
SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration
Source: arXiv:2603.21019 · Published 2026-03-22 · By Zihan Guo, Zhiyu Chen, Xiaohang Nie, Jianghao Lin, Yuanjian Zhou, Weinan Zhang
TL;DR
SkillProbe addresses critical security challenges in emerging Large Language Model (LLM) agent skill marketplaces, notably semantic-behavioral inconsistencies and inter-skill combinatorial risks. These vulnerabilities arise when individual skills, although benign in isolation, induce malicious behaviors during collaborative execution, a problem exacerbated by the reliance of agents on natural language documentation that may be misaligned or deceptive. The authors introduce SkillProbe, a multi-stage auditing framework built on multi-agent collaboration and a novel “Skills-for-Skills” modular design, which standardizes auditing as skill modules run by specialized agents.
SkillProbe’s pipeline includes admission filtering (Gatekeeper), semantic-behavioral alignment detection (Alignment Detector), and combinatorial risk simulation (Flow Simulator). It was evaluated on 2,500 real-world skills from the ClawHub marketplace across 8 state-of-the-art LLM reasoning engines. The results reveal a striking popularity-security paradox: over 90% of highly downloaded skills fail rigorous auditing. Moreover, the audit uncovered a giant connected component of high-risk skills, showing systemic cascading vulnerabilities rather than isolated cases. SkillProbe detects zero-day and complex multi-skill attacks missed by prior atomic-level audits, offering scalable governance for trustworthy agent ecosystems.
Key findings
- Over 90% of the top 2,500 most-downloaded ClawHub skills failed at least one auditing phase in SkillProbe, indicating download volume is an unreliable proxy for security.
- High-risk skills form a giant connected component in an inter-skill risk graph, confirming cascading exploit risks are systemic, not isolated.
- SkillProbe identified 9 distinct attack patterns including command injection, indirect prompt injection, data exfiltration, and intent hijacking through combinatorial risk simulation.
- Cross-evaluation across 8 diverse LLM reasoning engines showed strong consensus on high-risk identifications despite large runtime variance (from ~18s to over 280s per audit).
- Sonnet-4.6 model flagged the highest conditional (45%) verdicts indicating stricter semantic-behavioral inconsistency detection compared to other models.
- Semantic deviations were categorized in four classes: Match, Over-declaration, Under-declaration (shadow functions), and Mixed, enabling precise vulnerability classification.
- The Flow Simulator reduced combinatorial risk search space complexity from exponential O(2^N) brute force to linear O(N×|Rules|) via risk fingerprint tagging and policy-driven simulation.
- SkillProbe found multiple zero-day vulnerabilities and composite attacks overlooked by existing single-skill code-level and signature-based scanners.
Threat model
The adversary is a skill developer or attacker who can author agent skills with natural language documentation that appears benign but whose underlying code executes malicious behaviors or violates declared capabilities. They can attempt to exploit semantic-behavioral inconsistency and orchestrate multi-skill chains that trigger emergent attack paths. The adversary cannot control or evade centralized auditing, full multi-agent simulation, or cryptographic integrity checks, but may use subtle shadow functionality and combinatorial attacks to bypass atomic static scanners.
Methodology — deep read
The authors start with a threat model assuming adversaries can publish skills with semantically misleading natural language documentation that hide malicious or excessive behaviors in the executable code. Adversaries cannot evade detection completely but can exploit semantic-behavioral inconsistency and skill chaining to trigger latent vulnerabilities.
The core dataset comprises 2,500 real-world skills sampled from ClawHub as of March 2026, prioritized by descending download volume to emphasize widely used components. Each skill includes natural language documentation (SKILL.md), executable scripts, and configuration files. Data ingestion supports multiple formats (local directories, archives, remote URLs) and deduplication is ensured by SHA256 fingerprinting.
SkillProbe adopts a three-phase multi-agent auditing architecture: (1) Gatekeeper phase integrates existing security tools and LLM-based analyses for malicious code pattern detection and permission compliance evaluation. Multiple Gate Executors operate in parallel; outputs are centrally aggregated with conservative veto logic. (2) Alignment Detector extracts and normalizes declared capabilities from documentation and implemented capabilities from code via regex, AST analysis, code LLMs, and I/O binding tracing. A four-class alignment matrix categorizes semantic consistency issues. (3) Flow Simulator assigns risk tags to skill outputs/inputs and runs combinatorial attack simulations guided by a set of 9 risk-link policies that cover critical attack vectors (e.g., command injection, prompt injection, data exfiltration). It uses evidence enforcement requiring concrete code/document excerpts.
The orchestration is managed by a Security Auditor agent that drives specialized executor agents through a DAG-structured collaborative workflow based on the “Skills-for-Skills” design paradigm. This modularity facilitates extensibility and plug-in integrations.
Evaluation uses 8 diverse LLM series covering high-reasoning (Claude Sonnet 4.65, Gemini 3.1 Pro, GPT-5.2 Codex) and lightweight models (Claude Haiku 4.59, Gemini Flash-Lite 3.1, etc.) to audit the top 20 downloaded skills cross-model, and the full set of 2,500 skills with Nex-N1 as primary for large-scale scanning. Metrics include audit verdict distributions (Approved, Conditional, Rejected), runtime, number and severity of findings, and remediation recommendations.
Audit results are reported with fine-grained scorecards that synthesize findings along three dimensions: malicious patterns, semantic consistency, and composition safety. The final verdict applies a veto rule: one critical failure blocks skill approval. Visualization and retrieval use a Vue 3 frontend with real-time telemetry and embedded semantic vector search.
The setup was run on commodity GPUs/CPUs with asyncio-based backend task queue handling. No explicit mention of random seeds or statistical significance testing is provided. The code and platform (Holos-SkillHub) are publicly accessible, promoting reproducibility. One concrete end-to-end example given is the detection of a skill with over-declared permissions and a hidden code path triggering indirect prompt injection in combination with downstream skills that extract sensitive data.
Technical innovations
- The 'Skills-for-Skills' architecture modularizes auditing steps as skill modules, enabling dynamic multi-agent collaboration and extensibility without core engine changes.
- Semantic-behavioral inconsistency detection via a four-class alignment matrix comparing documentation declared vs. code-executed capabilities using combined regex extraction, code AST analysis, and LLM reasoning.
- A scalable combinatorial risk detection method that employs risk fingerprint tagging and risk link policies to reduce exploration from exponential to linear complexity while simulating multi-skill attack chains.
- Multi-agent orchestration design allowing parallel, dynamic scheduling of specialized auditor agents with serial, concurrent, and batch execution modes for tradeoffs between speed and depth.
Datasets
- ClawHub Agent Skills — 2,500 skills — Public marketplace dataset (skillhub.holosai.io)
Baselines vs proposed
- Skill Vetter baseline (admission filtering): rejected ~global BLOCK if any gate blocks vs SkillProbe Phase 1 for admission filtering.
- Atomic-level skill audits in prior works detected 26.1% vulnerability rate but missed emergent multi-skill chain attacks that SkillProbe Flow Simulator detected.
- Cross-model audit verdict consistency: Sonnet-4.6 conditional rate 45% vs average 19.4% among 8 models; GPT-5.2-Codex allowed more approvals (95%) with more remediation recs per skill (2.3).
- Runtime across models ranges from 18.5s (Gemini Flash) to 282s (Nex-N1.1) per skill audit with tradeoff between stringency and latency.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.21019.
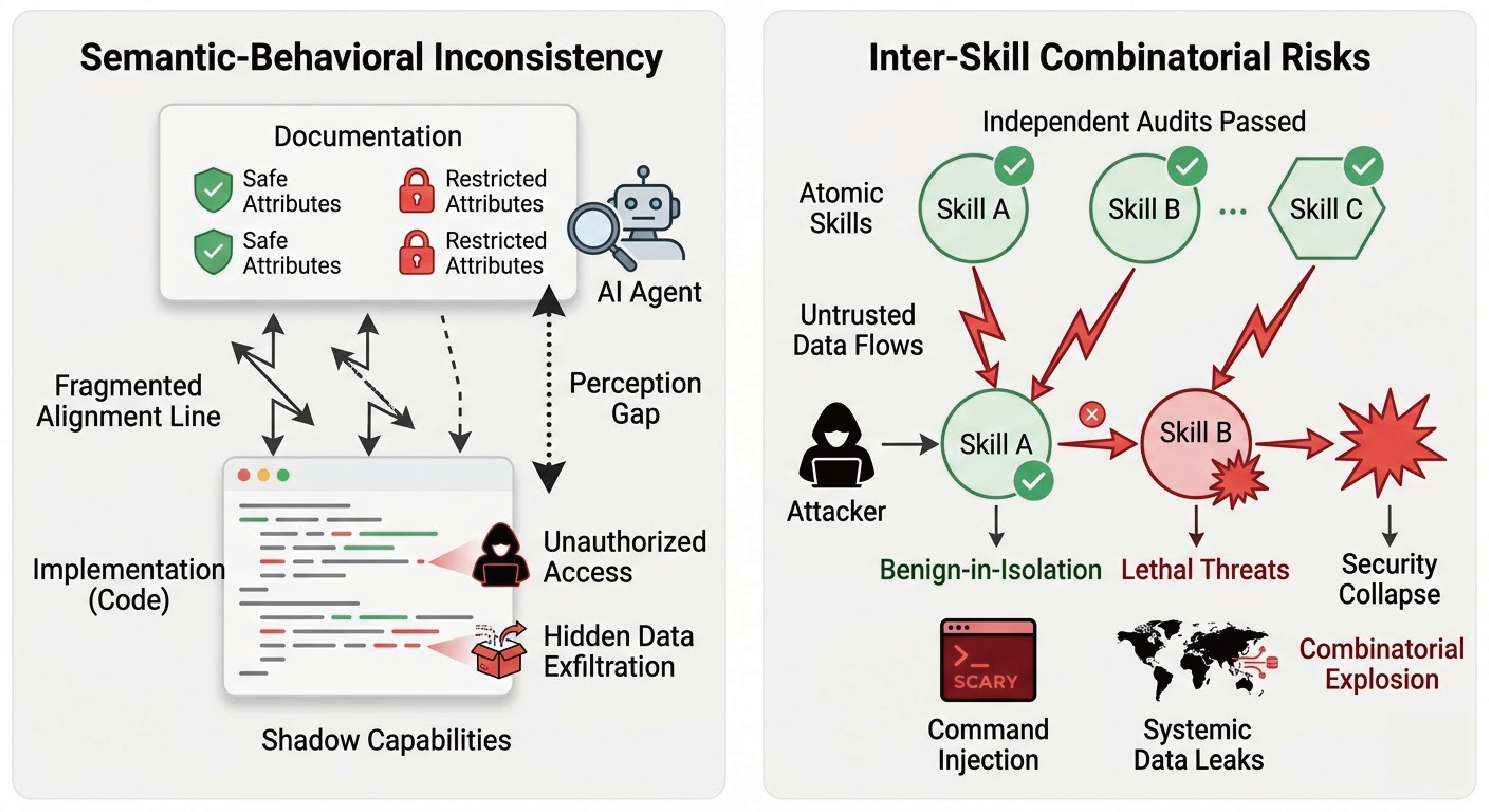
Fig 1: Visualizing invisible risks. Left panel depicts the semantic misalignment between high-
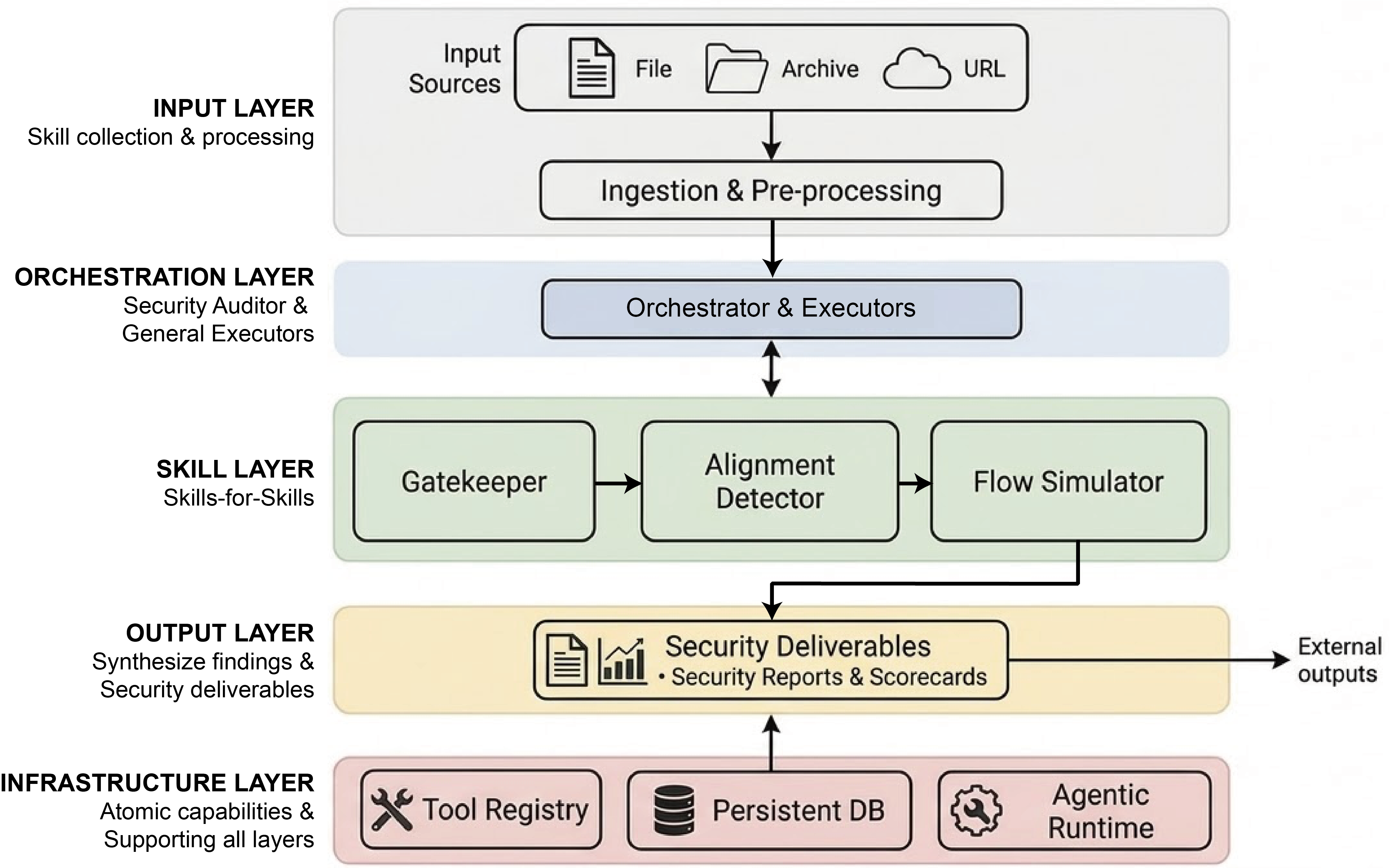
Fig 2: The overall system architecture of SkillProbe. The framework consists of five primary
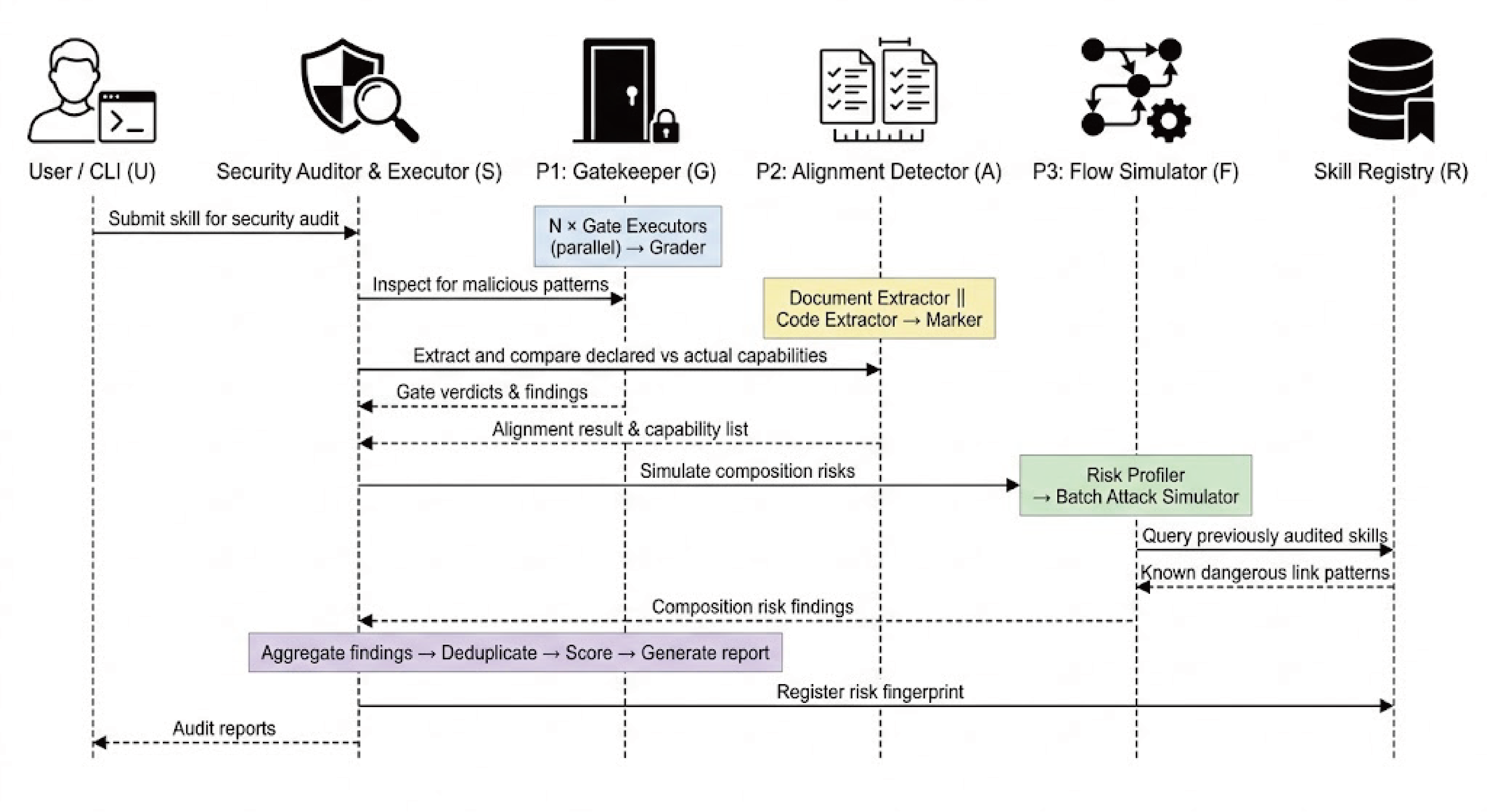
Fig 3: The overall workflow of the SkillProbe security auditing framework. The process com-
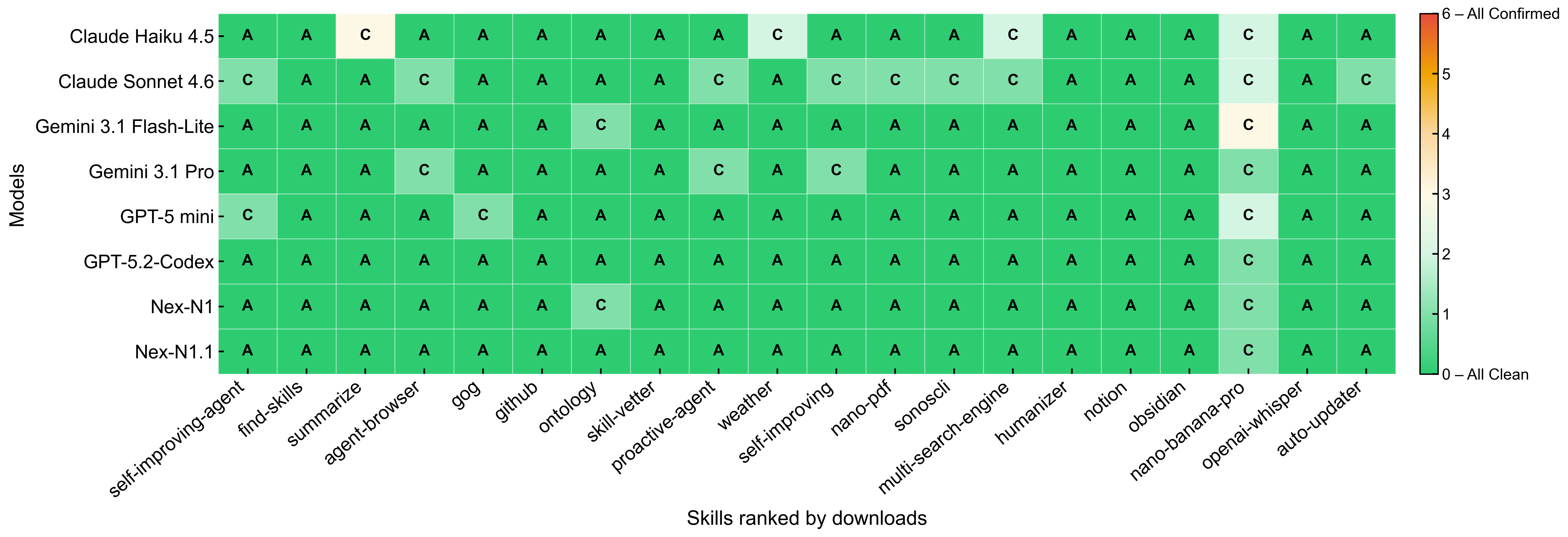
Fig 4: Cross-model audit consistency heatmap for ClawHub top 20 Skills. Each cell represents
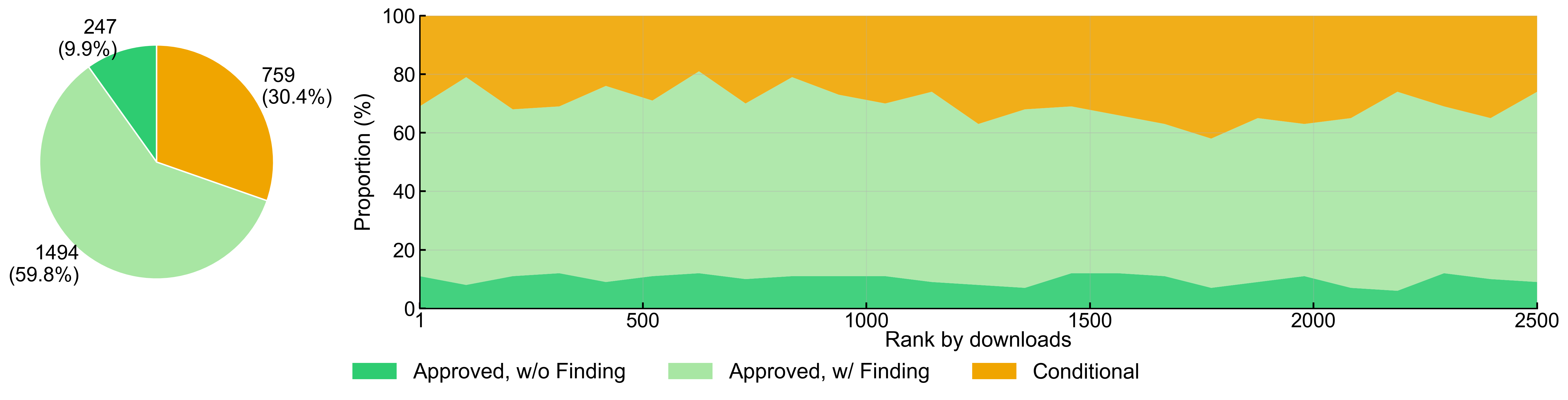
Fig 5: Security audit overview of the top 2500 most-downloaded skills on ClawHub. Left panel
Fig 6: Risk chain network of the 499 skills with at least one confirmed exploit from the nine official
Limitations
- No explicit adversarial testing against adaptive attackers attempting to evade SkillProbe's multi-agent auditing process or semantic querying.
- Evaluation focuses on top downloaded skills, potentially biasing against rarer or newly published skills with unknown security profiles.
- Discrepancies in audit verdicts across models reveal subjectivity in semantic-behavioral consistency thresholds.
- Lack of detailed statistical significance analysis or confidence intervals for detection metrics.
- The combinatorial analysis is constrained by predefined risk link policies; novel or unknown attack vectors may evade detection.
- System relies on LLMs' reasoning and code analysis abilities which can be brittle depending on skill complexity and LLM training data.
Open questions / follow-ons
- How robust is SkillProbe against adaptive adversaries who deliberately craft evasive semantic-behavioral inconsistencies informed by auditing logic?
- Can dynamic, runtime monitoring be integrated with SkillProbe’s static multi-agent auditing to provide end-to-end security guarantees?
- How does SkillProbe perform on non-English or domain-specific skills with ambiguous natural language documentation?
- What automated methods can create or update risk link policies to cover emerging attack vectors or ecosystem shifts?
Why it matters for bot defense
SkillProbe’s approach of multi-agent, modular auditing using the 'Skills-for-Skills' paradigm and semantic-behavioral consistency checking provides a novel framework for detecting covert and emergent risks in complex agent ecosystems. Bot-defense and CAPTCHA engineers can draw parallels in defending marketplaces of automated agents or plugins where semantic interfaces misalign with behaviors.
The combinatorial risk simulation and risk fingerprint tagging suggest promising directions for scalable analysis of chained components, which can inspire improved validation and vetting pipelines for multi-step attack chains or behavioral discrepancies in automation tools that mimic human interactive behavior. Overall, SkillProbe highlights the importance of integrating semantic-level audits with dynamic interaction modeling to raise security assurance in agent marketplaces.
Cite
@article{arxiv2603_21019,
title={ SkillProbe: Security Auditing for Emerging Agent Skill Marketplaces via Multi-Agent Collaboration },
author={ Zihan Guo and Zhiyu Chen and Xiaohang Nie and Jianghao Lin and Yuanjian Zhou and Weinan Zhang },
journal={arXiv preprint arXiv:2603.21019},
year={ 2026 },
url={https://arxiv.org/abs/2603.21019}
}