
Large Language Model for OWL Proofs
Source: arXiv:2601.12444 · Published 2026-01-18 · By Hui Yang, Jiaoyan Chen, Uli Sattler
TL;DR
This paper studies whether large language models can generate proof-faithful explanations over OWL ontologies, not just answer entailment queries. The authors argue that prior ontology/logic benchmarks mostly test answer selection or verification under clean, complete premises, while real proving requires three distinct capabilities: extracting the right supporting axioms, simplifying them to their logical essentials, and producing a coherent derivation. They build an automated framework around justifications for atomic subsumptions in EL ontologies, and they add two realistic stressors: noisy irrelevant axioms and incomplete premise sets.
The main empirical result is that some strong reasoning models do very well on easier proving cases, but performance drops sharply as logical structure gets more complex or the premises become messy. Across three ontologies—Snomed CT, GO-Plus, and Foodon—GPT-o4-mini and Qwen3-32B are the strongest overall, but even they struggle on more complex derivations. The authors’ strongest qualitative conclusion is that logical complexity is a better predictor of failure than whether the axioms are represented in formal logic or natural language, and that noise/incompleteness can reduce task performance by very large margins (up to 47% and 38%, respectively, in their reported settings).
Key findings
- On Snomed CT, GPT-o4-mini reached 99.19 Jaccard similarity for extraction and 97.21% weighted derivation step-wise accuracy in the formal-logic + inference-rules setting (Table 1), making it the strongest overall model on that ontology.
- Qwen3-32B was the second-best broad performer: on Snomed CT it achieved 95.87 Jaccard similarity for extraction and 94.15% weighted derivation step-wise accuracy with inference rules (Table 1), but still lagged GPT-o4-mini on overall derivation accuracy.
- Some models produced well-formed outputs without actually solving the task: on Snomed CT, Qwen2.5-32B had 99.71% format correctness but only 39.81 Jaccard similarity for extraction (Table 1).
- On GO-Plus, GPT-o4-mini hit 100.00% on format correctness, 100.00 Jaccard similarity, 100.00% axiom-wise simplification accuracy, and 98.47% weighted derivation step-wise accuracy with inference rules (Table 1).
- The paper reports that Snomed CT is substantially harder than GO-Plus or Foodon: format correctness is lower, and simplification/derivation accuracy drops much more on Snomed CT, consistent with more complex derivations (Section 6.1.1).
- Adding inference rules helped Qwen3-32B substantially, with roughly two- to threefold gains across metrics; for GPT-o4-mini, inference rules gave smaller gains and sometimes reduced performance on Snomed CT (Section 6.1.2, Fig. 5).
- Adding examples to the prompt increased Qwen3-32B’s weighted derivation overall accuracy by up to 16-fold on Snomed CT, from 3.82% to 61.95%, but could reduce format correctness in the no-example vs example comparison tradeoff (Section 6.1.3, Fig. 6).
- The authors report that noisy irrelevant axioms can cut performance by up to 47%, and missing premises by up to 38% in the extended settings described in the abstract/introduction.
- For derivation, models typically used 7–8 steps on average, but some outputs were much longer and unreliable; DeepSeek-R1-Qwen-8B exceeded 20 steps on Foodon despite low overall derivation accuracy (Table 1).
Threat model
The evaluated setting assumes an LLM is given a target OWL EL subsumption and a set of premises that may be complete or incomplete, with additional irrelevant axioms possibly added as noise. The model is expected to identify the necessary axioms, simplify them, and derive a valid proof. It does not assume the model can query an external reasoner during generation, and the input order is shuffled to reduce shortcut cues. In the incomplete-premise variant, the model must determine whether the provided premises are logically sufficient; in the noisy variant, it must ignore distractors. The paper does not consider an adaptive adversary that crafts prompts to exploit the model or a poisoning attacker that changes the underlying ontology.
Methodology — deep read
The paper’s threat model is not a classic adversarial security setting; instead it is an evaluation framework for LLM proving over ontologies. The “adversary” is effectively the gap between a model’s latent knowledge and the need to produce a faithful proof from a conclusion plus a set of premises. The authors explicitly consider two realism stressors: irrelevant noisy axioms and incomplete premises. In that incomplete-premise setting, the model is asked a logic-completeness question: are the provided premises sufficient to derive the target conclusion? They also compare formal-logic input against natural-language verbalizations of the same axioms to test whether syntax or reasoning complexity matters more.
Data are constructed automatically from three large real-world OWL ontologies in EL: Snomed CT, Foodon, and GO-Plus. The paper says these ontologies can infer millions of subsumptions, but due to compute limits they only sample a subset for evaluation. They randomly extract 350 target conclusions from Snomed CT and 70 each from Foodon and GO-Plus, filtering out non-EL axioms (for example, axioms with negation). The selected conclusions are atomic subsumptions A ⊑ B, and they are chosen across an even spread of atomic-distance values from 4 to 16. Labels are built from justifications: a justification is a minimal axiom subset that entails the target conclusion, and the dataset uses the minimal-size justification when multiple justifications exist. The authors then add noisy axioms that are semantically distant from the target and are guaranteed not to belong to any justification for that conclusion. Noise selection is based on sentence embeddings (BGE), after verbalizing each axiom and conclusion into natural language strings. The paper states that the examples are shuffled before prompting; however, the exact train/dev/test split is not a conventional supervised split because the setup is benchmark-style evaluation rather than model training on this dataset.
Architecturally, the paper does not introduce a new neural model; it introduces a pipeline and benchmark. The core formalism is EL description logic. Concepts are built from atomic concepts, conjunction, and existential restrictions. The paper includes a fixed inference-rule set for EL reasoning: subsumption chaining, conjunction introduction/elimination, existential propagation, and equivalence splitting. The dataset pipeline has three sequential tasks for complete proving. First, Extraction: the model must identify the axioms needed for the proof. Second, Simplification: each selected axiom must be rewritten into a logically simpler but still sufficient form, usually by stripping inessential conjuncts or converting equivalences into directional subsumptions. Third, Explanation/Derivation: the model must produce a stepwise proof from the simplified axioms to the target conclusion. In the prompt-based setup, the authors evaluate two prompt styles: one that supplies the EL inference rules, and one that provides examples. The output must be structured into AXIOMS_USED, SIMPLIFY, and DERIVE sections. A concrete example in Fig. 4 shows how the model is expected to extract axioms, simplify them, and then chain them into a derivation with explicit proof steps.
Training regime is mostly absent because the paper evaluates off-the-shelf reasoning LLMs rather than training a new one. The tested models include DeepSeek-R1-Distill-Qwen-32B, Qwen3-32B, Qwen2.5-32B, Magistral-Small-2506, Qwen3-8B, DeepSeek-R1-Distill-Qwen-8B, DeepSeek-R1-Distill-Llama-8B, and GPT-o4-mini. All prompts use a maximum token limit of 5,000 and temperature 0 for reproducibility. There is no mention of gradient-based training, optimizer settings, epochs, or seed sweeps, because the work is benchmark evaluation rather than model development. The main “control knobs” are prompt format (with/without inference rules; with/without examples), ontology, and logical difficulty.
Evaluation is multi-metric and task-specific. For format correctness, they measure whether the response adheres to the required three-section output format. Extraction is scored by Jaccard similarity between the predicted axiom set and the gold justification set. Simplification is scored by axiom-wise correctness, overall correctness, and length-drop percentage; length is defined as a weighted count of logical operators, roles, concepts, and equivalence gets weight 2. Derivation is scored by step-wise accuracy, overall accuracy, and number of generated steps. The authors also report weighted versions of metrics that multiply task scores by format correctness, so malformed outputs do not get inflated credit. The main comparison in Table 1 is across models and datasets, both with and without inference rules; Figures 5 and 6 further compare prompt variants. Figure 7 breaks performance down by atomic distance and justification size on Snomed CT, showing that higher logical complexity corresponds to worse results. The paper does not report significance tests or confidence intervals in the provided text.
Reproducibility is relatively strong for a benchmark paper: the abstract states that code and data are available on GitHub, and the paper provides detailed construction rules, prompt structure, and evaluation metrics. The authors also specify the ontology sources and the exact model families tested. What is not fully clear from the excerpt is the exact sampling procedure beyond the counts given, the complete distribution over atomic-distance bins in the final benchmark, and the full details of the prompt templates in Appendix A. The paper also says the dataset can be extended by others using the released code, which suggests the benchmark is reproducible even if the underlying ontologies themselves are large and partly non-public in practical use.
One concrete end-to-end example from Fig. 4: the input contains six axioms, including A ≡ ∃r.B and E ≡ A ⊓ F. The target is D ⊑ E. The gold extraction is axioms 1, 2, 3, 4, and 5, excluding an irrelevant axiom D ⊑ K. In simplification, equivalence axioms are rewritten directionally, e.g. A ≡ ∃r.B becomes ∃r.B ⊑ A and E ≡ A ⊓ F becomes A ⊓ F ⊑ E. In derivation, the model should first prove D ⊑ A using the existential and subclass chain, then combine that with D ⊑ F to infer D ⊑ A ⊓ F, and finally use A ⊓ F ⊑ E to conclude D ⊑ E. This example illustrates the paper’s central point: the proving task is not merely recognizing that the conclusion is entailed, but identifying which premises matter, reducing them to proof-relevant forms, and presenting a valid sequence of inference steps.
Technical innovations
- A three-stage proving benchmark for OWL EL ontologies: extraction, simplification, and explanation/derivation, rather than only entailment classification.
- An automatic dataset construction method based on minimal justifications for atomic subsumptions, with semantic noise injection via embedding-based distance selection.
- An atomic-distance heuristic to stratify conclusions by reasoning length and to separate easy transitive chains from structurally more complex derivations.
- A logic-completeness evaluation for incomplete-premise settings, asking whether the provided premises are sufficient for the conclusion.
- A prompt-evaluation protocol that compares explicit EL inference rules against few-shot examples and measures robustness under formal-logic vs natural-language inputs.
Datasets
- Snomed CT — 350 selected conclusions (subset of millions of inferable subsumptions) — sampled from the public ontology; source ontology used in prior work
- Foodon — 70 selected conclusions — sampled from the public ontology; source ontology used in prior work
- GO-Plus — 70 selected conclusions — sampled from the public ontology; source ontology used in prior work
Baselines vs proposed
- GPT-o4-mini vs Qwen3-32B on Snomed CT extraction: Jaccard similarity = 99.19% vs 95.87% (with inference rules)
- GPT-o4-mini vs Qwen3-32B on Snomed CT derivation overall accuracy: 93.49% vs 72.14% (with inference rules)
- GPT-o4-mini vs Qwen3-32B on GO-Plus derivation overall accuracy: 98.11% vs 92.50% (with inference rules)
- GPT-o4-mini vs Qwen3-32B on Foodon derivation overall accuracy: 88.57% vs 66.67% (with inference rules)
- Qwen2.5-32B vs GPT-o4-mini on Snomed CT extraction: Jaccard similarity = 39.81% vs 99.19% (with inference rules)
- DeepSeek-R1-Distill-Llama-8B vs GPT-o4-mini on GO-Plus derivation overall accuracy: 26.19% vs 98.11% (with inference rules)
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.12444.

Fig 1: LLMs for proof construction and presentation with Web ontologies
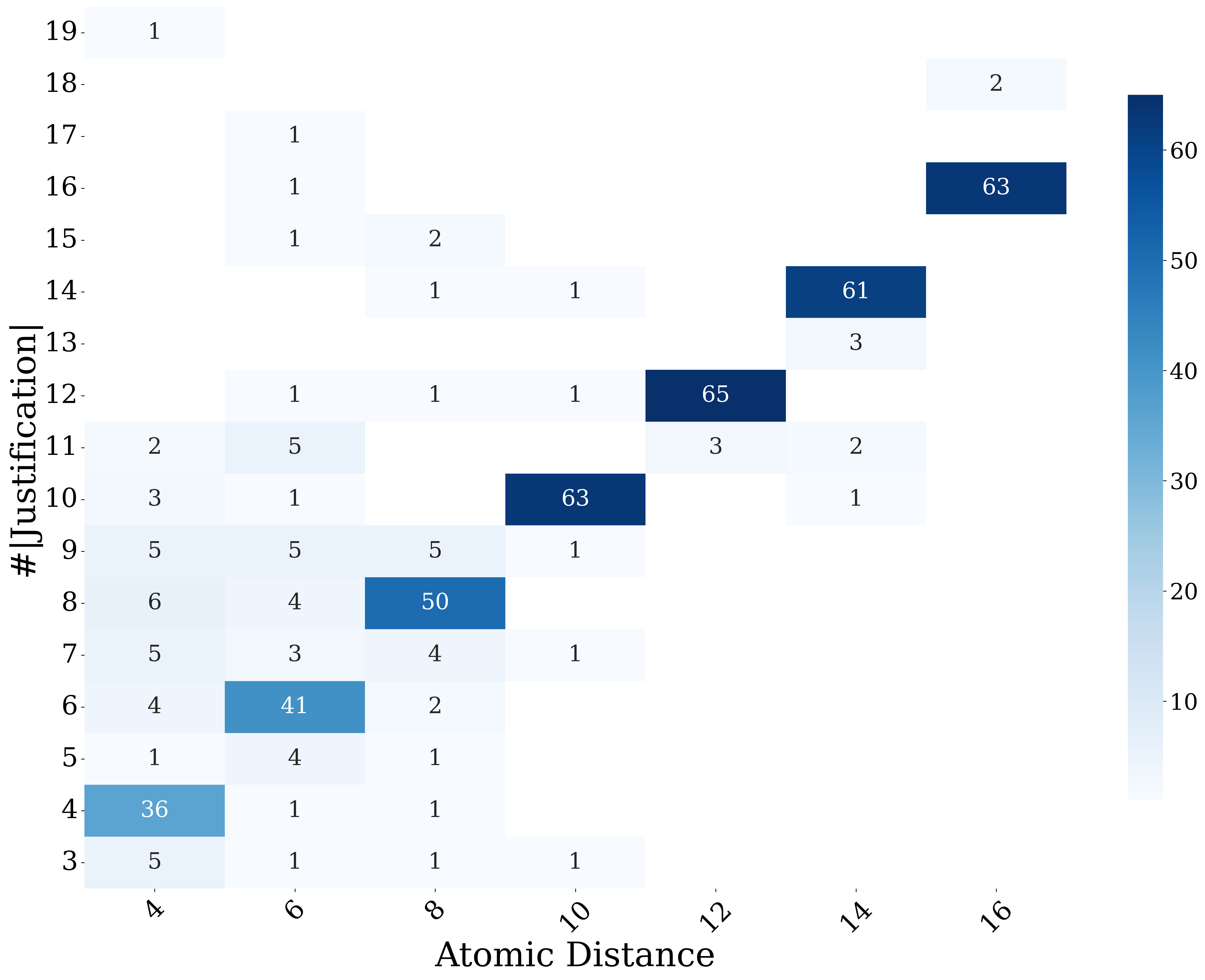
Fig 2: Distribution of the selected conclusions (subsump-
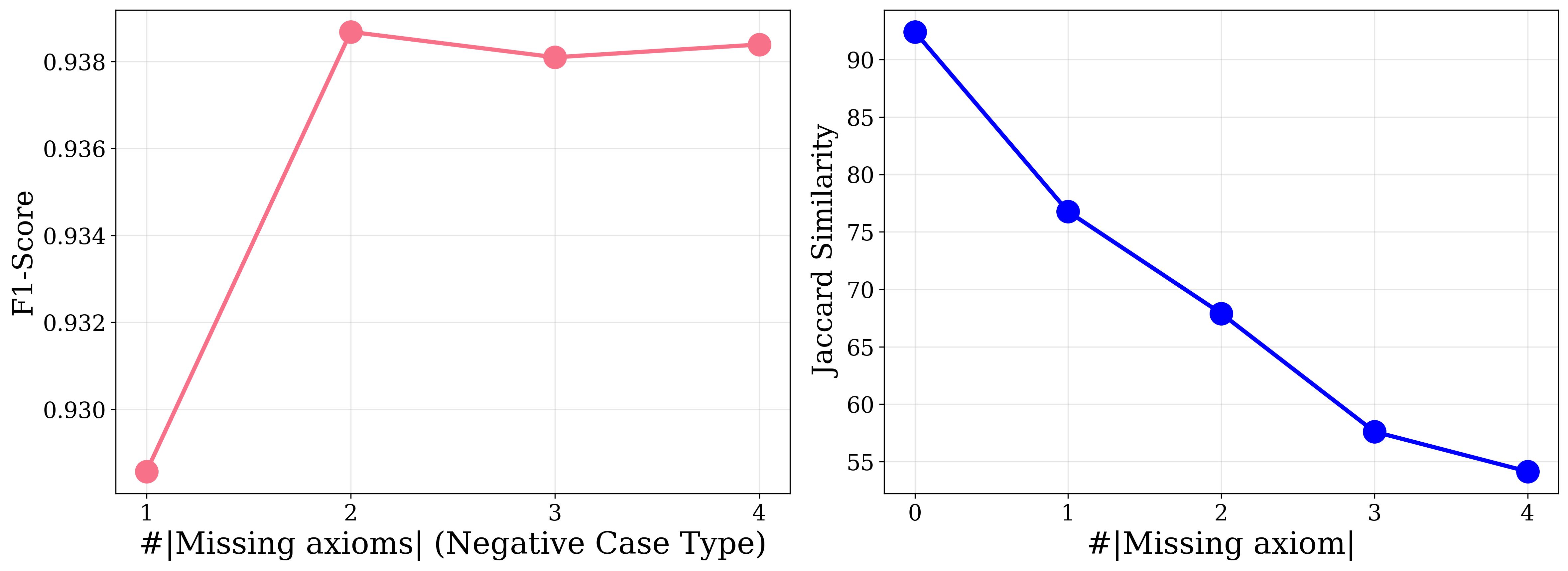
Fig 8: F1-scores for recognizing logical completeness (left)
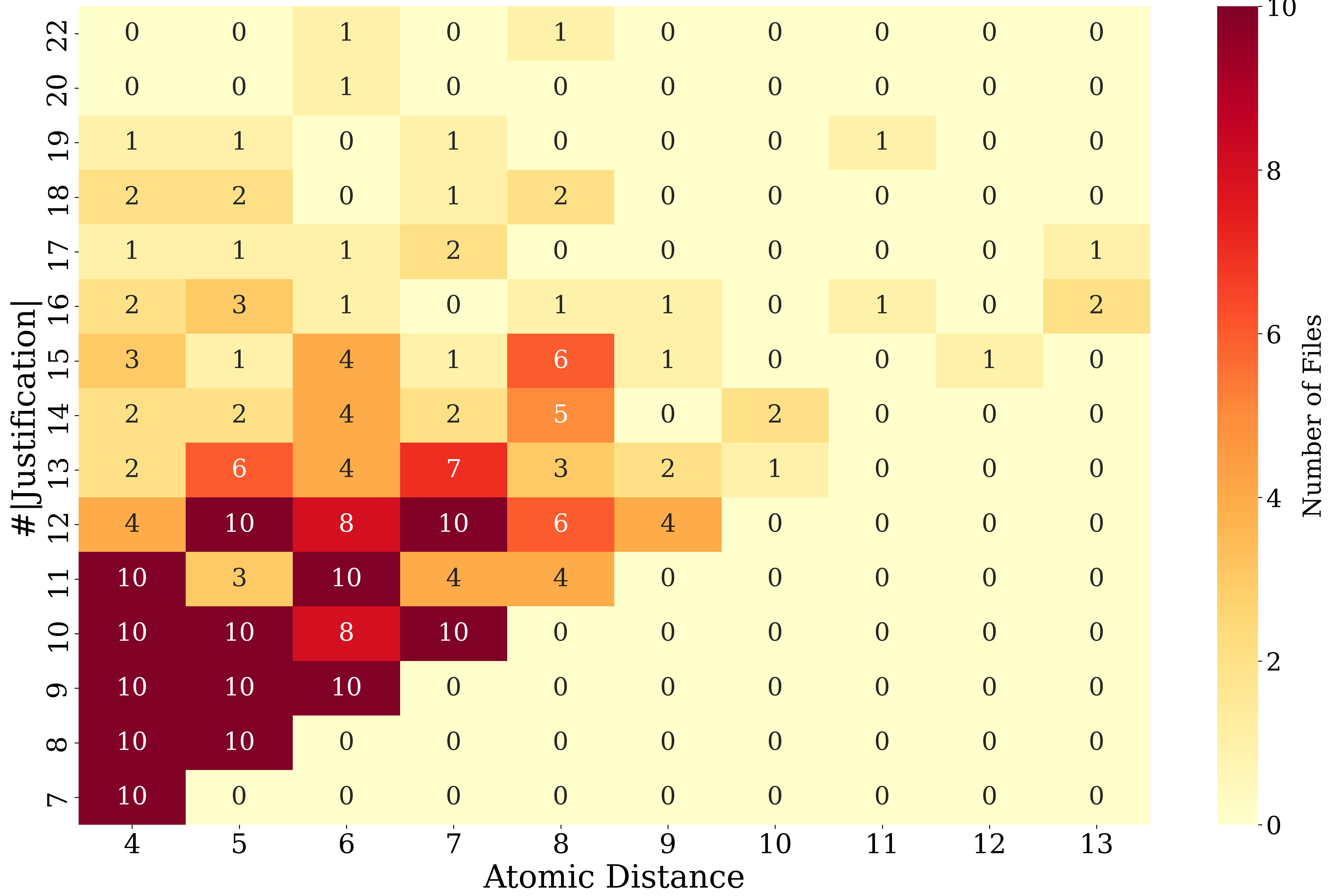
Fig 11: Average performance (weighted) of all methods on Foodon and GO-Plus, and the performance of GPT-o4-mini
Limitations
- The benchmark is relatively small after sampling: 350/70/70 conclusions, which may not cover the full long-tail of ontology proofs.
- Only EL ontologies are studied; results may not transfer to more expressive DLs with negation, disjunction, or richer axioms.
- The paper evaluates off-the-shelf prompt-based models, so it does not test fine-tuned systems or training-time adaptations for proof generation.
- The excerpt does not report significance testing, confidence intervals, or variance across random seeds.
- Noise is injected using embedding-based semantic distance, which may not match the hardest logically irrelevant distractors an attacker or user could provide.
- The incomplete-premise setting is mentioned as important, but the excerpt provides limited procedural detail on how missing-premise cases are generated and scored beyond the reported performance drops.
Open questions / follow-ons
- Can the benchmark be extended beyond EL to more expressive description logics while keeping automatic justification-based labeling tractable?
- Would fine-tuning on proof traces improve the models that currently look format-correct but logically weak, such as Qwen2.5-32B?
- How robust are the conclusions under different noise-generation strategies, especially adversarially chosen distractor axioms instead of embedding-nearest semantically similar axioms?
- Can models learn to explicitly represent justification sets and proof graphs, rather than emitting stepwise text that is only loosely grounded in the ontology?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the relevant lesson is not about CAPTCHAs directly but about evaluation design for reasoning systems that may sit behind trust, moderation, or assisted-verification workflows. The paper shows that a model can be highly fluent in the required output format while failing the actual reasoning task, so any system that uses LLM outputs for policy, identity, or fraud decisions needs task-grounded checks rather than surface-form acceptance. In practical terms, if you were using an LLM to explain why a user or content item matches a rule set, you should expect performance to degrade when the rule base is noisy, incomplete, or too logically deep, and you should design fallback validation with a symbolic reasoner or explicit proof verification.
A second takeaway is that prompt scaffolding matters differently by model. Some models improved a lot from explicit inference rules or examples, while others were already saturating and could even get worse with longer prompts. For bot-defense workflows, that means a single prompting strategy is unlikely to be universally robust across model families or across simple versus complex policy graphs. The paper’s extraction/simplification/explanation decomposition is also useful operationally: it suggests a way to separate “retrieve the supporting evidence” from “compress it” and “justify it,” which is a cleaner interface for auditing than a single free-form explanation. The main caveat is that this study is about ontology proofs, not human-interactive challenge-response systems, so the transfer is methodological rather than direct.
Cite
@article{arxiv2601_12444,
title={ Large Language Model for OWL Proofs },
author={ Hui Yang and Jiaoyan Chen and Uli Sattler },
journal={arXiv preprint arXiv:2601.12444},
year={ 2026 },
url={https://arxiv.org/abs/2601.12444}
}