
Lean Atlas: An Integrated Proof Environment for Scalable Human-AI Collaborative Formalization
Source: arXiv:2604.16347 · Published 2026-03-16 · By Banri Yanahama, Akiyoshi Sannai
TL;DR
This paper addresses a key limitation in AI-driven autoformalization of mathematics: while proof assistants ensure logical correctness of proofs via type checking, they do not guarantee that the formalized propositions and definitions faithfully represent the intended mathematical meaning. This mismatch is termed semantic hallucination, where AI-generated formal proofs pass type checking but semantically diverge from the original mathematical statements. The authors propose a human-in-the-loop approach where humans verify the semantic correctness of propositions and definitions, assisted by tooling to reduce the verification workload.
To realize this, they develop Lean Atlas, a Lean 4-based integrated proof environment that extracts and classifies the dependency graph of Lean projects into type (proposition/definition-level) and value (proof-level) dependencies, and presents this graph through an interactive web viewer. The key innovation, Lean Compass, is an algorithm to automatically extract the subset of project nodes affecting the semantic correctness of a chosen theorem set by pruning proof-level dependencies from theorems, thereby shrinking the verification set dramatically. The authors define "aligned Lean code" as code semantically verified by humans, establishing a quality baseline for AI-generated formalizations.
Evaluations on six Lean 4 formalization projects, including mathematical, physics, and cryptographic domains, demonstrate that Lean Compass achieves node reduction rates of 94-99% in proof-heavy projects (e.g. PrimeNumberTheoremAnd, Carleson, Brownian Motion), moderate reductions (59.8-69%) in mixed-structure projects (e.g. FLT, PhysLib), and lower reductions (27.3%) in definition-heavy projects (e.g. XMSS). This validates the tool's scalability and domain-agnostic applicability. The implementation is open-source.
Key findings
- Semantic hallucination is caused by the type checker verifying only logical correctness, not semantic equivalence of propositions and definitions.
- Lean Atlas classifies dependencies into 8 types by source kind (theorem/definition), dependency site (type/value), and target kind, enabling fine-grained analysis.
- The Lean Compass algorithm prunes value dependencies from theorem proofs (edges #3 and #4 in Table 1), which are guaranteed correct by the type checker, reducing review scope.
- Proof-heavy projects like PrimeNumberTheoremAnd achieve 99.1–99.7% node reduction; Carleson achieves 88.1–99.7% (average 96.2%); Brownian Motion achieves 89.1–99.0% (average 94.4%).
- Projects with mixed or definition-heavy structures see lower reductions: FLT milestone subset achieves 59.8%; PhysLib 69.0%; XMSS Encoding Scheme 27.3%.
- The theorem-to-definition ratio inside a review cone predicts reduction rate better than project size or label.
- Lean Compass soundness guarantees that if all extracted nodes are semantically correct, the target theorems are semantically aligned with intended statements.
- Interactive web viewer supports navigation of large dependency graphs with filtering and semantic confidence metadata for human review coordination.
Threat model
The adversary is an AI autoformalizer or theorem prover that generates formal proofs passing the Lean 4 type checker but producing propositions and definitions that semantically diverge from the intended mathematical statements (semantic hallucination). The adversary can manipulate types and proofs within the logic but cannot alter the trusted base libraries (Lean standard library and Mathlib). The human-in-the-loop workflow assumes humans verify semantic correctness only on a reduced subset of project nodes identified by Lean Compass; nodes pruned are assumed correct by type checking and hence safe to exclude from semantic review.
Methodology — deep read
The threat model assumes an adversary is an AI autoformalizer generating mathematically incorrect but type-check correct formalizations (semantic hallucinations). Humans and AI collaborate, with humans verifying semantic correctness of propositions and definitions.
Data consists of six diverse Lean 4 formalization projects of varying size and domain: mathematics (PrimeNumberTheoremAnd, Carleson, Brownian Motion, FLT), theoretical physics (PhysLib), and cryptography (XMSS Encoding Scheme). Key theorems and their dependency graphs are extracted using the Lean 4 backend tool integrated with the Lake build system. The dataset comprises project-specific nodes only, excluding the trusted base of Lean standard library and Mathlib.
The architecture consists of two parts: a Lean 4 backend that enumerates all constants, classifies them as theorem, definition, inductive, structure, abbreviation, or axiom, and constructs a directed dependency graph where edges are classified into 8 kinds combining source kind, dependency site, and target kind. The frontend is an interactive web viewer implemented with Next.js and React Flow that visualizes the hierarchical dependency graph and allows filtering by node and edge metadata.
The core algorithm Lean Compass takes as input a selected target theorem set and the full dependency graph. It prunes edges that are value dependencies from theorem proofs (edges types #3 and #4), since these are guaranteed correct by the type checker and cannot affect semantics. It performs breadth-first search from the target theorems on this pruned graph, including all reachable nodes plus axioms, to obtain the minimal subset requiring human semantic review.
Training is not applicable; the system is deterministic. Evaluation involves measuring node reduction rates (percentage decrease in dependency nodes requiring review) across main theorems in each project. No human experiments or timing studies were performed. Node counts before and after Compass pruning are reported.
The evaluation protocol counts project-specific dependency nodes in each theorem's review cone pre- and post-pruning. Reduction rate = 1 - (nodes after pruning / nodes before). Results are aggregated per project and shown per theorem. The authors argue soundness of the pruning method ensures that verifying extracted nodes suffices for semantic correctness.
The implementation and data are open-source at https://github.com/NyxFoundation/lean-atlas. Although details on hardware or seeds are not applicable, the system integrates with standard Lean 4 tooling and Mathlib. The methodology is fully described with algorithm pseudocode and example dependency graphs (e.g. Fig 3). The paper notes current limitations such as manual metadata annotation and lack of timing evaluation.
Technical innovations
- Definition of semantic hallucination in AI-generated formal proofs as passing type checking but failing semantic equivalence with intended mathematics.
- Lean Atlas tool that extracts and classifies Lean 4 project dependency graphs into an 8-kind edge taxonomy combining source node kind, dependency site, and target kind for detailed dependency analysis.
- Lean Compass algorithm that prunes value dependencies from theorem proofs to extract a project-specific minimal subgraph of nodes affecting semantic correctness for target theorems, supporting scalable human verification.
- Introduction of the concept of aligned Lean code: formalization code semantically validated by human verification in addition to type checking, as a quality standard for AI-generated formalizations.
Datasets
- PrimeNumberTheoremAnd — medium size (hundreds to thousands of nodes) — public GitHub repository
- Carleson — large scale (up to ~2000 nodes per theorem review cone) — public GitHub
- Brownian Motion — mid-size mathematical formalization — public/arXiv linked
- FLT (Fermat's Last Theorem) milestone subset — small subset (6 theorems selected) — public GitHub
- PhysLib — theoretical physics formalization (varied complexity) — public/arXiv linked
- XMSS Encoding Scheme — cryptographic formalization, definition-heavy — implemented by authors
Baselines vs proposed
- No direct baseline methods quantitatively compared; evaluation focuses on node reduction before and after Lean Compass pruning on the same dependency graphs.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.16347.
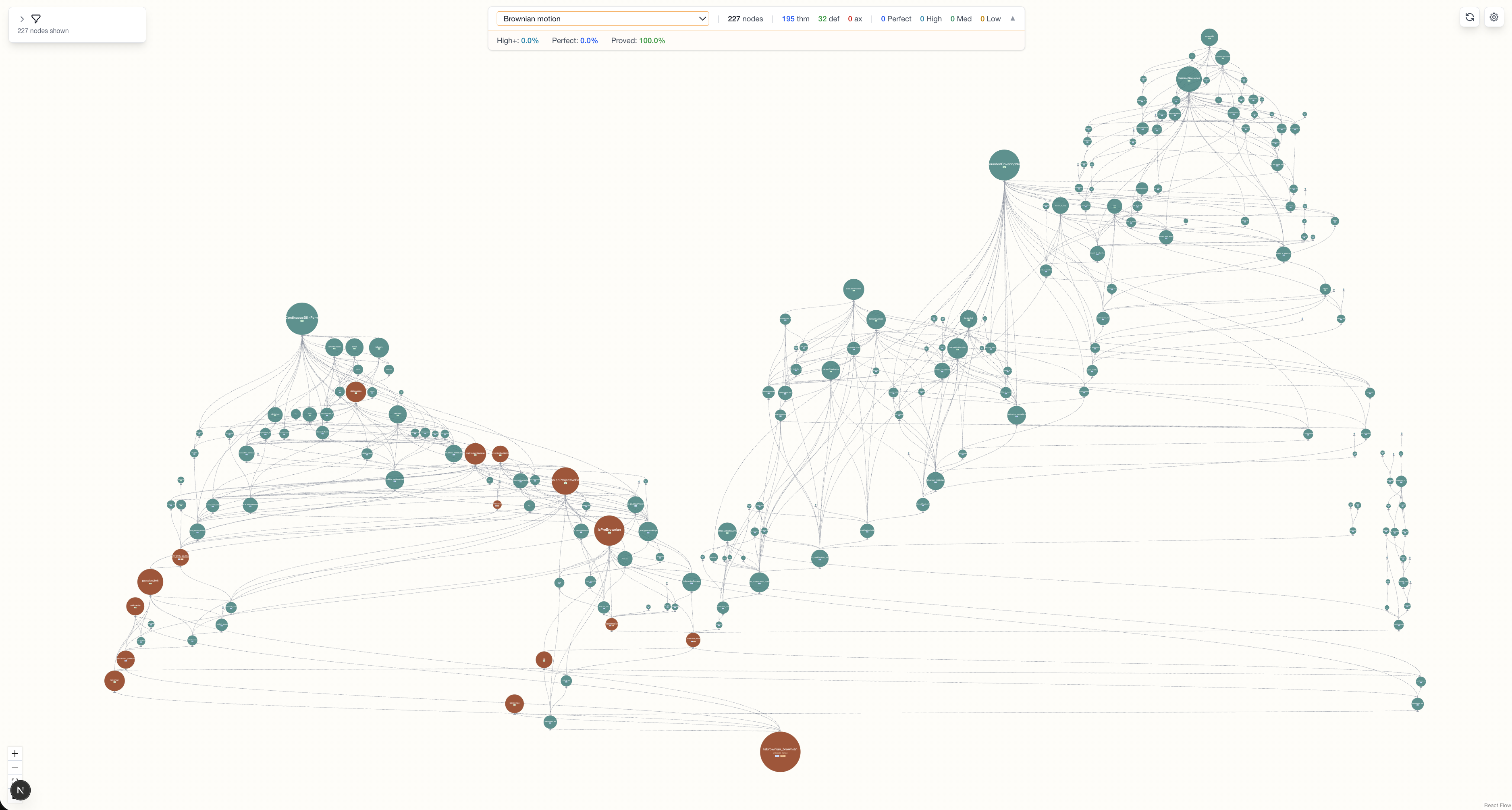
Fig 1: Lean Atlas web viewer.
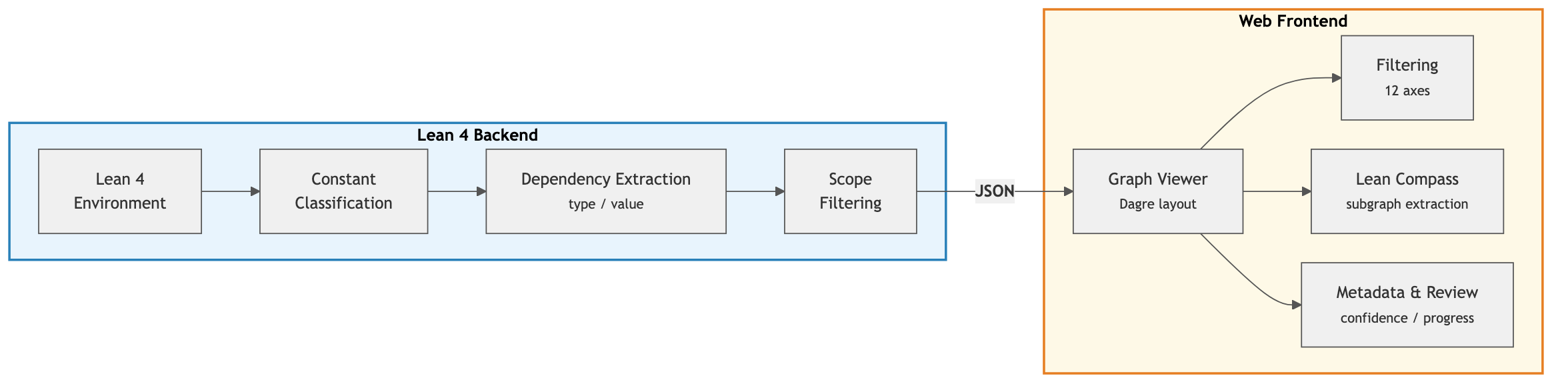
Fig 2: Architecture of Lean Atlas. The Lean 4 backend extracts and classifies the dependency
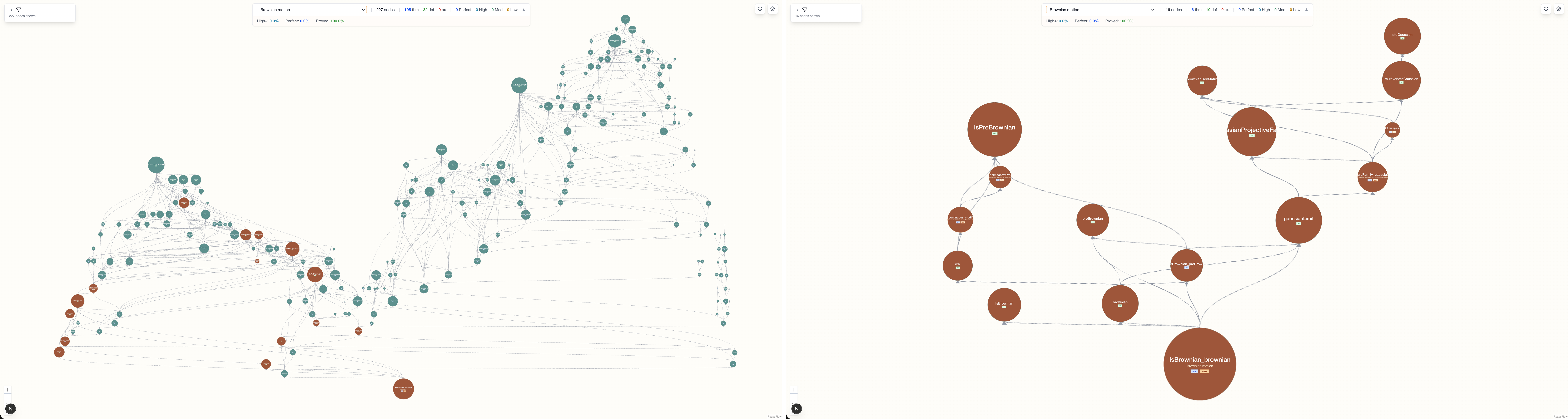
Fig 3: Dependency graph reduction by Lean Compass (Brownian Motion, main theorem
Limitations
- Only node reduction rates are evaluated as a proxy for semantic review effort; no human verification time or cognitive load studies conducted.
- Effectiveness depends on the chosen main theorem set capturing the complete mathematical claims of the project; incomplete sets limit coverage guarantees.
- Semantic confidence metadata currently requires manual annotation, limiting scalability to large projects and teams.
- Lean Compass pruning does not verify semantic correctness of pruned nodes; separate review needed to confirm their correctness if desired.
- Evaluation limited to Lean 4 projects; generalization beyond Lean or other proof assistants is implied but not empirically verified.
- No adversarial evaluation against deliberately misleading AI formalizations or distribution shift scenarios.
Open questions / follow-ons
- How much does the node reduction correlate with actual human verification time savings in practical formalization workflows?
- Can AI-generated semantic confidence metadata be integrated fully automatically to prioritize verification efforts?
- How does Lean Compass perform under adversarial scenarios or semantic hallucinations crafted to evade pruning?
- What are the prospects for extending Lean Atlas and Compass methods to other proof assistants beyond Lean 4?
Why it matters for bot defense
While not directly related to bot defense or CAPTCHA, the paper’s approach to separating logically guaranteed correctness from semantic alignment under human verification highlights challenges in trust and validation of AI-generated artifacts. For bot-defense engineers, the human-in-the-loop semantic verification and dependency pruning mechanisms could inspire analogous methods to reduce human burden in verifying AI-driven authentication or verification modules. Techniques like graph-based dependency analysis to narrow verification scope are potentially transferable concepts. Additionally, the explicit framing of semantic hallucination as a form of subtle AI failure provides a useful conceptual lens for reasoning about correctness vs. apparent validity in automated systems.
Cite
@article{arxiv2604_16347,
title={ Lean Atlas: An Integrated Proof Environment for Scalable Human-AI Collaborative Formalization },
author={ Banri Yanahama and Akiyoshi Sannai },
journal={arXiv preprint arXiv:2604.16347},
year={ 2026 },
url={https://arxiv.org/abs/2604.16347}
}