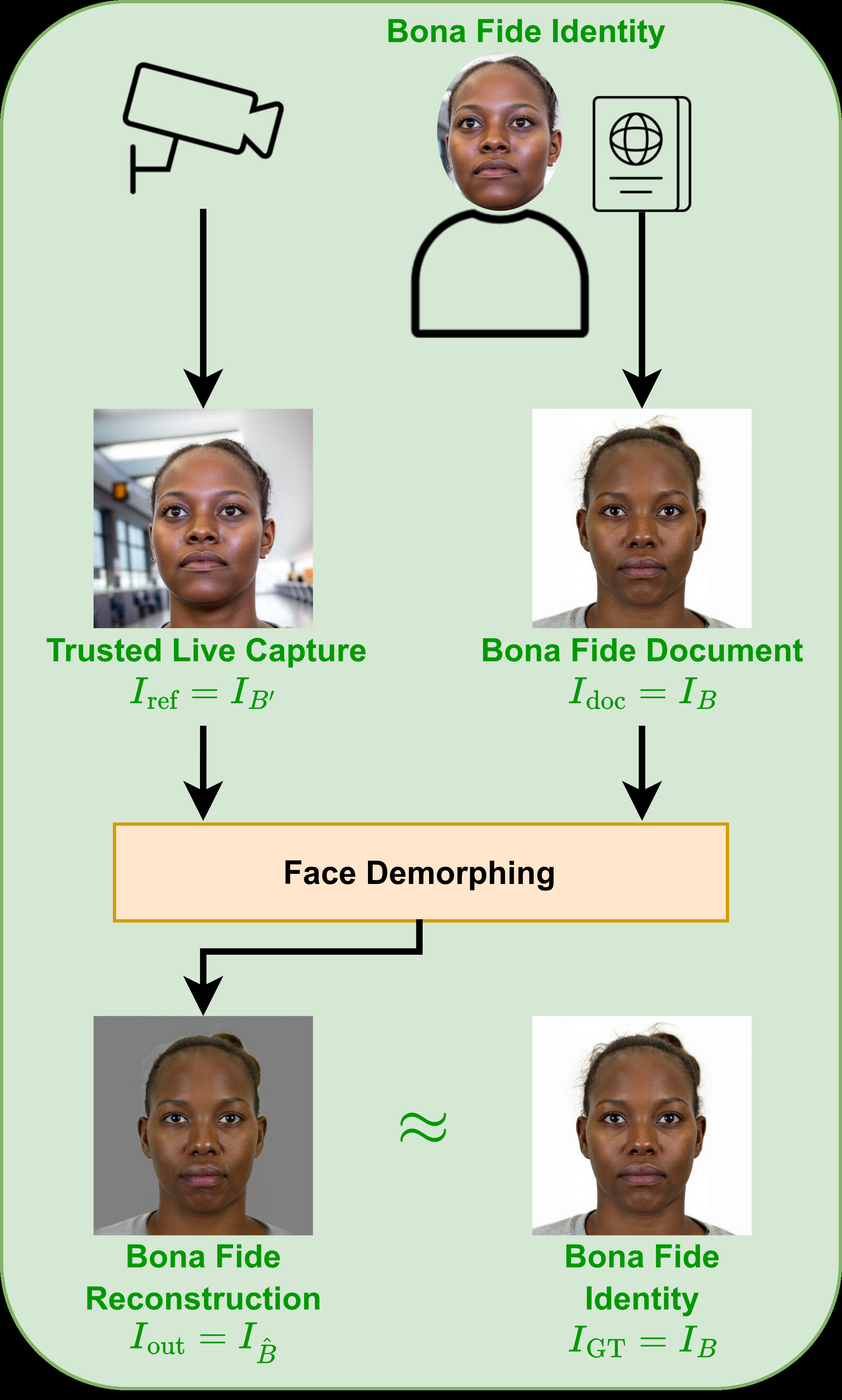
Fig 3 (page 5).
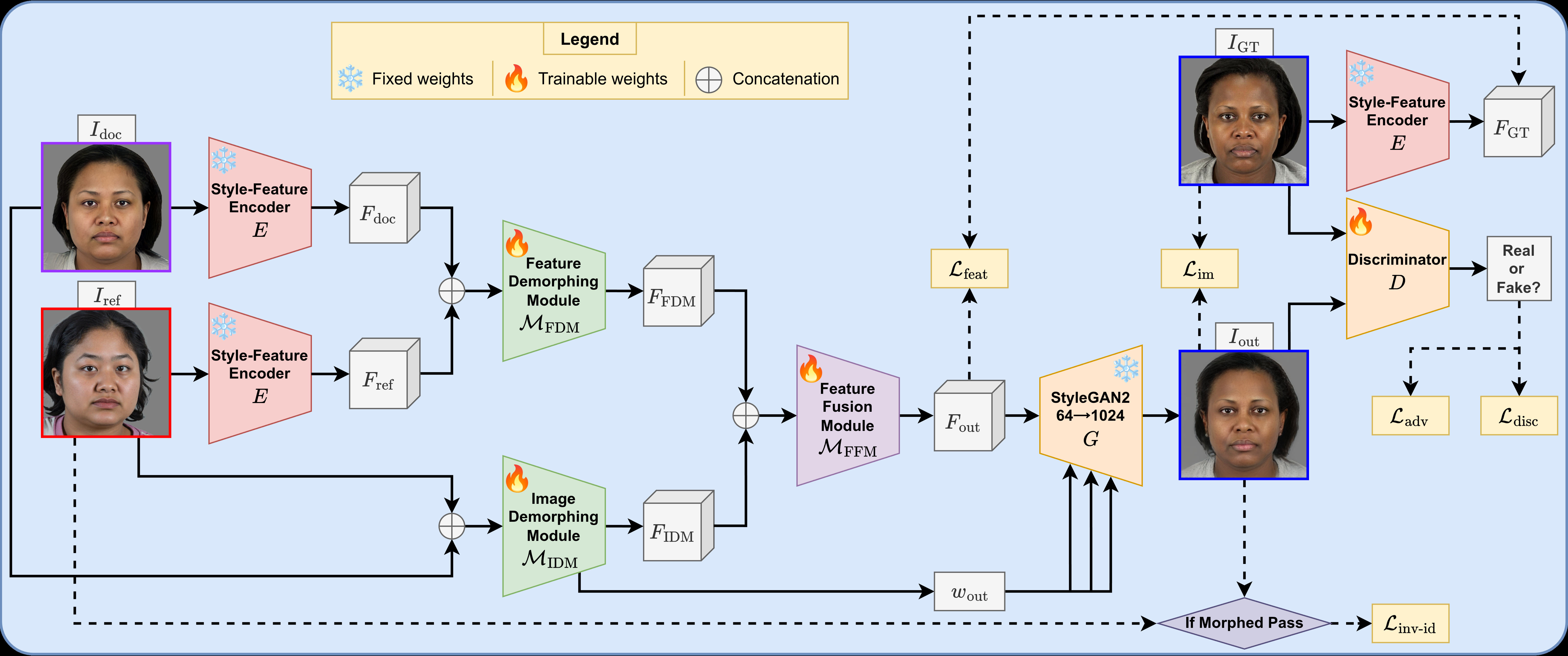
Fig 3: Overview
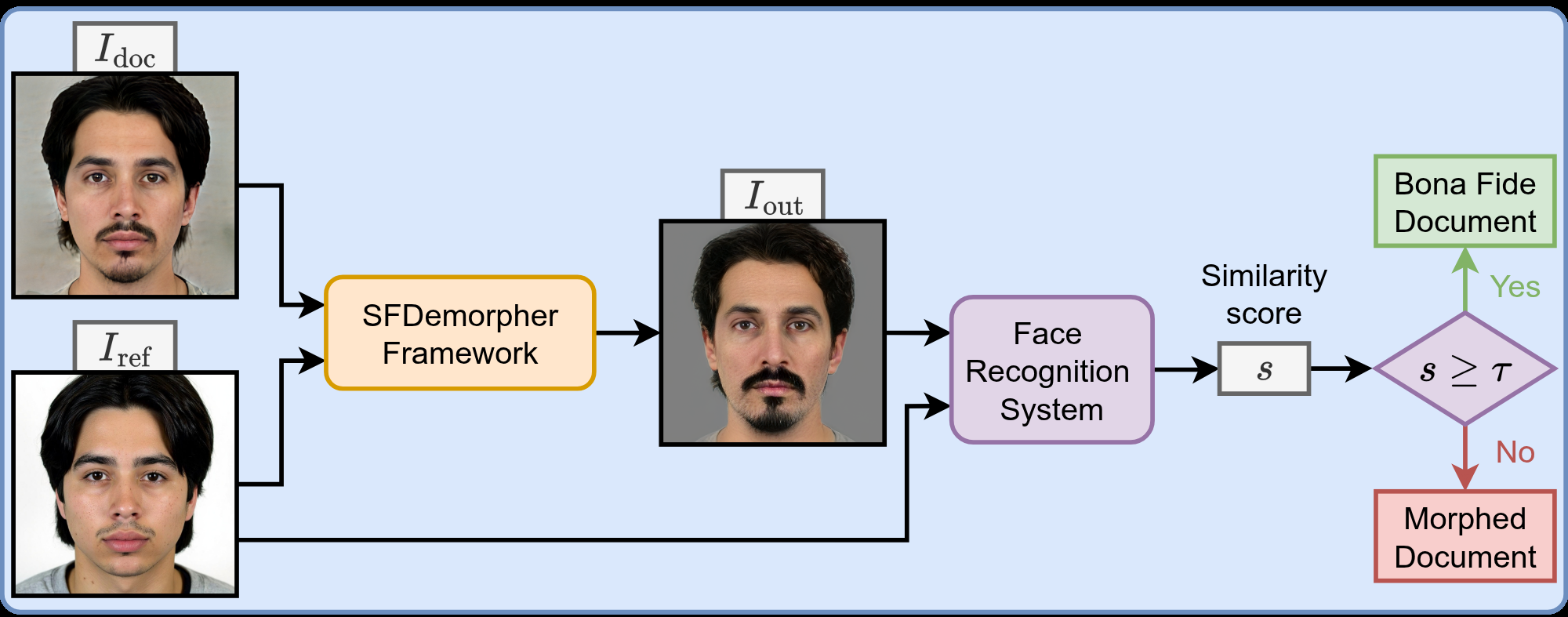
Fig 5 (page 8).

Fig 4: Qualitative results of accomplice identity restoration on morphed images from the FRLL-Morphs-

Fig 5: Qualitative results on the FEI Morph V2 [22, 63] dataset on splicing-based [24] morphs. The
Fig 6: Qualitative results of bona fide iden-
Limitations
- The excerpt does not include the actual numeric results tables, so claims of SOTA generalizability cannot be independently checked from the provided text alone.
- Training excludes criminal-restoration targets because they are ill-posed for splicing-based morphs; that leaves a real operational scenario evaluated only post hoc, not learned directly.
- The system depends on a trusted reference image and on an FRS such as AdaFace, so failure modes in the recognizer propagate directly into D-MAD decisions.
- The adversarial threat model is not deeply specified; there is no explicit adaptive attacker who knows the demorpher and optimizes morphs against it.
- BMS is introduced as a useful margin metric, but threshold calibration and real operating-point selection across deployments are not fully resolved in the excerpt.
- Reproducibility details are incomplete in the provided text: the appendix is referenced for module/hyperparameter specifics, but code release, seeds, and full training schedule are not stated here.
Open questions / follow-ons
- Can the dual-pass strategy be extended to other D-MAD settings where the trusted reference is noisy, low-resolution, or captured under a different sensor pipeline?
- How does SFDemorpher behave against adaptive morphing attacks optimized end-to-end against the demorpher plus AdaFace decision rule?
- Would training on additional bona fide capture variations reduce dependence on synthetic data, or is the synthetic-majority design already near the best trade-off?
- Can the same joint style-feature approach be adapted to other biometric traits, such as iris or periocular morphing-style attacks?
Why it matters for bot defense
For a bot-defense or biometric-assurance engineer, the main takeaway is that demorphing is only useful operationally if it is trained on the normal case, not just the attack case. The dual-pass setup is the part to pay attention to: if your production score pipeline assumes every sample is suspicious, you will likely hurt bona fide users and miscalibrate thresholds. The paper also reinforces a broader lesson for CAPTCHA-adjacent or identity-verification systems: artifact detection alone is brittle when attack generation gets better, so consistency against a trusted reference can be a stronger signal than looking for visible artifacts.
Practically, this suggests two implementation concerns. First, any deployment using a demorphing-style stage needs careful calibration against the downstream matcher, because the final decision is only as good as the similarity threshold and the recognizer’s embedding stability. Second, if you operate in a setting with mostly legitimate traffic, bona fide reconstruction quality is not a nice-to-have; it is central to reducing false alarms. SFDemorpher’s design is a reminder that generalization often comes from training distribution realism, not just from adding a larger generator.
Cite
@article{arxiv2603_28322,
title={ SFDemorpher: Generalizable Face Demorphing for Operational Morphing Attack Detection },
author={ Raul Ismayilov and Luuk Spreeuwers },
journal={arXiv preprint arXiv:2603.28322},
year={ 2026 },
url={https://arxiv.org/abs/2603.28322}
}