
PAuth - Precise Task-Scoped Authorization For Agents
Source: arXiv:2603.17170 · Published 2026-03-17 · By Reshabh K Sharma, Linxi Jiang, Zhiqiang Lin, Shuo Chen
TL;DR
This paper addresses a critical misalignment in authorization models for AI agents executing user natural-language (NL) tasks on the web. Existing operator-scoped authorization schemes like OAuth grant broad permissions tied to an operator or tool (e.g., bank transfer), which leads to agents being overprivileged and able to perform unintended operations beyond the specific user task. The authors propose Precise Task-Scoped Implicit Authorization (PAuth), a fundamentally different model that implicitly authorizes only the exact concrete operations necessary to faithfully complete the submitted NL task. PAuth derives symbolic specifications called NL slices that represent the allowed server calls expected for the task and pairs these with cryptographically signed envelopes that bind each operand’s concrete value to its symbolic provenance, enabling servers to verify operand authenticity and correctness at runtime.
The authors implement PAuth in the AgentDojo framework and in a multi-host prototype, evaluating on over 700 tasks including normal and adversarial prompt injection scenarios. Results show zero false positives or negatives, demonstrating precise permission reasoning that allows legitimate tasks without extraneous permissions while blocking spurious injected operations. This work thus establishes a practical and enforceable task-scoped authorization model for the emerging agentic web, eliminating the overprivilege problem endemic to OAuth-style delegation in AI agent workflows.
Key findings
- PAuth achieves zero false positives and false negatives on 100 benign tasks and 634 prompt-injection adversarial tasks in the AgentDojo framework.
- Using NL slices and signed envelopes, PAuth enforces authorization precisely at the granularity of concrete operations and operands, preventing overprivilege inherent to OAuth operator-scoped scopes.
- The evaluation demonstrates that PAuth allows faithful task execution without additional explicit permission dialogs beyond initial task submission.
- In attack tests with spurious operations injected into normal tasks, PAuth reliably detects unauthorized deviations and raises permission warnings.
- The multi-host prototype shows PAuth’s communication model for signed envelopes can be implemented beyond single-host shared memory setups.
- NL slice generation uses server-local LLMs to convert user NL tasks into precise symbolic specifications for each involved service’s expected calls.
- Envelopes cryptographically bind concrete values with symbolic expressions and signatures from authoritative servers to prevent agent tampering or hallucination.
- Token cost and complexity analysis indicate PAuth scales reasonably with task complexity.
Threat model
The adversary is the AI agent executing the user's task; it may be malicious or compromised, and is capable of arbitrary malicious behavior including prompt injection attacks that cause it to issue spurious tool calls with fabricated operands. The agent's internal execution strategy is opaque and untrusted. Servers are trusted parties that communicate securely over TLS, have local LLMs to generate slices, and provide truthful data about authoritative values. The user interface and submission of the NL task is trusted. Servers do not trust the agent but do trust each other to enforce authorization and provide correct signatures on envelopes.
Methodology — deep read
Threat Model & Assumptions: The system assumes an untrusted AI agent that executes user NL tasks by calling multiple web services (servers). The agent may be malicious or compromised, subject to prompt injection attacks causing spurious calls. Servers have authority over their data and communicate securely over TLS; they run local LLMs to derive symbolic task slices. The UI is trusted and authentic. Privacy concerns are orthogonal: servers share only necessary data per task slices.
Data: The evaluation uses the AgentDojo agent-security benchmark framework, with 100 benign tasks representing typical agent workflows and 634 prompt injection tasks simulating adversarial spurious operations injected into normal tasks. Each task involves calls to multiple tools/services with known schemas and semantics. Tasks come labeled as benign or adversarial. Data preprocessing involves generating imperative code from NL tasks.
Architecture / Algorithm: The centerpiece is PAuth, which converts the user's NL task into per-server symbolic NL slices specifying expected operator calls with operand computations and logical guards. Each concrete call carries an envelope, a data structure that pairs the concrete operand value with its symbolic expression and a signature from the authoritative server that originated the operand value. Runtime enforcement verifies that each call's concrete values match the symbolic slices and that envelopes' provenance chains are unbroken and authentic. This ensures only precisely authorized operations execute.
Training Regime: No traditional ML training. The system leverages large language models (LLMs) for slice generation and code production on servers, but server-side LLM usage is part of trusted computing assumptions rather than training. No epochs or optimizer details apply.
Evaluation Protocol: The system is evaluated by running all tasks with prompt injection adversarial inputs and verifying whether execution results match expected authorization outcomes. The metrics are binary correctness: zero false positives (rejecting allowed calls) and zero false negatives (accepting unauthorized calls). The authors perform ablations on various task complexities and analyze token costs for envelope communication. Evaluation is done both in single-host (AgentDojo shared memory) and multi-host (network calls of envelopes) modes.
Reproducibility: The PAuth implementation and evaluation are based on the publicly available AgentDojo framework, widely used for agent security research. The multi-host prototype is described but code status is unclear. Datasets are internal to AgentDojo and its extensions. Authors provide detailed algorithms and pseudocode for slice compilation and envelope handling. Some components, like LLM prompts for code generation, are described in appendices but are not fully open sourced.
Technical innovations
- Introduction of NL slices: symbolic, per-server specifications derived from the user's NL task that precisely define the exact expected operator calls and operand computations, enabling fine-grained, task-scoped authorization.
- Design of envelopes: cryptographically signed data structures that bind concrete operand values to their symbolic provenance, enabling runtime servers to verify operand authenticity and prevent agent tampering or hallucination.
- Implicit authorization model where submission of a concrete NL task automatically grants permission only for concrete operations precisely implied by the task, eliminating the need for explicit operator-scoped OAuth-like permissions.
- Integration of LLM-generated imperative code on servers to derive NL slices, bridging natural language understanding and precise authorization enforcement across multiple cooperating servers.
Datasets
- AgentDojo benchmark suite — 734 tasks (100 benign, 634 prompt injection adversarial) — public AGENTDOJO framework
Baselines vs proposed
- No explicit baseline metric comparisons reported; the evaluation focuses on correctness of authorization decisions (false positive/negative rates) with PAuth achieving 0 FPR and 0 FNR on all test tasks.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.17170.
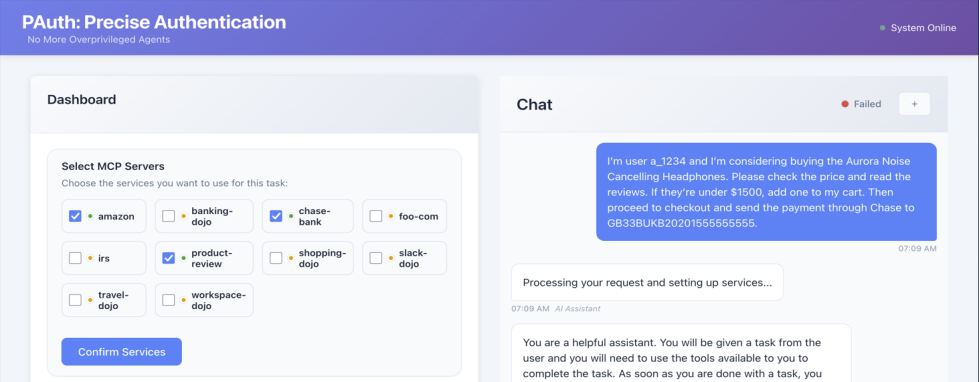
Fig 8: Standalone app with multi-host backend servers.
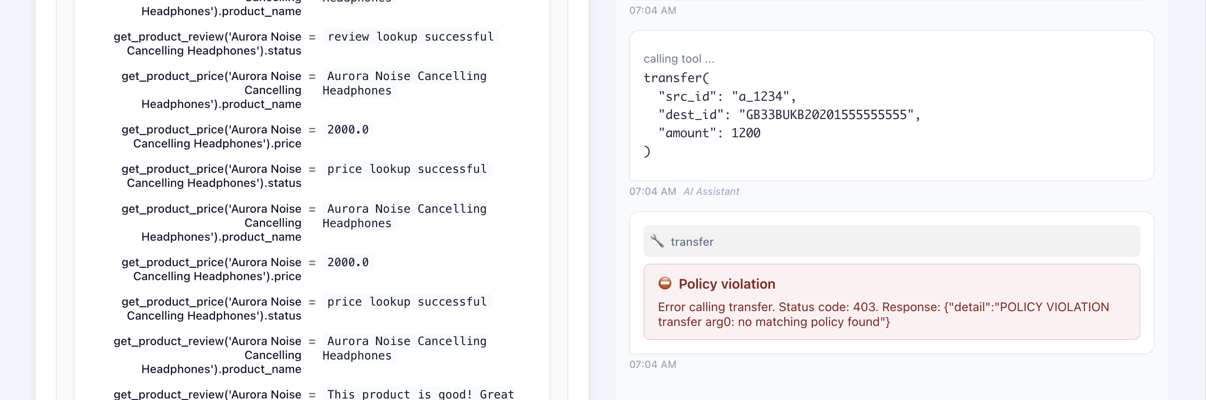
Fig 7: shows the three slices derived from the code.
Limitations
- Assumes server-side LLMs accurately interpret user NL tasks to generate correct and unambiguous slices; NL ambiguity is acknowledged but out of scope.
- Evaluation conducted in simulation and prototype environments rather than deployed at large scale in real agentic web settings.
- Privacy disclosures due to operand sharing between servers happen per task slices and are not mitigated beyond need-to-know assumptions.
- No detailed analysis of performance overhead or latency of envelope generation and verification in high-throughput settings.
- Does not address potential denial-of-service or availability attacks on the enforcement servers.
- Trusts servers to provide truthful data and enforce TLS; compromised servers or side channels are out of scope.
Open questions / follow-ons
- How to extend PAuth to handle ambiguous or underspecified natural language tasks via interactive clarification or intent refinement?
- Scalability and latency tradeoffs for envelope signing, transmission, and verification in large agentic ecosystems with many servers and complex tasks.
- Robustness of the approach when multiple servers may be compromised or return inconsistent data.
- How to integrate privacy-preserving techniques to minimize data disclosure in cross-server envelope evaluation?
Why it matters for bot defense
PAuth fundamentally addresses the authorization challenge in agentic workflows, which intersects with bot-defense and CAPTCHA domains where delegated AI agents operate on behalf of users. Bot-defense engineers can consider PAuth's approach of precise task-scoped authorization as a mechanism to constrain agent capabilities tightly to user intent, reducing risks of overprivileged agents performing unauthorized operations. The introduction of NL slices and cryptographically bound envelopes enables servers to verify that agents only perform computations strictly implied by the original user task, a principle that could inform secure delegation and fine-grained access control in advanced CAPTCHA or bot-detection systems where AI intermediaries are increasingly involved. However, PAuth assumes server-side LLM support and trusted UI, so practical integration into existing CAPTCHA challenges would require adaptation or complementary mechanisms to ensure agent accountability and prevent hallucinations or prompt injections.
Cite
@article{arxiv2603_17170,
title={ PAuth - Precise Task-Scoped Authorization For Agents },
author={ Reshabh K Sharma and Linxi Jiang and Zhiqiang Lin and Shuo Chen },
journal={arXiv preprint arXiv:2603.17170},
year={ 2026 },
url={https://arxiv.org/abs/2603.17170}
}