
HEEDFUL: Leveraging Sequential Transfer Learning for Robust WiFi Device Fingerprinting Amid Hardware Warm-Up Effects
Source: arXiv:2602.00338 · Published 2026-01-30 · By Abdurrahman Elmaghbub, Bechir Hamdaoui
TL;DR
HEEDFUL tackles a practical failure mode in deep-learning RF fingerprinting: models trained on one capture regime often collapse when the device is still warming up. The paper argues that the problem is not just channel shift or day-to-day variation; hardware itself is changing during the first minutes after power-on, so fingerprints drift before the radio reaches a steady state. To study this, the authors build a dataset and analysis pipeline around 15 Pycom devices and explicitly track both time-domain I/Q waveforms and estimated hardware impairments over the first 30 minutes of operation.
The core contribution is a two-stage framework that first learns to estimate multiple impairments and then transfers that knowledge into device classification. HEEDFUL combines targeted impairment estimation with sequential transfer learning so the classifier is anchored to device-specific hardware behavior rather than transient warm-up artifacts. In the reported experiments, this yields much stronger performance during early operation than conventional CNN/ResNet baselines, and it remains strong in cross-day and cross-protocol settings. The paper also releases new WiFi type B and N datasets that include both raw time-domain samples and impairment labels/estimates, which is important because the work suggests impairment-aware representations are central to robustness.
Key findings
- On WiFi type B, HEEDFUL reaches 96% accuracy when testing within the initial 6 minutes of device operation, versus 64% for ResNet and 40% for CNN.
- In the hardest early interval on WiFi type B, HEEDFUL still reports 95% accuracy at 4 minutes and 90% at 2 minutes after power-on.
- For cross-day evaluation on the Day 2 dataset, HEEDFUL maintains 87% classification accuracy across warm-up intervals, while ResNet and CNN drop to 20% and 43% in the initial 6-minute interval, respectively.
- For WiFi type N, HEEDFUL achieves 97% accuracy in the initial 6-minute interval and 91% in the initial 2-minute interval.
- The paper states that the warm-up period lasts about 12 minutes for these devices, and that key impairments such as CFO and SCE stabilize over that interval.
- The study spans 15 devices and over a month of collection, with over 250,000 frames total across the released datasets.
- The authors report that early warm-up captures exhibit visible I/Q shape changes over time, with the I/Q envelopes becoming more stable around the 12-minute mark.
Threat model
The adversary or challenge is a deployment-time domain shift: a device classifier must recognize transmitters using only RF captures despite hardware warm-up, cross-day variation, and protocol/domain changes. The model is assumed to see only raw physical-layer signals, not trusted metadata such as MAC addresses, which the authors spoof to avoid shortcut learning. The paper does not describe a cryptographic attacker or a sophisticated RF mimicry adversary; rather, it assumes a realistic wireless environment where device hardware state evolves over time and stable-phase training alone may be insufficient.
Methodology — deep read
The threat/problem framing is a domain-shift problem in RF fingerprinting: the attacker or deployment challenge is not necessarily an active spoofing adversary, but any setting where a classifier is trained on one temporal slice of device behavior and must generalize to another. The paper assumes the model has access only to captured RF signals and not to secret device internals. The key empirical question is whether a fingerprinting model trained on stable captures can still identify devices during early warm-up, and whether learning hardware impairment structure can reduce this temporal brittleness. The authors also motivate a realistic adversarial scenario by spoofing MAC addresses so the model cannot rely on packet metadata; the intended classifier input is physical-layer information in I/Q samples.
Data collection is split into a warm-up study and a HEEDFUL dataset. For the warm-up study, the testbed uses 15 commercial Pycom devices (10 FiPy and 5 LoPy) and a USRP B210 receiver synchronized to an OCXO. Data are collected in a controlled indoor lab with normal nearby WiFi traffic but no major motion or environmental changes. Two capture modes are used: wireless, with each transmitter 1 meter from the receiver and omnidirectional antennas on both ends; and wired, where the transmitter is directly connected to the receiver by SMA coax to remove multipath, fading, and path loss. The warm-up study uses identical 802.11b frames on WiFi channel 1 at 2.412 GHz, 20 MHz bandwidth, 1 Mbps, and HR/DSSS mode. The first 2 minutes after power-on are labeled warm-up captures, then the authors wait an additional 10 minutes to obtain stable captures. Frames are extracted from raw I/Q recordings into HDF5 files in arrival order. The main dataset claim is that the released WiFi type B and type N data include both time-domain I/Q and real hardware impairments, with over 250,000 frames collected over a month.
Architecturally, HEEDFUL is described as a sequential transfer learning pipeline with targeted impairment estimation. The paper says it uses deep single-input multi-output CNN models trained on time-domain I/Q representations to predict eight hardware impairments, then integrates the pretrained impairment estimator with a device-classification head. The impairments mentioned across the paper include CFO, SCE, error vector magnitude, carrier suppression error, PA-related effects, I/Q gain imbalance, quadrature error, pilot EVM, and I/Q timing skew (the exact final set is not fully enumerated in the excerpt, but the text explicitly says eight key impairments are analyzed). The novelty is not just multi-task prediction; it is the sequencing: first learn a representation that is tied to hardware impairment structure on stable data, then transfer that knowledge to classification so the downstream model is less dependent on transient warm-up behavior. The paper frames this as avoiding blind spots that arise if one trains only on stable data or tries to suppress impairments entirely.
The training regime is described only partially in the excerpt. The authors say the impairment estimator and classifier are both trained on stable data, and that evaluation includes training/testing on warm-up captures, training/testing on stable captures, and training on stable captures with testing on warm-up captures. The excerpt does not provide epoch counts, batch size, optimizer, learning rate, seed strategy, or hardware used for training, so those details are unclear from the provided text. Likewise, the exact CNN/ResNet baseline configurations are not fully specified here. A concrete end-to-end example from the paper is: train HEEDFUL on stable I/Q captures from the 15 Pycom devices, use the pretrained impairment-estimation backbone to encode impairment-aware features, then evaluate on frames captured within the first 2 to 6 minutes after power-on. Under that protocol, the model reportedly still classifies devices with 90% to 96% accuracy on WiFi type B, showing that stable-phase training plus impairment-aware transfer can generalize back into the unstable regime.
Evaluation is organized around temporal robustness and domain shift. The core metrics are classification accuracy under different time offsets, plus cross-day and cross-protocol testing. The baseline comparisons explicitly mentioned are CNN and ResNet, with HEEDFUL outperforming both in early warm-up and cross-day settings. The paper also states that the warm-up period is about 12 minutes and shows I/Q plots over 2, 4, 6, 12, and 20 minutes to visualize the drift. It additionally performs impairment analysis with t-SNE plots and evaluates both impairment estimation and device classification on wired and wireless WiFi type B and type N datasets. The excerpt does not mention statistical significance testing, confidence intervals, or k-fold cross-validation, so reproducibility of the reported deltas depends on the authors’ released code and datasets rather than on detailed statistical methodology in the excerpt.
Reproducibility appears relatively strong on artifacts: the paper claims public code on GitHub and downloadable datasets from the NetSTAR Lab website. It also explicitly says the new datasets are released and that they include both wired and wireless captures, which should make independent verification easier. What remains unclear from the excerpt is whether frozen pretrained weights are released, whether the impairment labels are ground-truth measurements or estimator outputs, and how exactly the eight-impairment targets are computed from the raw signals. Those missing details matter because the method’s main claim depends on the quality and stability of the impairment estimation stage.
Technical innovations
- Sequential transfer learning from impairment estimation to device classification, instead of training a classifier directly on raw I/Q or trying to remove impairments.
- Targeted impairment estimation over multiple hardware impairments, using them as an intermediate representation for robust RF fingerprinting.
- A warm-up-focused analysis showing that device signatures drift over the first ~12 minutes after power-on, which explains why stable-phase-only training fails on early captures.
- New WiFi type B and type N RF fingerprint datasets that pair time-domain samples with real hardware impairment information.
Datasets
- WiFi type B RF fingerprint dataset — over 250,000 frames total — NetSTAR Lab / Oregon State University release
- WiFi type N RF fingerprint dataset — over 250,000 frames total across the released corpus — NetSTAR Lab / Oregon State University release
- Warm-up/stable Pycom capture dataset — 15 devices over a month, over 5000 wireless frames/device/day and over 3000 wired frames/device/day — collected by the authors
Baselines vs proposed
- ResNet: accuracy = 64% on WiFi type B during the initial 6-minute interval vs proposed: 96%
- CNN: accuracy = 40% on WiFi type B during the initial 6-minute interval vs proposed: 96%
- ResNet: accuracy = 20% on Day 2 cross-day testing in the initial 6-minute interval vs proposed: 87%
- CNN: accuracy = 43% on Day 2 cross-day testing in the initial 6-minute interval vs proposed: 87%
- ResNet/CNN: not numerically specified in the excerpt for WiFi type N early intervals vs proposed: 97% (6-minute) and 91% (2-minute)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2602.00338.

Fig 2: IoT Testbed consisting of 15 Pycom transmitting
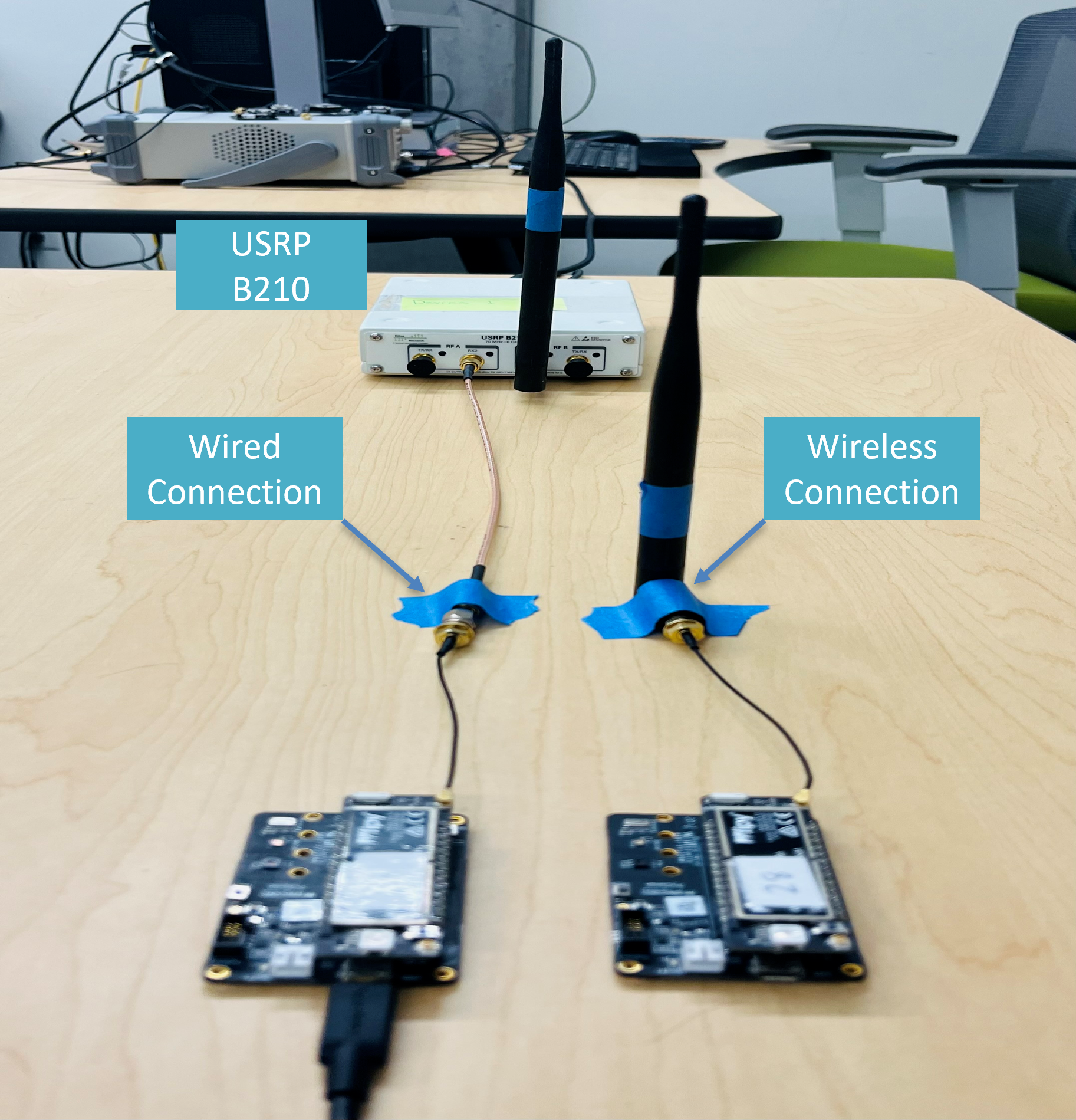
Fig 3: Exp. 1: training & testing on Warm-up captures
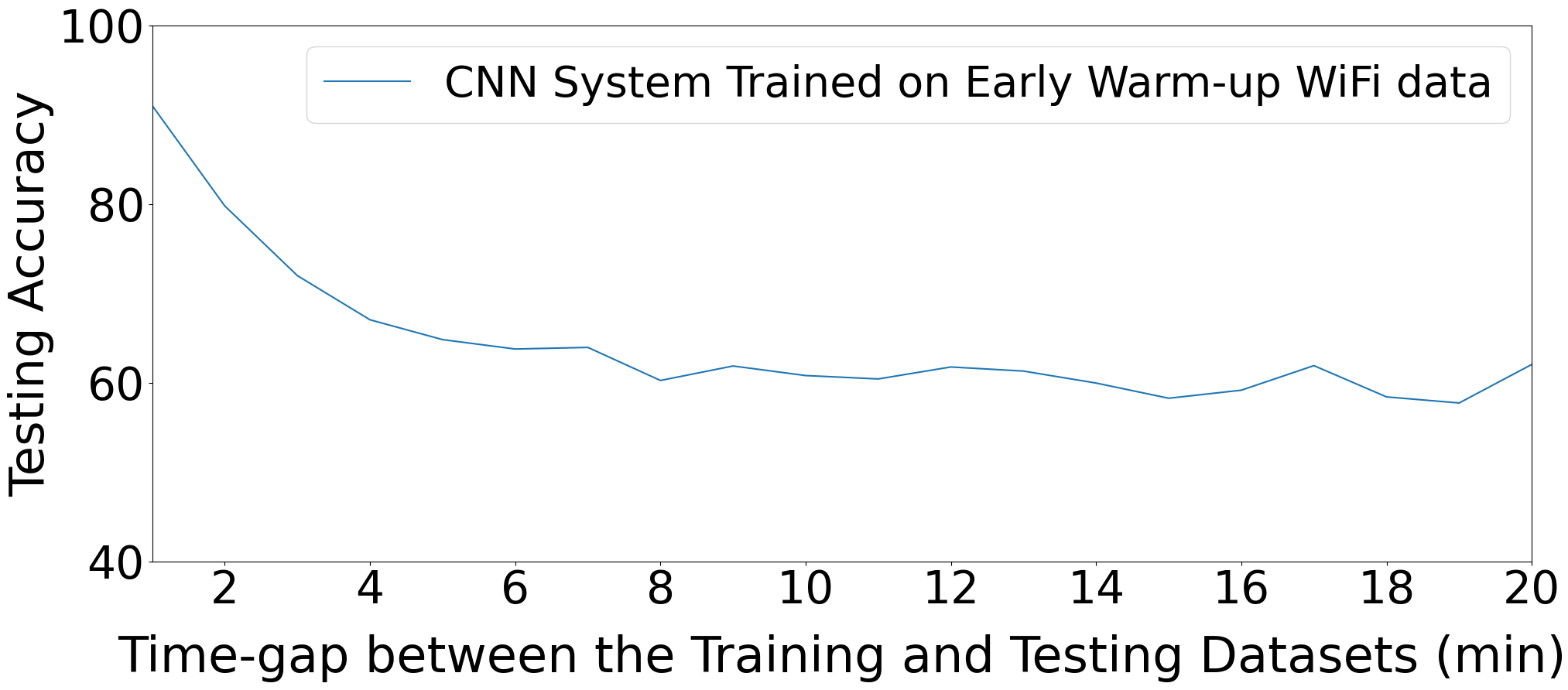
Fig 4: Exp. 2: training & testing on Stable captures
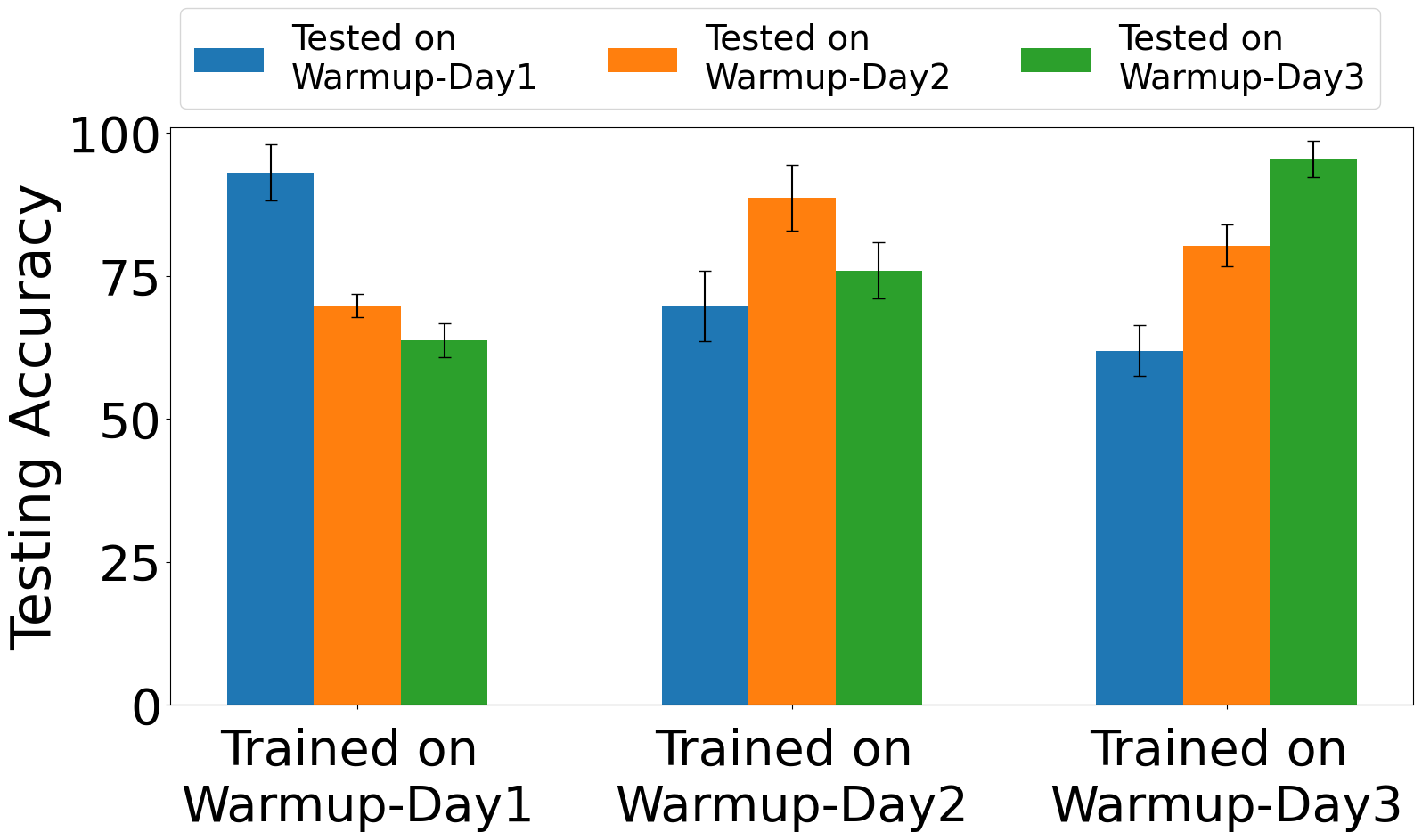
Fig 5: Exp. 3: training on Stable captures and testing on
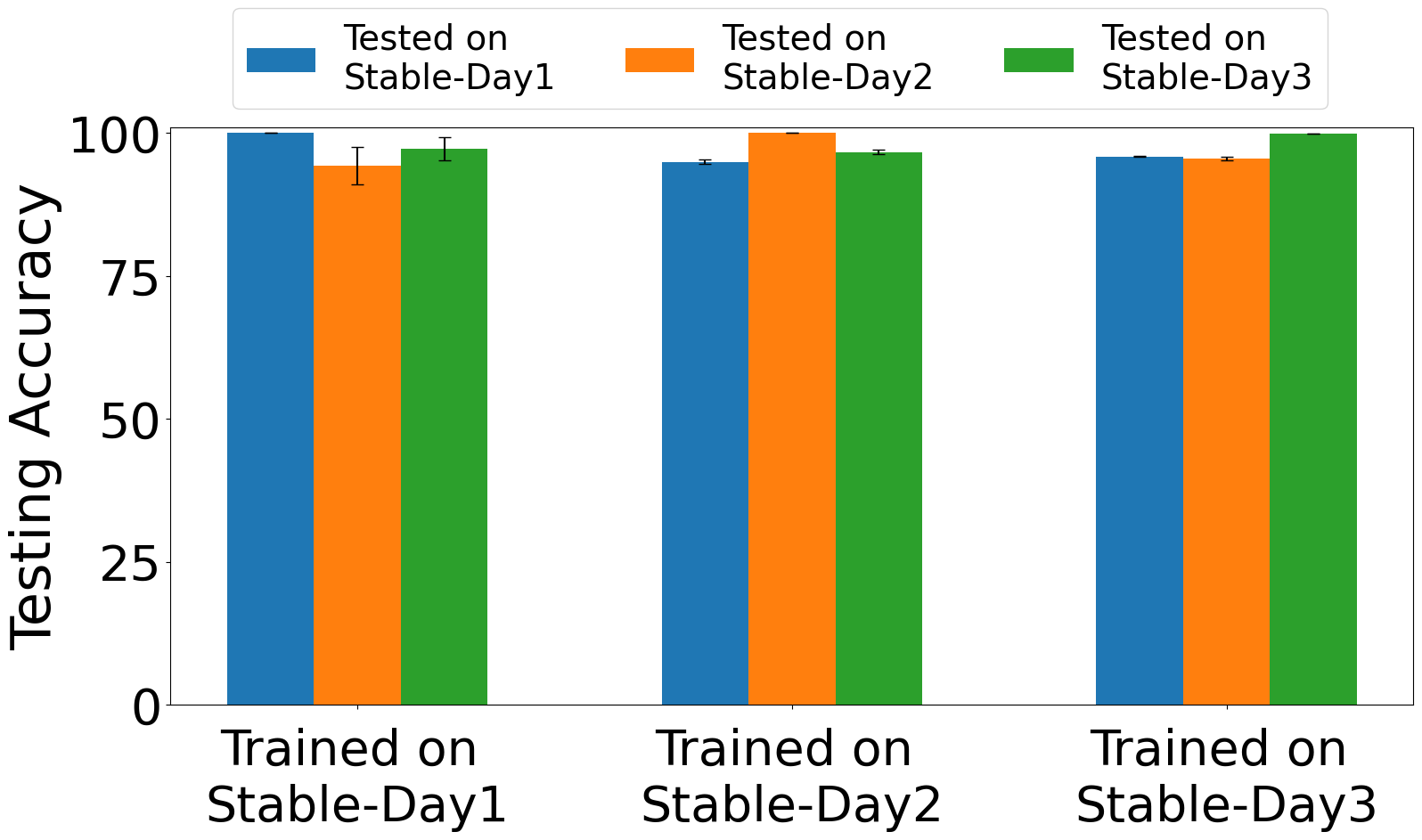
Fig 6: The Hardware Impairment Measurement Setup
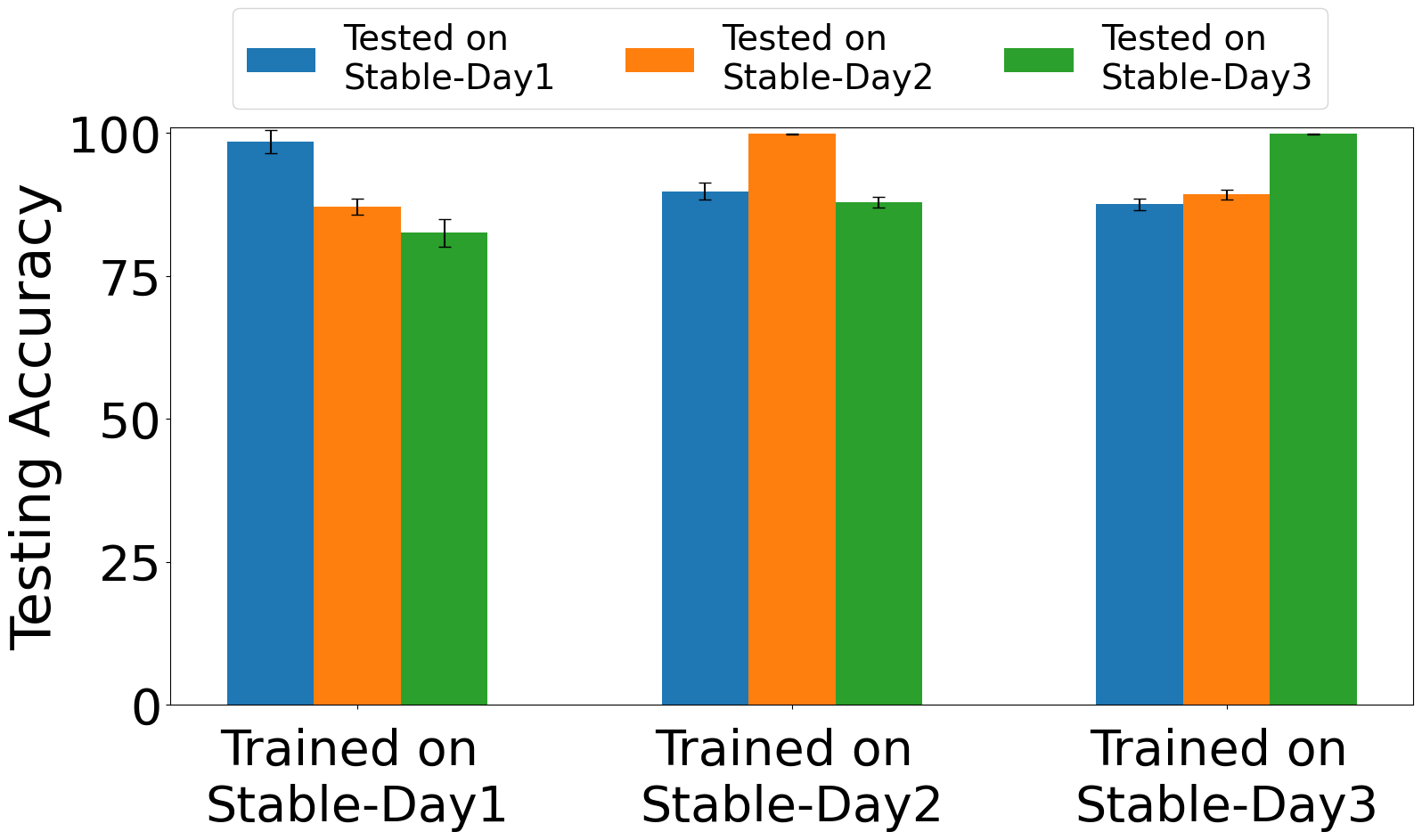
Fig 7: shows the behavior of these hardware impair-
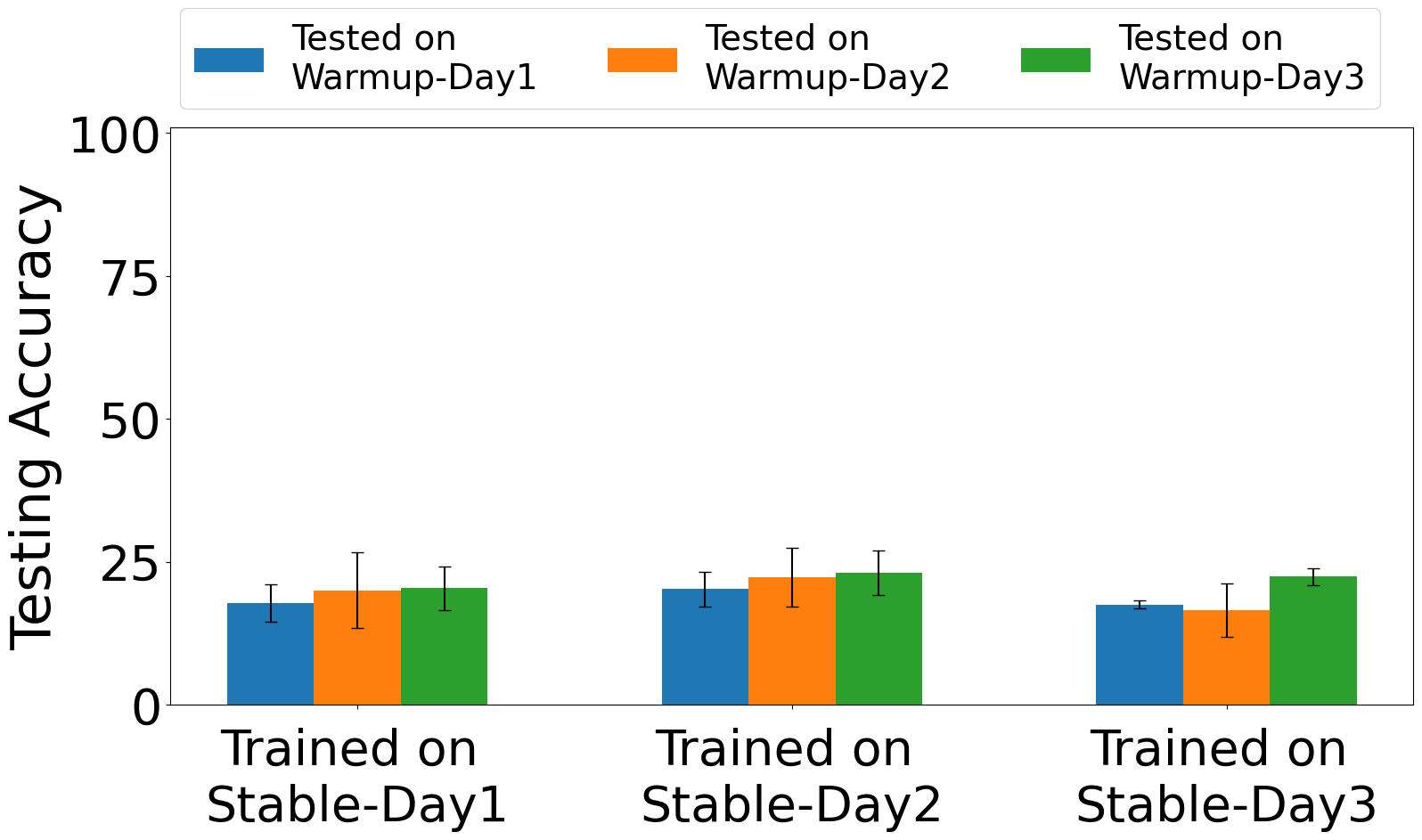
Fig 7 (page 7).
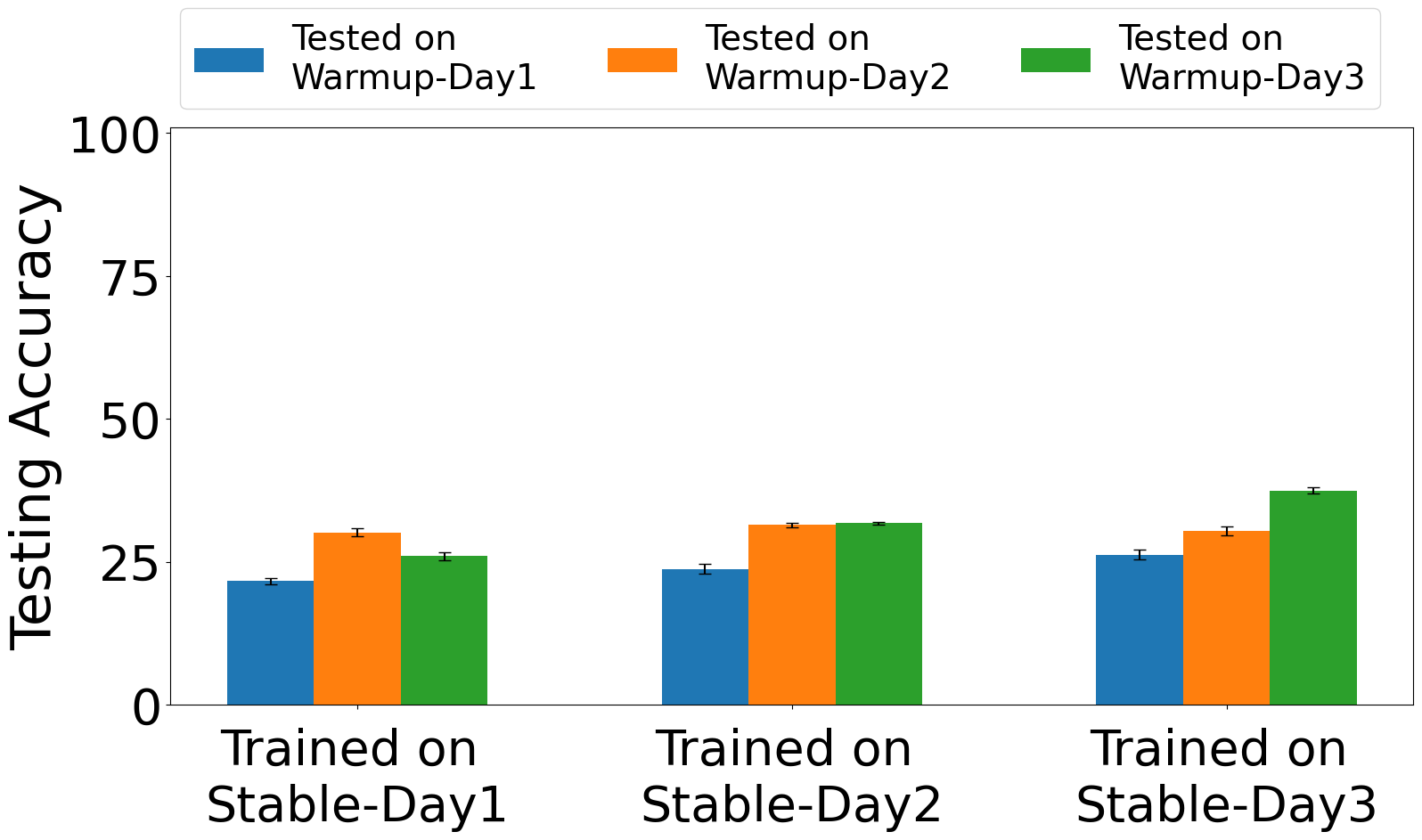
Fig 8 (page 7).
Limitations
- The excerpt does not provide the full training hyperparameters, optimizer, epoch count, or seed strategy, making exact reproduction harder.
- The evaluation appears centered on 15 Pycom devices in a controlled lab, so broader generalization to other hardware families and messier deployments is unproven.
- The paper emphasizes early warm-up and cross-day shift, but the excerpt does not show stress tests against active adversaries, spoofing beyond MAC address spoofing, or deliberate RF mimicry.
- Cross-protocol results are claimed, but the excerpt does not show the full numerical breakdown for all protocol/domain combinations.
- It is unclear from the excerpt whether impairment labels are measured ground truth or outputs from another estimator, which affects how to interpret the multi-output learning setup.
Open questions / follow-ons
- Would the impairment-aware transfer still work on different chipsets, form factors, or radios with different warm-up dynamics?
- How sensitive is HEEDFUL to the choice of the eight impairment targets, and would a smaller or learned impairment set work better?
- Can the method be extended to open-set identification or impostor detection, not just closed-set classification among known devices?
- How robust is the approach under stronger channel variation, mobility, or active RF spoofing that tries to imitate the impairment signature?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main lesson is that biometric-like RF fingerprints are time-dependent, not fixed identities. If a system uses device fingerprints for risk scoring, admission control, or session continuity, warm-up effects can create false negatives early in device operation and false confidence later if the model only learns stable behavior. HEEDFUL suggests a more robust design pattern: model the nuisance factors explicitly, then transfer from nuisance-aware representations into the identity task.
From an operations perspective, this work is a reminder to test any device-authentication or anti-abuse system under time-shifted conditions, not just random train/test splits. A bot-defense engineer would likely use the paper as evidence to add warm-up-phase captures to evaluation suites, to check whether models are overfitting to a steady-state regime, and to consider intermediate latent targets (like impairments) when building more stable physical-layer identity signals.
Cite
@article{arxiv2602_00338,
title={ HEEDFUL: Leveraging Sequential Transfer Learning for Robust WiFi Device Fingerprinting Amid Hardware Warm-Up Effects },
author={ Abdurrahman Elmaghbub and Bechir Hamdaoui },
journal={arXiv preprint arXiv:2602.00338},
year={ 2026 },
url={https://arxiv.org/abs/2602.00338}
}