
Deep Learning for Virtual Reality User Identification: A Benchmark
Source: arXiv:2604.16341 · Published 2026-03-14 · By Davide Frizzo, Fabrizio Genilotti, David Petrovic, Arianna Stropeni, Francesco Borsatti, Davide Dalle Pezze et al.
TL;DR
This work addresses the critical problem of robust user identification within Virtual Reality (VR) environments using behavioral biometrics derived from motion tracking data. Prior research has shown the potential of VR motion data as a discriminative modality, but modern deep learning architectures, especially structured state space models (SSMs), have not been systematically evaluated in this context. The authors benchmarked multiple sequence modeling architectures—including conventional recurrent (LSTM, GRU), convolutional (CNN, TCN), attention-based (Transformer), and novel SSM variants (S4D, S5)—on the 'Who is Alyx' dataset, which contains long-duration motion capture from 71 users playing the VR game Half-Life: Alyx.
Their results demonstrate that end-to-end deep learning approaches outperform traditional feature-based MLPs, with CNN, TCN, and the S4D state space model achieving the highest identification accuracy as measured by mean reciprocal rank (MRR). The BRA (body-relative acceleration) encoding of the raw motion data yielded the best performance compared to position or velocity encodings. Notably, the Transformer model underperformed, likely due to limited dataset size and lack of large-scale pretraining. Evaluation also considered computational complexity and memory requirements, showing that the TCN and S4D models provide the best trade-offs for deployment on resource-constrained VR hardware. This study establishes a rigorous benchmark of modern sequence models for VR user identification and highlights promising architectures for practical authentication systems in safety-critical VR applications.
Key findings
- The BRA (body-relative acceleration) temporal encoding provides better identification accuracy than BRV (velocity) and BR (position), especially in low-data regimes, with performance converging for long sequences (>10 minutes).
- CNN, TCN, and S4D models achieve the highest MRR scores on the Who is Alyx dataset, outperforming LSTM, GRU, Transformer, and MLP baselines (Fig 2).
- Transformer architecture performs significantly worse than other deep models on this dataset, possibly due to quadratic attention cost and lack of large-scale pretraining.
- MLP trained on handcrafted statistical features performs better than LSTM but worse than CNN, TCN, and SSM models, indicating the advantage of end-to-end deep learning on raw sequences.
- S4D requires 2.67 million parameters and 0.895 GFLOPs, achieving comparable accuracy to CNN (4.0M parameters, 0.589 GFLOPs) and TCN (1.4M parameters, 0.839 GFLOPs) but with lower memory footprint and competitive computation cost (Table I and Fig 1).
- Models trained on session 1 and tested on session 2 show the ability to generalize across sessions with differing tasks and days, though cross-session accuracy is lower than within-session.
- Downsampling to 15 Hz and segmenting sequences into 20-second windows with 50% overlap during training and non-overlapping evaluation provide effective input preprocessing.
- Majority voting over longer test sequences improves classification stability and increases MRR across all models, illustrating the benefit of aggregating predictions.
Threat model
The adversary aims to circumvent VR user identification by mimicking legitimate users' behavioral motion patterns captured by headset and controllers. They do not have direct access to model internals or raw biometric templates but may attempt impersonation through recorded or simulated movement behavior. Attacks involving physical device tampering, sensor spoofing, or injection are outside this scope.
Methodology — deep read
The threat model assumes an adversary attempting to impersonate VR users through behavioral biometrics captured by head-mounted displays and controllers. The attacker does not have access to raw biometric data or model internals but may attempt to mimic user movement patterns.
Data: The benchmark uses the publicly available 'Who is Alyx' dataset comprising 71 users playing Half-Life: Alyx on HTC Vive Pro. Each user has about 90 minutes of motion recordings across two sessions on different days and game chapters to assess cross-session generalization. The dataset includes 18 features per frame—positions and orientations for the HMD and two controllers—sampled at 15 Hz after downsampling from the original 90 Hz, excluding noisy first and last minutes.
Data is encoded using three schemes: Body Relative (BR) positions/orientations, Body Relative Velocity (BRV) as first derivatives, and Body Relative Acceleration (BRA) as second derivatives.
Sequences are windowed into fixed-length 20-second segments (300 frames) with 50% overlap for training, and non-overlapping for testing, where majority voting aggregates predictions to a session-level user ID.
Architecture: The authors benchmark nine models: MLP on handcrafted stats features, CNN, Temporal Convolutional Network (TCN), Long Short-Term Memory (LSTM), Gated Recurrent Unit (GRU), Transformer with self-attention, and three State Space Models—S4D (diagonal SSM), and S5 (simplified MIMO SSM). SSMs model long-term dependencies via linear dynamical systems with recurrent and convolutional duality, enabling efficient training via FFT.
Training used the Adam optimizer with Early Stopping (patience=5). The best model checkpoint was selected based on mean accuracy on the validation set (last 5 minutes of training session). Models were trained on session 1 and evaluated on session 2 to measure cross-session robustness.
Evaluation Metrics included Mean Reciprocal Rank (MRR) to gauge ranking quality of user ID predictions and floating point operations (FLOPs) and parameter counts to assess computational complexity and memory for deployment feasibility on VR hardware.
One end-to-end example: For a 20-second window, raw position and orientation data are converted to body-relative acceleration (BRA), downsampled to 15 Hz, and input as an 18-feature multivariate time series to the S4D model. The model output is a probability distribution over the 71 users. During inference, predictions for multiple non-overlapping windows are averaged by majority voting to produce the final predicted user ID for the session.
Reproducibility: The dataset is publicly available as 'Who is Alyx'. The paper does not state explicit code release or pretrained weights availability. Some preprocessing steps and model hyperparameters are described in detail.
Technical innovations
- First systematic benchmark of modern State Space Models (S4D and S5) against established deep architectures for VR behavioral biometric user identification.
- Application and evaluation of temporal derivative encodings (acceleration BRA, velocity BRV) on raw VR motion data enhancing discriminability over raw positional data.
- Comprehensive accuracy-efficiency trade-off analysis highlighting S4D and TCN as optimal models balancing identification performance and resource constraints in VR hardware deployment.
- Use of majority voting over long test sequences to improve classification stability in behavioral biometric identification within VR.
Datasets
- Who is Alyx VR dataset — 71 users with ~90 minutes total per user across 2 sessions — Publicly available dataset containing HTC Vive Pro tracking data during Half-Life: Alyx gameplay
Baselines vs proposed
- MLP (handcrafted features): MRR ~below S4D/TCN but better than LSTM; Params = 0.89M vs S4D = 2.67M
- CNN: highest MRR, Params = 4.0M, FLOPs = 0.59, vs S4D Params = 2.67M, FLOPs = 0.895 (similar accuracy, lower memory for S4D)
- TCN: competitive MRR with CNN, Params = 1.4M vs S4D 2.67M, FLOPs 0.84 vs 0.89
- LSTM: lower accuracy compared to CNN, TCN, and S4D; Params = 4.6M, FLOPs = 2.7 (higher compute requirements)
- Transformer: worst MRR performance despite low Params (1.3M) and FLOPs (0.88), likely data size and quadratic complexity limitation
- S4D outperforms GRU and LSTM while requiring fewer parameters and less floating point operations compared to LSTM (2.67M vs 4.6M parameters)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2604.16341.
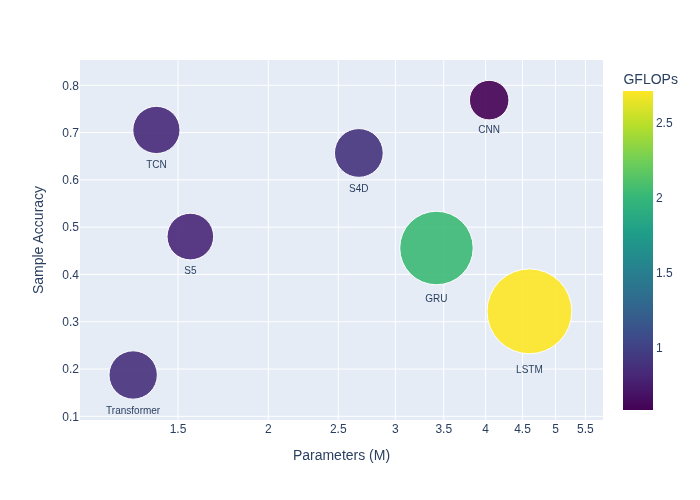
Fig 1: Performance and efficiency trade-offs: comparison
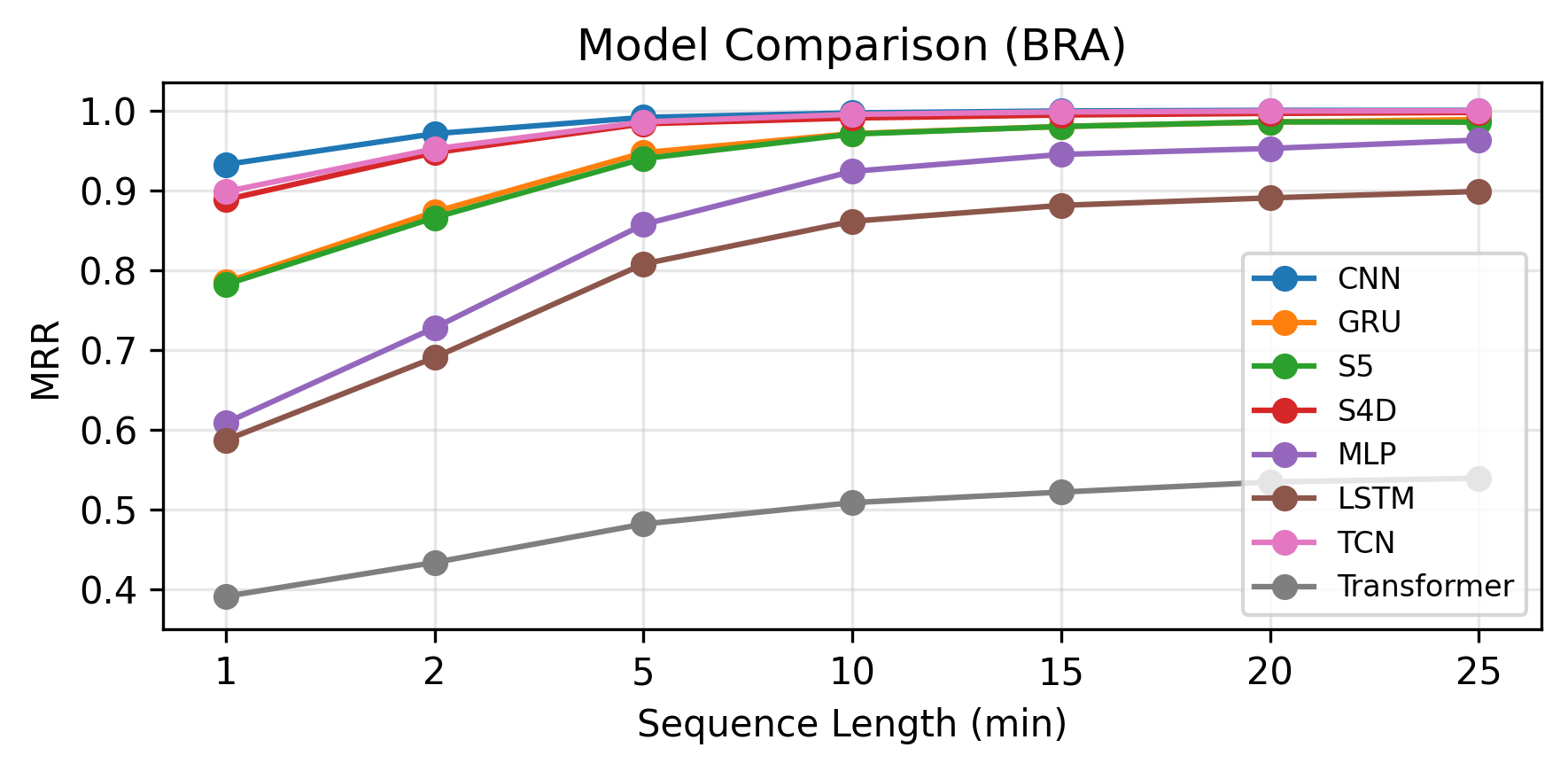
Fig 2: Test sample size vs. Mean Reciprocal Rank (MRR) for the BRA, BRV and BR encodings
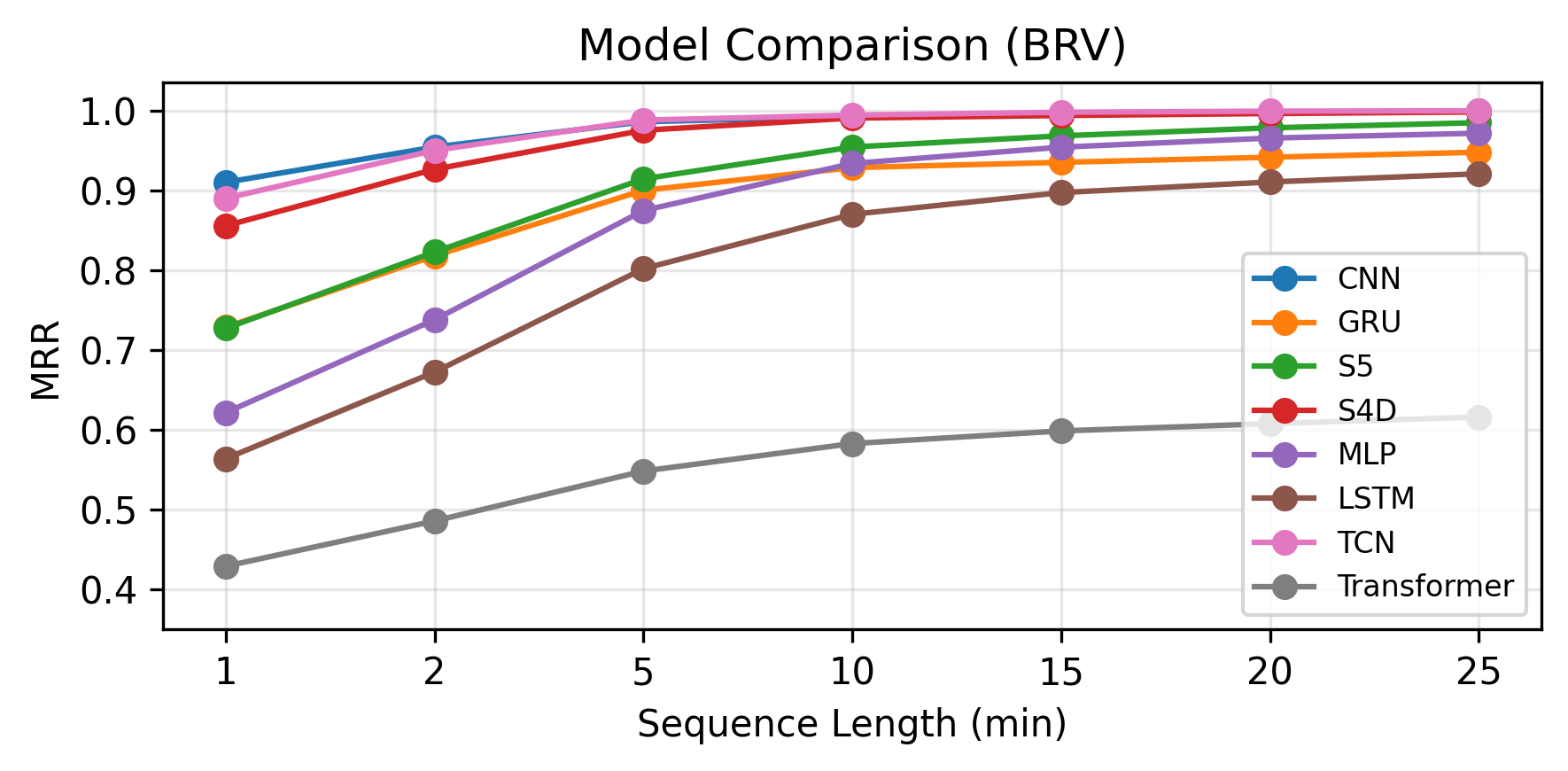
Fig 3: Test sample size vs. MRR
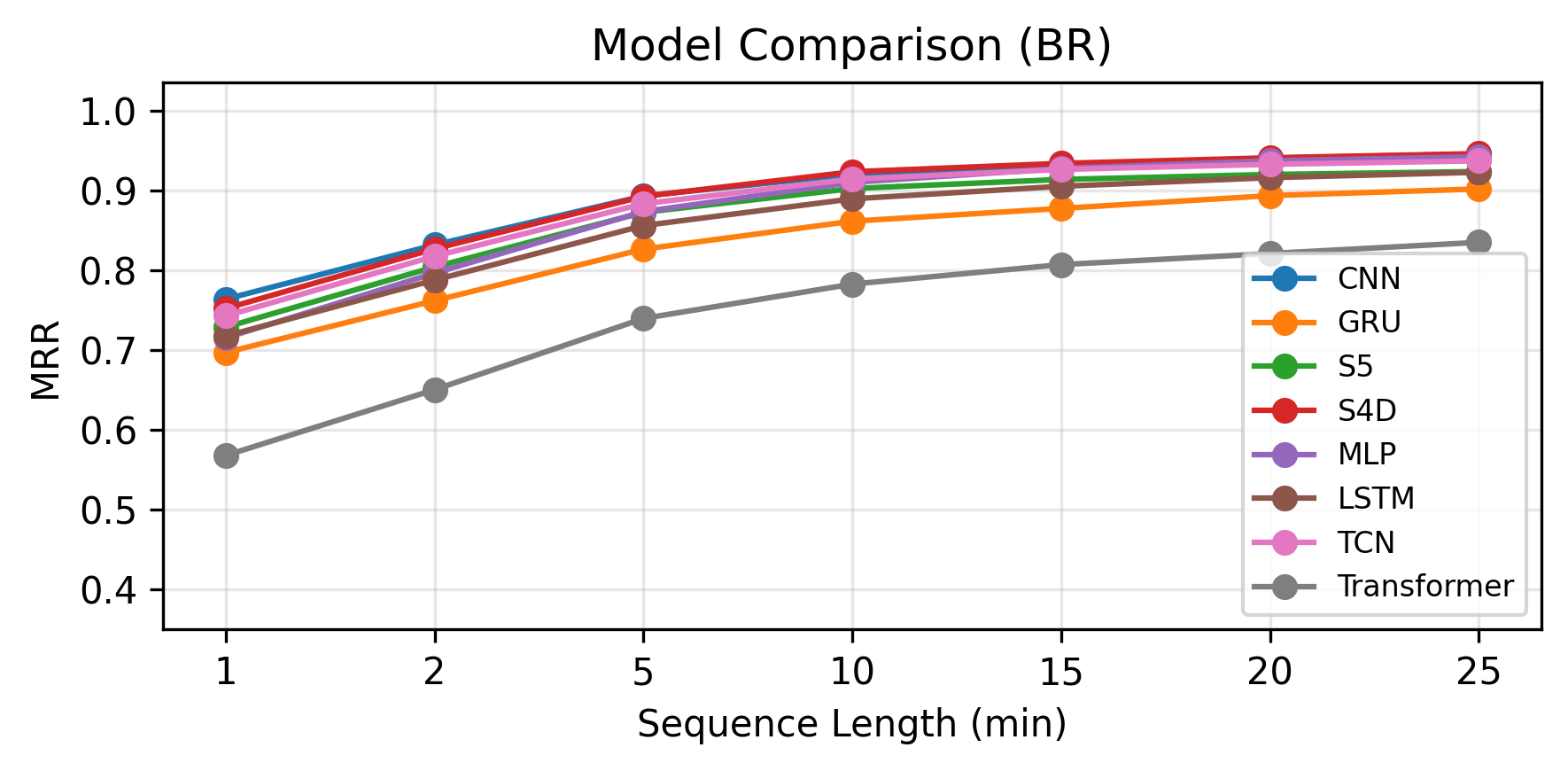
Fig 4 (page 5).
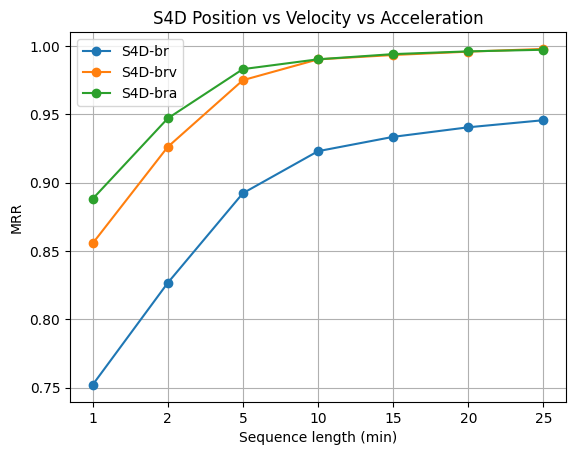
Fig 5 (page 5).
Limitations
- Cross-session evaluation only; no cross-application or cross-device generalization tested, limiting understanding of model robustness to domain shifts.
- Transformer underperformance may be dataset size related; lack of pretraining prevents full assessment of attention-based models.
- Limited discussion on adversarial robustness or resistance to intentional mimicry attacks on behavioral biometrics.
- No publicly released code or pretrained weights stated, limiting reproducibility and wider adoption.
- Long-term temporal stability beyond two sessions spaced by days remains unexamined; performance decay over months is unknown.
- Multimodal data (gaze, physiological signals) included in dataset but only motion data used; ignoring other modalities might miss identification cues.
Open questions / follow-ons
- How do state space models generalize to cross-application and cross-device VR user identification scenarios with varying hardware and software ecosystems?
- What is the long-term temporal stability of behavioral biometrics in VR beyond days, including effects of user learning, adaptation, or fatigue over weeks and months?
- Can multimodal fusion leveraging gaze and physiological signals improve robustness and accuracy of VR user identification beyond motion data alone?
- What model compression or quantization strategies best preserve accuracy of SSMs like S4D for deployment on constrained standalone VR devices?
Why it matters for bot defense
This study provides valuable insights for bot-defense and CAPTCHA practitioners interested in leveraging behavioral biometrics from VR interactions for user authentication. The benchmark establishes state-of-the-art model architectures and input encoding strategies specifically focused on modeling long, high-dimensional VR motion sequences, highlighting the trade-offs in accuracy, computational footprint, and memory usage relevant for deployment in constrained VR hardware environments. The finding that acceleration-based encodings (BRA) improve discriminability suggests the importance of careful feature representation when designing behavioral biometric systems.
Practitioners should note the limitations of attention-based models like Transformers on relatively small VR datasets without pretraining, favoring SSMs or convolutional approaches instead. Also, the clear drop in identification performance across sessions underlines the challenges of temporal variability affecting continuous authentication in VR. Overall, the presented benchmark and analyses help inform architecture selection and evaluation methodology for robust and privacy-preserving VR user identification systems that could augment or complement existing CAPTCHA and bot-detection mechanisms in mixed reality or metaverse platforms.
Cite
@article{arxiv2604_16341,
title={ Deep Learning for Virtual Reality User Identification: A Benchmark },
author={ Davide Frizzo and Fabrizio Genilotti and David Petrovic and Arianna Stropeni and Francesco Borsatti and Davide Dalle Pezze and Riccardo De Monte and Manuel Barusco and Gian Antonio Susto },
journal={arXiv preprint arXiv:2604.16341},
year={ 2026 },
url={https://arxiv.org/abs/2604.16341}
}