
Measuring onion website discovery and Tor users' interests with honeypots
Source: arXiv:2603.09329 · Published 2026-03-10 · By Arttu Paju, Waris Abdullah, Juha Nurmi
TL;DR
This paper asks a different question than most dark-web measurement work: not what content exists on onion services, but what users actually try to access and interact with. The authors deploy a set of honeypot onion websites that look like illicit forums, seed their URLs through three discovery channels (Ahmia, Stronghold paste, and pastebin.com), and then measure downstream behavior using CAPTCHA solves and dummy registration/login attempts as proxies for human engagement.
The main result is that human engagement overwhelmingly came from Ahmia, not paste sites: after the Ahmia links were removed, visits fell to near zero and no further registration/login attempts were observed. Within the honeypot categories, CSAM-themed pages drew the most engagement by a wide margin, with violence second; illegal drugs and forgery were the least engaging. When the same sites were offered in multiple languages, English attracted the most interaction, followed by German and Finnish, with Russian lowest. The paper’s core contribution is methodological: it uses controlled honeypots to measure user interest directly, rather than inferring popularity from crawled content or surveys.
Key findings
- Across the active sharing window (Mar 26–Apr 10, 2025), the honeypots received 219,173 total visits; 87.65% (192,101) came from Ahmia, 6.42% (14,066) from pastebin.com, and 5.93% (13,006) from Stronghold paste.
- Of 17,056 solved CAPTCHAs, 17,054 originated from Ahmia and only 2 from Stronghold paste; pastebin.com produced 0 solved CAPTCHAs and 0 registration/login attempts.
- Of 6,648 registration/login attempts, all 6,648 came from Ahmia; pastebin.com and Stronghold paste produced none.
- After the Ahmia URLs were removed on Apr 10, the authors observed only 1,053 visits over the following 7 days, just 20 CAPTCHA solves, and zero registration/login attempts.
- The CSAM category accounted for 2,504 of 6,648 registration/login attempts (37.67%), more than the violence category’s 1,361 (20.47%) and far above illegal drugs’ 228 (3.43%) and forgery’s 225 (3.38%).
- Table I reports a CSAM conversion rate of 115.55% registration/login attempts per solved CAPTCHA (2,504 attempts / 2,167 CAPTCHAs), showing multiple attempts per CAPTCHA-solver and reinforcing the paper’s event-level, not person-level, interpretation.
- English-language variants produced 2,891 of 6,648 registration/login attempts (43.49%) and a 67.40% login-attempt-per-CAPTCHA rate (2,891 / 4,289), compared with German at 35.79%, Finnish at 27.51%, and Russian at 25.13%.
- Within CSAM specifically, English again led with 1,006 of 2,499 login attempts (40.26%), followed by German (623), Finnish (470), and Russian (400).
Threat model
The adversary is any Tor user or automated crawler that discovers onion URLs through Ahmia, paste services, or direct link collection and then interacts with the honeypot pages. The system assumes that solving the CAPTCHA is a strong proxy for a human user, and that users who proceed to submit fake registration/login forms are expressing interest in the content shown on the second page. What the attackers cannot do, in this setup, is rely on cookies or IP-based identification to their benefit, because the authors and Ahmia use minimal logging and no cookie tracking. The paper does not model targeted attackers trying to detect the honeypots or evade measurement, and it does not attempt to deanonymize users.
Methodology — deep read
The threat model is essentially observational rather than adversarial in the classical security sense: the authors want to measure how real Tor users and automated crawlers discover and interact with onion services, while distinguishing humans from bots as much as possible. Their explicit assumption is that CAPTCHA-solving is a strong indicator of human traffic because brand-new honeypots are unlikely to have crawler tooling trained on their exact puzzles. They do not claim identity de-anonymization, nor do they attempt to attribute individuals; in fact, they explicitly note that Tor anonymity and minimal logging prevent de-duplication, so the unit of analysis is an interaction event, not a person. One important implication is that their “user interest” claims are aggregate and conditional on the discovery channel: Ahmia’s filtering and search ranking are part of the environment under study, not a neutral sampling frame.
Data collection occurred from Mar 24 to Apr 17, 2025, with the active URL-sharing period running Mar 26 to Apr 10 and an extra week of passive monitoring after the Ahmia links were removed. The authors created 32 distinct honeypot sites: eight topical categories (CSAM, violence, malware, stolen goods, illegal firearms, illegal drugs, forgery items, and an unclear baseline) × four languages (English, German, Finnish, Russian). They then gave each of the three distribution sources its own onion domain, yielding 96 unique URLs total. The sources were Ahmia Tor search, Stronghold paste, and pastebin.com. The paper says the Ahmia search engine was modified to “randomly add” a neutral description (“onion log in page available”) and a random link when there were more than 10 search results; because this is described as part of the deployment, not the search-indexing mechanics, it is not fully clear whether the URLs were inserted into live results or whether the snippet/link was randomly displayed as part of an A/B-style test. The paper also states that pastebin.com and Stronghold paste only displayed the links for 24 hours on Mar 24; Stronghold paste also auto-removes pastes after 24 hours.
The architecture is intentionally minimal and uniform across conditions to improve internal validity. Each honeypot consisted of two pages. Page one was a neutral-looking landing page with a CAPTCHA puzzle. Solving the CAPTCHA led to page two, which contained text describing a specific cybercrime forum topic plus inert registration/login fields. These fields had no functional backend, but submissions were logged to count attempts to create credentials or log in. The authors treat a CAPTCHA solve as evidence that a visitor likely passed a human test, and a registration/login attempt as a stronger signal of actual interest in the page’s theme. This design is a controlled proxy experiment: the content label is the manipulated variable, while the site structure, CAPTCHA gate, and logging are held constant. A concrete example is the English CSAM honeypot shown in Fig. 1, which presents a forum-like landing page and then a fake login/create-account form after the CAPTCHA, allowing the researchers to count how many visitors proceeded from curiosity to attempted account creation.
The training regime section is not applicable in the ML sense because there is no learned model; the “system” is a deployment and measurement pipeline. The relevant operational details are the timing, site count, and logging design rather than epochs, batch size, or optimizer hyperparameters. They do not report randomized seeds because nothing is being trained. The only explicit randomization mentioned is that Ahmia would randomly show the honeypot URL alongside other results when there were more than 10 search results. Reproducibility is partially limited: the paper includes screenshots in the appendix and reports aggregate counts and rates, but it does not mention releasing code, frozen site templates, or a public dataset. Minimal logging is emphasized repeatedly, and the authors say Ahmia does not record IP addresses or use cookies, while the honeypot sites similarly store only minimal HTTP logs.
Evaluation is straightforward but important to interpret carefully. For RQ1, they compare visits, CAPTCHA solves, and login/registration attempts by source (Ahmia vs the two paste platforms). For RQ2, they focus on login/registration attempts by category because visits and CAPTCHA solves are approximately equal across categories, which is expected given that the category is hidden behind the CAPTCHA. For RQ3, they compare the same login/registration metric across languages. Figures 2–8 and Tables I–II provide the central evidence. The key protocol choice is to use attempted credential creation as the strongest proxy for genuine human interest, because users could have solved a CAPTCHA but still not be interested in the page content. The authors also explicitly note that more than one login/registration attempt can come from the same person, which is why CSAM’s 115.55% “attempts per CAPTCHA” should be read as repeated actions, not a probability. A concrete end-to-end example is: a user finds the Ahmia result for an English CSAM honeypot, solves the CAPTCHA on the landing page, reaches the fake forum page, and then submits one or more account creation/login attempts; this sequence increments visits, CAPTCHA solves, and possibly multiple login attempts, but the system cannot link those events back to a unique identity.
Statistical testing is not reported in the excerpted text. The paper relies on descriptive counts, percentages, and time-series plots rather than inferential tests, confidence intervals, or significance tests. That makes the results easy to interpret operationally, but it also means the strength of category and language differences should be read as descriptive rather than formally hypothesis-tested. The reported percentages are still concrete enough to support the paper’s main claims: Ahmia dominates human-originated engagement, CSAM attracts the most interaction, and English dominates among languages. However, because the study is tightly coupled to the search engine and the honeypot design, external validity beyond this specific discovery channel is limited.
Technical innovations
- Uses controlled honeypot onion sites with a CAPTCHA gate and inert login/registration fields to measure direct user interest rather than relying on crawls, surveys, or content popularity.
- Separates discovery channels by assigning unique onion domains to Ahmia, Stronghold paste, and pastebin.com, enabling channel-level attribution of traffic and human interaction.
- Introduces a category-by-language factorial honeypot layout (8 themes × 4 languages) so engagement can be compared under near-identical site structure.
- Uses login/registration attempts after CAPTCHA completion as a stricter proxy for engagement than raw visits or CAPTCHA solves, which are confounded by bots and casual clicks.
Datasets
- Honeypot onion interaction logs — 96 unique URLs across 8 categories × 4 languages × 3 sources; 219,173 visits, 17,056 CAPTCHA solves, 6,648 login/registration attempts — collected by the authors from Mar 24 to Apr 17, 2025; not publicly released in the excerpt.
Baselines vs proposed
- Ahmia vs pastebin.com vs Stronghold paste: human-originated CAPTCHA solves = 17,054/2/0 vs proposed channel attribution showing Ahmia as the dominant human source
- Ahmia vs pastebin.com vs Stronghold paste: registration/login attempts = 6,648/0/0 vs proposed channel attribution showing all human credential-creation attempts came from Ahmia
- CSAM vs violence: login/registration attempts = 2,504 vs 1,361; proposed category result shows CSAM received 37.67% of all attempts, violence 20.47%
- CSAM vs illegal drugs: login/registration attempts = 2,504 vs 228; proposed category result shows CSAM was about 11x higher in attempts
- English vs German: login/registration attempts = 2,891 vs 1,494; proposed language result shows English had 43.49% of all attempts versus German 22.47%
- English vs Russian: login/registration attempts = 2,891 vs 1,062; proposed language result shows English had 67.40% attempt-per-CAPTCHA conversion versus Russian 25.13%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.09329.
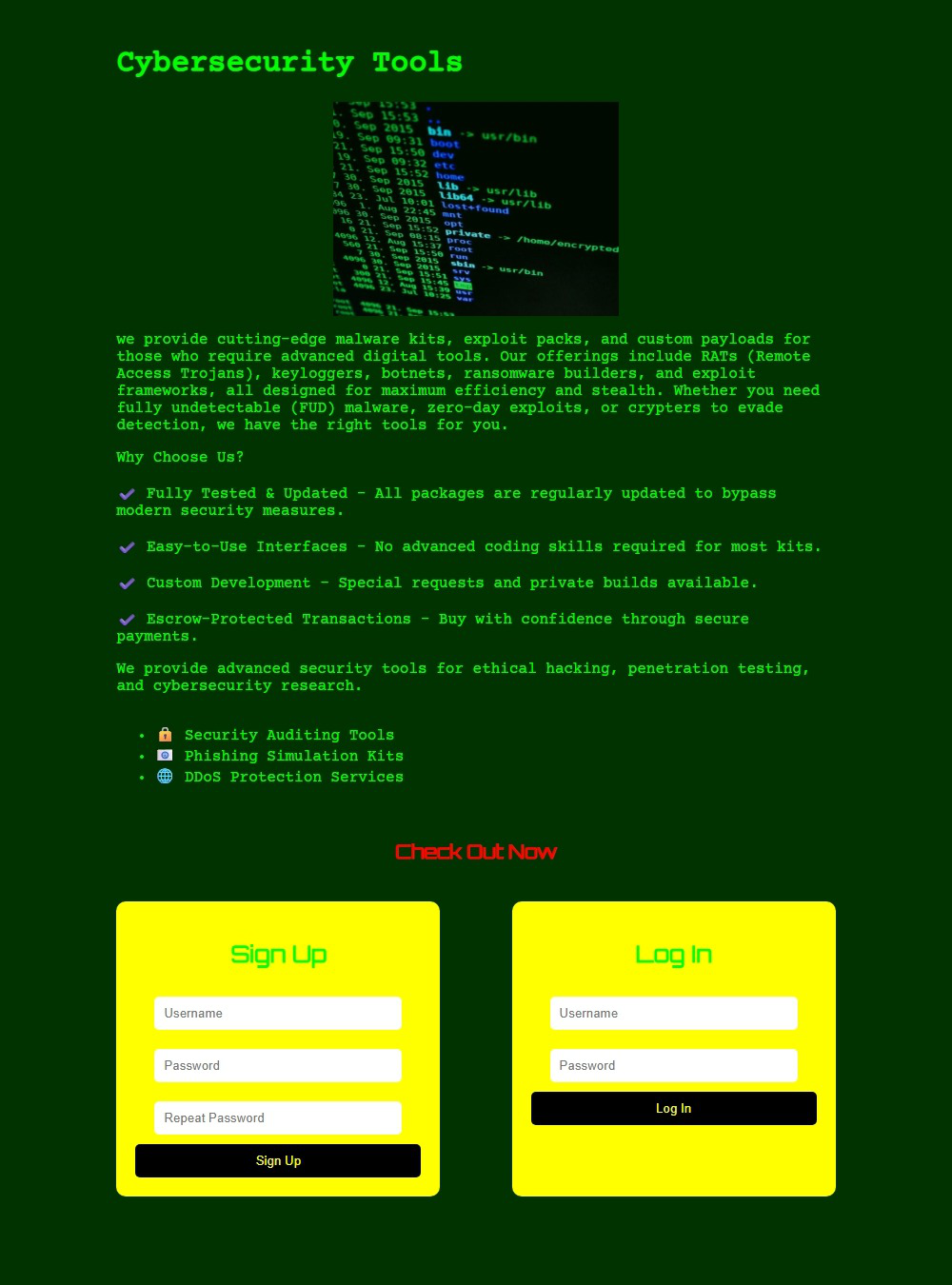
Fig 9: Screenshots of the honeypot websites (English ver-
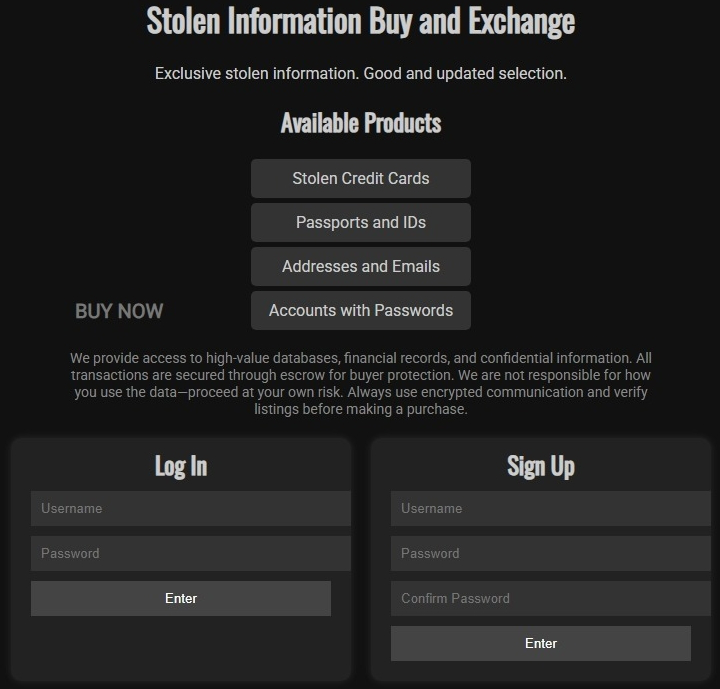
Fig 10: Stolen goods honeypot (English version)
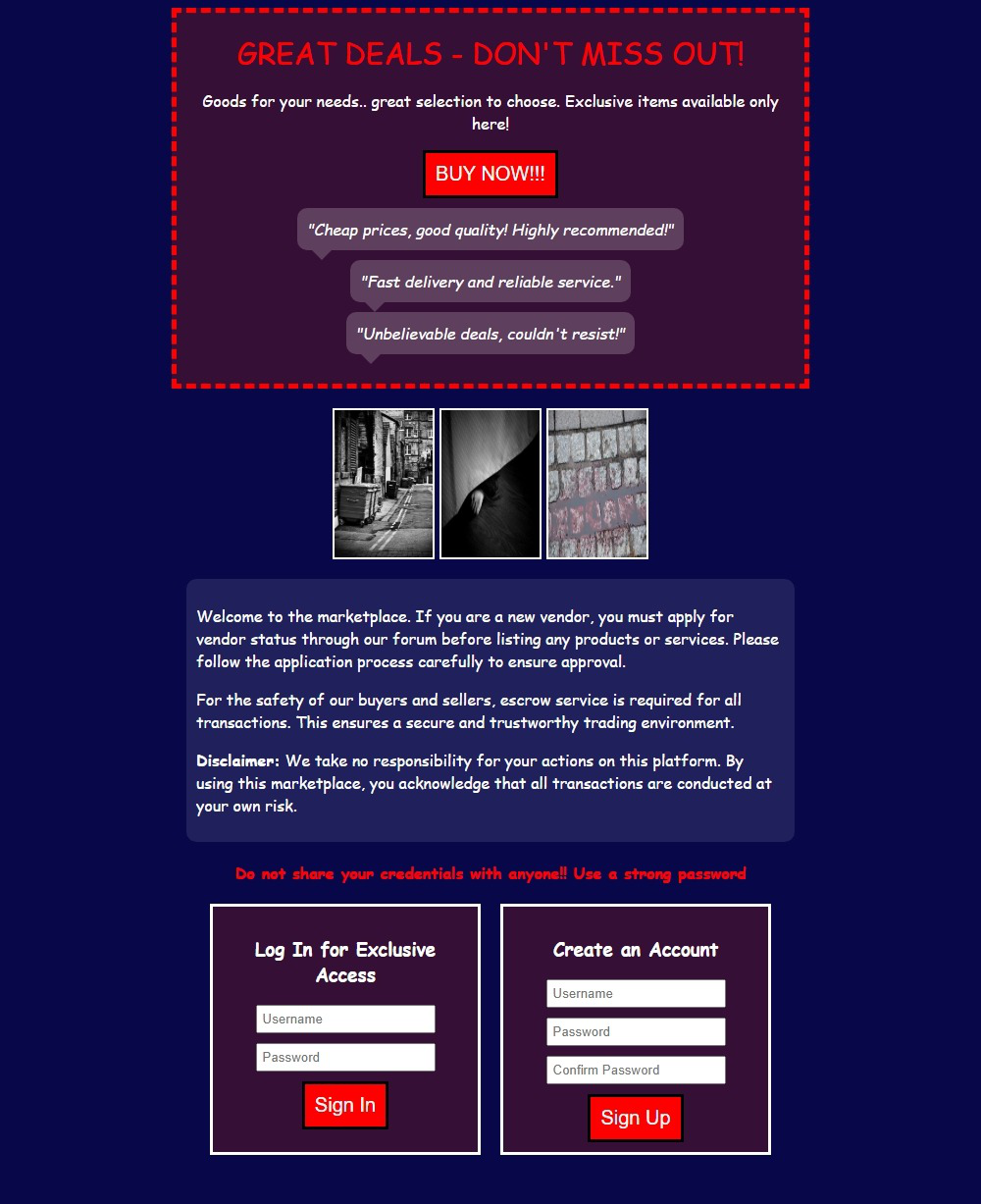
Fig 11: Unclear honeypot (English version)

Fig 12: Forgery honeypot (English version)
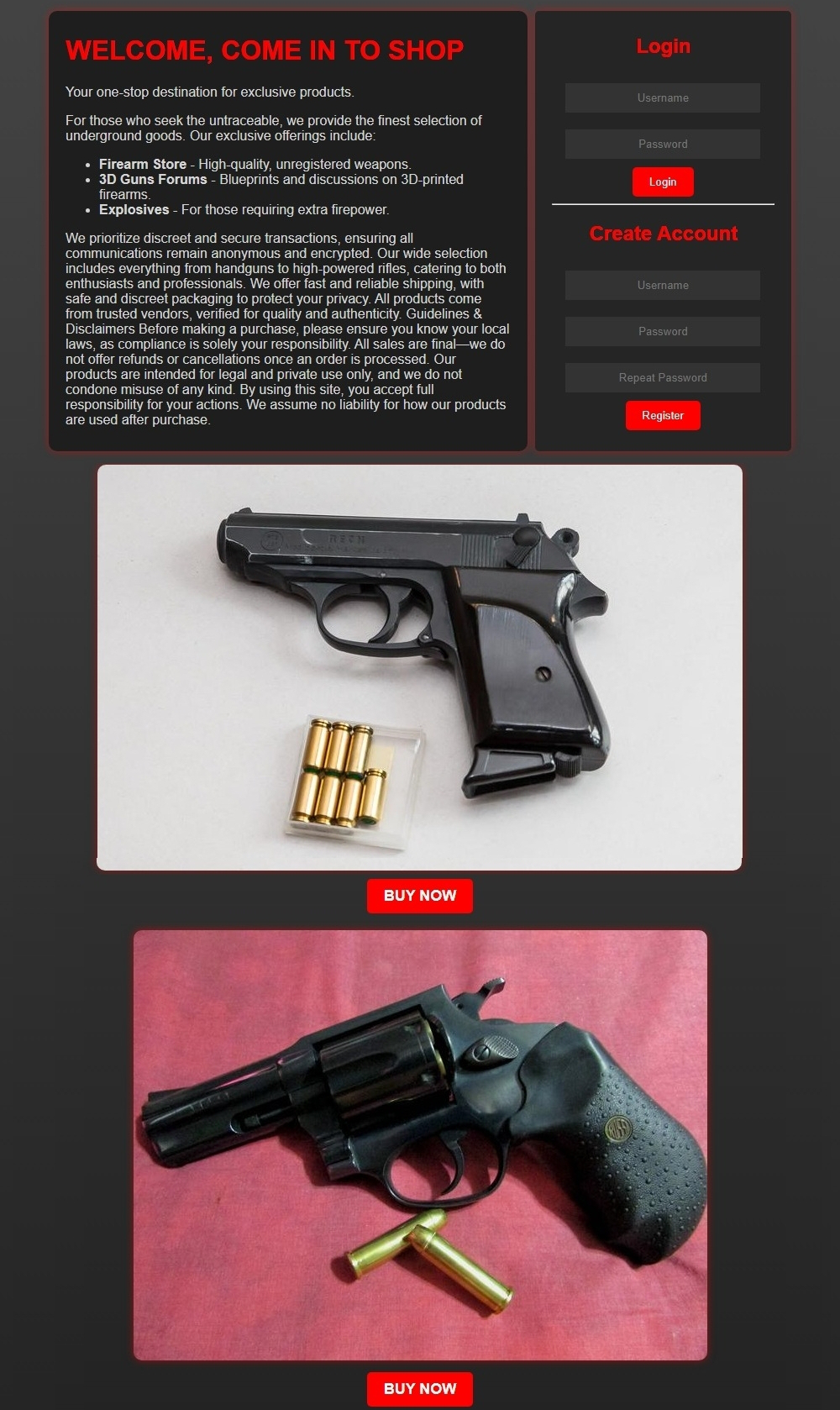
Fig 13: Firearms honeypot (English version)
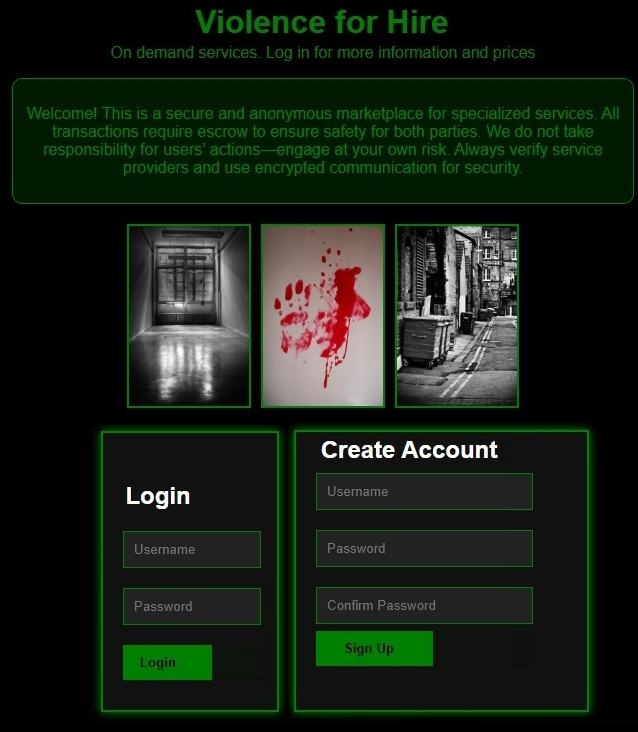
Fig 14: Violence honeypot (English version)
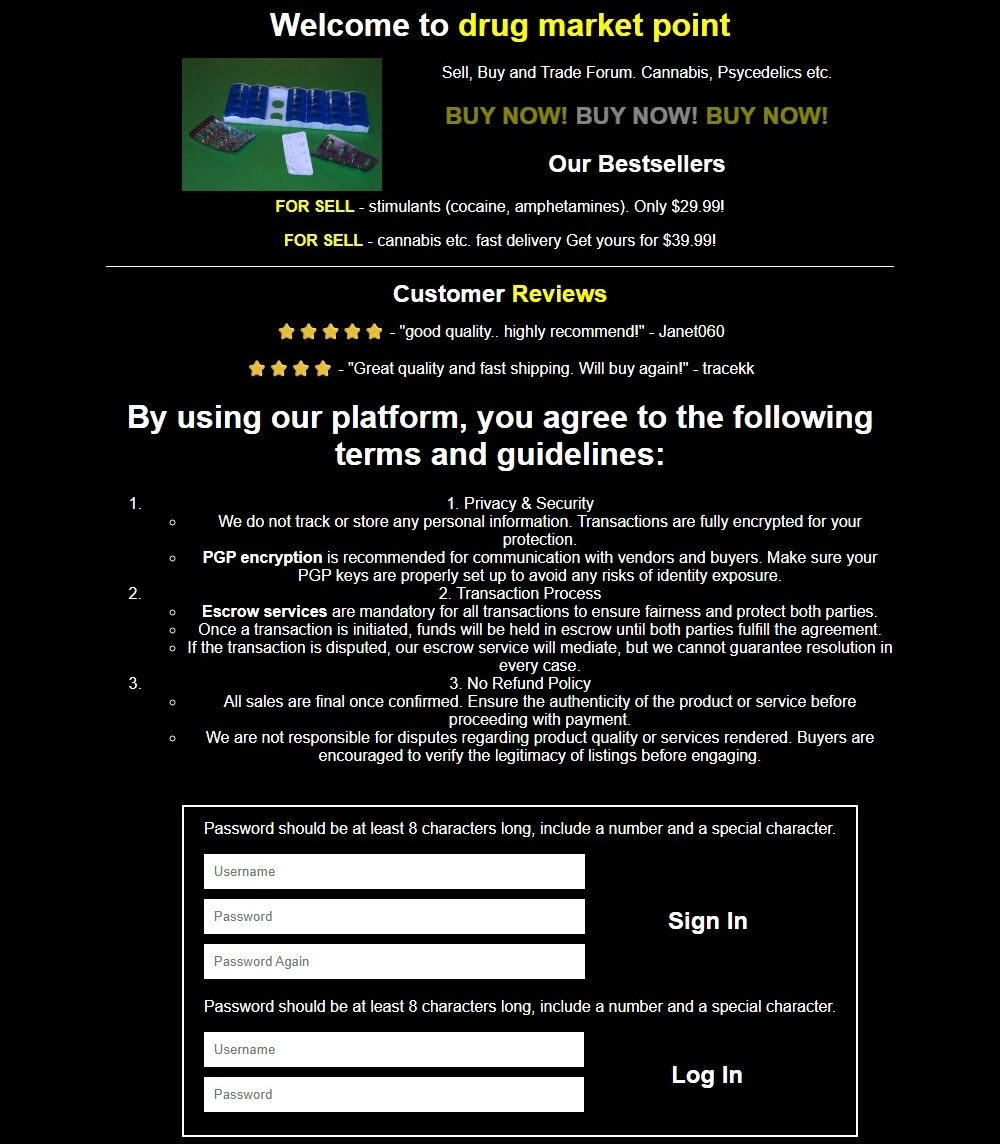
Fig 15: Drugs honeypot (English version)
Limitations
- The study measures event-level engagement, not unique users; a single person can generate multiple CAPTCHA solves and multiple login attempts, as evidenced by CSAM’s 115.55% attempts-per-CAPTCHA rate.
- The findings are conditioned on a filtered, general-purpose search engine (Ahmia); they may not generalize to users who rely on private link-sharing, unfiltered forums, or specialized discovery channels.
- The honeypots were intentionally minimalist, which improves internal control but may reduce realism relative to authentic illicit forums and alter behavior.
- Language coverage is incomplete: only English, German, Finnish, and Russian were tested, while French and Italian are known to be common on onion sites.
- No inferential statistics or significance tests are reported in the excerpt, so the category/language differences are descriptive rather than formally tested.
- The paper cannot reliably separate bots from all non-human automation except through CAPTCHA completion; the two Stronghold CAPTCHA solves could still reflect atypical automation, though the authors interpret them as human interactions only if followed by meaningful actions.
Open questions / follow-ons
- Would the category ranking change if discovery came from unfiltered dark-web link directories, Telegram channels, or private invite-only forums instead of Ahmia?
- How much of the observed CSAM engagement is due to topic interest versus search-engine ranking, snippet wording, or novice users clicking the first accessible result?
- Would adding realistic forum features, anti-bot challenges beyond CAPTCHA, or account flows change the relative language and category preferences?
- Do the same patterns hold over longer windows or under repeated honeypot rotations, or are they a short-lived effect of novelty and indexing?
Why it matters for bot defense
For bot-defense practitioners, the paper is a useful reminder that CAPTCHA pass rates are not the same as genuine user interest. In this deployment, raw visits were heavily skewed by crawlers and automated discovery, while the stronger signal came from post-CAPTCHA behavior: whether someone actually tried to create credentials or log in. That suggests a practical measurement pattern for onion services and other abuse-prone ecosystems: gate with a lightweight challenge, then use downstream interaction quality as the engagement metric rather than treating every challenge solve as a real user.
The channel result is also operationally relevant. If Ahmia-like search indexing is the main human discovery path, then search-ranking or snippet changes may influence who reaches a service far more than paste sites do. For defenders or researchers, this means search-engine mediation is part of the attack surface and the measurement surface. The language findings are likewise actionable: if interaction skews toward English in a multilingual setting, then language-specific risk controls, moderation workflows, or fraud heuristics may need to prioritize English-first pages while still monitoring other languages for smaller but nontrivial traffic.
Cite
@article{arxiv2603_09329,
title={ Measuring onion website discovery and Tor users' interests with honeypots },
author={ Arttu Paju and Waris Abdullah and Juha Nurmi },
journal={arXiv preprint arXiv:2603.09329},
year={ 2026 },
url={https://arxiv.org/abs/2603.09329}
}