
MGDIL: Multi-Granularity Summarization and Domain-Invariant Learning for Cross-Domain Social Bot Detection
Source: arXiv:2603.27928 · Published 2026-03-30 · By Boyu Qiao, Yunman Chen, Kun Li, Wei Zhou, Songlin Hu, Yunya Song
TL;DR
MGDIL tackles cross-domain social bot detection under two practical problems that most prior systems do not handle well: missing or inconsistent user fields, and severe train-test distribution shift across datasets and time periods. Instead of feeding raw heterogeneous signals directly into a classifier, the paper first converts profile metadata and historical posts into a single textual format using LLM-based multi-granularity summarization, then fine-tunes an LLM with instruction tuning, and finally adds domain-adversarial and contrastive objectives to make the learned representation less domain-specific. A graph module is optionally layered on top when user relations are available.
The main empirical claim is that this combination is substantially more robust than traditional ML, neural, graph, and prompt-only LLM baselines on cross-domain evaluation. The authors train on 13 datasets, hold out 2 newer datasets as targets, and report that MGDIL gives the best overall accuracy and Macro-F1 across the reported settings, with the biggest gains on the hardest target dataset (Fox-2023). The paper also shows that summarized historical posts are more useful than raw post text for transfer, and that vanilla LoRA instruction tuning alone is not enough to prevent collapse under shift.
Key findings
- The authors train on 13 social-bot datasets and evaluate on 2 held-out target datasets; MGDIL-MetaSummary reaches 96.42 ± 0.60 Accuracy and 94.13 ± 0.84 Macro-F1 on Fox-2023, versus LoRA-Finetune MetaSummary at 75.86 ± 20.22 Accuracy and 70.41 ± 17.18 Macro-F1 (Table 1).
- On TwiBot-2020, MGDIL-MetaData achieves 79.80 ± 0.10 Accuracy and 76.82 ± 0.10 Macro-F1, outperforming the best LoRA-Finetune MetaData baseline at 76.64 ± 2.72 Accuracy and 73.74 ± 3.25 Macro-F1 (Table 1).
- On the merged dataset, MGDIL-MetaSummary scores 81.63 ± 0.11 Accuracy and 78.27 ± 0.21 Macro-F1, compared with LoRA-Finetune MetaSummary at 77.08 ± 1.24 Accuracy and 73.42 ± 1.53 Macro-F1 (Table 1).
- Direct prompting with off-the-shelf LLMs is not enough: GPT-5.4-nano gets only 46.60 ± 0.05 Accuracy / 46.34 ± 0.05 Macro-F1 on the merged dataset, and Deepseek-V3.2 gets 60.23 ± 0.25 / 40.24 ± 0.14 there (Table 1).
- OOD adaptation baselines help only modestly on TwiBot-2020: BotRGCN + Tuning reaches 63.28 ± 3.01 Accuracy / 62.49 ± 8.89 Macro-F1, and RGT + Tuning reaches 67.68 ± 2.85 / 66.60 ± 2.37, still below MGDIL (Table 1).
- The paper reports that summary-based inputs outperform raw historical posts in the ablation of Figure 3; the text states that raw historical posts perform worse and are less stable, especially under larger domain shift.
- The implementation fine-tunes Qwen2.5-1.5B with LoRA on four NVIDIA H800 80GB GPUs, and all experiments are repeated with five random seeds, with results reported as mean ± standard deviation (Experiment Setup).
Threat model
The adversary is an emerging social bot or bot operator whose accounts may be partially observed, may omit some profile fields, may use different language styles across time and datasets, and may induce distribution shift relative to training data. The detector is assumed not to have fully reliable in-domain test distribution and must generalize to unseen datasets and newer bot populations. The method does not assume the attacker can corrupt labels, modify the training process, or directly attack the model with query-based adaptation; instead, the main challenge is OOD generalization under incomplete information.
Methodology — deep read
The threat model is cross-domain social-bot detection under distribution shift, not an active evasion game with adaptive adversaries at test time. The authors assume the detector may see incomplete user information (missing profile fields, unavailable relations, sparse historical posts) and that the target domain can differ from the source domains by topic, release time, bot style, and schema completeness. In their OOD setup, the model is trained on 13 older datasets and evaluated on 2 newer held-out datasets; they also group the 13 sources into 3 temporal domains to provide coarse domain labels for adversarial learning. The paper does not describe adversaries that can specifically probe the detector, adapt to its prompts, or poison training data.
Data-wise, the paper uses 15 social-bot detection datasets in total, but the excerpt only names some of them explicitly: Cresci-2015, Cresci-2017, TwiBot-2020, and Fox-2023. The datasets vary in annotation protocol, bot category, topical context, and modality completeness (Table 4 in the appendix, referenced but not shown). The authors say they preprocess all accounts into a unified instruction-tuning format, and that missing profile fields are not silently dropped: they are rendered as explicit placeholders such as “unavailable” or “unknown.” Historical posts are summarized into five fixed dimensions: content themes, sentiment polarity, emotional tone, linguistic style, and communicative function. For the cross-domain contrastive objective, the supervision includes both class labels (bot/human) and coarse domain labels derived from dataset release time. The source/target split is a held-out-domain evaluation rather than random within-dataset splitting.
Architecturally, MGDIL has three main stages. First, multi-granularity summarization converts heterogeneous inputs into unified text. Profile metadata are mapped field-by-field into slot strings using predefined templates and missing-value indicators. Historical posts are summarized by DeepSeek-V3.2 into structured outputs over the five dimensions above. Second, the concatenated text prompt is fed into a base LLM, Qwen2.5-1.5B, which is LoRA-finetuned for task-oriented instruction following. The LLM encoder output is then projected into a latent vector h_i. Two auxiliary objectives are attached to this latent vector: a domain discriminator with a gradient reversal layer (GRL), which tries to predict domain IDs while the encoder learns to make them hard to infer; and a cross-domain supervised contrastive loss, which pulls same-class samples from different domains together and pushes different-class samples apart. Third, when relation information is available, a relation-aware GNN takes the learned latent representations as node features and performs relation-specific message passing over a user graph. The graph module is explicitly optional in the sense that some datasets do not provide relation structure; the main paper notes that graph-based baselines are only evaluated where graph data exist.
Training is described at a fairly high level, with some key settings omitted in the excerpt and deferred to Table 8 in the appendix. The paper states that all experiments run on four NVIDIA H800 GPUs with 80 GB memory under CUDA 12.8, and that results are averaged over five random seeds. The backbone is Qwen2.5-1.5B, and LoRA is used for parameter-efficient fine-tuning. The total objective is the sum of classification loss, adversarial loss weighted by λ_adv, and contrastive loss weighted by λ_con. The paper also includes a hyperparameter analysis figure for λ_adv and λ_con, suggesting those weights materially affect performance. What is not fully specified in the excerpt are exact batch size, epoch count, optimizer choice, learning rate schedule, GRL coefficient schedule, and temperature τ; those details are presumably in the appendix or code release.
Evaluation is primarily cross-domain and compares against six groups of baselines: traditional ML (Random Forest, SVM, Decision Tree, AdaBoost), neural methods (MLP, MLP+RoBERTa), graph methods (BotRGCN, RGT), OOD methods (Tuning, AdaBot), prompted LLMs (GPT-5.4-nano, Deepseek-V3.2), and a vanilla LoRA instruction-tuning baseline. Metrics are Accuracy and Macro-F1, reported as mean ± standard deviation across five seeds. The most important comparison in Table 1 is that vanilla instruction tuning helps but remains unstable under shift, whereas MGDIL improves both mean performance and variance. The authors also run an ablation around multi-granularity summarization in Figure 3, comparing metadata only, metadata + summarized history, and metadata + raw history. That ablation is central because it isolates the claim that the LLM summarization step is doing real work rather than just adding more tokens. A concrete end-to-end example, as implied by the method: a user with missing profile fields and several historical posts is first converted into a slot-based profile text with explicit placeholders; the historical posts are summarized by dimension into a fixed-format text; the combined prompt is instruction-tuned by Qwen2.5-1.5B; the latent embedding is then pushed to be class-discriminative but domain-invariant via the GRL discriminator and cross-domain contrastive loss; if relation data exist, the graph module further refines the representation before final bot/human classification.
Reproducibility looks decent but not complete from the excerpt alone. The authors say the code is available on GitHub, and the paper reports five-seed averages and standard deviations, which is good practice. However, the exact preprocessing pipeline, temporal domain partitioning, appendix tables, and full hyperparameter settings are not shown in the provided text. The snippet also hints that some baselines are not evaluated on all datasets because required modalities are missing, which is fair but means the comparison set is not perfectly uniform across all methods.
Technical innovations
- LLM-based multi-granularity summarization that converts heterogeneous profile and historical-post inputs into a unified textual representation instead of relying on raw multi-modal feature fusion.
- A joint objective combining instruction tuning, domain-adversarial learning via GRL, and cross-domain supervised contrastive learning to reduce dataset-specific leakage while preserving class separation.
- A relation-aware GNN refinement stage that can sit on top of the semantic encoder when social graph structure is available.
- Explicit handling of missing fields with placeholders in the rendered input, rather than dropping absent modalities silently.
Datasets
- 15 social bot detection datasets total — size not specified in the excerpt — public datasets aggregated by the authors
- 13 source datasets for training — size not specified in the excerpt — drawn from the 15-dataset collection
- 2 held-out target datasets for evaluation (TwiBot-2020, Fox-2023) — size not specified in the excerpt — public datasets
- Cresci-2015 — size not specified in the excerpt — public
- Cresci-2017 — size not specified in the excerpt — public
- TwiBot-2020 — size not specified in the excerpt — public
- Fox-2023 — size not specified in the excerpt — public
Baselines vs proposed
- Random Forest: Accuracy = 56.43 ± 1.20 vs proposed = 81.63 ± 0.11 on merged dataset (MetaSummary)
- SVM: Accuracy = 54.37 ± 0.30 vs proposed = 81.63 ± 0.11 on merged dataset (MetaSummary)
- AdaBoost: Macro F1 = 64.04 ± 0.16 vs proposed = 78.27 ± 0.21 on merged dataset (MetaSummary)
- MLP: Accuracy = 71.29 ± 3.35 vs proposed = 79.83 ± 0.18 on TwiBot-2020 (MetaSummary)
- BotRGCN: Accuracy = 60.07 ± 3.85 vs proposed = 79.80 ± 0.10 on TwiBot-2020 (MetaData)
- RGT + Tuning: Macro F1 = 66.60 ± 2.37 vs proposed = 76.82 ± 0.10 on TwiBot-2020 (MetaData)
- GPT-5.4-nano: Macro F1 = 46.34 ± 0.05 vs proposed = 78.27 ± 0.21 on merged dataset (MetaSummary)
- Deepseek-V3.2: Accuracy = 80.01 ± 0.51 vs proposed = 96.42 ± 0.60 on Fox-2023 (MetaSummary)
- LoRA-Finetune MetaSummary: Accuracy = 75.86 ± 20.22 vs proposed = 96.42 ± 0.60 on Fox-2023 (MetaSummary)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.27928.

Fig 1: Two Core Challenges in Social Bot Detection.

Fig 2: Overview of the MGDIL framework. MGDIL first summarizes user information into unified structured textual inputs,

Fig 3 (page 2).

Fig 4 (page 4).
Fig 5 (page 4).
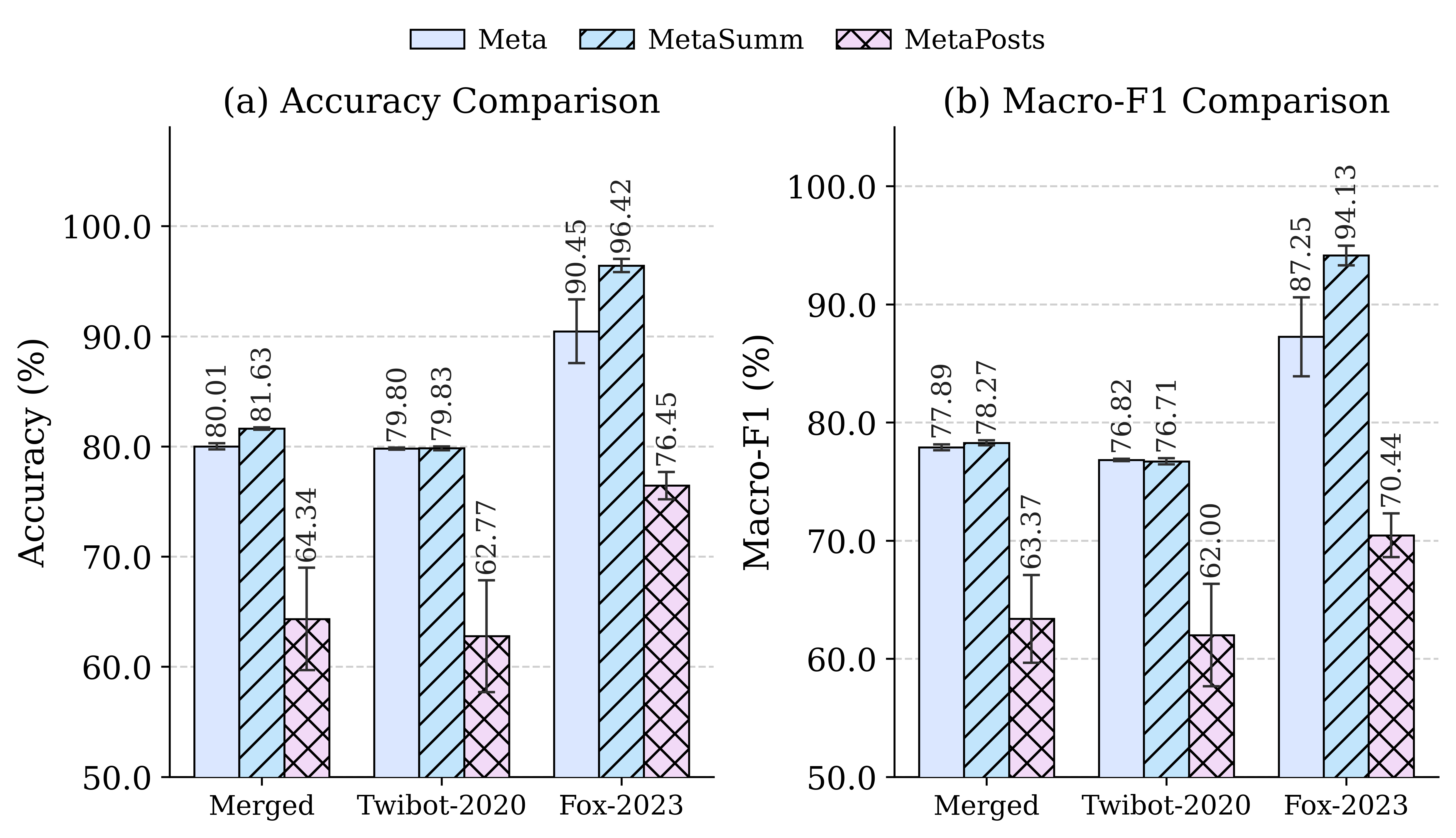
Fig 3: Comparison Between Raw Historical Posts and
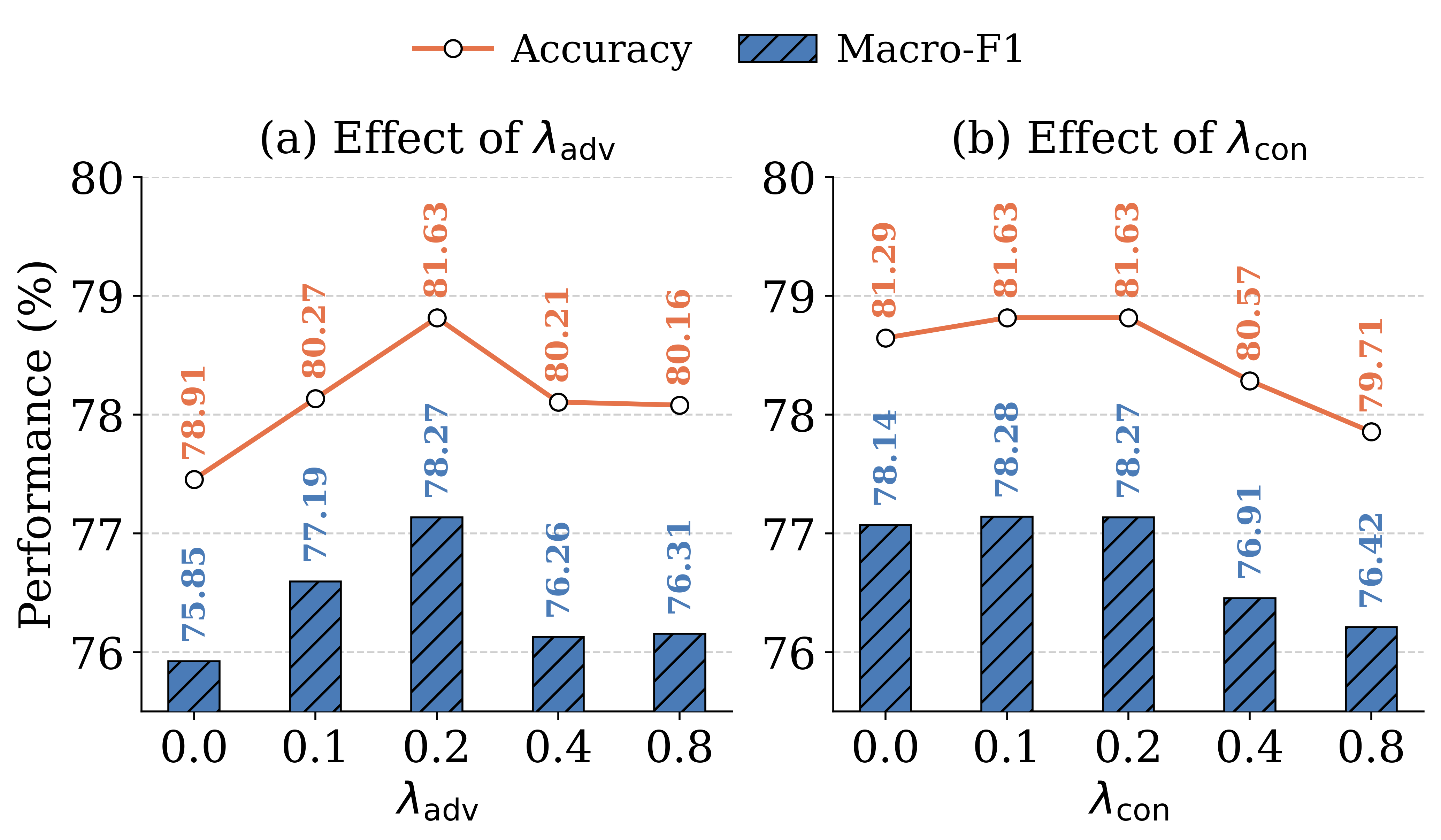
Fig 4: Hyperparameter analysis of 𝜆𝑎𝑑𝑣and 𝜆𝑐𝑜𝑛, where
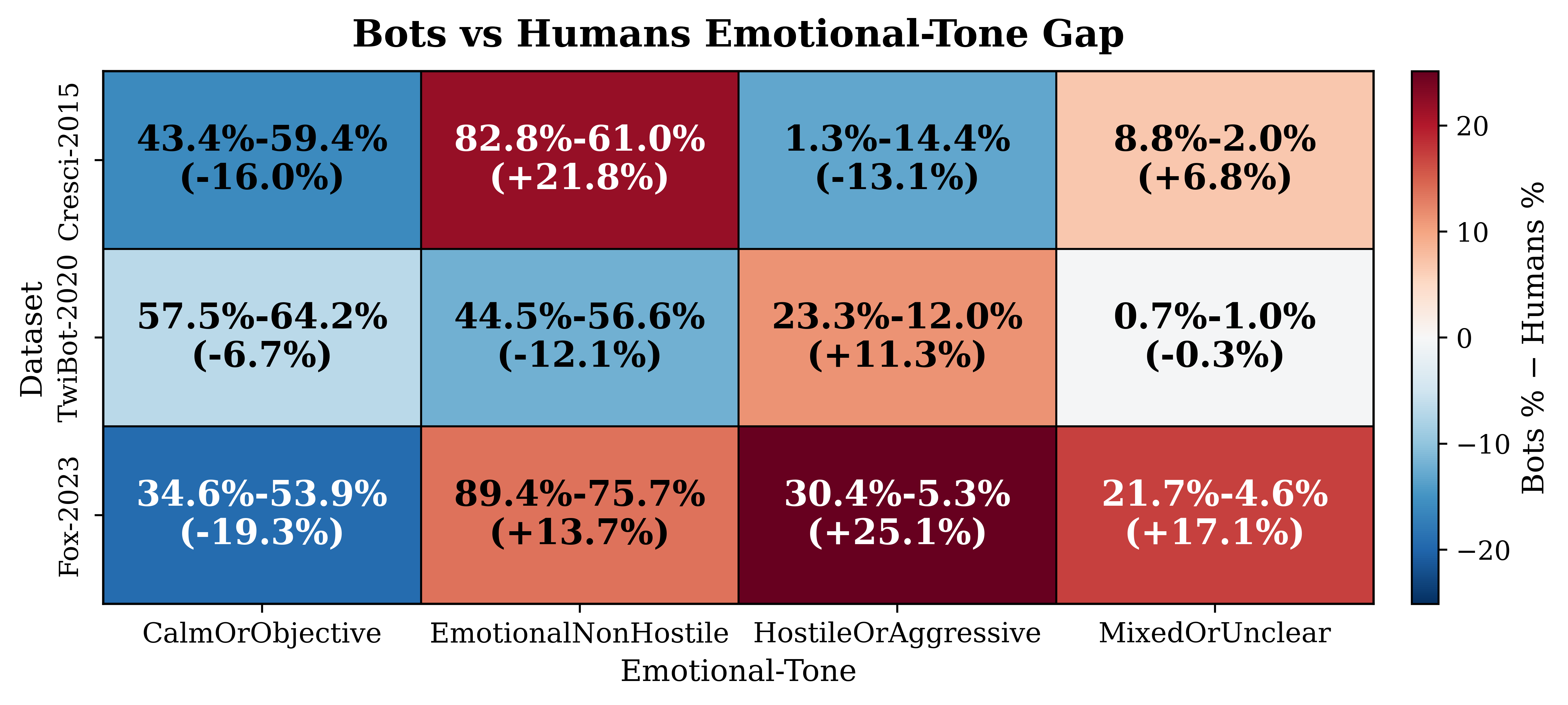
Fig 7: Comparison of emotional tone across bots and humans.
Limitations
- The excerpt does not provide the full dataset sizes, class balance, or per-dataset composition, so it is hard to judge sample adequacy or label noise.
- The domain labels used for adversarial learning are coarse temporal groupings by release date, which may not capture finer shifts such as topic drift or platform-specific changes.
- The graph-enhancement module cannot be evaluated on every dataset because relation information is not always available, making the method partly input-dependent.
- The paper’s strongest gains are reported in cross-domain settings; there is no evidence in the excerpt of robustness against adaptive attackers, prompt injection, or active evasion.
- Some baselines have a much narrower applicability set than MGDIL (for example, graph baselines only on TwiBot-2020), so cross-method comparisons are not perfectly uniform across all datasets.
- The excerpt does not include confidence intervals beyond seed-wise mean ± std, nor statistical significance tests between MGDIL and the strongest baselines.
Open questions / follow-ons
- How much of the gain comes from summarization versus the adversarial/contrastive objectives, if each component were scaled independently on the same target domains?
- Would the method still work if the target domain has a different platform, language, or annotation scheme, rather than just a later temporal split?
- How sensitive is the LLM summarization to prompt wording, category schema design, and summarizer model choice (e.g., DeepSeek-V3.2 versus a smaller open model)?
- Can the graph module be made optional at inference without hurting performance when relation data are missing, or does the model implicitly depend on graph signals during training?
Why it matters for bot defense
For bot-defense practitioners, the main takeaway is that representation robustness can come from normalizing heterogeneous signals into a stable textual schema before classification, rather than trying to engineer one detector per modality. In a CAPTCHA-adjacent setting, this suggests a similar pattern for behavior-risk scoring: convert sparse account metadata, interaction history, and content traces into a fixed semantic summary, then train with explicit domain-invariance objectives across products, locales, or time slices.
Operationally, the paper is a reminder that prompt-only LLM detectors are likely to be brittle under domain shift, especially when the input schema changes or important fields are missing. The most relevant engineering lesson is to evaluate on held-out domains and later time windows, not just random splits, and to test whether summary abstractions preserve signal when raw features are incomplete. If you have graph or relationship data, the paper also suggests using it as an optional refinement layer rather than making the entire detector depend on it.
Cite
@article{arxiv2603_27928,
title={ MGDIL: Multi-Granularity Summarization and Domain-Invariant Learning for Cross-Domain Social Bot Detection },
author={ Boyu Qiao and Yunman Chen and Kun Li and Wei Zhou and Songlin Hu and Yunya Song },
journal={arXiv preprint arXiv:2603.27928},
year={ 2026 },
url={https://arxiv.org/abs/2603.27928}
}