
FATe of Bots: Ethical Considerations of Social Bot Detection
Source: arXiv:2602.05200 · Published 2026-02-05 · By Lynnette Hui Xian Ng, Ethan Pan, Michael Miller Yoder, Kathleen M. Carley
TL;DR
This paper addresses the important and understudied topic of the ethical considerations in social media bot detection. While social bots have well-documented negative impacts on online information ecosystems, the algorithms designed to detect these bots operate within complex socio-technical systems with human users, varying cultural norms, and evolving bot behaviors. The authors apply the FATe framework—focusing on Fairness, Accountability, and Transparency—to examine ethical challenges in social bot detection across three pillars: training datasets, algorithm development, and bot usage. Through a mixed-methods approach combining a comprehensive literature survey, empirical evaluation of bot detection performance across language groups, and qualitative analysis of user misclassification experiences, they reveal significant ethical blind spots such as dataset bias toward English and Twitter/X, disproportionate false positives, and opaque platform policies. The paper culminates in a set of concrete recommendations to diversify datasets, improve accountability mechanisms (such as appeal processes), and enhance transparency of bot classification and use definitions. Their work advances an agenda for more responsible and equitable deployment of social bot detection systems at scale.
Key findings
- 94.2% (48/51) of surveyed bot detection algorithms are trained on datasets collected from Twitter/X, with only 5% (3/51) trained on platforms like Reddit, Instagram, or TikTok.
- 84.3% (43/51) of training datasets contain posts primarily in English, showing strong language imbalance.
- Bot detection algorithms including BotBuster perform significantly worse on non-English language users compared to English users across 19 labeled datasets (detailed metrics in Table 3).
- Only 16.7% (7/51) of detection systems are capable of classifying accounts beyond Twitter/X, indicating low cross-platform generalizability.
- Snowball and event-based sampling strategies used in training data collection produce topic- and network-centric datasets, leading to overfitting to certain bot types (e.g., political) and underfitting others (e.g., health bots).
- User anecdotes from Reddit document frequent false positives where human users are mislabeled as bots, with low availability and clarity of appeals or recourse mechanisms.
- Platform policies regarding acceptable or malicious bot behavior are generally opaque and inconsistently communicated to users.
- Large language model-based bot detection methods still suffer from biases inherent in their training data, limiting fairness.
Threat model
The adversary is an automated social media bot creator aiming to manipulate information dissemination and evade detection by bot classifiers. Adversaries may adapt bot behaviors to cause false classification or remain undetected. The defender is the platform and researchers deploying detection algorithms. The model assumes no omniscient adversary but acknowledges risk of algorithmic bias creating harms such as false positives mislabeling humans as bots. The defender does not control external institutions or full user recourse mechanisms.
Methodology — deep read
The authors employ a mixed-methods approach structured around the FATe framework:
Threat Model and Assumptions: The adversary includes malicious social media bots aiming to manipulate information and evade detection, as well as platform operators developing detection algorithms. The paper does not model an explicit attacker with full knowledge but considers risks like false positives and platform opacity as ethical challenges.
Data:
- Literature survey collected 51 bot detection algorithm papers spanning 2015-2024 via snowball sampling starting from a seminal paper "The Rise of the Social Bot". Papers were selected if they developed bot detection algorithms in English.
- Empirical evaluation used the BotBuster system trained on 87,056 users (primarily English) updated with a multilingual vector module in 2025. Evaluation leveraged 19 manually labeled datasets from the OSOME bot repository containing social media user accounts labeled “bot” or “human.” Language metadata from tweets determined English vs. non-English groups.
- Qualitative data was collected from Reddit threads mentioning misclassification as bots (top 20 threads from r/Instagram, r/Facebook, r/Twitter each) to understand user experiences with false positives and appeal processes.
- Platform policies on bot and automation usage were manually extracted and analyzed.
- Algorithm and Analysis:
- The BotBuster algorithm used supervised learning and was evaluated for accuracy and fairness across English and non-English users.
- Literature survey annotated platform focus, language distribution, algorithm type, and event context.
- Coding of Reddit anecdotes categorized misclassification occurrence, appeal options, and consequences.
Training Regime: Details about epochs, batch size, optimizers are not specified for BotBuster or surveyed models. The focus is on dataset composition and bias effects rather than training specifics.
Evaluation Protocol:
- Performance metrics compared BotBuster’s accuracy on English-posting users vs non-English users across 19 datasets.
- Survey compared distributions of training datasets in papers by platform, language, and event context.
- Anecdotal evidence analyzed user experiences qualitatively.
- Platform policy transparency and definitions of bot usage were assessed.
- Reproducibility: The bot detection datasets are publicly referenced (e.g., OSOME repository). The BotBuster algorithm is cited from previous literature but code release status is unclear. Dataset annotations of the literature survey are partially tabulated in the appendix.
Example: Applying BotBuster to a dataset from OSOME containing mixed English and Spanish tweets, the algorithm’s false negative rate was higher on Spanish-language users, reflecting language bias in the training data collected mostly from English tweets on Twitter/X.
Technical innovations
- Extension of the FATe (Fairness, Accountability, Transparency) ethics framework from general ML domains to the socio-technical domain of social bot detection with human and automated actors.
- Mixed-methods ethical analysis combining a large survey of bot detection literature, empirical evaluation across language groups using a multilingual algorithm, and qualitative study of real-world user misclassification experiences.
- Systematic identification of training data asymmetries in language, platform, and event context as ethical issues affecting bot detection fairness.
- Integration of user experience narratives from Reddit into algorithm accountability and transparency assessment.
Datasets
- OSOME bot repository — 19 manually labeled datasets of social media users flagged as bots or humans — public
- Surveyed papers’ bot detection datasets — 51 datasets sampled from 2015-2024 — mostly X (Twitter) platform and English language
Baselines vs proposed
- BotBuster accuracy on English tweets: higher compared to non-English tweets (exact metrics in Table 3, specific numbers not fully detailed in summary).
- Surveyed bot detection algorithms: 94.2% trained on Twitter/X data vs proposed need for multi-platform data diversity.
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.05200.
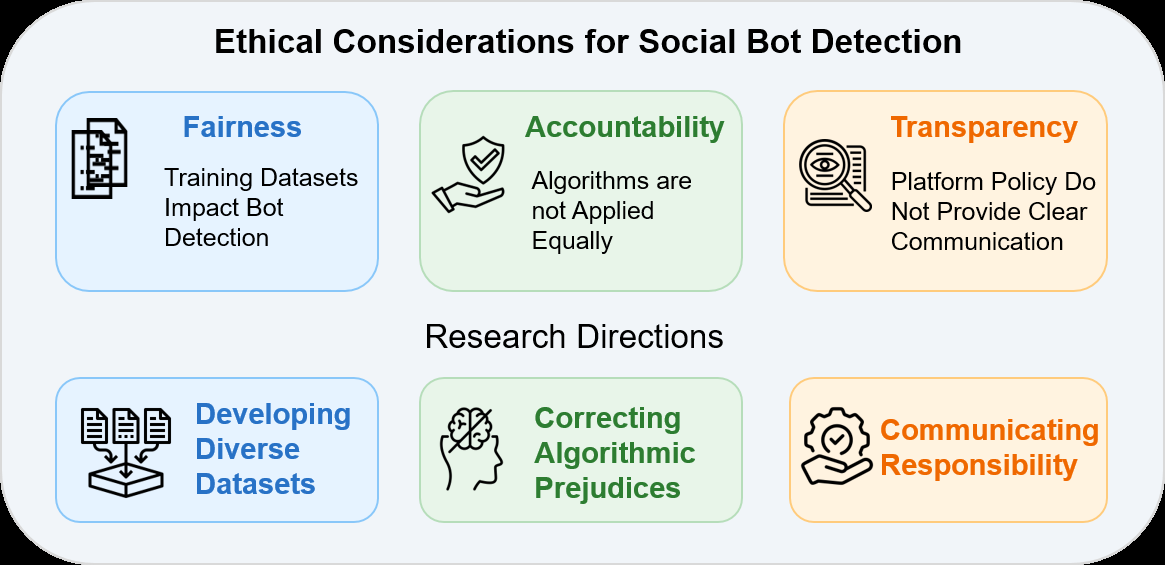
Fig 1: Summary of FATe framework applied to social bot detection in this article, including recommendations for respective research
Limitations
- Literature survey relies on snowball sampling, possibly biasing toward interconnected papers and datasets, reducing representativeness.
- Empirical evaluation limited to BotBuster algorithm and language groups; other languages or algorithms not analyzed in-depth.
- Reddit anecdotal analysis is non-exhaustive and qualitative, lacking statistical generalization about misclassification frequency or impact.
- Training and testing mainly focus on static datasets without adversarial testing against adaptive bots.
- Cultural and ethical perspectives primarily from Western, American-centric viewpoint limiting global generalizability.
- Technical training details (hyperparameters, reproducibility code) for BotBuster and other algorithms are sparse or not released.
Open questions / follow-ons
- How can multilingual and cross-platform diverse datasets be systematically constructed to reduce bias in bot detection?
- What accountability frameworks and appeal systems are effective for users falsely classified as bots to regain platform trust?
- How should definitions of malicious versus benign bot behavior be standardized and communicated transparently across platforms?
- Can bot detection models be robust to adaptive adversaries who actively manipulate detection features or platform signals?
Why it matters for bot defense
Bot-defense engineers developing CAPTCHA or bot detection technology can draw critical lessons from this work: that training data biases (language, platform, event context) strongly impact detection fairness and may systematically misclassify legitimate users, especially those outside dominant language or culture groups. Incorporating diverse and representative datasets, and auditing algorithmic performance across demographic and linguistic subgroups, is essential to reduce inequitable false positives. Additionally, deploying transparent communication and user appeal mechanisms is important for accountability, reducing user harm from misclassification. Finally, understanding the socio-technical context including use cases of both malicious and benign bots guides the design of nuanced detection criteria rather than broad, blunt labeling. Such an ethical approach complements technical bot detection advances to improve trust and fairness in live systems.
Cite
@article{arxiv2602_05200,
title={ FATe of Bots: Ethical Considerations of Social Bot Detection },
author={ Lynnette Hui Xian Ng and Ethan Pan and Michael Miller Yoder and Kathleen M. Carley },
journal={arXiv preprint arXiv:2602.05200},
year={ 2026 },
url={https://arxiv.org/abs/2602.05200}
}