
TaSA: Two-Phased Deep Predictive Learning of Tactile Sensory Attenuation for Improving In-Grasp Manipulation
Source: arXiv:2602.05468 · Published 2026-02-05 · By Pranav Ponnivalavan, Satoshi Funabashi, Alexander Schmitz, Tetsuya Ogata, Shigeki Sugano
TL;DR
TaSA tackles a very specific but important failure mode in tactile manipulation: when a dexterous hand has to tell the difference between its own fingers/palm touching each other and the object actually contacting the environment. The paper’s core claim is that if you do not model self-touch explicitly, the tactile stream becomes ambiguous and policies can mistake self-collision for task completion, especially in insertion-style tasks where forces are small and contact patterns are similar. The proposed remedy is a two-stage predictive framework inspired by sensory attenuation: first learn a forward model of self-touch from hand configuration, then feed that predicted self-touch into a recurrent motion policy so the controller can attenuate predictable self-generated signals and focus on object contact.
Empirically, the authors test this on an Allegro Hand with uSkin tactile sensors on the index and thumb, using teleoperated data and three precision insertion tasks: paper clip fixing, coin insertion, and pencil lead insertion. The paper reports that adding predicted self-touch to raw tactile input substantially improves success on all three tasks, with especially large gains on the hardest pencil-lead setting. The strongest results are the unseen-position generalization cases: middle-slot paper clip fixing and coin insertion both reach 100% success with RT+Self, while raw tactile baselines stay materially lower. The authors also show that predicted self-touch tracks measured self-contact closely on held-out episodes, with correlations around 0.96 (thumb) and 0.98 (index), and they use PCA plots to argue that augmenting raw tactile with self-touch produces cleaner class separation in feature space.
Key findings
- Self-touch prediction on held-out episodes tracks measured tactile self-contact with reported correlations of r ≈ 0.96 for the thumb tip and r ≈ 0.98 for the index tip (Fig. 7).
- In paper clip fixing, raw tactile only reaches 42/60 = 70% success, while RT+Self reaches 57/60 = 95% (Table VI).
- In paper clip fixing, the unseen middle placement is solved perfectly with RT+Self: 10/10 for both big and small clips, versus 8/10 and 8/10 under RT only (Table VI).
- In coin insertion, raw tactile only achieves 61/90 = 68% success, while RT+Self achieves 83/90 = 92% (Table VII).
- In coin insertion, the held-out middle slot is 10/10 for all three coin types under RT+Self, versus 7/10 for each coin type under RT only (Table VII).
- In pencil-lead insertion, raw tactile only reaches 66/250 = 26% success, while RT+Self reaches 146/250 = 58% (Table VIII).
- For the hardest pencil-lead conditions, RT+Self improves the 0.7 mm lead from 0/10 at -20° to 3/10, and the 2.0 mm lead from 3/10 to 7/10 at -20° (Table VIII).
- The self-touch learning phase was trained on 200 teleoperated episodes sampled at 10 Hz with 400 time steps each, collected from random index-thumb motions spanning light grazing to sustained contact.
Methodology — deep read
TaSA is explicitly a two-phase predictive control pipeline. The threat or failure mode it addresses is not an external adversary in the cybersecurity sense, but a perception/control ambiguity: when a robot hand touches itself during manipulation, the tactile stream mixes self-generated signals with object-induced signals, and a policy trained on raw tactile alone can misread self-contact as successful object interaction or stable grasping. The paper assumes a dexterous hand with sufficient tactile resolution to observe these distinctions, and that self-touch can be learned from hand configuration without needing object context. In the manipulation phase, the model assumes access to current joint positions, commanded joint positions, and raw tactile signals; the self-touch model is frozen and reused as a differentiable forward model. There is no explicit adversarial setting, no attacker model, and no discussion of malicious perturbations.
Data collection is split into a self-touch dataset and task-specific manipulation datasets. For self-touch, the authors collect 200 episodes of random index-thumb motions at 10 Hz, each 400 time steps long, covering open pinch, closed pinch, and rubbing-like self-contact. These are recorded on an Allegro Hand with eight active joints used in the model context (4 index, 4 thumb) and uSkin tactile sensors mounted on the index and thumb fingertips; each fingertip sensor has 30 taxels and each taxel measures tri-axial force, so the tactile vector is 60 taxels × 3 axes. The paper states that training in this phase uses only free-space or self-contact motions, so every tactile observation corresponds to self-touch rather than object contact. For manipulation, they use teleoperated demonstrations through a leader-follower setup (human-operated Dynamixel leader, transmitted to the Allegro Hand via U2D2). The paper defines condition splits per task: paper clips are trained on front/back placements and tested on middle; coins are trained on left/right and tested on middle; pencil leads are trained on extreme angles (-20°, 0°, +20°) and tested on intermediate angles (-10°, +10°). The paper reports 10 trials per condition in each task table, but does not specify a separate train/validation/test split beyond these held-out condition sets.
The architecture is also two-stage. In the self-touch learning phase, the model is a fully connected network (FCN) that maps current joint position q_t plus previous commanded joint position q^cmd_{t-1} to predicted self-touch tactile state. The text gives a hidden dimension of 128 with GELU activations and dropout 0.2. Table I specifies an encoder-decoder style layout: Linear(16→64) → GELU → Dropout(0.2), then Linear(64→128) → GELU, followed by a decoder with Linear(128→64) → GELU and Linear(64→188) → GELU. The output is decomposed into predicted tactile for index and thumb tips (90 each, presumably 30 taxels × 3 axes per fingertip) and an auxiliary joint-state prediction of dimension 8. One inconsistency in the paper is that the input description in the prose says the FCN receives q_t and q^{des}_{t-1}, while Table I names the inputs as q_t and q^{cmd}_t; the exact variable naming is therefore a bit unclear, but the intended input is plainly the robot’s joint configuration and intended motion command.
In the motion learning phase, the recurrent model receives x_t = [q_t, \hat{s}t, T_t], where \hat{s}t is the predicted self-touch from the frozen FCN and T_t is the raw tactile sensor output. An LSTMCell with hidden dimension 100 processes these inputs over time. The decoder then predicts three things: next joint configuration \hat{q}, desired joint configuration \hat{q}^{des}t (or q^{cmd} in the table notation), and predicted raw tactile \hat{T}. The predicted posture and desired posture are fed back into the frozen self-touch FCN to generate \hat{s}{t+1} = f_st(\hat{q}, \hat{q}^{des}_t), making the self-touch model a differentiable forward model inside the recurrent rollout. This is the central novelty: the network is not just concatenating another tactile channel, but using a learned predictive model of self-contact to reconstruct the tactile consequences of the robot’s own motion, with the hope that the remaining discrepancy emphasizes object contact. The baseline comparator is an otherwise similar recurrent model that uses raw tactile plus q_t only (RT only / t-rnn), versus the proposed RT + Self / st-rnn.
Training details are partially specified. For self-touch prediction, the authors use Adam, batch size 100, learning rate 0.001, 20,000 epochs, and train on an NVIDIA GeForce RTX 4070 GPU. For the motion-learning insertion tasks, they use batch size 300, learning rate 0.001, and 6,000 epochs; the paper does not explicitly name the optimizer here, but the surrounding text implies standard gradient-based training and likely the same Adam-family setup, though that is not clearly stated. No random seed strategy, early stopping criterion, or learning-rate schedule is reported. Hardware is clearly stated for data collection and execution: an Allegro Hand, XELA Robotics uSkin sensors, a Dynamixel-based teleoperation leader, and a ROBOTIS U2D2 servo board. The paper also notes the uSkin taxel spacing is about 6.5 mm, which matters because the sensor is fine enough to resolve finger-finger versus object contact patterns at fingertip scale.
Evaluation is two-tiered: first, self-touch prediction quality is assessed on held-out episodes by comparing predicted and measured self-contact traces, and second, task success is measured on the three insertion tasks using 10 trials per condition. The paper reports per-condition success tables rather than averaged metrics like F1, precision, or mean contact error. The self-touch results are visualized in Fig. 7 as time-series overlays; the authors claim the prediction error stays near zero during sustained self-contact, with spikes during rapid transitions or re-grasp events. They interpret those spikes as useful because they signal unexpected changes. For downstream task evaluation, the paper uses success rate only, with tables showing raw counts and percentages (Tables VI–VIII). There is also a PCA feature-space analysis in Fig. 8 comparing “Case A” raw tactile versus “Case B” tactile plus predicted self-touch, to show that the augmented representation reduces overlap between conditions and tightens clusters. There is no mention of statistical significance testing, confidence intervals, or multiple-seed variance, so the reported deltas should be treated as single-run or at least non-parametric summary evidence rather than statistically validated effect sizes.
A concrete end-to-end example is the paper clip task. Suppose the hand approaches a front-position paper clip: in the raw tactile-only baseline, finger-finger contact during grasp/preload can look very similar to clip-paper completion, so the policy can prematurely declare success or execute a slightly wrong motion. Under TaSA, the FCN first predicts what tactile forces should arise purely from the hand’s own joint configuration and self-contact. The LSTM then receives both the raw tactile stream and that predicted self-touch signal, so self-generated contacts are attenuated in the learned representation. The reported outcome is that RT only succeeds 42/60 overall, while RT+Self succeeds 57/60, with the test middle position improving to 10/10 for both clip sizes. The same mechanism is claimed to carry over to coins and pencil leads, where subtle lateral or angular misalignments otherwise make self-contact and object contact nearly indistinguishable.
Reproducibility is mixed. The paper provides useful architecture tables, task splits, sensor hardware, and training hyperparameters, which makes the system reasonably reimplementable in principle. However, it does not mention code release, dataset release, frozen weights, or whether demonstrations are available publicly. There are also some notational inconsistencies between prose and tables for the self-touch inputs/outputs, and the truncation of the paper text means some implementation specifics may be omitted from the source excerpt. The reported evidence is nonetheless concrete enough to understand the method and its empirical behavior, but not enough to fully replicate without additional details from the authors.
Technical innovations
- Introduces a two-phase sensory-attenuation pipeline that first learns a forward model of self-touch and then injects that prediction into a recurrent manipulation policy, rather than treating all tactile input as undifferentiated contact.
- Uses a frozen self-touch FCN as a differentiable internal model during motion learning, so the recurrent network can explicitly reconstruct and attenuate predictable self-generated tactile signals.
- Applies the approach to contact-ambiguous insertion tasks where finger-finger and finger-object contacts are visually and tactually confusable, showing a clear benefit over raw-tactile-only recurrent baselines.
- Frames self-touch disambiguation as a manipulation representation problem rather than purely a contact estimation problem, and supports this with PCA feature-space analysis (Fig. 8).
Datasets
- Self-touch teleoperation dataset — 200 episodes × 400 timesteps at 10 Hz — collected on Allegro Hand with uSkin sensors during random index-thumb motions
- Paper clip fixing dataset — 60 trials total per method (2 clip sizes × 3 positions × 10 trials) — collected by the authors on a teleoperated Allegro Hand
- Coin insertion dataset — 90 trials total per method (3 coin sizes × 3 slots × 10 trials) — collected by the authors using a 3D-printed slot
- Pencil lead insertion dataset — 250 trials total per method (5 lead diameters × 5 angles × 10 trials) — collected by the authors on a mechanical drafting pencil setup
Baselines vs proposed
- Self-touch prediction (thumb tip): correlation with measured self-touch r ≈ 0.96 vs predicted error near zero during sustained contact (Fig. 7a)
- Self-touch prediction (index tip): correlation with measured self-touch r ≈ 0.98 vs predicted error near zero during sustained contact (Fig. 7b)
- Paper clip fixing, RT only: success = 42/60 = 70% vs RT+Self: 57/60 = 95% (Table VI)
- Coin insertion, RT only: success = 61/90 = 68% vs RT+Self: 83/90 = 92% (Table VII)
- Pencil-lead insertion, RT only: success = 66/250 = 26% vs RT+Self: 146/250 = 58% (Table VIII)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.05468.
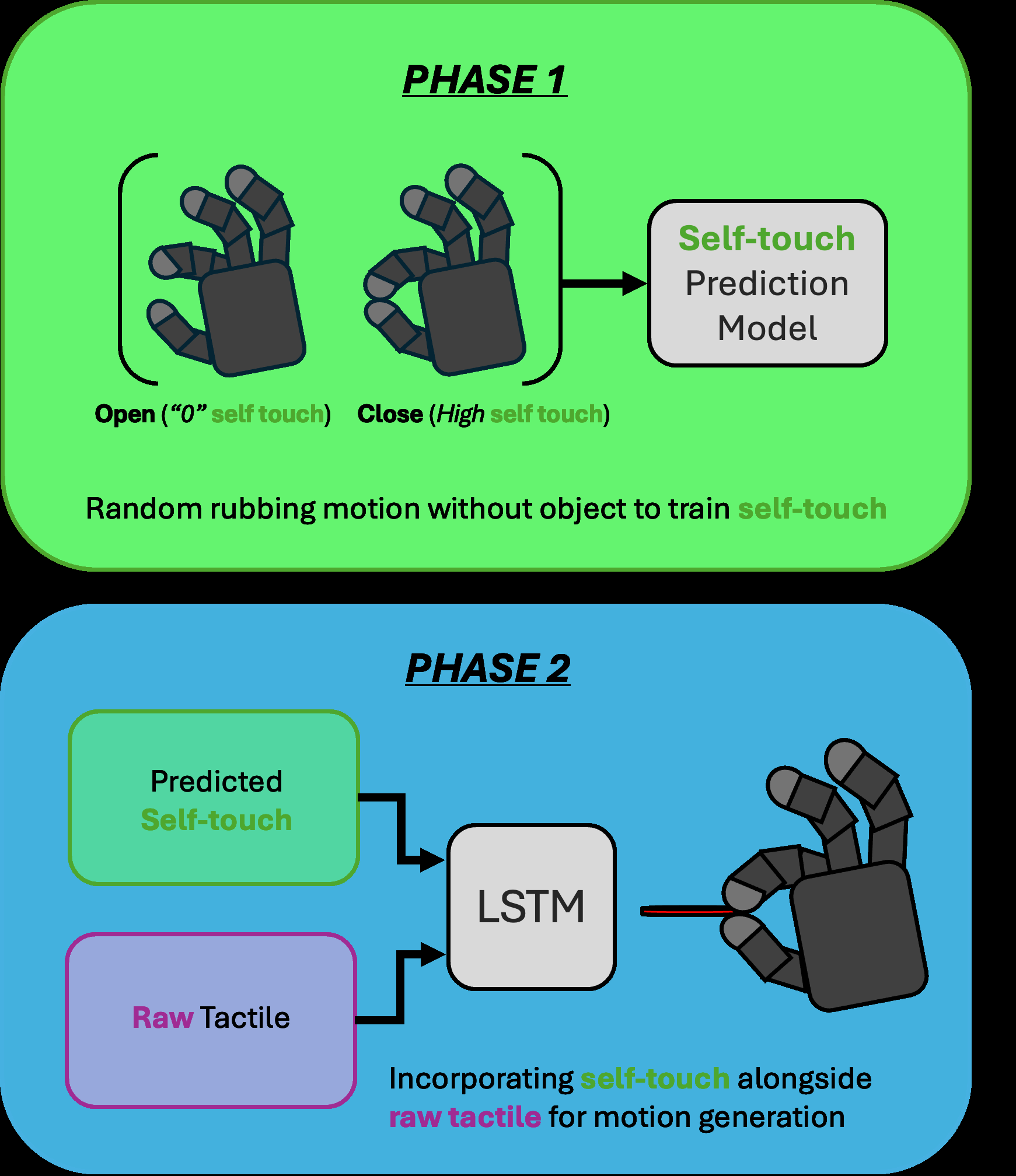
Fig 1: Diagrammatic representation of TaSA - the proposed two-phased
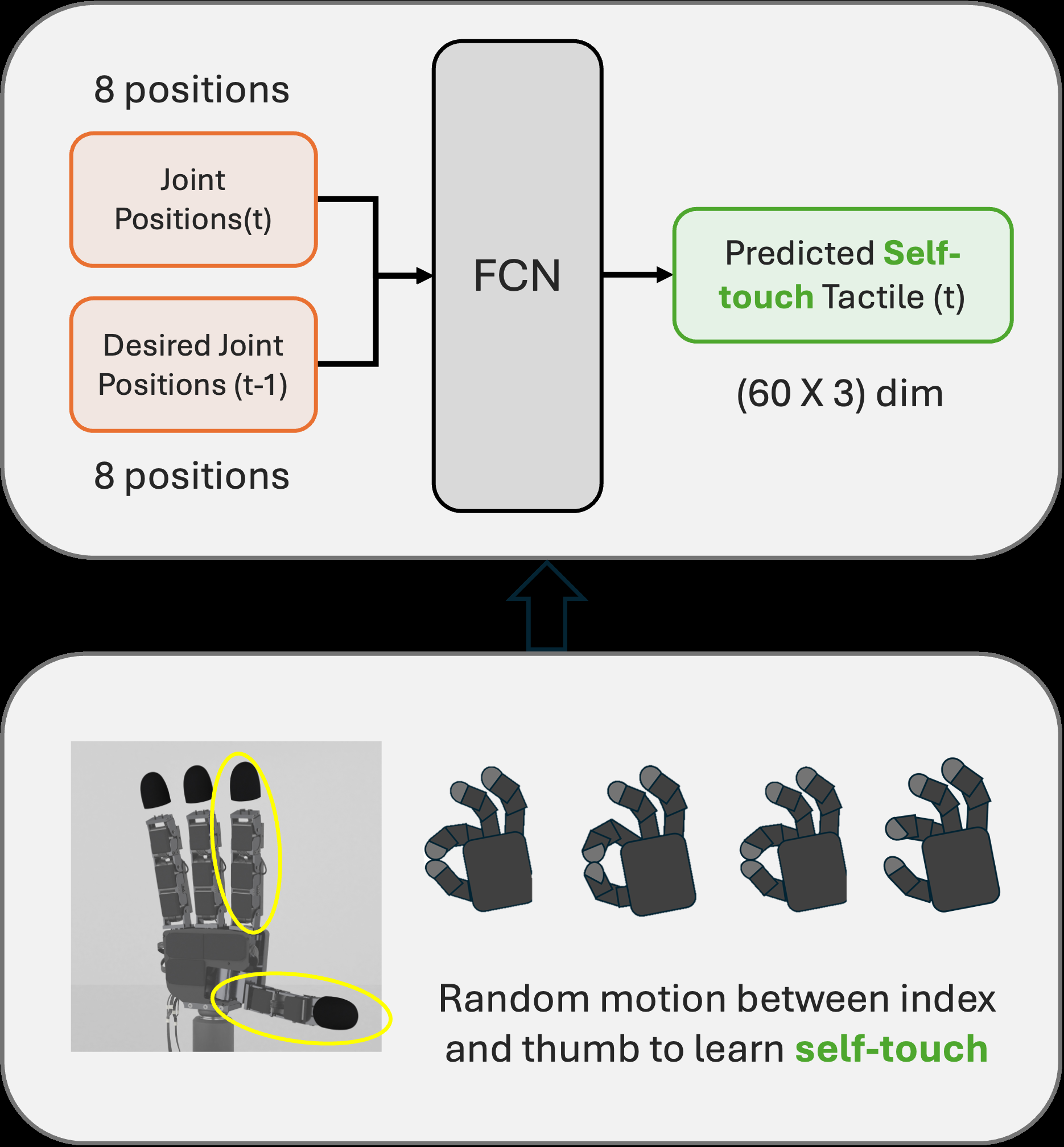
Fig 2: Diagrammatic representation of the self-touch learning phase with
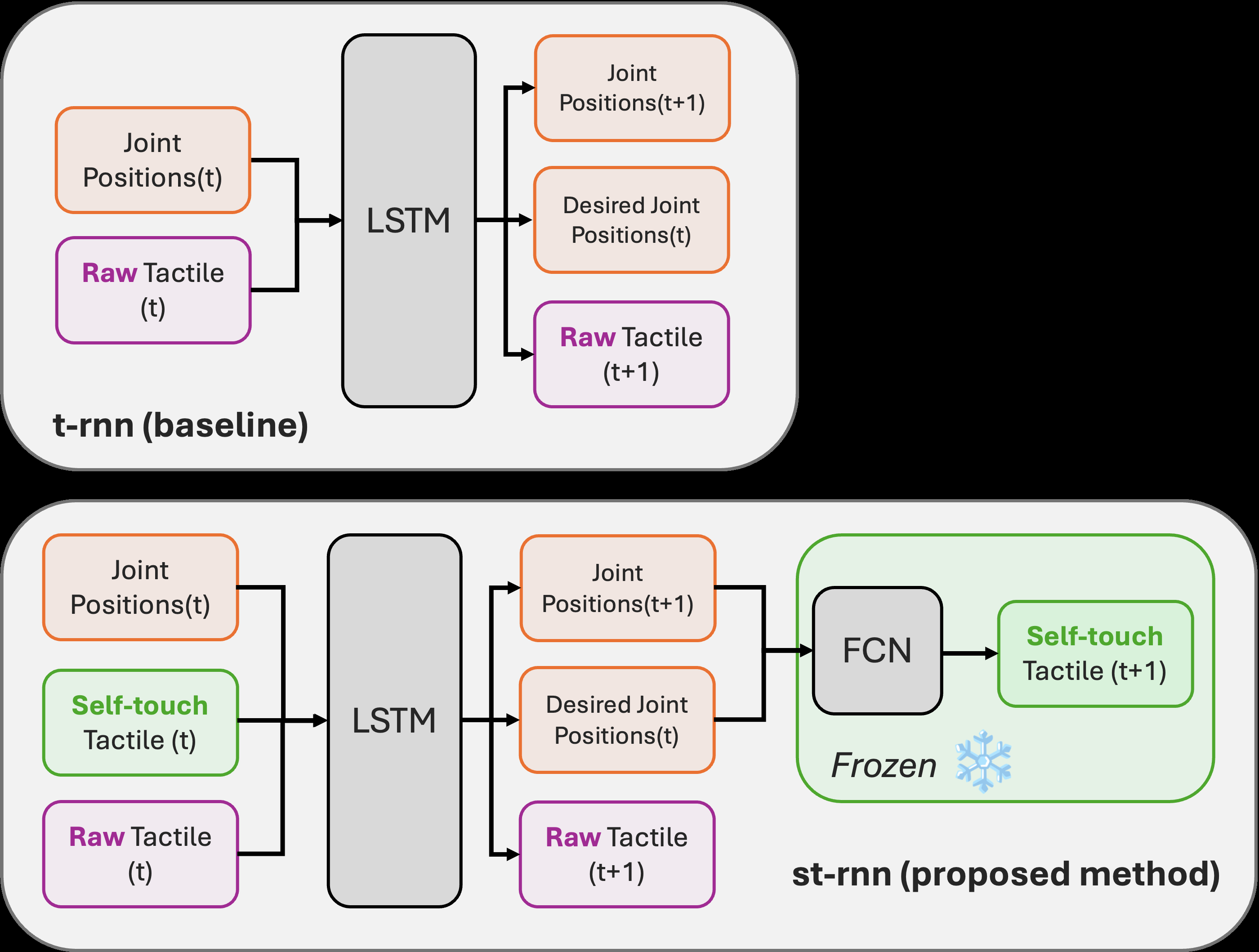
Fig 3: Comparison of the proposed method that uses both raw tactile and

Fig 4: Diagrammatic representation of successful motion of the three tasks

Fig 5: Diagrammatic representation of the setup: We teleoperate the Allegro
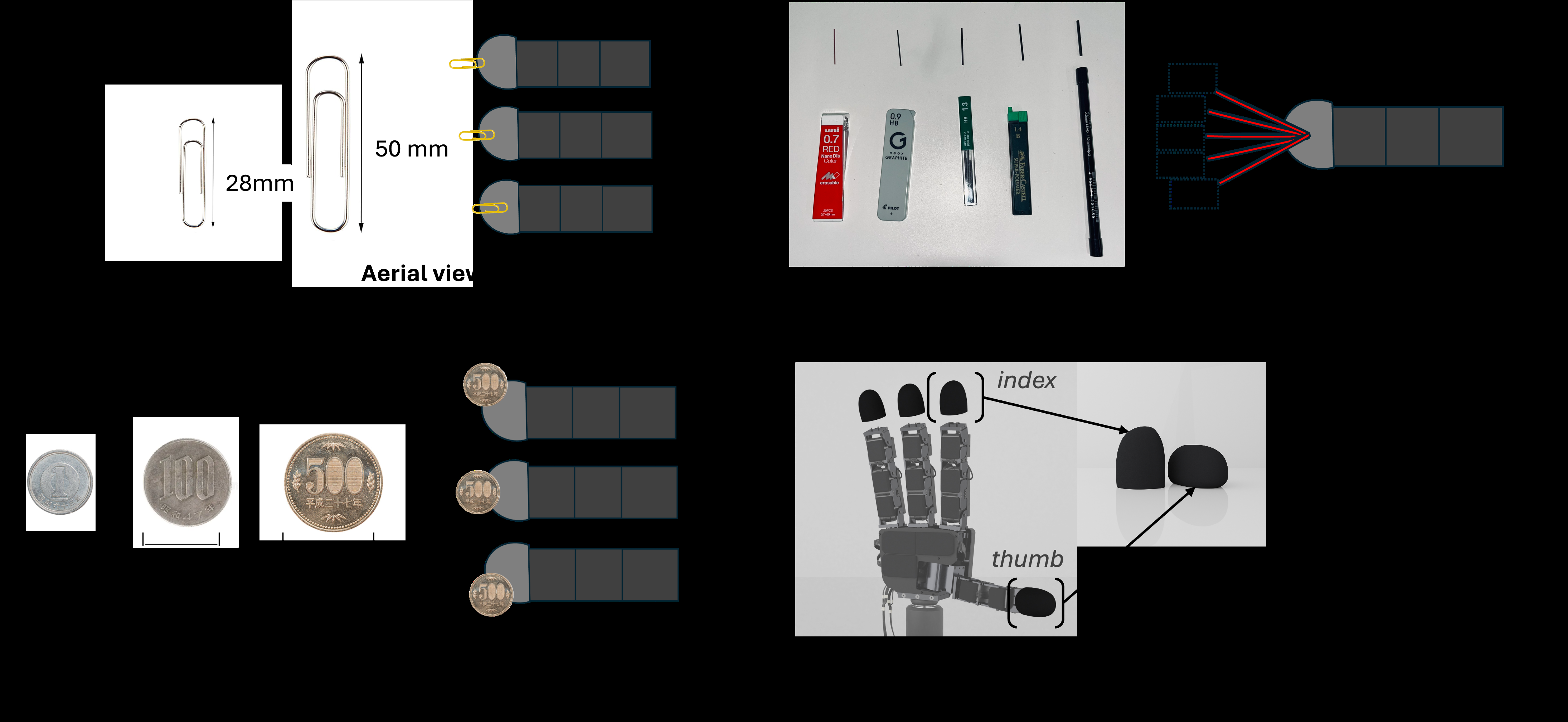
Fig 6: Diagrammatic representation of the material’s size and orientations
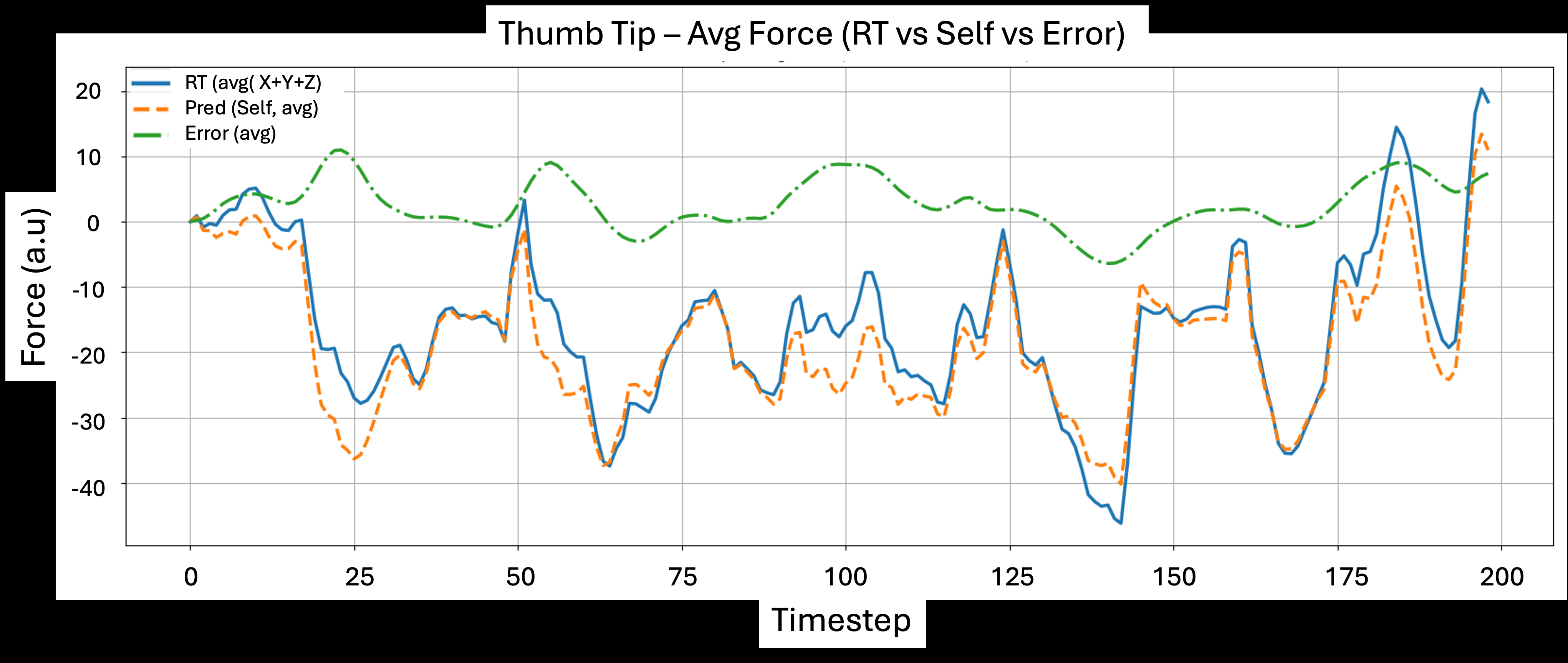
Fig 7: Self-touch prediction on test episodes. During sustained finger–finger contact the error stays near zero; spikes appear around rapid transitions and
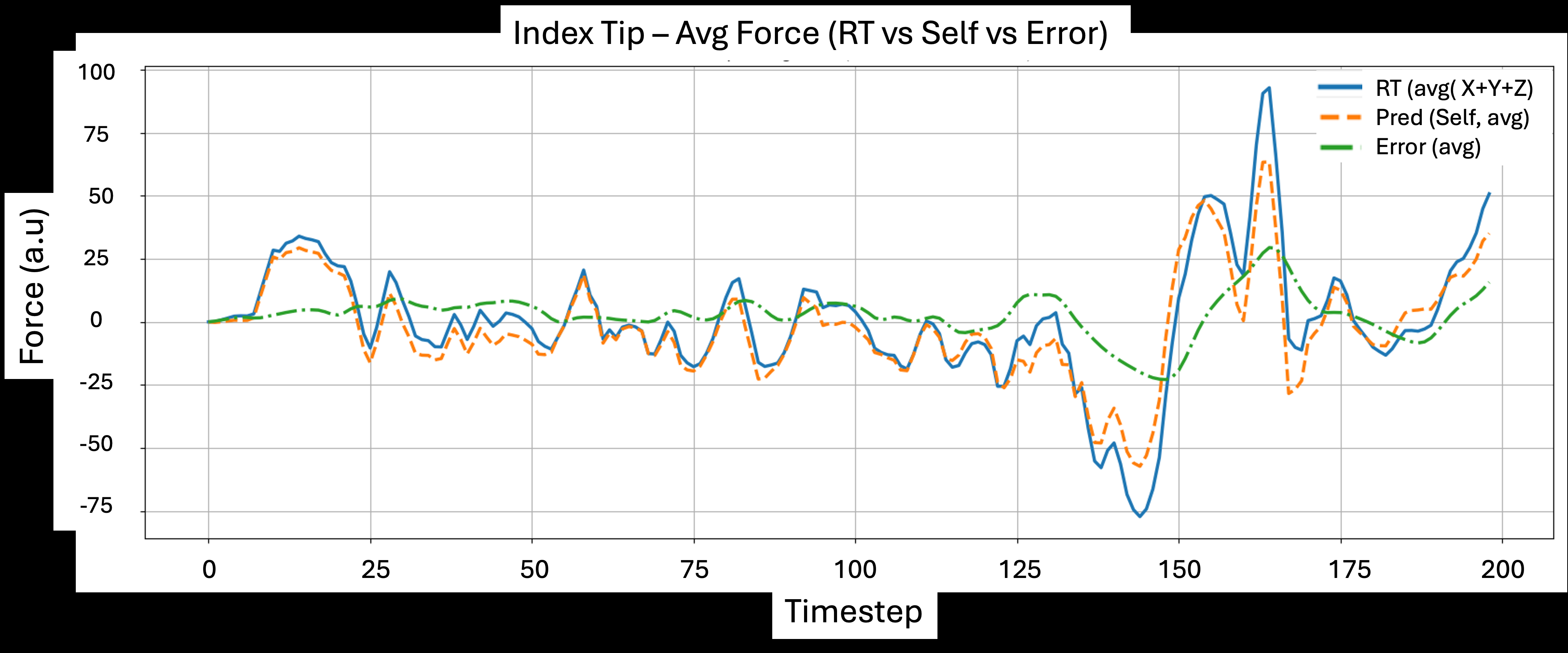
Fig 8: PCA feature–space comparison at the initial step for three tasks (paper clip, coins, lead) under two conditions: (Case A) RAW RT and (Case B) RT
Limitations
- The paper does not report confidence intervals, statistical significance tests, or multi-seed variance, so the robustness of the gains is unclear.
- Evaluation is limited to two-finger (index-thumb) self-touch; the authors explicitly note multi-finger and finger-palm extensions as future work.
- The method is trained and tested on a single hand platform (Allegro Hand with uSkin fingertips), so portability to other hands/sensor layouts is not demonstrated.
- There is no public code or dataset release mentioned in the excerpt, which limits reproducibility.
- The self-touch learning description has minor notation inconsistencies between prose and Table I (q^{des} vs q^{cmd}), which makes exact implementation details slightly ambiguous.
- The paper focuses on held-out geometry/position conditions but does not test under broader distribution shifts such as wear, sensor drift, or noisy latency perturbations.
Open questions / follow-ons
- Can the same attenuation idea scale to 5-finger or whole-hand manipulation where self-contact combinatorics explode and many contacts occur simultaneously?
- Would a richer decomposition of tactile space into self-touch, object touch, and environment touch outperform the current two-way separation?
- How sensitive is the learned attenuation to sensor latency, hand calibration error, and drift in tactile baselines over long deployments?
- Could the self-touch forward model be trained jointly with the policy end-to-end without losing the clean separation that seems to help here?
Why it matters for bot defense
For a bot-defense engineer, the main takeaway is architectural rather than domain-specific: TaSA shows how an explicit predictive model of a confounding signal can improve downstream decision-making when raw observations mix multiple causes. In CAPTCHA or behavioral bot detection, the analogous problem is not self-touch but separating predictable user-driven patterns from task-relevant anomalies. The method suggests a useful design pattern: first learn a forward model of expected behavior under normal action, then feed the residual or attenuated representation into the detector or policy. The caution is that this only helps when the confound is structured and learnable; if the nuisance signal is highly variable or adversarially manipulated, a learned attenuation model may be brittle unless it is validated under distribution shift and spoofing conditions.
Cite
@article{arxiv2602_05468,
title={ TaSA: Two-Phased Deep Predictive Learning of Tactile Sensory Attenuation for Improving In-Grasp Manipulation },
author={ Pranav Ponnivalavan and Satoshi Funabashi and Alexander Schmitz and Tetsuya Ogata and Shigeki Sugano },
journal={arXiv preprint arXiv:2602.05468},
year={ 2026 },
url={https://arxiv.org/abs/2602.05468}
}