
Privacy-Preserving Covert Communication Using Encrypted Wearable Gesture Recognition
Source: arXiv:2602.07936 · Published 2026-02-08 · By Tasnia Ashrafi Heya, Sayed Erfan Arefin
TL;DR
This paper tackles a very specific but important gap: wearable gesture systems are often treated as UX or sensing problems, yet in covert or safety-critical use they can become privacy liabilities because raw motion traces, intermediate features, and model outputs can leak intent, behavior, or identity. The authors propose an end-to-end covert communication pipeline in which smartwatch gesture recognition is performed directly over encrypted motion features, so neither raw sensor signals nor learned representations are exposed to untrusted infrastructure. They frame the threat as broader than eavesdropping on packets: the adversary may observe stored ciphertexts, network traffic, repeated executions, and even compromised infrastructure, but should never see plaintext motion, features, or labels.
The main novelty is combining encrypted inference with a gesture-based covert communication protocol and practical feedback channels for message retrieval. The system uses pause-delimited gesture windows, extracts a 96-dimensional feature vector from gyroscope data, and runs a homomorphic / MPC-style neural pipeline with CrypTen-compatible components. On data from 9 smartwatch users and 600 gesture instances (the abstract reports 600; the experimental section explicitly details 540 gesture instances from 9 users × 15 repetitions × 4 gestures, so the full-count provenance is slightly inconsistent in the text), the paper reports over 94.44% classification accuracy and argues the approach is deployable on both server-class and edge devices such as Jetson Nano / Orin. The paper’s core claim is not just accuracy, but that this accuracy is achieved while preserving privacy by construction in an adversarial setting.
Key findings
- The system reports over 94.44% classification accuracy for encrypted gesture recognition on commodity smartwatch data, despite operating on protected representations rather than plaintext motion signals.
- The data collection section states 9 users performed 15 repetitions of 4 gesture symbols (A, B, C, E), which would yield 540 gesture instances; the abstract instead says 600 gesture samples, so the paper’s sample-count reporting is inconsistent.
- The final gesture vocabulary was reduced to {A, B, C, E} after exploratory clustering with K-means (K=4), because these symbols were consistently separated across users while visually similar symbols (e.g., D vs B) were frequently confused.
- The feature extractor produces 32 features per inertial axis and 96 features total per gesture instance (X/Y/Z gyroscope axes), combining temporal and spectral statistics rather than end-to-end raw-sequence modeling.
- The system explicitly avoids exposing raw sensor streams, intermediate features, and classification outputs to third parties; all three remain encrypted/end-to-end protected in the proposed architecture.
- The paper evaluates deployment across heterogeneous compute environments, including NVIDIA Jetson Nano and Jetson Orin, in addition to traditional server systems, to argue practical feasibility under edge constraints.
- Temporal segmentation uses opening and closing pauses as delimiters; the paper argues this reduces leakage of message boundaries and length compared with continuous inference over unsegmented streams.
Threat model
The adversary is an untrusted or compromised infrastructure operator, network observer, or insider who can see traffic, stored ciphertexts, and potentially intermediate system artifacts if they were exposed. They may attempt inference, replay, profiling, or model-state inspection, and they may control the server-side compute environment used for recognition. The system assumes the adversary does not possess the recipient’s private key and therefore cannot decrypt gesture features or outputs; it also assumes the user-controlled endpoints are trustworthy enough to perform local encryption/decryption and feedback rendering.
Methodology — deep read
Threat model and assumptions: the paper assumes an untrusted or honest-but-curious-to-active infrastructure layer between sender and receiver, including smartphones, servers, cloud/edge compute, and network links. The attacker may observe ciphertext traffic, replay sensor traces, infer from intermediate model states if exposed, or leverage insider access to decrypted data; the design goal is that none of these parties can access raw sensor signals, engineered features, intermediate activations, or final predictions in plaintext. The system is also positioned against replay and profiling attacks on wearable motion data. The authors explicitly contrast their approach with TEEs, arguing that hardware trust assumptions and side-channel exposure are undesirable; instead they prefer cryptographic isolation via HE/MPC. What the adversary cannot do, by design, is see plaintext motion data at any stage outside the user-controlled endpoints.
Data provenance and preprocessing: data were collected under IRB approval from 9 participants wearing a Fossil Gen 6 smartwatch on the dominant wrist. The smartwatch sampled tri-axial accelerometer and gyroscope data at 60 Hz and transmitted it over Bluetooth to a paired smartphone for logging. The paper’s final experimental protocol uses a compact gesture alphabet of four symbols, {A, B, C, E}, selected after an exploratory study. That study first considered a broader set of alphanumeric-like symbols and used visual inspection plus K-means clustering (K=4) over extracted feature space to identify symbols with strong between-class separability; Table 1 reports that A, B, C, and E were the most stable clusters across users, while visually similar symbols were prone to confusion. The paper states each participant performed 15 repetitions of the four symbols, implying 540 labeled gesture instances, but the abstract mentions 600 samples; no reconciliation is provided. Gestures were performed naturally, with variation in speed, intensity, and wrist posture. The traces include both motion segments and inter-gesture pauses, and the pauses are used as boundary cues for temporal segmentation.
Architecture and algorithm: the system is organized into three modules. The Information Sending Module captures gesture motion on the smartwatch, sends it to the paired smartphone, applies lightweight preprocessing consistent with the trained model input, and immediately encrypts the resulting feature vector with a receiver-authorized homomorphic encryption public key. The Prediction Module receives encrypted features and runs a homomorphic neural network (HNN) / multi-party encrypted computation pipeline using CrypTen. The text says CrypTen supports arithmetic operations (addition, subtraction, multiplication, division, matrix operations, and limited nonlinear transforms) through MPC with lattice-based backends, fixed-point arithmetic, and secret sharing; the paper also walks through BGV-style encryption, key generation, encryption, and decryption equations, although in practice CrypTen is described as combining MPC with leveled HE rather than relying on pure HE alone. The Information Receiving Module decrypts the encrypted prediction on the recipient’s smartwatch and renders the result through covert feedback channels (haptic or visual). The gesture communication protocol is modeled as a finite-state machine: idle, active, and closed/reset. A pause of duration approximately t1 activates the channel, gesture symbols are recognized in the active state, and a closing pause of duration approximately t2 terminates the session. This pause-delimited structure is meant to make segmentation robust while also bounding inference complexity and reducing observable timing leakage.
Training regime and one concrete example: the paper’s feature extraction uses 32 features per axis over the segmented window, yielding a 96-dimensional vector per gesture. These include temporal statistics such as mean, standard deviation, interquartile range, absolute energy, skewness, kurtosis, sample entropy, longest-strike-above/below-mean, and complexity-invariant distance, plus spectral features such as centroid, flatness, kurtosis, skewness, decrease, spread, rolloff, and slope. The text does not fully specify the HNN architecture in the provided excerpt, but it indicates that the model is built from HE-compatible operations and trained/evaluated in both plaintext and encrypted modes to enable direct comparison. The paper discusses fixed-point encoding for approximate real-valued computation and mentions secure multiplication via Beaver triples, suggesting the encrypted pipeline is implemented as a practical MPC/HE hybrid rather than a pure cryptosystem toy example. As a concrete end-to-end example: a user performs gesture A after an opening pause; the smartphone segments the motion window between opening and closing pauses, extracts the 96-D feature vector, encrypts it, sends ciphertexts to the compute node (server or Jetson), the HNN performs inference on encrypted values, the decrypted label is returned to the recipient device, and the recipient receives it via discreet haptic or visual cue. The paper does not provide the exact optimizer, batch size, epoch count, random seed strategy, or full hyperparameter table in the excerpt, so those details are not recoverable here.
Evaluation protocol and reproducibility: evaluation is framed around classification accuracy and deployment feasibility under encrypted execution, with additional plots mentioned in the figure captions comparing ROC curves and training loss for a general neural network versus a homomorphic neural network on different devices. The paper claims over 94% accuracy and says it evaluates on high-performance systems and resource-constrained edge devices (Jetson Nano, Jetson Orin), but the excerpt does not include a full baseline table or ablation study details. There is no evidence in the excerpt of cross-validation folds, held-out attacker evaluation, statistical significance tests, or explicit distribution-shift tests beyond the natural inter-user variability in the collected dataset. Reproducibility is partially limited by the truncated text: the paper mentions concrete libraries (CrypTen, HElib, SEAL, Gloo, NCCL, cuBLAS, cuDNN) and device classes, but the excerpt does not state whether code or frozen weights are released. The paper does, however, provide enough methodological detail to reconstruct the sensing pipeline, feature set, segmentation logic, and high-level encrypted inference design.
Technical innovations
- Applies multi-party homomorphic / encrypted gesture recognition to a wearable covert-communication setting, rather than to a generic ML benchmark.
- Uses pause-delimited wrist-motion segmentation as part of the privacy story, not just as a signal-processing convenience, to bound inference windows and reduce observable metadata leakage.
- Combines encrypted inference with covert recipient-side feedback channels (haptic and visual) so the communication path stays discreet end to end.
- Evaluates feasibility on commodity smartwatches plus edge devices (Jetson Nano / Orin), aiming for deployment under constrained compute rather than only cloud settings.
Datasets
- Wearable gesture dataset — 540 labeled gesture instances reported from 9 users × 15 repetitions × 4 symbols; abstract says 600 samples — collected by the authors on a Fossil Gen 6 smartwatch (non-public in excerpt)
Baselines vs proposed
- General neural network: ROC / training loss compared against homomorphic neural network, but the excerpt does not provide the numeric ROC AUC or loss values.
- Plaintext gesture recognition: classification accuracy is reported as over 94.44% for the encrypted system, but the excerpt does not provide the plaintext comparator accuracy.
- Device comparison (server vs Jetson Nano vs Jetson Orin): the paper states it evaluates across these platforms, but the excerpt does not give per-device latency or accuracy numbers.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.07936.
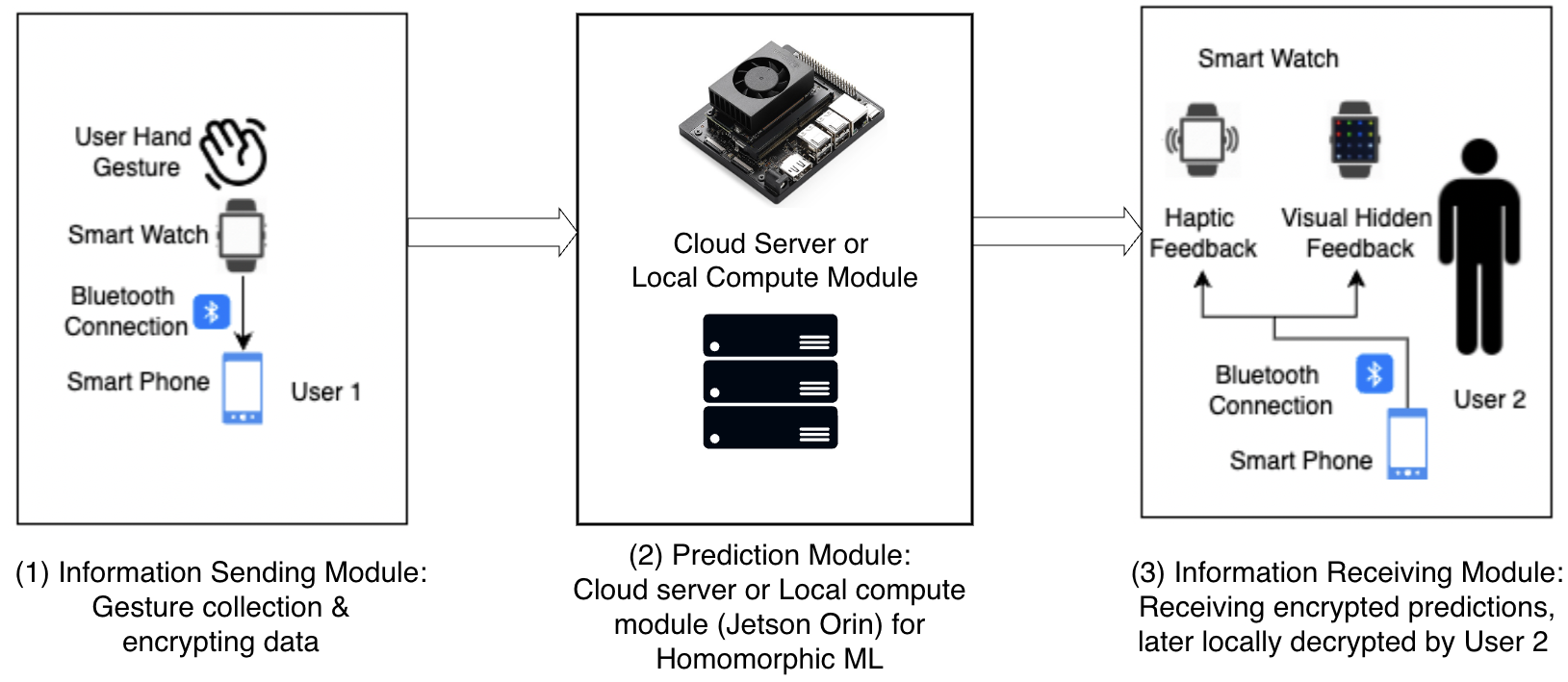
Fig 1: System overview.
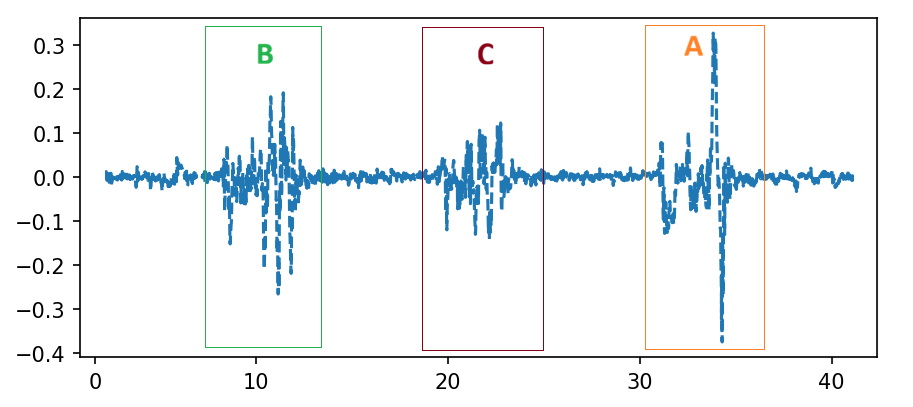
Fig 2: Example of temporal segmentation on a continuous wrist-motion stream. Highlighted
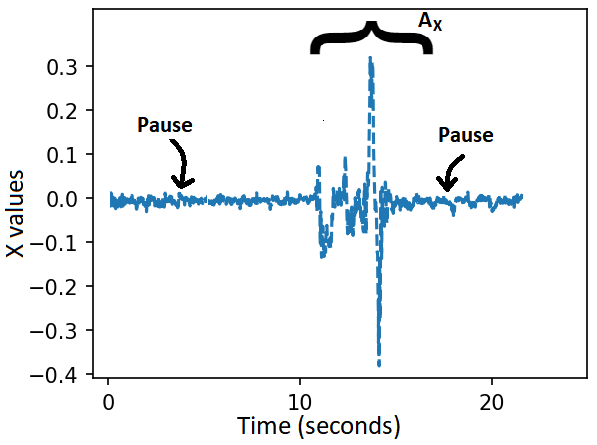
Fig 3: State-machine model for temporally segmented gesture communication. Opening and
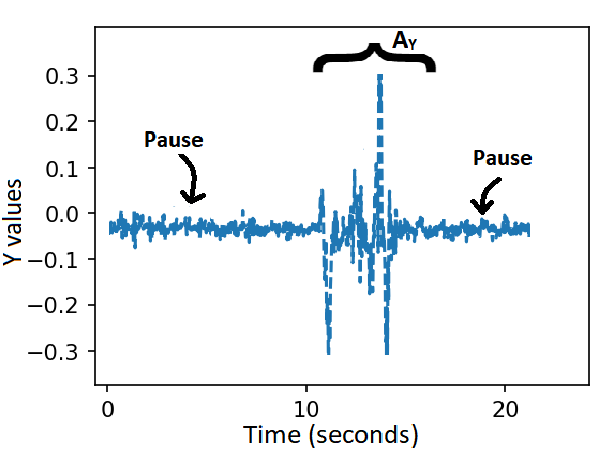
Fig 4: Example wrist-motion gyroscope traces illustrating the temporal segmentation protocol.
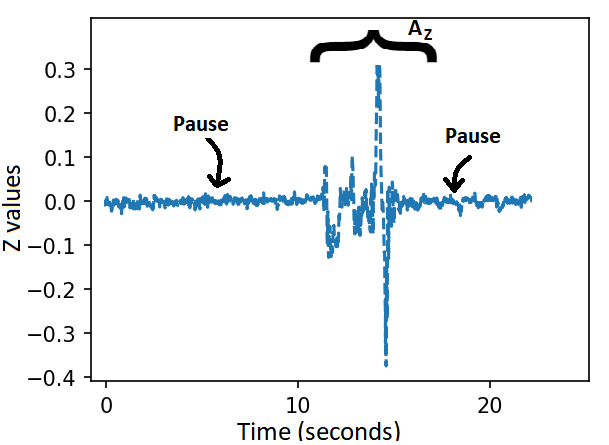
Fig 5 (page 9).
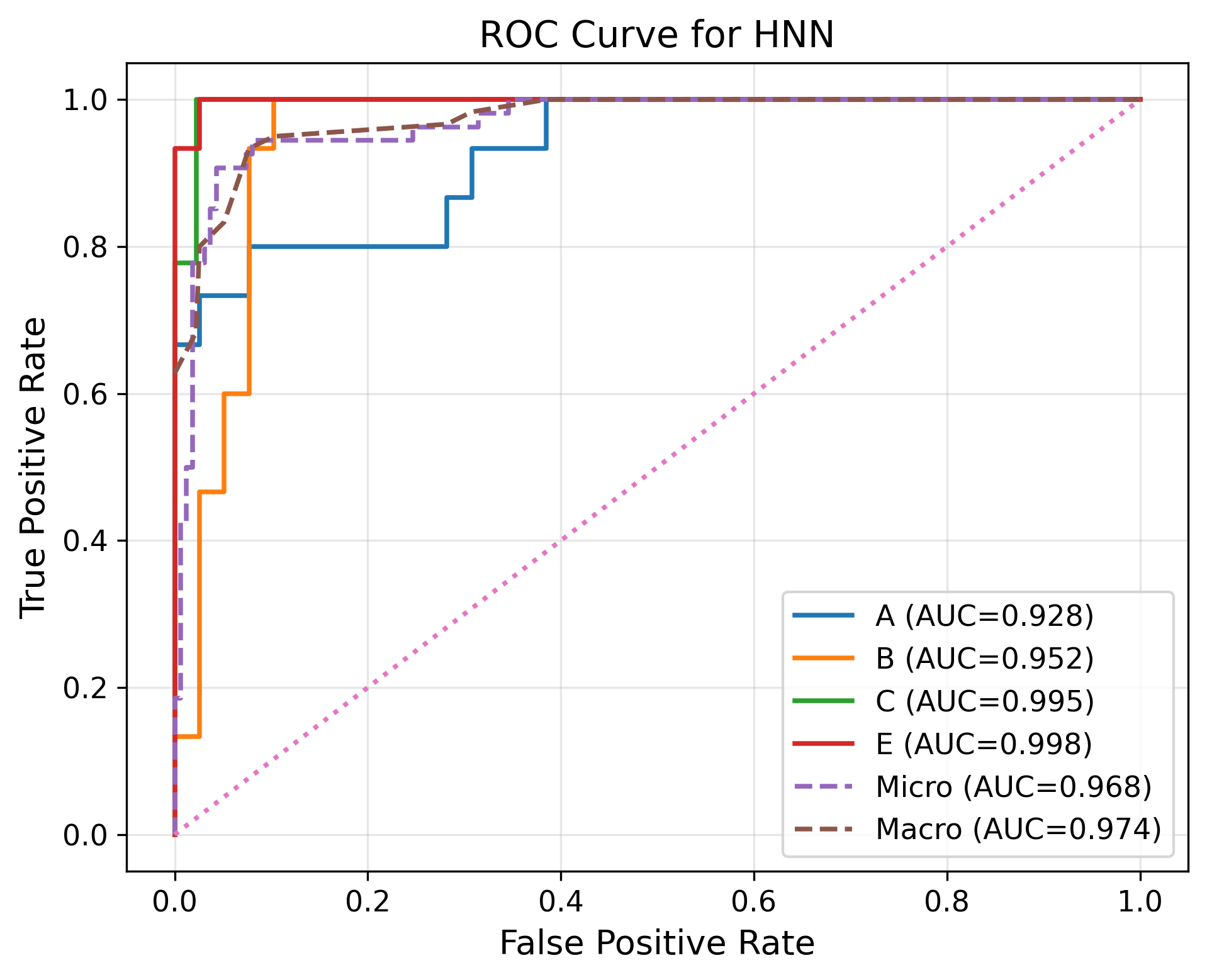
Fig 5: ROC curve of general neural network trained on different devices
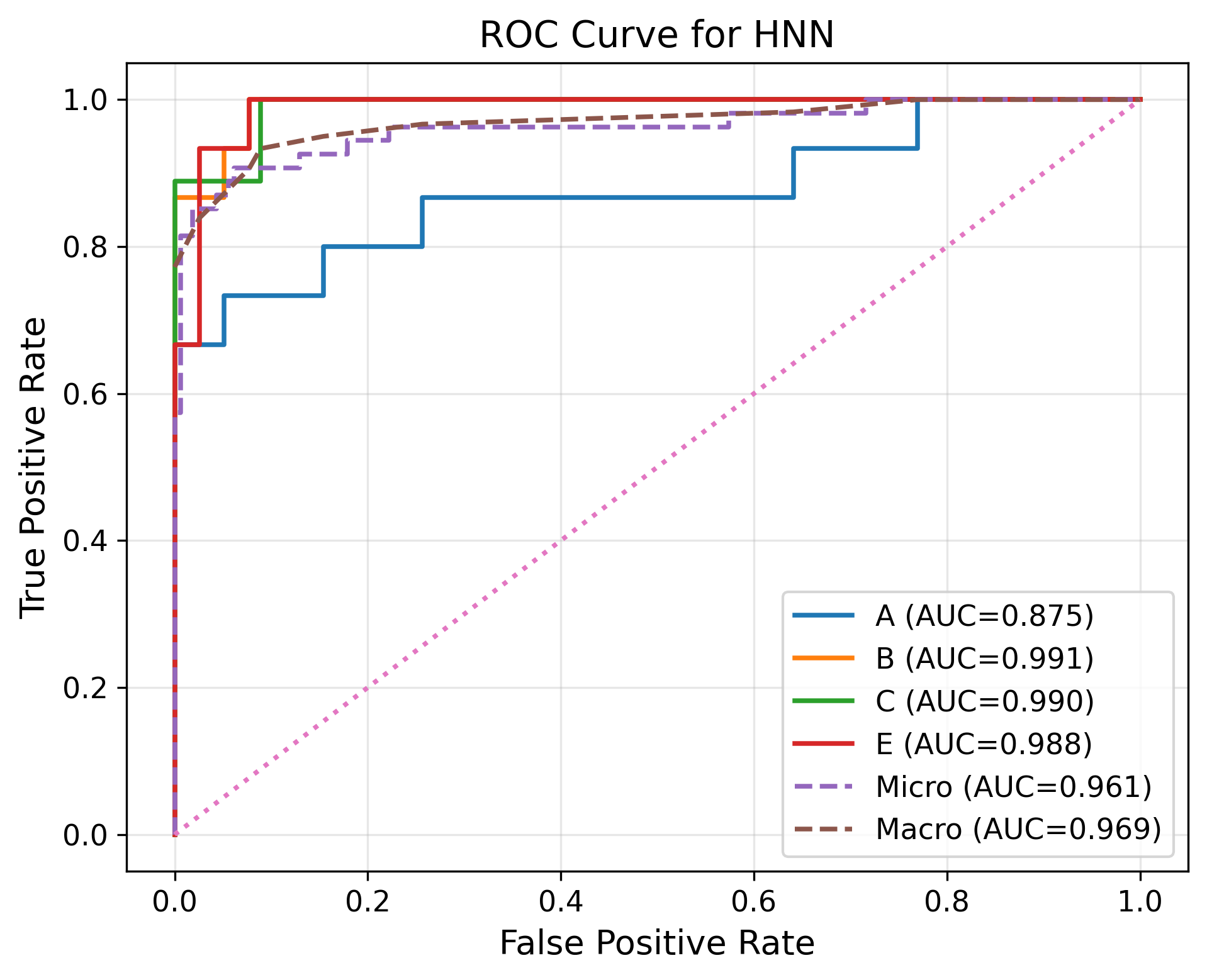
Fig 6: ROC curve of homomorphic neural network trained on different devices
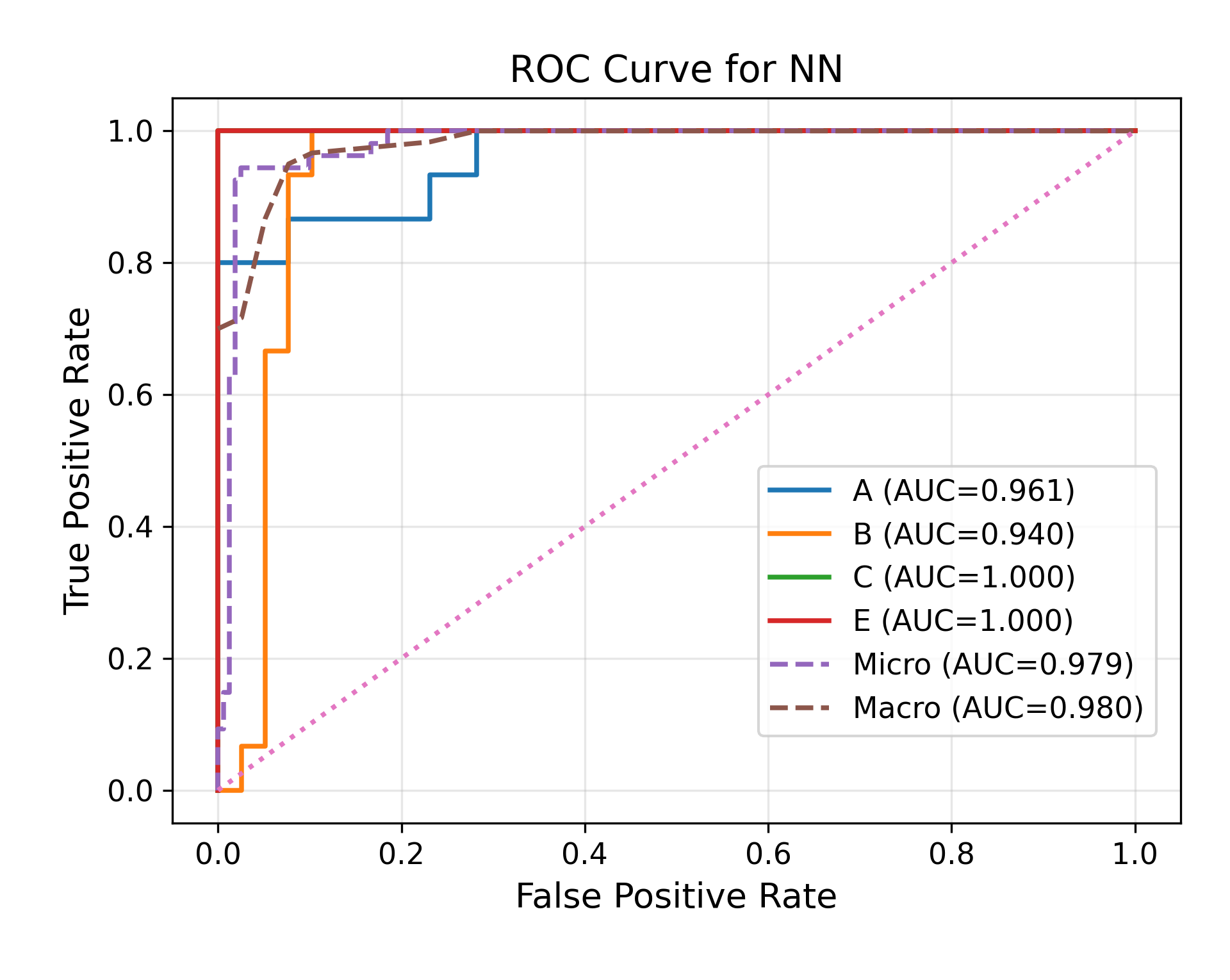
Fig 7: Comparison of training loss of General Neural Network and Homo Morphic Neural
Limitations
- The sample-count reporting is inconsistent: the abstract says 600 gesture samples, while the data-collection arithmetic in the body implies 540 instances.
- The excerpt does not provide the full HNN architecture, optimizer, epochs, batch size, or hyperparameter choices, making reproduction incomplete from the provided text alone.
- There is no clearly reported held-out attacker evaluation, replay-test protocol, or distribution-shift benchmark in the excerpt, despite those threats being central to the motivation.
- The gesture vocabulary is very small ({A, B, C, E}), so the reported accuracy may not extrapolate to richer command sets or longer message sequences.
- Encrypted inference typically incurs overhead, but the excerpt does not provide latency, throughput, or energy numbers in the same place as the accuracy claim, so practicality is only partially quantified.
- The work appears to rely on user-specific gesture modeling and natural pause patterns; robustness to new users, more diverse motion styles, or noisy real-world environments is not fully established in the excerpt.
Open questions / follow-ons
- How much latency and energy overhead does the encrypted pipeline add relative to plaintext gesture recognition on the same smartwatch-to-edge path?
- Can the pause-based segmentation scheme be attacked through timing, duration, or motion-style side channels even if all payloads are encrypted?
- Would the approach still work for larger vocabularies, continuous command streams, or multi-symbol messages beyond the small {A, B, C, E} set?
- How does the model behave under cross-user transfer, unseen motion styles, or adversarially crafted gestures intended to trigger misclassification?
Why it matters for bot defense
For bot-defense practitioners, the main lesson is architectural: if gesture-based authentication or covert human signaling is used in an untrusted pipeline, protecting only the raw sensor payload is not enough, because features and outputs can still leak intent or identity. This paper treats the recognition stack itself as sensitive and pushes encryption through the feature-extraction and inference stages. That mindset maps directly to CAPTCHA or bot-detection systems that use behavioral biometrics, touch dynamics, or wearable signals: if the verifier, a cloud service, or a device relay is untrusted, the feature pipeline may become a privacy leak even when the final decision is small.
A second practical takeaway is that segmentation and interaction design can be security-relevant. The authors deliberately use pause-delimited windows and a very small, low-effort gesture vocabulary to reduce both usability burden and leakage from timing/length metadata. For CAPTCHA-adjacent systems, that suggests that the choice of interaction protocol—when a session starts, how long it lasts, how many actions are visible, and what metadata is exposed—can matter as much as the classifier. If a bot-defense system relies on wearable or gesture-derived signals, one should ask whether an attacker can replay traces, infer labels from intermediate features, or exploit boundary cues even if the classifier output itself is protected.
Cite
@article{arxiv2602_07936,
title={ Privacy-Preserving Covert Communication Using Encrypted Wearable Gesture Recognition },
author={ Tasnia Ashrafi Heya and Sayed Erfan Arefin },
journal={arXiv preprint arXiv:2602.07936},
year={ 2026 },
url={https://arxiv.org/abs/2602.07936}
}