
SocialPulse: An Open-Source Subreddit Sensemaking Toolkit
Source: arXiv:2602.07248 · Published 2026-02-06 · By Stephanie Birkelbach, Maria Teleki, Peter Carragher, Xiangjue Dong, Nehul Bhatnagar, James Caverlee
TL;DR
SocialPulse is an open-source, interactive toolkit for exploratory analysis of Reddit communities that combines topic modeling, sentiment analysis, user-activity characterization, and optional bot detection in one workflow. The paper’s core problem is not building a new standalone model; it is reducing the fragmentation of current social-media sensemaking workflows, which often force researchers to bounce between separate scripts and closed tools. SocialPulse is positioned as a practical system for moving from aggregate patterns to post-level inspection, and from single-subreddit analysis to cross-subreddit comparison.
What is new here is the integration: the toolkit ties together Reddit ingestion, BotBuster-based bot filtering, BERTopic topic discovery, VADER sentiment scoring, LLM-assisted topic labeling/summarization, and a Flask dashboard for interactive drill-down. The authors illustrate the system with a case study on r/conspiracy (compared with r/politics) showing how the interface surfaces topic diversity, temporal activity patterns, sentiment differences, and content duplication across communities. The main result is a reusable open-source pipeline and a demo workflow; the paper reports exploratory findings from the case study rather than benchmark-style performance gains.
Key findings
- SocialPulse unifies four analysis stages—data ingestion, optional bot filtration, analytical modeling, and interactive visualization—into a single pipeline for Reddit sensemaking.
- In the r/conspiracy case study over the week of 1/4/26, BERTopic identified 20 distinct topics with “a high degree of thematic diversity,” and the authors report most topics were well-separated with little overlap.
- The case study’s sentiment counts for r/conspiracy were 421 negative posts, 140 neutral posts, and 336 positive posts, indicating a slight negative skew.
- Posting activity in r/conspiracy peaked on Saturdays and was lowest on Mondays; the highest hourly volume occurred from 15:00–16:00 UTC.
- Topic 0 in r/conspiracy had largely neutral topic-level sentiment (score = 0.47), while current-event topics were described as more negative and more unstable over time.
- A cross-subreddit comparison between r/conspiracy and r/politics found two shared users, two identical external links, and multiple duplicated posts; the duplicated posts were all about current events.
- The authors state there were more social spammers in r/conspiracy than in r/politics, based on BotBuster outputs, but they do not report a numeric bot-detection metric in the paper text provided.
- The toolkit is open-source and released with code at https://github.com/birkelbachs/SocialPulse, but the paper does not report quantitative runtime, accuracy, or usability comparisons against prior tools.
Threat model
The main adversary is an automated or semi-automated account that posts or amplifies content in public Reddit communities and may distort exploratory analysis. SocialPulse assumes the analyst can collect public Reddit data, apply BotBuster scores, and optionally exclude high-probability bots before interpretation, but it does not assume the attacker is observable in advance or that bot scores are perfect. The system does not claim resistance to adaptive bot behavior, coordinated human campaigns, or adversarial text crafted to fool BERTopic or VADER.
Methodology — deep read
Threat model and assumptions: SocialPulse is framed as an exploratory analytics tool, not a defense system. The relevant adversary in the bot-filtration component is an automated or semi-automated account amplifying content on Reddit; the system assumes users may want to identify and optionally remove such accounts before analysis. The paper also assumes a human analyst who wants to study public Reddit discourse across one or more subreddits, compare communities, and inspect both high-activity and long-tail participants. The system does not claim to defeat adaptive adversaries, and the paper does not describe any red-team evaluation of bot evasion or prompt injection against the LLM-assisted parts. In practice, the strongest assumption is that public Reddit API data and BotBuster scores are sufficiently reliable for exploratory filtering, while the final interpretation remains human-driven.
Data provenance and collection: data come from the Reddit API, with user-specified subreddits and either a fixed number of posts or a time-bounded collection window. The system supports Best/Hot/Recent sorting categories, which means the collected sample can be tuned toward high-traffic communities or long-tail communities depending on the research question. The paper does not provide a corpus-wide dataset size, exact number of subreddits used in the demo, or a train/test split, because the toolkit is presented as a reusable system rather than a fixed benchmark dataset. In the case study, the authors analyze r/conspiracy over the week of 1/4/26 and compare it with r/politics; the case-study counts that are explicitly reported are the 20 BERTopic topics and the sentiment totals (421 negative, 140 neutral, 336 positive). Preprocessing details are only partially specified: the system ingests posts, comments, and metadata, then optionally filters out likely bots before topic modeling and sentiment analysis. There is no mention of text normalization beyond what is implied by BERTopic/VADER defaults.
Architecture and algorithm: the pipeline has four sequential modules. First, Data Ingestion uses Reddit API retrieval based on subreddit selection and collection strategy. Second, Bot Filtration is optional and uses BotBuster, described as a mixture-of-experts neural network that consumes user metadata and posting behavior to estimate bot probability; the user can set a minimum threshold for flagging accounts. Third, the Analytical Engine combines (a) BERTopic, which in its standard form uses Sentence-BERT embeddings plus HDBSCAN clustering and c-TF-IDF topic representation, (b) LLM tooling, specifically gpt-4.1-mini per Table 2, to refine topic labels and summarize complex threads, (c) VADER for polarity scoring of posts/comments, and (d) cross-community comparison for shared themes, duplicate posts, and overlapping users. Fourth, the Flask-based dashboard exposes interactive views for exploratory topic analysis, sentiment-over-time, topic-specific drill-down, and cross-subreddit side-by-side comparison. The paper emphasizes configurability: users can adjust BERTopic hyperparameters, bot thresholds, subreddit sets, and data-collection mode. One concrete end-to-end example from the case study: a researcher selects r/conspiracy for the week of 1/4/26, optionally filters bots, runs BERTopic to extract 20 topics, views the topic map in the dashboard, inspects Topic 0 where aggregate sentiment is 0.47, then compares those results to r/politics and sees overlapping users and duplicated current-event links.
Training regime and implementation: because this is primarily a toolkit/demo paper, there is no end-to-end supervised training loop reported for SocialPulse itself. BERTopic and BotBuster are used as pre-existing components, and the paper does not specify epochs, batch size, optimizer, random seed strategy, or GPU hardware for any custom model training. LLM assistance is performed via gpt-4.1-mini, but the paper does not report prompts, decoding settings, temperature, or cost. The implementation stack listed in Table 2 is practical rather than research-experimental: Reddit API for collection, BotBuster for bot scoring, BERTopic for topic modeling, VADER for sentiment, Flask for the web app. This means reproducibility depends mostly on the open-source codebase and the behavior of external components, not on a fixed training recipe authored in the paper.
Evaluation protocol and reproducibility: the paper does not present controlled offline evaluation with labeled ground truth, cross-validation, or statistical tests. Instead, evaluation is primarily a qualitative case study demonstrating exploratory workflows and the kinds of insights the dashboard exposes. The case study reports descriptive outputs: 20 topics in r/conspiracy, topic-level sentiment patterns, day-of-week/hour-of-day activity variation, and cross-subreddit duplication. It also notes more social spammers in r/conspiracy than r/politics, but does not give precision/recall or ROC-AUC for bot detection. There are no ablation studies isolating the contribution of bot filtering, LLM labeling, or the dashboard UI. Reproducibility is reasonably strong at the software level because the code is public on GitHub, but the paper does not provide frozen weights, a released curated dataset, or a fully specified containerized environment. The main empirical claims are therefore best read as demonstration outputs from a specific exploratory run, not as benchmarked performance claims.
Technical innovations
- An integrated Reddit sensemaking pipeline that combines topic modeling, sentiment, bot filtering, and cross-subreddit comparison in one interactive system rather than scattering them across separate tools.
- Configurable optional bot filtration via BotBuster before downstream discourse analysis, which is meant to reduce distortion from automated amplification.
- LLM-assisted topic refinement and higher-level thread summarization layered on top of BERTopic to improve interpretability of discovered topics.
- Interactive drill-down from aggregate topic/sentiment summaries to individual posts and comments, plus side-by-side community comparison in the dashboard.
Datasets
- Reddit public subreddit data — size not reported — Reddit API
- r/conspiracy case-study slice (week of 1/4/26) — size not reported — Reddit API
- r/politics comparison slice — size not reported — Reddit API
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.07248.
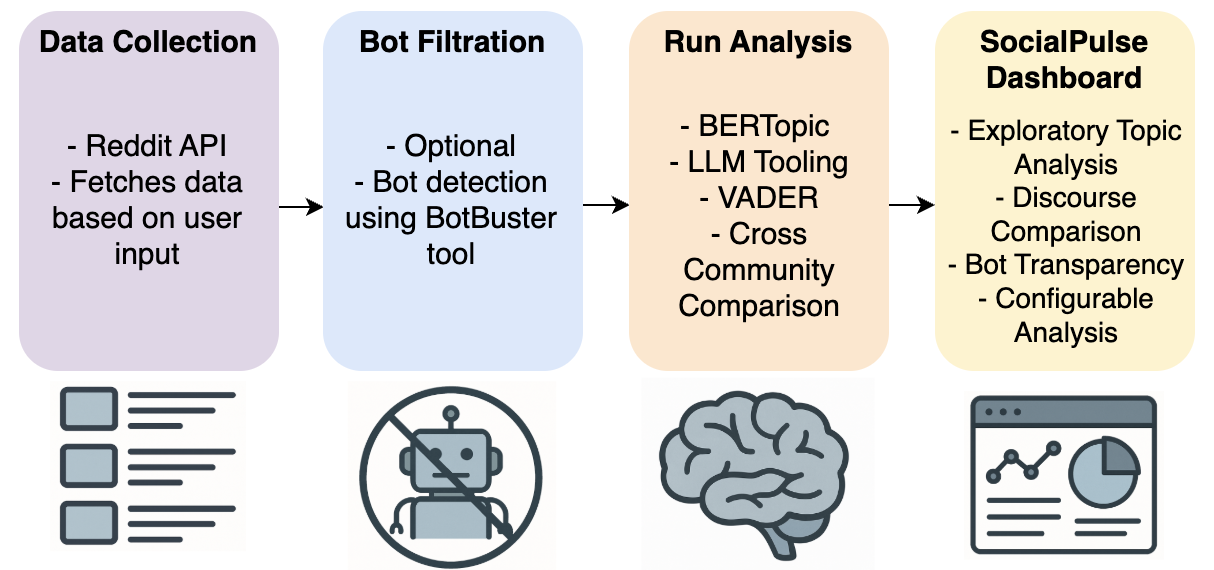
Fig 1: The SocialPulse pipeline supports rapid ex-
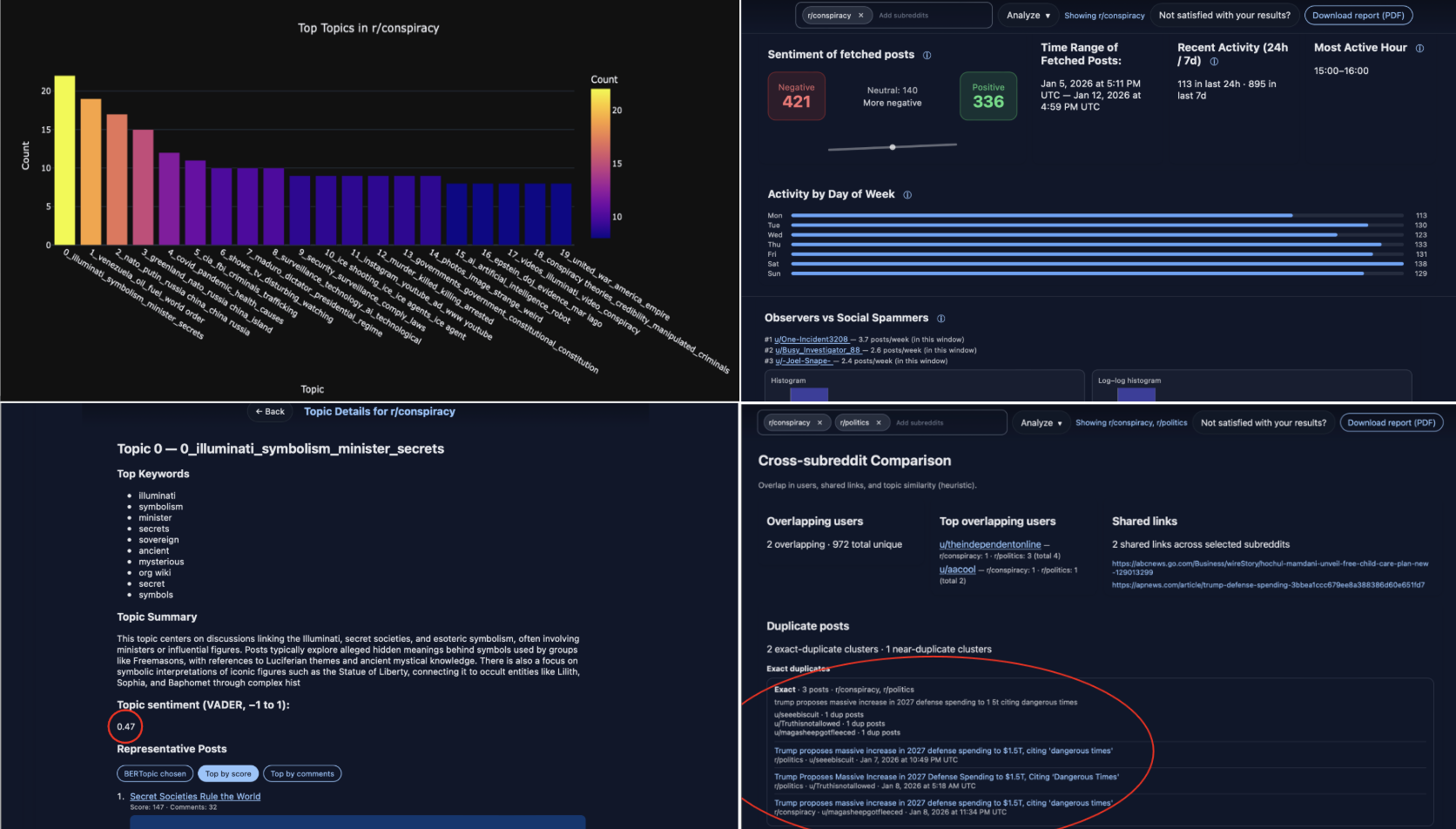
Fig 2: The SocialPulse analytics interface supports rapid, multi-level sensemaking of Reddit discourse. The interface
Limitations
- No quantitative benchmark against prior tools or alternative pipelines; the paper is a demo/system paper, so claims are mostly qualitative.
- No reported dataset size, exact subreddit list beyond the case study, or full preprocessing details, which makes replication of the demo outputs hard to audit.
- No offline evaluation for bot detection, topic quality, or sentiment accuracy; the paper relies on pre-existing tools without measuring end-task performance in this setting.
- No ablation study showing how much value each module adds (bot filtration vs. BERTopic vs. LLM labels vs. dashboard).
- The case study is limited to one subreddit pair and one reported week, so generalization to other communities or longer time ranges is untested.
- Potential bias from Reddit API collection mode (Best/Hot/Recent, fixed-size vs. time window) is acknowledged implicitly, but not systematically analyzed.
Open questions / follow-ons
- How robust is the pipeline to adaptive bots and coordinated campaigns that change language, timing, or metadata to evade BotBuster?
- What is the impact of Reddit sampling mode (Best/Hot/Recent vs. time-windowed collection) on topic distributions and cross-subreddit overlap findings?
- Can the LLM-assisted topic-labeling step be evaluated for consistency, faithfulness, and bias across different communities and sensitive domains?
- How well does SocialPulse work outside Reddit’s nested-comment structure, and what components need redesign for other platforms?
Why it matters for bot defense
For bot-defense practitioners, SocialPulse is useful mainly as an analyst-facing triage and investigation layer rather than a detection engine. It shows a pattern that often matters in operational anti-abuse work: combining automated scoring with human-inspectable drill-down across topics, time, and communities. That makes it easier to understand whether suspected bots are concentrated around particular narratives, whether activity spikes align with real events, and whether content is being duplicated across communities.
For CAPTCHA or bot-mitigation teams, the biggest practical takeaway is that aggregate-level bot prevalence is not enough; participation structure and discourse context matter. A tool like this can help identify where automated activity is concentrated, what content is being amplified, and whether a community’s apparent sentiment or topical mix is being skewed by a long-tail of low-volume accounts or by a smaller set of high-activity users. The limitation is that SocialPulse depends on post hoc analysis of public data, so it complements but does not replace live prevention or challenge-based controls.
Cite
@article{arxiv2602_07248,
title={ SocialPulse: An Open-Source Subreddit Sensemaking Toolkit },
author={ Stephanie Birkelbach and Maria Teleki and Peter Carragher and Xiangjue Dong and Nehul Bhatnagar and James Caverlee },
journal={arXiv preprint arXiv:2602.07248},
year={ 2026 },
url={https://arxiv.org/abs/2602.07248}
}