
When Handshakes Tell the Truth: Detecting Web Bad Bots via TLS Fingerprints
Source: arXiv:2602.09606 · Published 2026-02-10 · By Ghalia Jarad, Kemal Bicakci
TL;DR
This paper asks whether passive TLS handshake metadata, specifically JA4 fingerprints, can separate malicious web bots from legitimate human traffic without relying on browser-side behavior or intrusive scripts. The motivation is practical: higher-layer signals like User-Agent strings, cookies, mouse dynamics, and keystrokes are increasingly spoofable, while TLS ClientHello structure is much harder for casual bots to alter because it is produced by the underlying TLS stack. The authors position JA4 as a lower-cost, privacy-preserving signal for triaging suspicious sessions before they ever reach application-layer defenses.
Their core experiment is straightforward: parse JA4DB records into structured features, label traffic as benign or bad bot after excluding known good crawlers, and train two gradient-boosted tree models (XGBoost and CatBoost) on an 80/20 split. The reported result is very strong separation on the held-out test set: CatBoost reaches AUC 0.998, F1 0.9734, and accuracy 0.9863, with XGBoost nearly identical. Feature importance points to JA4-specific handshake components, especially ja4_b, cipher_count, and ext_count, as the dominant signals. The paper’s main practical claim is not that TLS fingerprinting solves bot detection universally, but that it is an effective first-line signal against bots that do not fully emulate a real browser TLS stack.
Key findings
- CatBoost achieved AUC = 0.998, F1 = 0.9734, and accuracy = 0.9863 on the test set derived from JA4DB.
- XGBoost was nearly tied with CatBoost: precision = 0.9668, recall = 0.9798, F1 = 0.9732, accuracy = 0.9862.
- On XGBoost, the confusion matrix reports 28,699 true negatives, 9,840 true positives, 338 false positives, and 203 false negatives.
- On CatBoost, the confusion matrix reports 28,701 true negatives, 9,842 true positives, 336 false positives, and 201 false negatives.
- The dataset after excluding known good bots contained approximately 50,212 bad-bot records (22.08%) and 148,610 benign records (65.35%), from an initial 227,404 records.
- The study used a fixed 80/20 train-test split with no synthetic oversampling, and the authors explicitly note that the data remain naturally imbalanced.
- Feature importance analysis showed ja4_b as the most influential feature for XGBoost, followed by cipher_count and ext_count; the paper also names ja4_c, alpn_code, os, sni_flag, and tls_version as secondary contributors.
- The authors state that the approach is effective against automated scripts, scrapers, and header/IP spoofing, but low or ineffective against full browser automation (Puppeteer/Playwright/Selenium driving a real browser) and advanced TLS spoofing.
Threat model
The adversary is a web bot operator who can spoof headers, rotate IPs, and use standard automation or scraping tools, but who does not fully emulate a real browser TLS stack. The defender passively inspects JA4-derived TLS ClientHello features and assumes those handshakes are observable before encryption. The method is not designed to defeat a bot that drives an actual browser engine or a specialized TLS-spoofing library that can reproduce browser fingerprints bit-for-bit.
Methodology — deep read
Threat model and assumptions: the defender observes TLS ClientHello metadata passively and wants to classify connections as benign human traffic or malicious bot traffic. The attacker can rotate IPs, spoof headers such as User-Agent, and use standard non-browser tooling, but the method assumes they do not fully emulate a real browser TLS stack or implement a specialized TLS-fingerprinting evasion library. The paper is explicit that the method is not meant as authentication or attribution; it is a detection/prioritization signal. It succeeds when bots use distinct or nonstandard TLS implementations, and fails or degrades when the adversary drives a genuine browser engine or bitwise-matches browser fingerprints.
Data provenance and labeling: the experiments use JA4DB, a community-maintained repository of JA4 fingerprints. The paper describes two provenance channels: active submission in controlled environments and passive network monitoring from real traffic. The raw corpus is reported as 227,404 records. For training labels, entries containing application or user_agent_string indicators for well-known crawlers such as Googlebot, Bingbot, or LinkedInBot were treated as “good bots” and excluded. Remaining records whose application field contained “bot” were labeled bad bots; the rest were labeled benign. After this filtering, the paper reports approximately 50,212 bad-bot records (22.08%) and 148,610 benign records (65.35%), with 32,007 good-bot records excluded. The data were split 80/20 into train and test using a fixed random seed. The paper does not describe a separate attacker-held-out split, time-based split, or cross-validation, so the evaluation appears to be a standard random holdout on the same source distribution.
Feature extraction and representation: the core input is the JA4 string, which encodes TLS handshake structure. The authors parse these raw strings into structured fields including protocol, TLS version, SNI presence, cipher_count, ext_count, ALPN code, ja4_b (cipher suite hash), ja4_c (extension/signature hash), and metadata fields such as application, OS, device, verified flag, and observation count. Categorical columns including protocol, TLS version, ALPN code, ja4_b, ja4_c, application, os, and device are label-encoded for XGBoost. For CatBoost, categorical features are passed directly through CatBoost’s Pool interface, which avoids manual one-hot or label encoding and lets CatBoost handle category statistics internally. The novelty here is not the encoding itself but the use of JA4-derived handshake structure as the feature space for bot detection.
Models and training regime: two gradient-boosted tree classifiers are trained. XGBoost uses 500 boosting trees, maximum depth 8, learning rate 0.05, subsample 0.8, colsample 0.8, and Logloss as the objective. CatBoost uses 500 iterations, depth 8, learning rate 0.05, and Logloss, again with a fixed random seed. The paper does not report batch size, epoch count in neural-network terms, early stopping, GPU/CPU hardware, or multiple random seeds. It also states explicitly that no synthetic oversampling was used, which matters because the class distribution is imbalanced and the reported metrics are therefore on the natural skew rather than a balanced benchmark.
Evaluation protocol and one end-to-end example: evaluation uses accuracy, precision, recall, F1, confusion matrices, and ROC/AUC on the held-out 20% test set. XGBoost’s test confusion matrix is 28,699 TN / 338 FP / 203 FN / 9,840 TP, yielding precision 0.9668, recall 0.9798, F1 0.9732, and accuracy 0.9862. A concrete example of the pipeline is: a JA4DB record arrives with a ClientHello-derived JA4 string; the extractor pulls out cipher_count, ext_count, ALPN code, and hashes like ja4_b and ja4_c; the categorical fields are encoded; the feature vector is fed to the trained XGBoost or CatBoost model; the model outputs a bot probability; thresholding at the default decision boundary yields benign or bot. The ROC curve for XGBoost is shown in Fig. 2 with AUC 0.998, and feature importance is shown in Fig. 3. CatBoost’s training log is shown in Fig. 4. No statistical significance testing is reported, and no calibration analysis is provided.
Reproducibility and reporting gaps: the paper cites public sources for JA4 and JA4DB, and it reports enough hyperparameters to reimplement the two tree models. However, it does not provide code, frozen model weights, exact preprocessing scripts, exact feature schema after extraction, or a versioned snapshot of the JA4DB subset used. The labeling rules are described at a high level but not with a fully enumerated decision tree, so reproducing the exact sample counts may require access to the same repository state. The paper also does not report run-to-run variance across seeds, which would matter because the metrics are very high and the margin between XGBoost and CatBoost is tiny.
Technical innovations
- Uses JA4 TLS handshake fingerprints, rather than behavior or content signals, as the primary feature set for web bad-bot detection.
- Shows that a small set of JA4-derived fields, especially ja4_b, cipher_count, and ext_count, carries most of the discriminative power.
- Demonstrates that off-the-shelf gradient-boosted trees on structured JA4 features can reach near-perfect separation on JA4DB without oversampling.
- Frames the detection problem with an explicit attacker boundary: strong against header/IP spoofing and non-browser stacks, weak against real-browser emulation and advanced TLS spoofing.
Datasets
- JA4DB — 227,404 records total; ~50,212 bad bots, 148,610 benign, 32,007 good bots excluded — community-maintained repository (ja4db.com)
Baselines vs proposed
- XGBoost: AUC = 0.998 vs proposed CatBoost = 0.998
- XGBoost: F1 = 0.9732 vs proposed CatBoost = 0.9734
- XGBoost: accuracy = 0.9862 vs proposed CatBoost = 0.9863
- XGBoost: precision (bot class) = 0.9668 vs proposed CatBoost = 0.9670
- XGBoost: recall (bot class) = 0.9798 vs proposed CatBoost = 0.9800
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.09606.
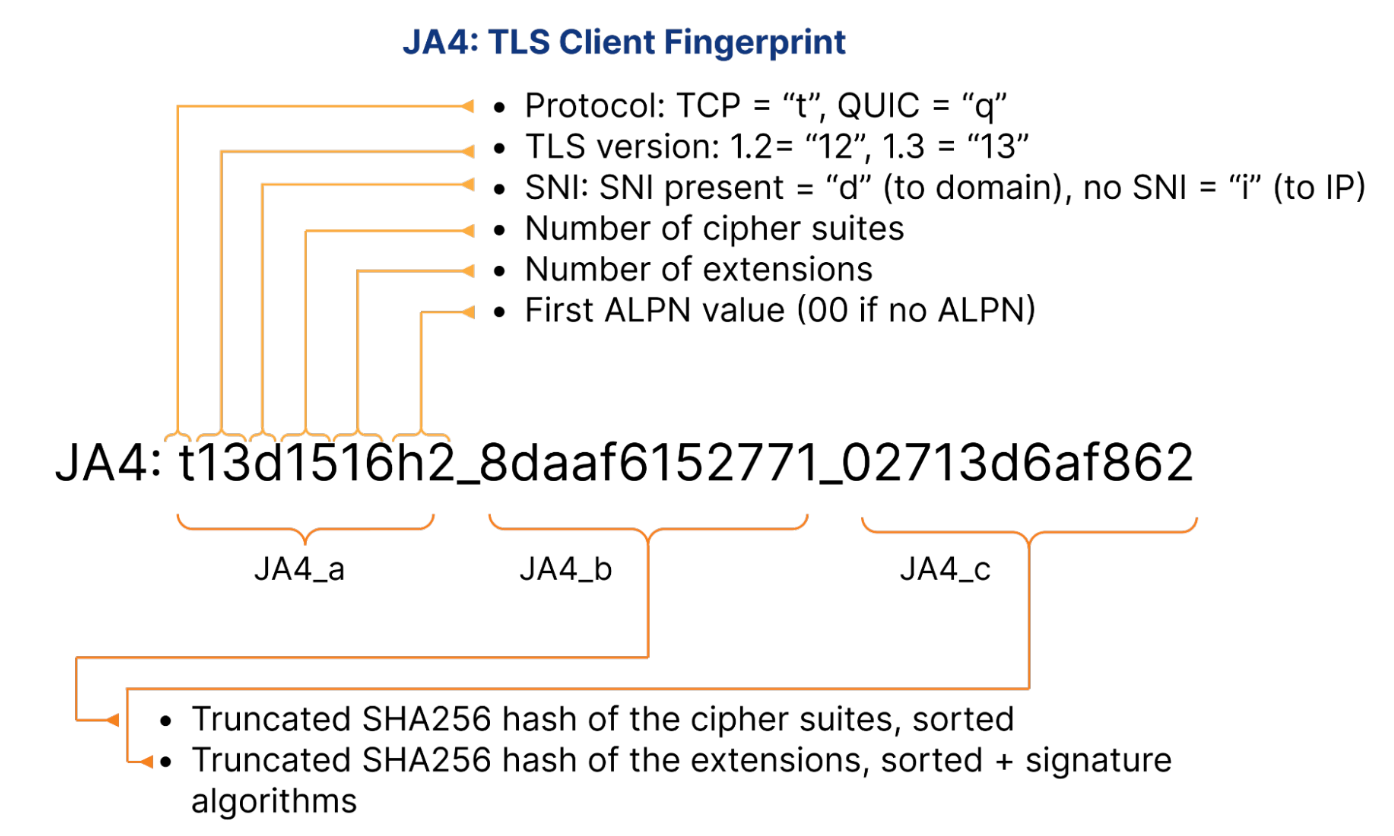
Fig 1: JA4 TLS client fingerprint structure [22]
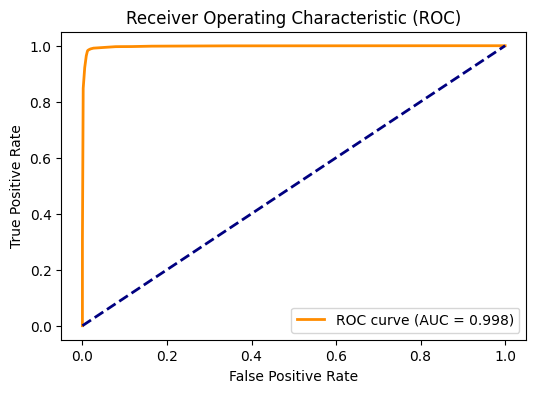
Fig 2: Receiver Operating Characteristic curve for the
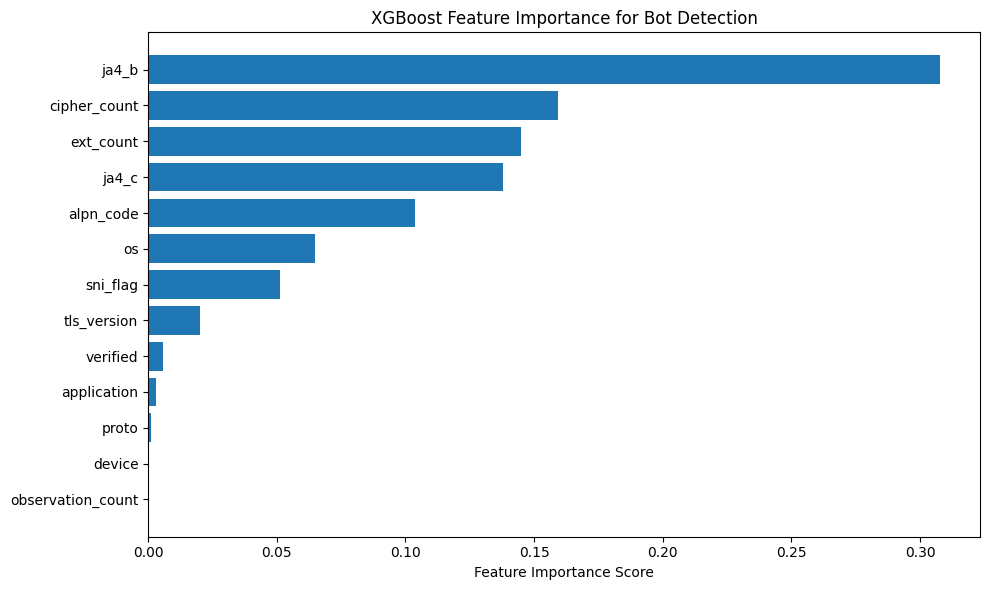
Fig 3: Feature importance for XGBoost Classifier.

Fig 4: Training log of CatBoost Classifier.
Limitations
- The reported evaluation is a single 80/20 random split; there is no time-based split, cross-validated estimate, or attacker-held-out evaluation.
- The dataset labeling depends partly on application and user-agent heuristics, which may leak higher-layer information into the labels and feature set.
- The method is explicitly weak against full browser automation and sophisticated TLS spoofing, so the best-case results may overstate performance against modern evasive bots.
- No ablation table is provided to quantify how much each feature family contributes beyond the importance ranking.
- The paper does not report calibration, threshold tuning, or the operational false-positive cost on real production traffic.
- Reproducibility is limited by the absence of code, frozen dataset snapshot, and run-to-run variance across seeds.
Open questions / follow-ons
- How does JA4-based bot detection hold up under a strict attacker-held-out evaluation, especially against bots collected after the model is trained?
- Which feature subset remains predictive if higher-layer metadata like application, OS, or device are removed to reduce label leakage and dependence on semi-observable fields?
- How much do HTTP/3 or QUIC fingerprints improve robustness when TLS handshakes become less informative or are masked by browser automation?
- Can JA4 features be fused with weak behavioral signals in a calibrated way that preserves low false positives while improving coverage against real-browser automation?
Why it matters for bot defense
For a bot-defense engineer, this paper suggests a low-friction pre-CAPTCHA filter: if a session’s JA4 fingerprint looks like a non-browser TLS stack, you can raise risk, throttle, or step up challenge before spending a CAPTCHA or other interactive test. That is especially useful when the goal is to reduce load from scrapers, credential-stuffers, and generic automation that can already solve some challenges or mimic superficial behavior.
The main operational caution is that JA4 should be treated as one signal among several, not as a standalone bot verdict. Real browsers driven by automation frameworks will look human at the TLS layer, and sophisticated actors can intentionally mimic browser fingerprints. So in practice, this work is most relevant as part of a risk-scoring pipeline: combine TLS fingerprinting with rate limits, session consistency checks, IP reputation, and application-layer behavior, and use it to prioritize which traffic deserves heavier scrutiny or a CAPTCHA challenge.
Cite
@article{arxiv2602_09606,
title={ When Handshakes Tell the Truth: Detecting Web Bad Bots via TLS Fingerprints },
author={ Ghalia Jarad and Kemal Bicakci },
journal={arXiv preprint arXiv:2602.09606},
year={ 2026 },
url={https://arxiv.org/abs/2602.09606}
}