
Physiological and Behavioral Modeling of Stress and Cognitive Load in Web-Based Question Answering
Source: arXiv:2601.17890 · Published 2026-01-25 · By Ailin Liu, Francesco Chiossi, Felix Henninger, Lisa Bondo Andersen, Tobias Wistuba, Sonja Greven et al.
TL;DR
This paper studies whether very short web survey interactions can reveal stress and cognitive load from multimodal signals, and whether those signals align better with experimentally manipulated task demands or with participants’ own moment-to-moment reports. The core problem is that survey method work often relies on coarse self-reports or post-hoc paradata, which miss rapid changes during a single question. The authors therefore ran a controlled 2×2 within-subjects laboratory study (N=29) manipulating question difficulty and time pressure in a web-based multiple-choice task while recording mouse movements, eye tracking, ECG, and EDA.
What is new here is the combination of ultra-short interaction windows (single-question trials, roughly sub-20 seconds) with a direct comparison between three “views” of the same event: the designed condition, the immediate subjective rating, and the observed physiology/behavior. The paper’s main claim is not just that these states are detectable, but that they are not interchangeable: objective difficulty and time pressure do not perfectly map onto perceived difficulty or stress, and different modalities carry different signal depending on which label is used. The reported result is that there are distinct physiological and behavioral patterns in these short windows, and that multimodal models plus feature attribution can distinguish conditions and self-reports to a useful degree, suggesting a route to adaptive survey interfaces that respond in real time.
Key findings
- The study used a 2×2 within-subjects design with 29 valid participants and 48 total questions per participant, creating short single-trial windows for modeling stress and cognitive load rather than block-level averages.
- Question difficulty was operationalized from validated German-language test batteries: easy items had ~80% ± 0.5% average accuracy in the source norms, while difficult items had ~61.5% ± 0.5% accuracy.
- Time stress was induced with a visible 15-second countdown timer; the no-timer condition allowed unlimited response time.
- The authors collected four synchronized modalities per trial: mouse dynamics, eye tracking, ECG, and EDA, plus immediate post-question ratings of perceived difficulty, perceived stress, and confidence.
- Behavioral features included y-axis cursor flips, hover counts (>500 ms stationary), total hover time, and total cursor distance; physiological features included tonic SCL, nsSCR amplitude, mean HR, HRV, and task-evoked pupil dilation.
- Participants completed 48 multiple-choice questions in 8 blocks of 6, with question order fully randomized within blocks and answer option order randomized on-screen to reduce sequence and position effects.
- One participant was excluded because self-reported stress had zero variance across all assessments, leaving 29 valid participants; the sample age range was 19–74 (mean 27.03, SD 11.07).
Threat model
The relevant threat is not a malicious attacker but a legitimate respondent whose cognitive resources are strained by difficult content or time pressure, causing stress, cognitive overload, satisficing, or degraded survey data quality. The system assumes normal users, not bots or adversaries trying to evade detection, and it cannot infer internal state perfectly—only estimate it from multimodal proxies. The paper does not claim protection against model-aware evasion or spoofing, and it does not study adversaries who intentionally manipulate sensor signals.
Methodology — deep read
Threat model and assumptions: this is not a security-adversarial study in the CAPTCHA sense; the “adversary” is the combination of time pressure, cognitively difficult questions, and the resulting internal strain that can degrade response quality. The authors assume that question properties are known to the experimenter and that the participant is a normal web respondent, not a malicious bot. They also assume that stress and cognitive load can be meaningfully probed through immediate self-report and peripheral physiological/behavioral proxies, even though those are not a ground-truth measure in a strict psychometric sense. Importantly, they frame the problem interactionistically: the same objective condition may produce different subjective states across people, so they do not treat the manipulated condition as identical to the person’s lived experience.
Data provenance, size, labels, splits, preprocessing: the dataset comes from a controlled lab study with 30 recruited participants, 29 retained for analysis after excluding one participant with constant neutral stress ratings. Each participant completed 48 multiple-choice questions arranged into 8 blocks of 6. The 2×2 manipulated factors were question difficulty (easy vs difficult) and stress induction (timer vs no timer). Question type (general knowledge vs cognitive reasoning) was not part of the main factorial design but was counterbalanced and later modeled as a random effect. Labels were available in two forms: condition-based labels from the experimental manipulation and self-reported trial-level ratings collected immediately after each question. Those ratings included perceived difficulty on a 7-point scale, perceived stress on a 7-point scale, and confidence on a 4-point scale. The excerpt does not provide a formal train/test split, cross-validation scheme, or exact preprocessing details for every signal stream; it does state that preprocessing was done per dependent variable and that sensor streams were synchronized via Lab Streaming Layer plus Flask timestamps. The text also specifies baselines for physiological measurement: a 3-minute resting period before the blocks, and a randomized fixation interval (1250/1500/1750 ms) before each trial.
Architecture / algorithm: the paper is a modeling study rather than a novel deep architecture paper. The dependent variables extracted per trial were: from EDA, mean tonic skin conductance level (SCL) and average amplitude of nonspecific SCRs; from ECG, mean HR and HRV; from eye tracking, task-evoked pupil dilation computed as mean pupil diameter during the active question period minus the baseline pupil diameter during fixation; from mouse tracking, y-flips, hover counts, total hover time, and total cursor distance. These features were intended as proxies for autonomic arousal, effort, uncertainty, and engagement. On the modeling side, the paper uses both statistical models and machine-learning models; the excerpt explicitly shows a random forest classifier and SHAP explanations for all features, including four self-reported-class labels, implying that self-report categories were also used in at least one classification setup. The novelty is not a new classifier family but the combination of modalities, short time windows, and dual-labeling strategy (experimental vs self-report).
Training regime and experimental procedure: participants arrived in a lab, gave consent, filled a demographic questionnaire, were fitted with ECG, EDA, eye-tracking, and mouse-tracking equipment, and then completed a 3-minute rest baseline. The task was implemented in a custom Flask web application on a MacBook Pro. Each trial began with a fixation cross, then a multiple-choice question; after answering, the participant could not revise the response. Immediately afterward, they rated perceived difficulty, perceived stress, and confidence. A 20-second rest period was suggested but optional, and a 5-minute break was suggested halfway through the session. The excerpt does not specify optimizer, learning rate, epochs, batch size, number of random seeds, or whether participant-wise grouped cross-validation was used; if those details exist, they are outside the provided text. For the statistical analyses, the paper says it used models to investigate how signals reflect conditions and self-reports, and it presents regression and piecewise regression visualizations for stress-difficulty ratings, plus SHAP for feature attribution in the random forest classifier.
Evaluation protocol and one concrete example: the evaluation appears to compare signal sensitivity under the four factorial conditions and under subjective ratings, and then to assess machine-learning performance on those labels. The figures referenced in the excerpt include average accuracy and average response time across the four experimental conditions, self-reported ratings across manipulated conditions, a visualization of stress-difficulty ratings with a simple linear regression and a piecewise regression, and SHAP values for the random forest classifier. The exact numeric model performance metrics are not visible in the excerpt, so I cannot responsibly invent them. A concrete end-to-end example is: a participant receives a difficult general-knowledge question in the timer condition, with 15 seconds visible. During that trial, the system logs cursor trajectories, pupil diameter, ECG, and EDA while the participant answers. Immediately afterward, the participant rates the item as difficult and stressful. These trial-level signals are then converted into features such as hover time, y-flips, SCL, HRV, and pupil dilation, and those features are used in statistical comparisons and in a classifier to see whether the trial belongs to the difficult-vs-easy or timer-vs-no-timer condition, and whether the model can recover the participant’s subjective stress/difficulty category. The authors then inspect feature importance with SHAP to identify which modalities contributed most.
Reproducibility: the excerpt does not mention a public code release, frozen weights, or dataset availability. It does provide enough apparatus detail to replicate the study design: exact sensors, sampling rates (ECG 130 Hz, EDA 500 Hz, eye tracking 30 Hz scene/120 Hz eye cameras), timing structure, and trial counts. However, model training and evaluation details are incomplete in the provided text, so exact replication of the ML results would require the full methods and appendix.
Technical innovations
- Moves multimodal stress/load detection into sub-20-second, single-question survey windows instead of longer blocks or continuous tasks.
- Uses an interactionist framing that treats manipulated condition and subjective experience as related but non-identical labels for the same trial.
- Combines mouse dynamics, eye tracking, ECG, and EDA in a web-based survey context with per-trial synchronization via Lab Streaming Layer and application logs.
- Introduces a tiered micro-intervention concept for adaptive survey interfaces based on detected cognitive-affective state, rather than only post-hoc quality screening.
Datasets
- Custom 2×2 within-subjects survey study — 29 valid participants, 48 questions each (1,392 trials total if all answered) — collected in a controlled lab study with self-collected multimodal sensor streams
- Validated German-language question batteries — question norms with ~80% ± 0.5% (easy) and ~61.5% ± 0.5% (difficult) average accuracy — source norms from prior published test batteries
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.17890.
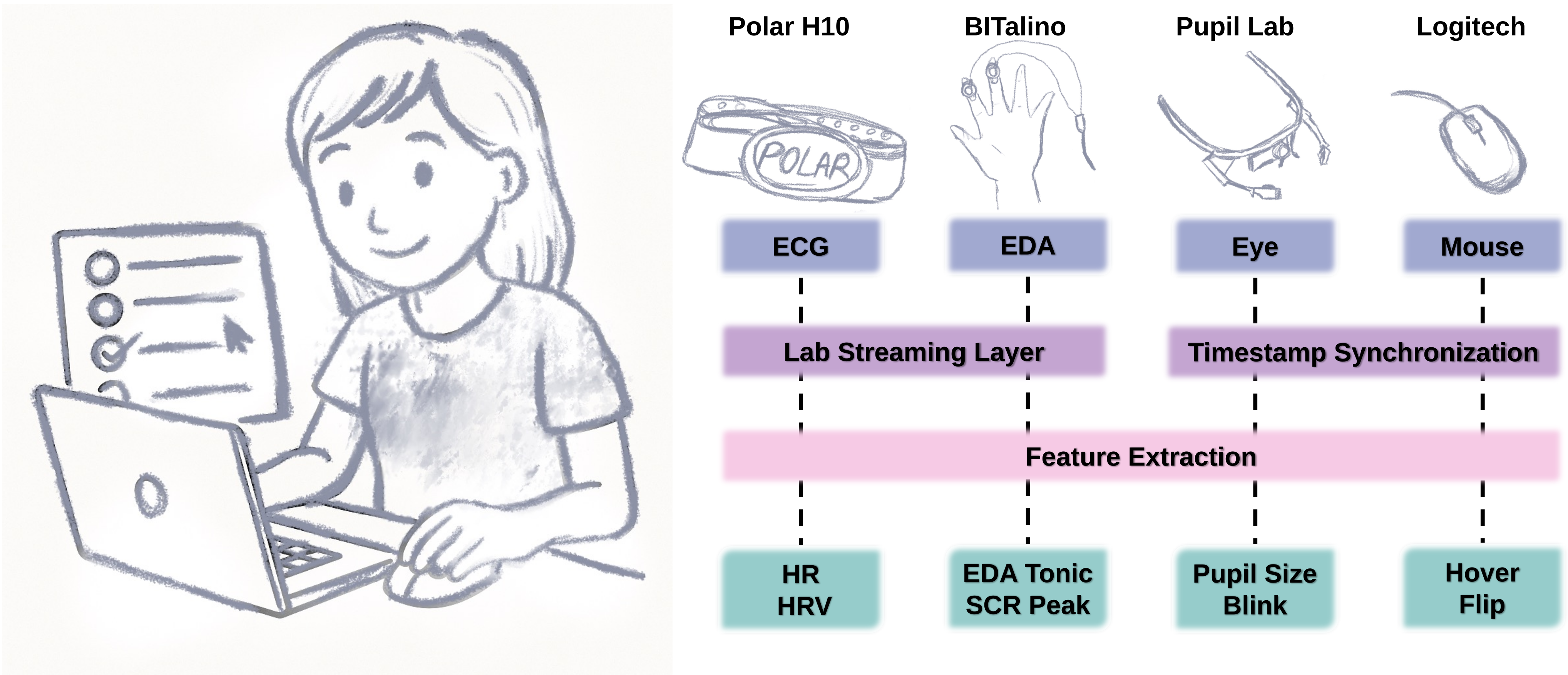
Fig 1: Experimental setup integrating web-based task presentation with multimodal sensor data acquisition. The system simultane-
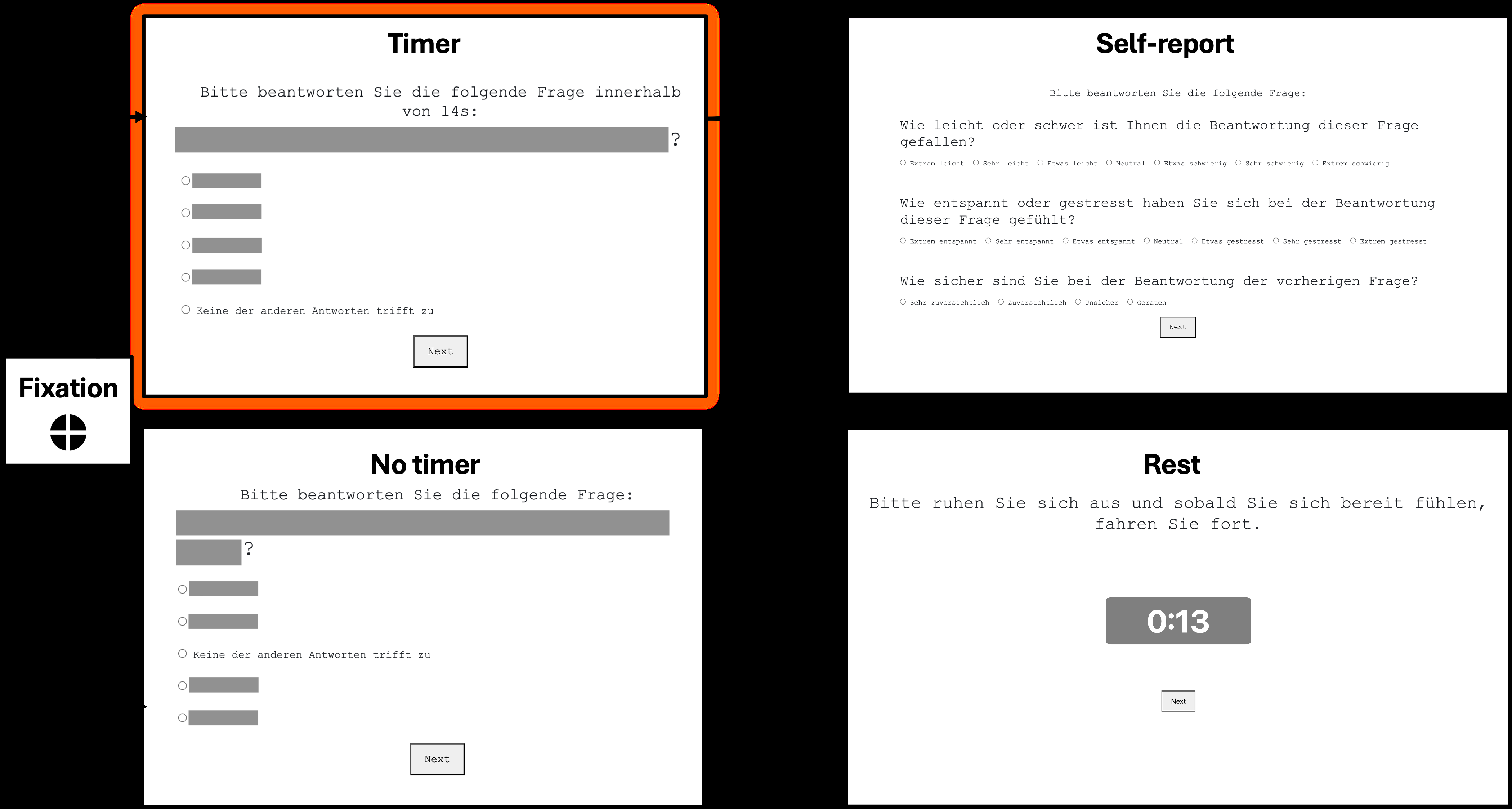
Fig 2: Flow diagram illustrating the procedure of trials (questions). (1) fixation cross, (2) Multiple-choice question with timer or no
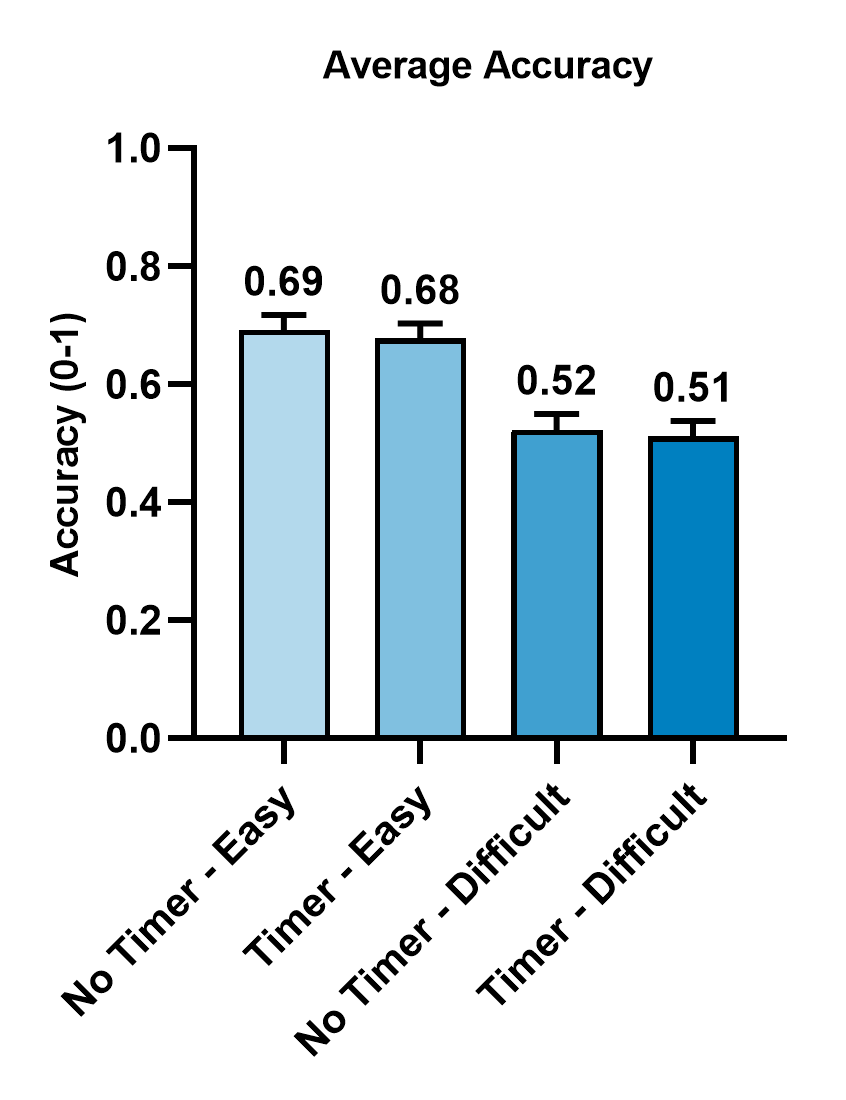
Fig 3: The (a) average accuracy and (b) the average response time across the four experimental conditions with standard errors
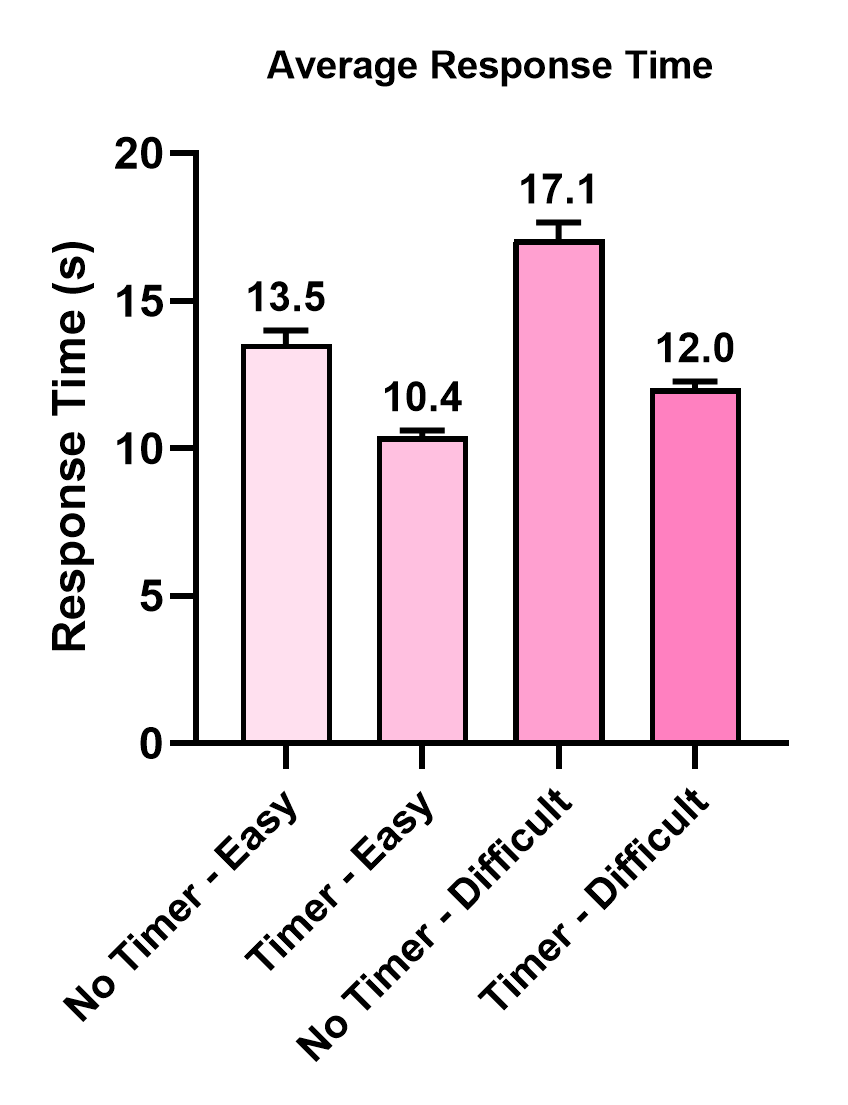
Fig 4 (page 12).
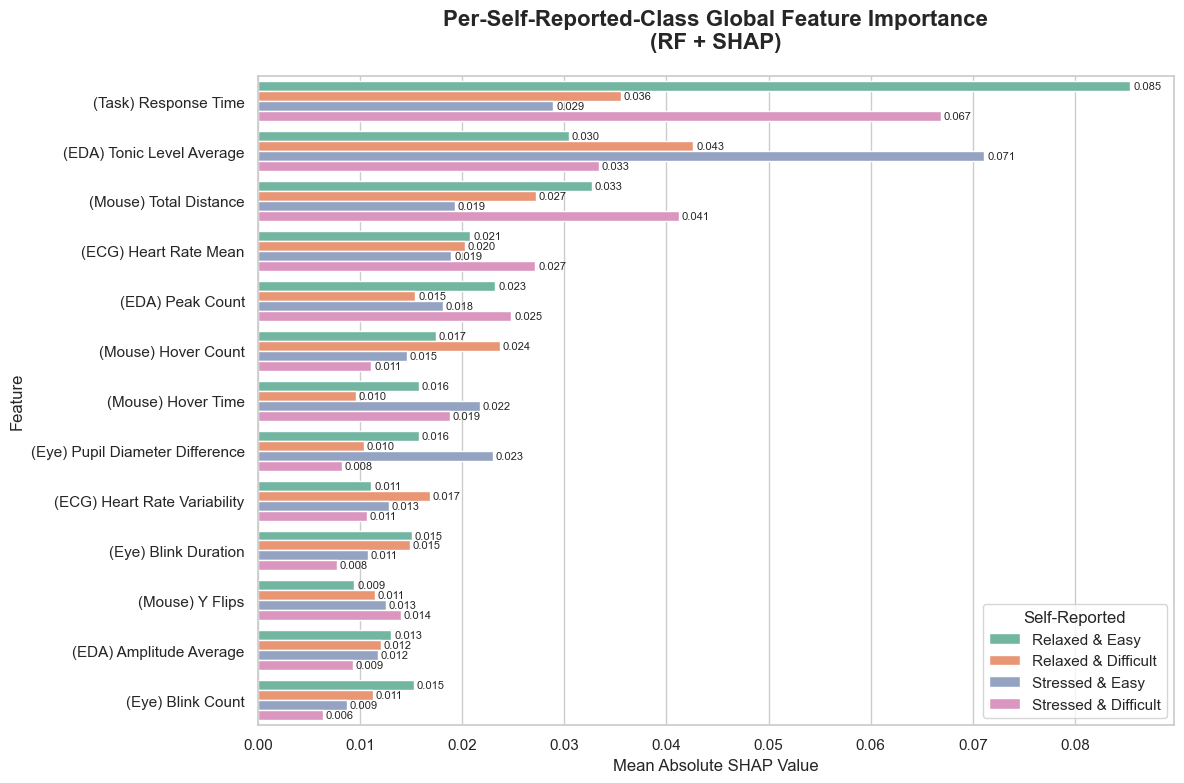
Fig 4: SHapley Additive ex-Planations (SHAP) for all features used in the RF classifier, including 4-self-reported-class labels
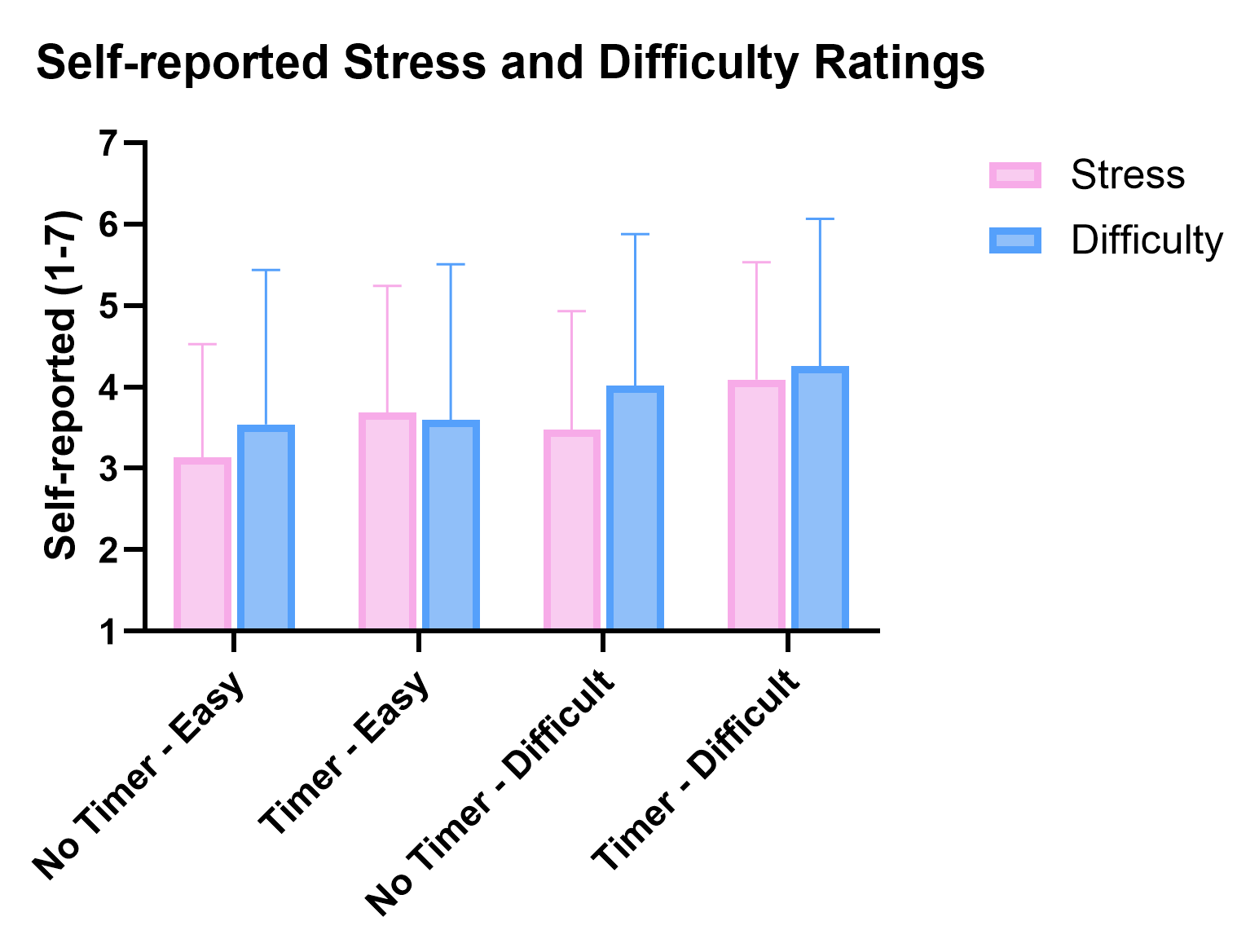
Fig 5: Mean and Standard Deviation of the self-reported ratings over manipulated conditions
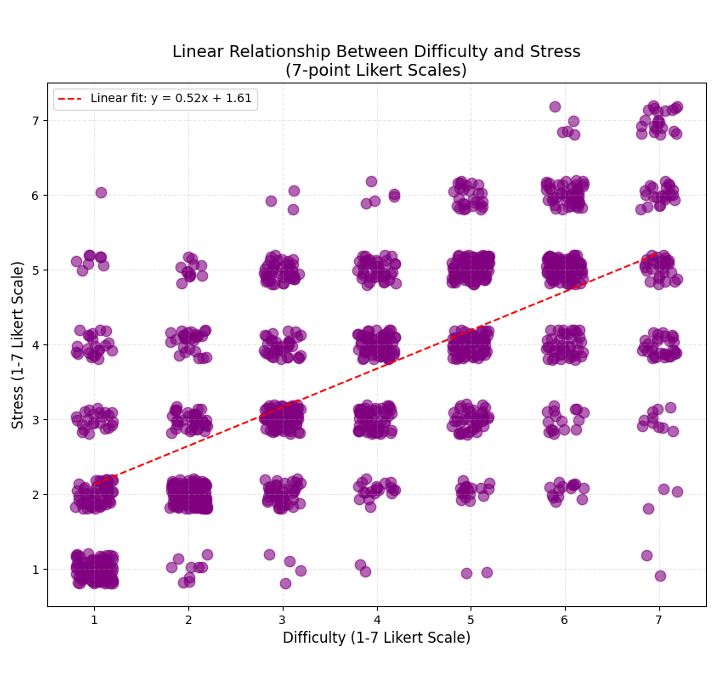
Fig 6: Visualization of self-reported stress-difficulty ratings. (a) Simple linear regression shows the overall trend; (b) Piecewise
Fig 8 (page 29).
Limitations
- Small sample size: 29 valid participants from a university-recruited lab sample limits statistical power and generalizability.
- Single-language, single-lab setting: the task was in German and collected under controlled laboratory conditions, which may not transfer to typical remote survey environments.
- The excerpt does not report full model metrics, confidence intervals, or exact train/test protocol, so the strength of the ML claims cannot be independently checked from the provided text alone.
- Question difficulty is based on prior normed item accuracy, but subjective difficulty can diverge from those norms; that is informative, but it complicates using difficulty labels as ground truth.
- No adversarial or bot-specific evaluation is reported; the work is about human cognitive-affective state detection, not direct fraud or CAPTCHA resilience.
- The adaptive intervention framework is proposed conceptually; the excerpt does not show an intervention study demonstrating that real-time adaptation improves outcomes.
Open questions / follow-ons
- How well do these trial-level physiological and behavioral signals generalize to remote, noisy home settings without controlled lighting, seating, and sensor placement?
- Can a lightweight subset of signals, especially mouse-only or webcam-only features, approximate the multimodal model closely enough for practical deployment in surveys?
- What intervention policy minimizes burden and maximizes data quality once the system detects rising stress or overload: clarification, time extension, break suggestion, or question redesign?
- How stable are the mappings across populations, languages, and item types, especially for respondents with different prior knowledge or stress appraisal styles?
Why it matters for bot defense
For a bot-defense or CAPTCHA practitioner, the paper is most useful as evidence that short web interactions contain detectable human cognitive-affective signatures, but those signatures are task-sensitive and not equivalent to a universal notion of “human-ness.” In other words, if you were building an adaptive verification flow, you could think about using mouse, eye, and timing signals to detect overload or confusion and then change the interaction—yet the paper also warns that objective task difficulty and subjective strain diverge, so a single threshold would be brittle.
Practically, this argues for caution in reusing these signals as a proxy for fraud detection. The study is about normal humans under experimental stress, not bots or attackers. That means its features may help with UX-sensitive risk scoring or escalation logic, but they are not evidence that the same features can robustly separate humans from automation. For CAPTCHA design, the more relevant takeaway is that micro-interactions can be instrumented to detect burden in real time and that adaptive prompts should probably be triggered by multiple modalities and context, not by response time alone.
Cite
@article{arxiv2601_17890,
title={ Physiological and Behavioral Modeling of Stress and Cognitive Load in Web-Based Question Answering },
author={ Ailin Liu and Francesco Chiossi and Felix Henninger and Lisa Bondo Andersen and Tobias Wistuba and Sonja Greven and Frauke Kreuter and Fiona Draxler },
journal={arXiv preprint arXiv:2601.17890},
year={ 2026 },
url={https://arxiv.org/abs/2601.17890}
}