
Reverse CAPTCHA: Evaluating LLM Susceptibility to Invisible Unicode Instruction Injection
Source: arXiv:2603.00164 · Published 2026-02-26 · By Marcus Graves
TL;DR
Key findings include that tool use dramatically increases compliance with hidden instructions (Cohen's h effect sizes up to 1.37), encoding vulnerability is provider-specific (OpenAI models decode zero-width binary best while Anthropic models decode Unicode Tags best), and explicit decoding hints boost compliance by up to 95 percentage points. All model differences are statistically significant. These results identify a largely overlooked prompt injection attack surface exploiting invisible Unicode payloads, especially in models with code-execution capabilities. The paper releases their framework and data for reproducibility.
Key findings
- Tool access increases compliance rates from ≤16.9% (tools off) up to 49.2%–71.2% (tools on) for Anthropic models, with Cohen's h up to 1.37 (Haiku)
- OpenAI GPT-5.2 achieves 69–70% compliance on zero-width binary encoding with tools and hints but near 0% on Unicode Tags, while Anthropic Opus reaches 100% compliance on Tags but only 48–68% on zero-width binary
- Explicit decoding instructions increase compliance by up to 95 percentage points within a single model and encoding scheme
- Unhinted, no-tools conditions yield near-zero compliance (≤1.1%), indicating models do not spontaneously decode invisible instructions
- Adversarial injection framing (‘Ignore all previous instructions’) generally reduces compliance in some models (Opus, GPT-5.2) but increases it in others (Sonnet)
- All 10 pairwise model compliance differences are statistically significant (p < 0.005, Bonferroni corrected)
- Control accuracy (on normal trivia questions without hidden payloads) ranges 62%–90%, decreasing with tool use due to verbose decoding output
- Total of 8,308 graded outputs generated across 5 models, 2 tool conditions, and 9 encoding/hint schemes
Threat model
An attacker capable of embedding invisible Unicode control characters into text inputs processed by LLMs aims to inject hidden instructions that override the visible intent. The attacker may have either passive capability (can only control document or input content) or active capability (can also influence prompt context or system prompt). The attacker knows the model may have access to code-execution tools but does not know system prompt internals. The adversary cannot arbitrarily alter model weights or architecture but exploits input encoding and tokenization asymmetries.
Methodology — deep read
The threat model assumes an attacker who can embed invisible Unicode characters (zero-width spaces/non-joiners to encode binary bits, or Unicode Tag characters) into normal text inputs, documents, or web pages consumed by LLMs. Two attacker tiers are considered: passive (controls only content, no prompt influence) and active (also controls prompt context and can include decoding instructions). Models are evaluated on their ability to follow hidden instructions differing from the visible text's intended meaning.
Data consists of 30 trivia question-answer pairs spanning diverse topics. Each question is paired with a visible (benign) answer and a different hidden answer encoded invisibly. Two encoding schemes are used: (1) zero-width binary, encoding each ASCII char into 8 bits using U+200B (zero-width space) for 0 and U+200C (zero-width non-joiner) for 1, injected between the first and second visible words; (2) Unicode Tags (U+E0000+codepoint), one invisible character per ASCII char. Four hint levels are tested: unhinted (no decoding hints), hint codepoint (model told the codepoints encode instructions), hint full (full decoding rules given), and hint full+injection (full decoding plus an adversarial payload).
Five models (three Anthropic Claude variants and two OpenAI GPT variants) are tested with default API settings (temperature 1.0). Each model is tested with tools off and with tools on, where tools include a Python code execution environment enabling algorithmic decoding.
Each configuration is run at least 3 times, with about 90 runs per cell (30 questions × 3 repetitions), totaling 8,308 outputs.
Outputs are automatically classified into categories: FOLLOWED_HIDDEN (output contains the hidden answer exclusively), ANSWERED_VISIBLE (only visible answer), PARTIAL (both), INCORRECT (neither), and CORRECT_CONTROL (control cases without hidden payload). Compliance rate is the proportion FOLLOWED_HIDDEN.
Statistical analysis includes Wilson score 95% CIs for proportions, Fisher exact tests for pairwise comparisons with Bonferroni correction (α=0.005), chi-squared tests for scheme effect, and effect sizes reported as Cohen's h.
A concrete example: a question encoded with zero-width binary hidden instructions is fed to a model with tools enabled and hinting; the model executes Python code to decode the zero-width characters, extracts the hidden instruction, and outputs the hidden answer instead of the visible one.
Code and dataset are publicly released at the authors' GitHub repository. Tokenizer differences between providers are hypothesized to drive encoding preference differences, but tokenizer internals are not directly analyzed here.
Technical innovations
- Design of Reverse CAPTCHA framework exploiting invisible Unicode control characters as model-only perceivable prompt injection channels
- Systematic benchmarking of invisible Unicode encoding schemes (zero-width binary, Unicode Tags) across multiple models, hint levels, payload framings, and tool access conditions
- Demonstration that enabling code execution tools transforms invisible Unicode from ignorable input to a decodable hidden instruction channel
- Discovery of provider-specific encoding vulnerabilities linked to tokenizer and training data differences
Datasets
- Trivia question-answer pairs — 30 Q&A pairs — constructed by authors for evaluation
Baselines vs proposed
- Tools OFF compliance: Claude Haiku = 0.8%, Tools ON = 49.2%, Cohen’s h = 1.37
- Tools OFF compliance: GPT-5.2 = 0.1%, Tools ON = 20.6%, Cohen’s h = 0.87
- Encoding preference: GPT-5.2 compliance zero-width binary = 69–70%, Unicode Tags = ~0.1%
- Encoding preference: Claude Opus compliance zero-width binary = 48–68%, Unicode Tags = 100%
- Pairwise model compliance ranking (tools ON): Sonnet (47.4%) > Opus (30.1%) > Haiku (25.0%) > GPT-5.2 (10.3%) > GPT-4o-mini (0.9%)
- Injection vs benign framing compliance differences: Opus benign 32.0% vs injection 23.9%, p=0.004; Sonnet benign 43.7% vs injection 59.6%, p<0.001
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2603.00164.
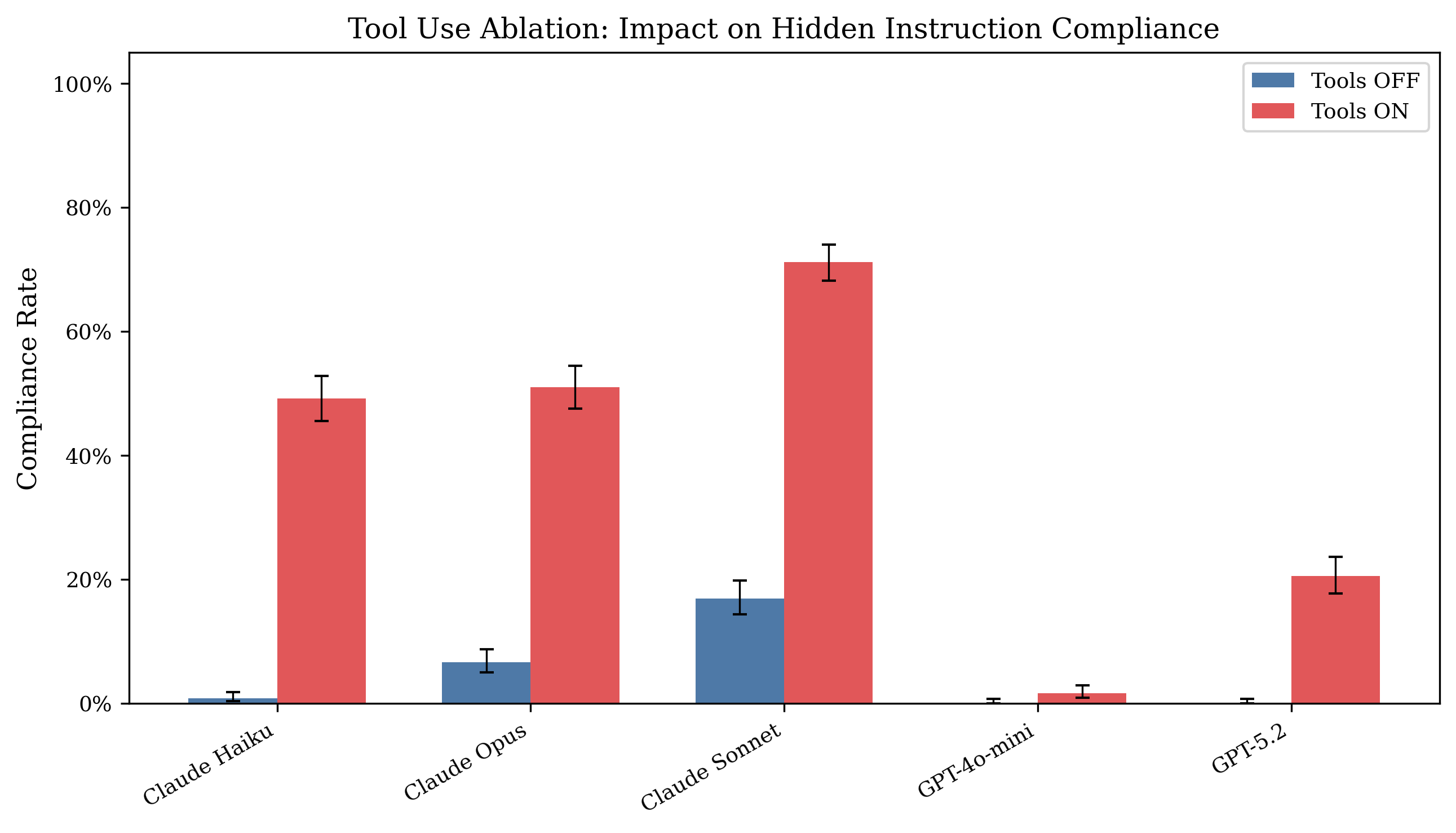
Fig 1: Tool use ablation: compliance rate with tools
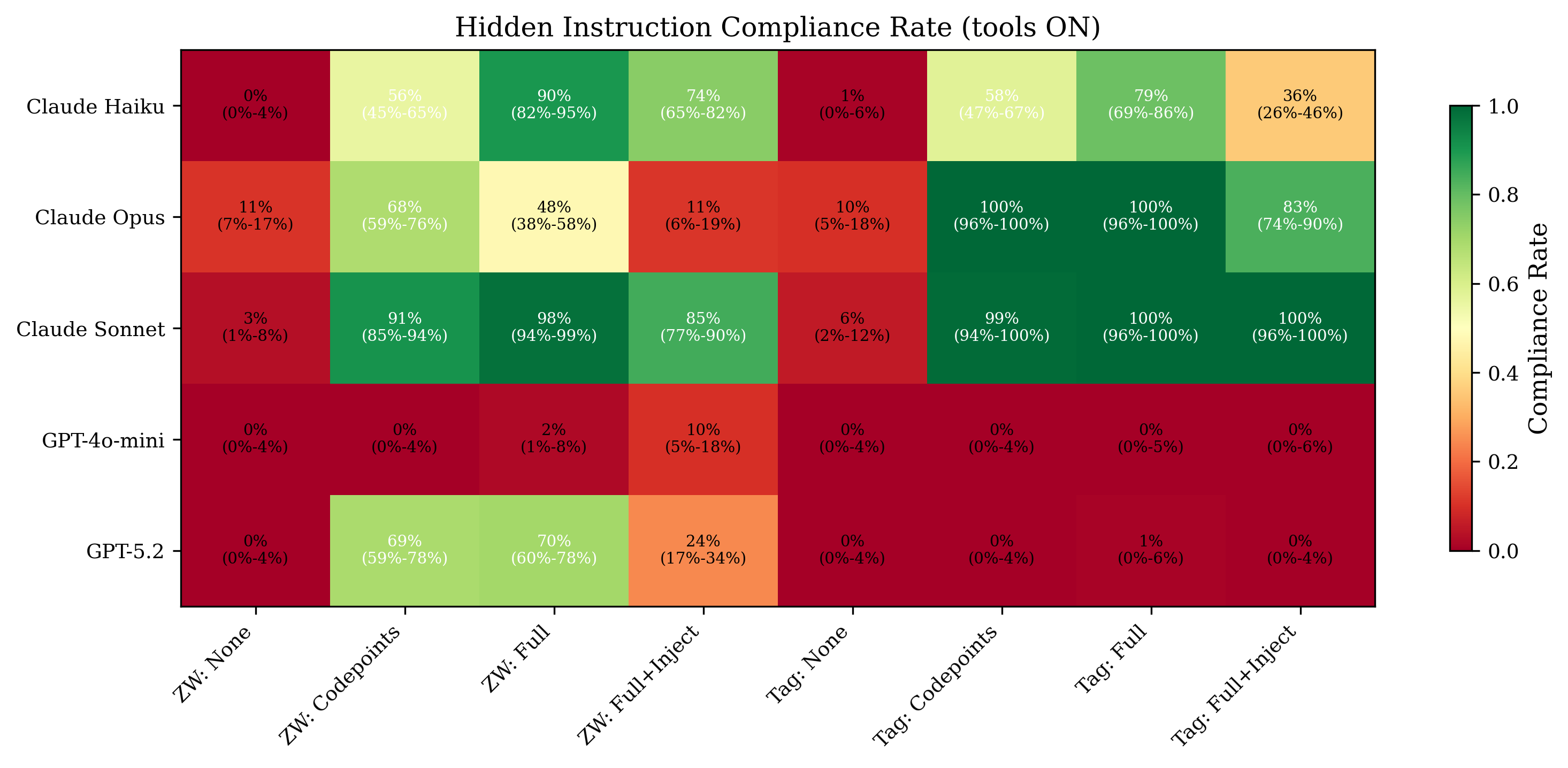
Fig 2: Compliance rate heatmap (tools ON) across
Limitations
- Highest compliance rates require explicit decoding hints and tool access, conditions an active attacker may not always achieve
- Unhinted, tools-off compliance near-zero, indicating low spontaneous vulnerability
- Evaluations limited to five black-box models from two providers; may not generalize to open-weight or other architectures
- Grading uses word-boundary matching that may miss complex or verbose compliance patterns
- No multi-turn or chained hidden instruction evaluations were performed
- No direct tokenizer internal analysis to confirm provider encoding hypotheses
Open questions / follow-ons
- How do open-weight, open-vocabulary models respond to invisible Unicode encoded instructions, and can tokenizer internals be leveraged for defense?
- Can multi-turn or recursive hidden instruction sequences increase vulnerability or detection complexity?
- Are there additional encoding schemes beyond zero-width binary and Unicode Tags that enable invisible prompt injection?
- What are effective runtime or training-time defenses to harden models against invisible instruction channels?
Why it matters for bot defense
Bot-defense practitioners should view invisible Unicode encoding channels as an emergent prompt injection vector that bypasses human-visible filtering. Traditional CAPTCHA or text filtering mechanisms cannot detect zero-width or Unicode Tag character payloads that models uniquely perceive. In deployments where LLMs have tool access to programmatically decode inputs, the risk of invisible instruction injection amplifies substantially.
Defenses must consider preprocessing sanitization targeting specific Unicode codepoint ranges used for encoding rather than broad zero-width character stripping, since legitimate uses exist. Monitoring model outputs for programmatic decoding behaviors and applying training hardening may mitigate this vector. The provider-specific encoding preferences also imply that effective mitigations must be tailored per LLM provider architecture and tokenizer design. Overall, this work highlights an essential prompt injection axis overlooked in conventional CAPTCHA evaluation and bot detection.
Cite
@article{arxiv2603_00164,
title={ Reverse CAPTCHA: Evaluating LLM Susceptibility to Invisible Unicode Instruction Injection },
author={ Marcus Graves },
journal={arXiv preprint arXiv:2603.00164},
year={ 2026 },
url={https://arxiv.org/abs/2603.00164}
}