
CAPTCHA Solving for Native GUI Agents: Automated Reasoning-Action Data Generation and Self-Corrective Training
Source: arXiv:2603.23559 · Published 2026-03-23 · By Yuxi Chen, Haoyu Zhai, Chenkai Wang, Rui Yang, Lingming Zhang, Gang Wang et al.
TL;DR
This paper addresses the challenging problem of enabling native GUI agents—end-to-end vision-language models that operate directly on raw screenshots—to robustly solve modern interactive CAPTCHA challenges. While specialized CAPTCHA solvers exist, they lack general GUI capabilities, and general GUI agents fail to handle the unique visual, reasoning, and interactive complexity of modern CAPTCHAs. The authors present ReCAP, a CAPTCHA-capable GUI agent that integrates both CAPTCHA-solving and general GUI interaction. They develop a dynamic CAPTCHA system spanning seven diverse CAPTCHA types designed to train fundamental CAPTCHA-solving primitives such as robust OCR, fine-grained visual understanding, spatial localization, and continuous control. A key innovation is a large-scale automated data collection and curation pipeline generating rich reasoning-action traces, including self-correction traces derived from failed attempts to teach error recovery. Training with a joint reasoning/action loss on this data significantly boosts CAPTCHA solving success rates from roughly 30% to 80% on the dynamic CAPTCHA benchmark while retaining strong general GUI performance. The approach also transfers zero-shot to a large suite of real-world CAPTCHA challenges from leading providers, substantially outperforming prior open-source GUI agents and specialized baselines in both success rate and interaction efficiency. Extensive ablation studies validate the critical role of chain-of-thought reasoning supervision and self-correction data. Overall, this work bridges the gap between general GUI agents and CAPTCHA solvers using scalable data, reasoning-driven training, and careful benchmarking.
Key findings
- On the dynamic CAPTCHA benchmark covering 7 challenge types, ReCAP-32B achieves an 81.00% overall success rate, compared to under 35.00% for prior general GUI agents and specialized pipelines (Table 1).
- ReCAP models require only about 1.54 average interaction steps to solve CAPTCHAs successfully, substantially fewer than 2-4 steps for other GUI agents and at least 3-5 steps for the specialized Halligan pipeline.
- Zero-shot transfer to a real-world CAPTCHA benchmark spanning 26 CAPTCHA types demonstrates strong generalization: ReCAP-32B outperforms baseline models and frequently achieves the best or second-best success rates on difficult interaction-heavy challenges (Table 2).
- Finetuning on CAPTCHA data preserves or slightly improves general GUI agent performance on established benchmarks including Android Control, ScreenSpot-V2, and Multimodal-Mind2Web (Table 3).
- Ablation of chain-of-thought (CoT) reasoning supervision reduces overall CAPTCHA success rate from 71.90% to 66.40% (Table 4), with the largest impact on complex challenges requiring multi-step logic.
- Including self-correction traces derived from failed attempts improves the model’s ability to reflect on and recover from errors, yielding superior CAPTCHA solving performance (Section 4.6).
- ReCAP-8B performance shows degradation on general GUI tasks compared to ReCAP-32B, indicating a capacity-generalization trade-off when jointly training for CAPTCHA and broad GUI behaviors.
Threat model
Adversaries are automated agents attempting to solve CAPTCHAs by directly interacting with native GUI challenges through visual perception and sequential GUI action generation. They do not have privileged ground truth or direct API access to CAPTCHA answers and must solve steps within limited interaction budgets and time constraints. They cannot inject manual intervention or access external solver oracles beyond model inference.
Methodology — deep read
Threat Model & Assumptions: The adversary is a CAPTCHA solver aiming to autonomously interact with native GUI CAPTCHA challenges, without explicit privileged access to ground truth answers. The adversary can observe raw GUI screenshots and perform sequences of GUI actions (clicks, drags, typing). However, it cannot cheat by querying solution oracles beyond the designed environment. The goal is to robustly solve arbitrary, interactive CAPTCHAs within limited interaction steps and time constraints.
Data: The authors develop a dynamic CAPTCHA generation system covering seven representative CAPTCHA types: Text, Compact Text, Icon Match, Icon Selection, Paged, Slider, and Image Grid. Captchas are procedurally generated with randomized layout, styling, and diverse visual assets (icons, images, distorted text) to mitigate overfitting and promote semantic reasoning rather than pattern memorization. The system supports real-time interactive feedback and provides rich meta annotations (answer labels, target coordinates, user actions). The training dataset includes ~150K expert solution trajectories with chain-of-thought (CoT) reasoning traces and ~10K self-correction trajectories created from failed student attempts, plus 73K general GUI interaction trajectories from prior datasets (Aguvis, AgentNet).
Architecture/Algorithm: ReCAP builds on Qwen3-VL vision-language foundational models (8B and 32B parameter variants). The model inputs raw screenshots and autoregressively generates interleaved reasoning text tokens and structured multi-action tokens representing GUI operations. The output format allows multiple GUI actions in a single response to enable efficient, low-latency interaction. A unified loss function weights reasoning and action tokens equally to balance accurate reasoning and precise control. No new model components beyond this training paradigm and loss weighting are introduced. Chain-of-thought reasoning helps the model learn intermediate semantic decisions explicitly.
Training Regime: Models are finetuned for a single epoch over approx. 230,000 samples (150K solution +10K self-correction + 70K general GUI). Both reasoning and action loss weights are set to 0.5. The expert reasoning traces are generated by a strong, larger Qwen2.5-VL-72B-Instruct model. Training occurs with fixed random seeds and standard optimization, though exact hardware details are not specified.
Evaluation Protocol: Evaluation uses held-out CAPTCHA instances from the dynamic system with substantial style/layout variation. Each CAPTCHA type is evenly represented in test sets of 1000 samples. Models have limited interaction budgets: 5 steps for most, 8 for more complex types. Metrics include CAPTCHA solve success rate and average number of interaction steps in successful trials (proxy for latency). Baselines include multiple open-source GUI agents, the specialized Halligan CAPTCHA solver, and OpenAI’s Computer-Use Agent (CUA). Additional zero-shot transfer evaluation uses a real-world CAPTCHA benchmark covering 26 variants collected from major providers. General GUI agent benchmarks (Android Control, ScreenSpot-V2, Multimodal-Mind2Web) are used to measure baseline preservation.
Reproducibility: The authors open-source the dynamic CAPTCHA system, datasets, code, and trained ReCAP models at https://github.com/ASTRAL-Group/ReCAP-Agent. The dynamic CAPTCHA engine supports unbounded data generation facilitating future research. Full reasoning-action trace data and self-correction pipelines are included.
Concrete Example: A CAPTCHA with multiple icons randomly styled and arranged is rendered by the dynamic system. The expert reasoning model generates a chain-of-thought trace such as identifying target icons by semantic features, verifying candidate clicks, and planning a click sequence. The final correct GUI action sequence is paired with the reasoning. Failed student model attempts are collected on similar instances, with introspective correction traces generated by the expert to teach error recovery. The ReCAP model is finetuned on thousands of such traces to internalize the reasoning-action pipeline, enabling efficient zero-shot solving of novel visual CAPTCHA variants.
Technical innovations
- A dynamic CAPTCHA generation system spanning seven diverse CAPTCHA types with stochastic rendering and rich visual diversity that enables unbounded scalable data collection for training.
- An automated pipeline generating large-scale CAPTCHA interaction trajectories paired with explicit chain-of-thought reasoning traces to train native reasoning-action models.
- Leveraging failed model attempts to generate self-correction traces, training the agent to reflect on and correct its errors online for improved robustness.
- Unified training with interleaved reasoning and multi-action output tokens, weighted equally, allowing simultaneous learning of precise control and semantic decision-making.
- Demonstration that integrated CAPTCHA solving ability can be absorbed by large-scale vision-language models without compromising general GUI capabilities.
Datasets
- Dynamic CAPTCHA System Dataset — ~160,000 total trajectories (150K solution + 10K self-correction) — generated via proprietary dynamic CAPTCHA system
- General GUI Interaction Datasets — approximately 73,000 trajectories combined from Aguvis and AgentNet — publicly referenced prior datasets
- Real-World CAPTCHA Benchmark — 26 CAPTCHA variants collected from Google, hCAPTCHA, GeeTest, Arkose Labs, Amazon, etc. — Halligan (Teoh et al., 2025) benchmark dataset
Baselines vs proposed
- UI-TARS-1.5-7B: overall CAPTCHA solve rate = 33.6% vs ReCAP-32B: 81.0%
- Qwen3-VL-Thinking-8B: overall CAPTCHA solve rate = 28.7% vs ReCAP-8B: 71.9%
- Halligan specialized pipeline: overall CAPTCHA solve rate = 25.14% vs ReCAP-32B: 81.0%
- OpenAI CUA agent: overall CAPTCHA solve rate = 31.8% vs ReCAP-32B: 81.0%
- On real-world CAPTCHAs, Halligan achieves best results on some text-heavy challenges (e.g., 66% on mtcaptcha), but ReCAP-32B outperforms on interaction-heavy types such as recaptchav2 (63% vs 61%) and hcaptcha (26% vs 2%)
- On general GUI benchmarks, Android Control success rates: Qwen-32B = 67.2%, ReCAP-32B = 67.4%; ScreenSpot-V2: Qwen-32B = 94.5%, ReCAP-32B = 93.24%
- Ablation: Removing CoT reasoning reduces ReCAP-8B CAPTCHA success from 71.9% to 66.4%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.23559.
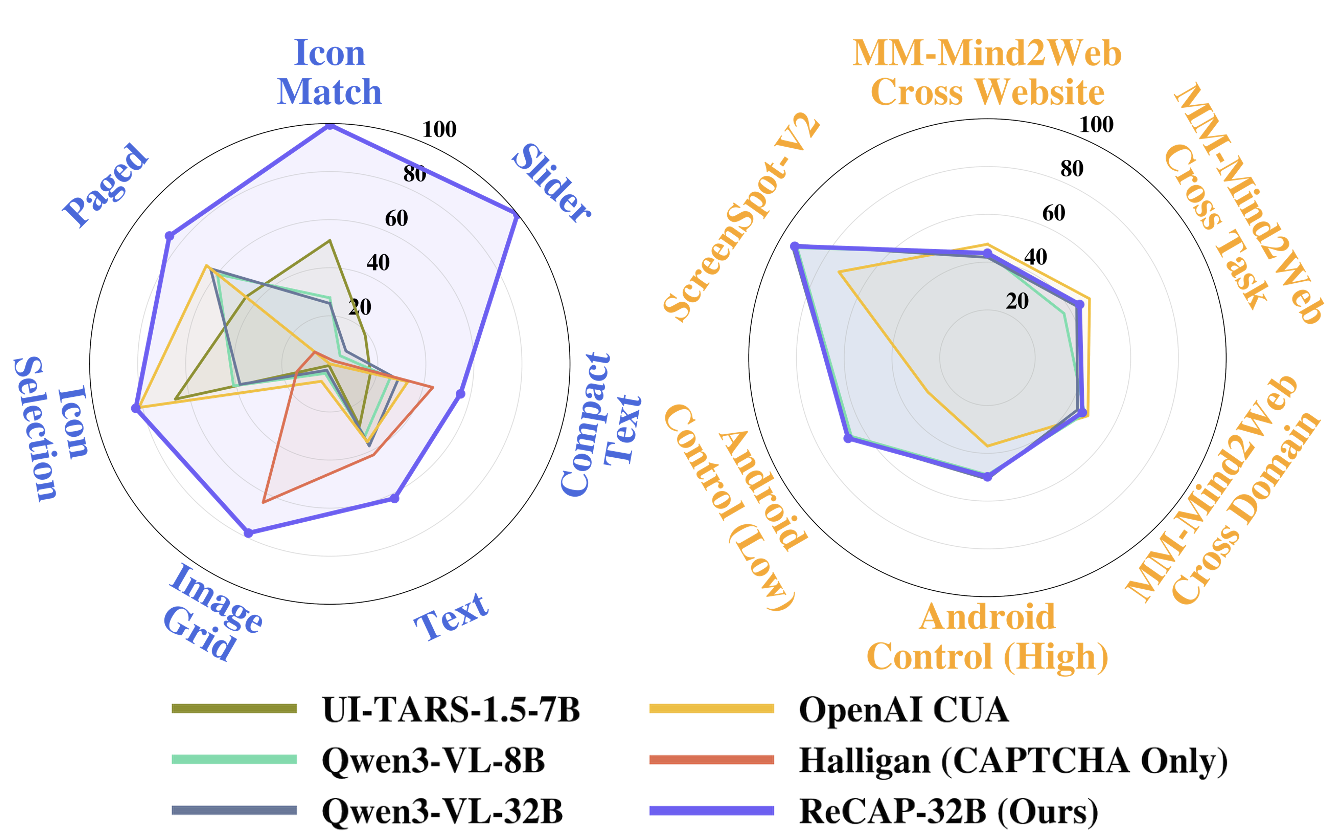
Fig 1: Performance on CAPTCHA and general GUI agent

Fig 2: The suite of CAPTCHA challenges in our dynamic CAPTCHA system, designed to train fundamental CAPTCHA-solving
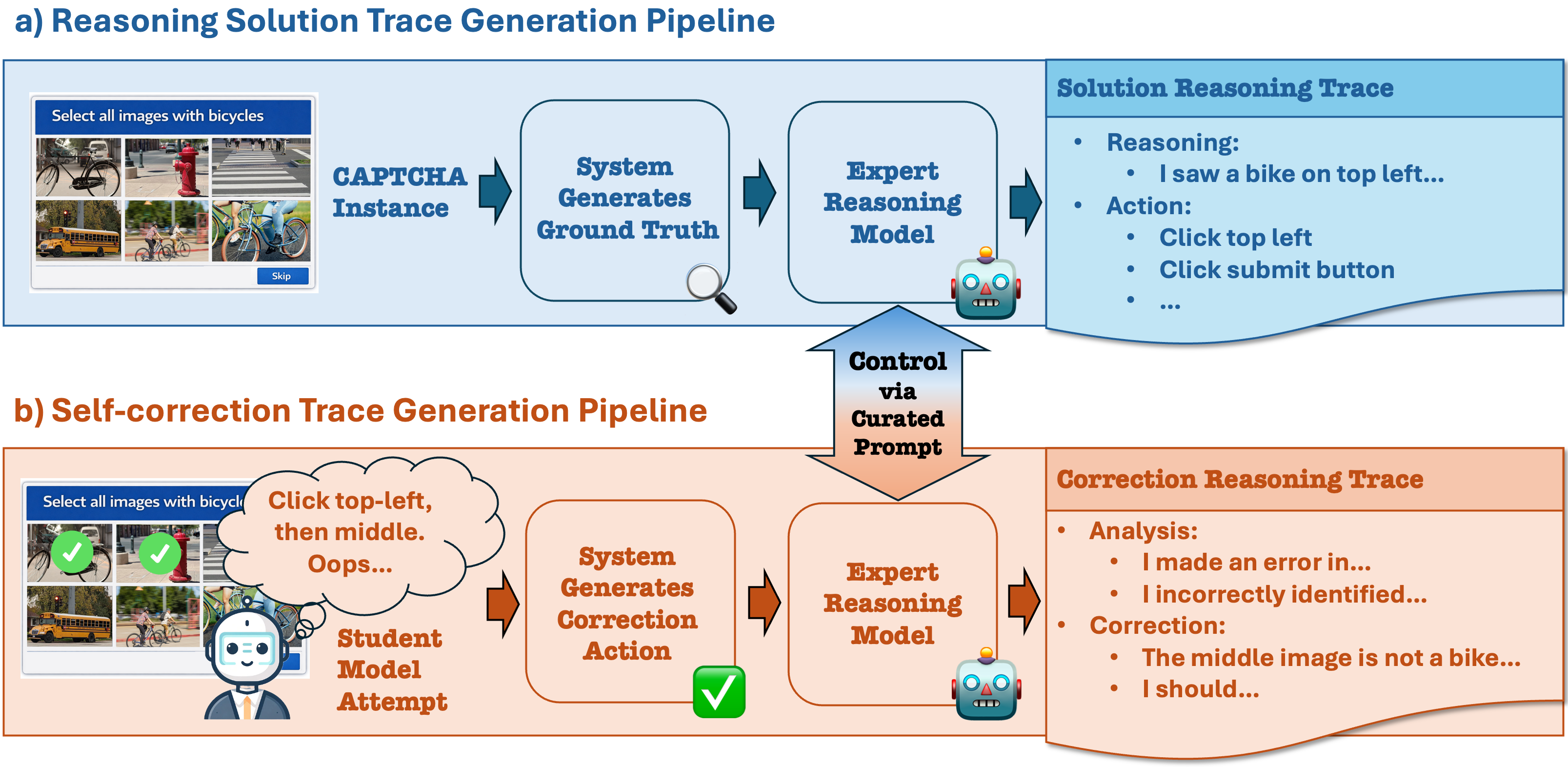
Fig 3: Data collection and curation pipeline for our CAPTCHA training dataset. a) shows the reasoning solution trace generation
Fig 4 (page 11).
Fig 5 (page 11).
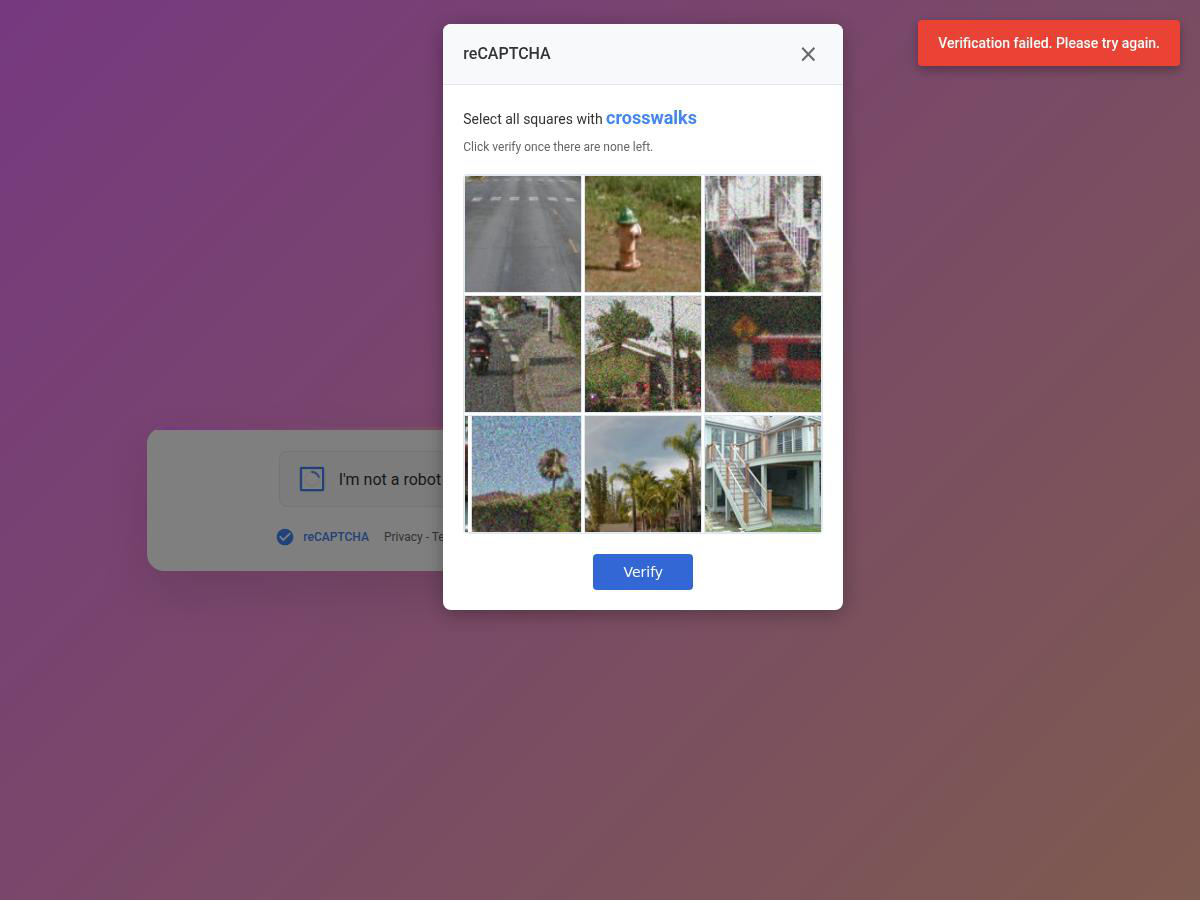
Fig 4: Text-like CAPTCHA Challenges
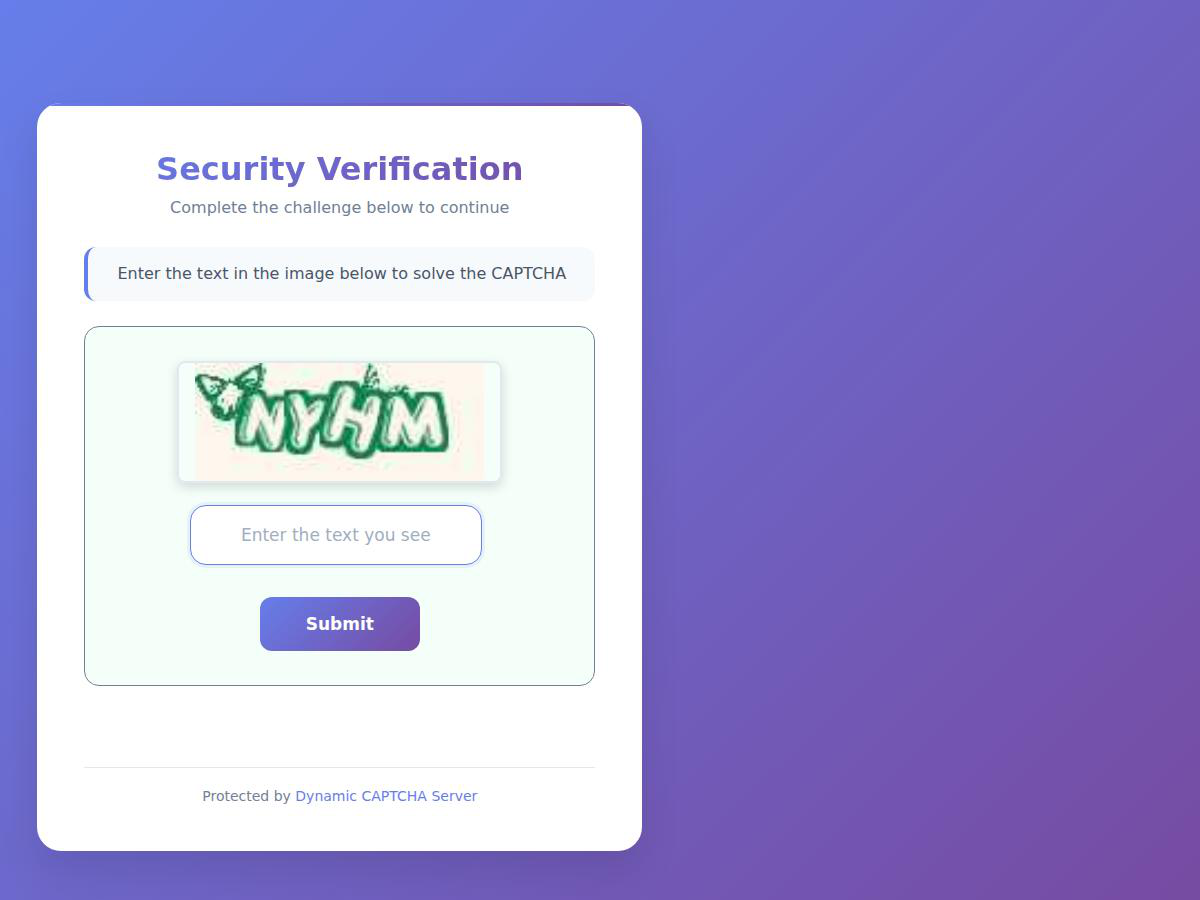
Fig 5: Icon Selection CAPTCHA Challenge
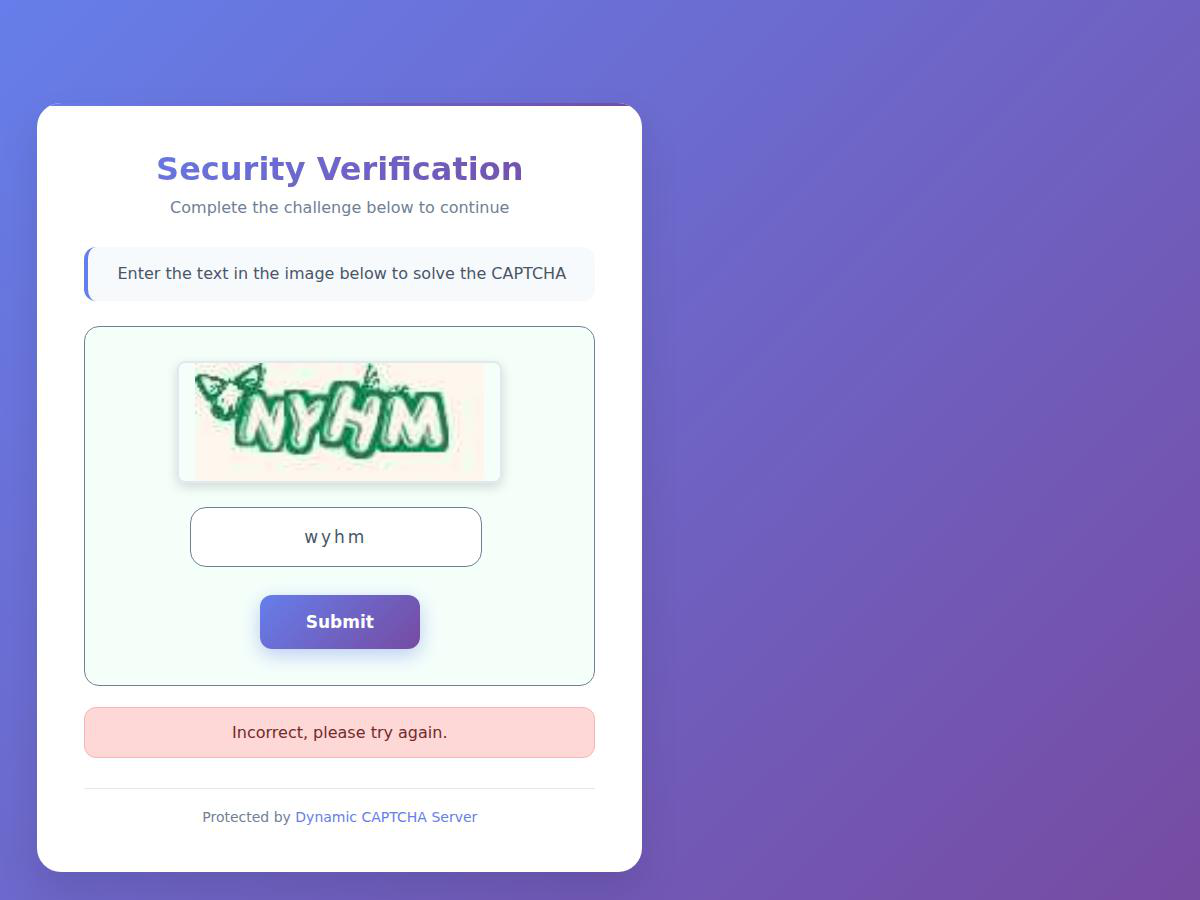
Fig 6: Drag-related CAPTCHA Challenges
Limitations
- Limited model capacity of smaller variants (e.g., 8B) leads to degradation on general GUI tasks when jointly trained for CAPTCHA solving.
- Evaluation primarily focuses on the proposed dynamic CAPTCHA system and a single real-world CAPTCHA benchmark; broader distribution or adversarial CAPTCHAs were not tested.
- Self-correction data is generated by a strong expert model, which may not fully capture complex failure modes under adaptive adversarial CAPTCHAs.
- The approach depends on accurate ground-truth annotations and a rich CAPTCHA renderer, which may not generalize to all real-world CAPTCHA variants or modalities (e.g., audio CAPTCHAs).
- Training and inference details such as hardware requirements, latency under real deployment conditions, and robustness to time limits or CAPTCHA refreshes need fuller characterization.
Open questions / follow-ons
- How can self-correction and reasoning traces be further optimized to improve robustness against adversarial or unseen CAPTCHA designs?
- What are the capacity and architectural trade-offs for jointly supporting broad GUI tasks and increasingly complex CAPTCHA challenges in a unified model?
- Can similar reasoning-action training paradigms be extended to non-visual or multi-modal challenges like audio CAPTCHAs or multi-factor authentication?
- How well does the approach generalize to CAPTCHAs with adversarial noise or actively adaptive challenge generation beyond the dynamic rendering system?
Why it matters for bot defense
This work shows that scaling vision-language GUI agents with task-specific data and reasoning-action supervision can substantially close the performance gap on modern CAPTCHA challenges, which now emphasize complex visual reasoning and multi-step interactive behavior. Bot-defense practitioners can leverage such CAPTCHA-capable agents to understand new attack vectors that exploit integrated vision-language reasoning models, potentially revealing weaknesses in CAPTCHA design or deployment. The dynamic CAPTCHA system and reasoning/action data generation pipeline provide a useful testbed for evaluating CAPTCHA robustness and guide improvements toward challenges that reliably resist advanced automated agents. Furthermore, the demonstrated low interaction step count highlights latency and efficiency considerations critical to real-world CAPTCHA defenses. Overall, this research underscores the necessity for evolving CAPTCHA systems beyond heuristic or pattern-based designs as native GUI reasoning agents become increasingly capable.
Cite
@article{arxiv2603_23559,
title={ CAPTCHA Solving for Native GUI Agents: Automated Reasoning-Action Data Generation and Self-Corrective Training },
author={ Yuxi Chen and Haoyu Zhai and Chenkai Wang and Rui Yang and Lingming Zhang and Gang Wang and Huan Zhang },
journal={arXiv preprint arXiv:2603.23559},
year={ 2026 },
url={https://arxiv.org/abs/2603.23559}
}