
Telling Human and Machine Handwriting Apart
Source: arXiv:2601.11700 · Published 2026-01-16 · By Luis A. Leiva, Moises Diaz, Nuwan T. Attygalle, Miguel A. Ferrer, Rejean Plamondon
TL;DR
This paper asks a security-oriented question: can we reliably distinguish genuine online handwriting from synthetic handwriting generated by modern models and classical motion synthesis? The authors frame this as a reverse Turing test for behavioral biometrics, motivated by the fact that handwritten gestures, digits, signatures, and traces are increasingly used for liveness, reauthentication, and CAPTCHA-like checks. Their main novelty is not a new generator, but a detector: a shallow GRU classifier that consumes raw spatiotemporal trajectories rather than hand-engineered features such as velocity.
The study is unusually broad for this task. It evaluates 10 public datasets spanning isolated symbols, digits, gestures, pointing traces, mouse movements, mobile touch, and signatures, and compares seven synthesizers ranging from Sigma-Lognormal/Kinematic Theory reconstructions to GANs, Transformers, and diffusion models. The headline result is very strong average performance: 98.3% AUC and 1.4% EER across datasets and generators, with performance staying high in few-shot settings and remaining competitive in out-of-domain tests. The paper’s main practical takeaway is that raw trajectory structure appears easier to classify than velocity-only summaries, and that a small recurrent model is already enough to expose many synthetic traces.
Key findings
- Across 10 datasets and 7 synthesizers, the proposed trajectory-based GRU reaches 98.3% average AUC and 1.4% average EER.
- In the main detection experiment, only 3 of 70 dataset–generator combinations fell materially below near-perfect performance; the paper reports 71% AUC for SDT on Chars74k and 86% AUC for both ΣΛ reconstruction and DHG on Biosecure, while the rest were 100% or close to 100%.
- Trajectory input outperforms engineered velocity input in almost all settings; the paper explicitly says velocity is only better in a few low-data ΣΛ cases such as Biosecure and ProjectedSign at 10% training.
- With only 10% of the data used for training, the classifier still maintains strong few-shot performance when evaluated on the remaining 90%, indicating the decision boundary is learnable from limited samples.
- In out-of-domain experiments, the model trained on MobileTouch generalizes best to other datasets; the authors attribute this to MobileTouch’s diversity: 72 symbol classes and 94 smartphones.
- The full pooled experiment used 267K training, 53K validation, and 29K test samples; when class balance was forced to be equal, the trajectory-based model still beat the velocity-based model by about 4 absolute points in AUC, accuracy, and F-score.
- Affine synthesis was the easiest synthetic source to detect, which the authors connect to implausible timestamp/spatial consistency in the generated trajectories.
- BeCAPTCHA samples were also described as very easy to detect, supporting the claim that modern classifiers can expose reply-attack-style synthetic movement data even when generators are strong on appearance rather than motor realism.
Threat model
The adversary can generate synthetic online handwriting traces using a variety of generators, including kinematic reconstruction, stochastic perturbation of ΣΛ components, GANs, autoregressive/Transformer methods, diffusion models, and simple affine distortions. The defender sees only the resulting (x, y, t)-style trajectory sequences and must decide whether they were produced by a human or a machine. The attacker is assumed not to control the detector, not to know per-user labels at inference, and not to have the ability to bypass the input representation beyond crafting synthetic traces that look human-like to the classifier.
Methodology — deep read
Threat model and assumptions: the paper treats synthetic handwriting as a reply-attack vector against systems that use handwriting as proof of human presence. The adversary can generate large amounts of fake online handwriting using a range of synthesizers, from analytical motion models to modern generative models. The detector is assumed to see only the observed trajectory data at inference time; the goal is not writer identification or symbol recognition, but binary classification of human vs machine. The authors explicitly target a user-independent and device-independent setting, so the classifier is not allowed to rely on a particular user’s idiosyncrasies or a single device’s sampling characteristics. In the out-of-domain setting, the provenance of the test data is unknown and may come from a different dataset, device, symbol set, or synthesizer.
Data and preprocessing: the study uses 10 public datasets covering isolated characters, digits, gestures, pointing traces, mouse movements, mobile touch, and signatures. The text names several by figure/table labels: $1-GDS, $N-MMGS, $N-MMGF, Chars74k, Biosecure, MCYT-100, SUSIGv, BioSignS, BioSignF, Mouse, MobileTouch, and ProjectedSign; the paper notes that some device-dependent datasets are split into stylus and finger subsets (for $N-MMGS and BioSign). The raw samples are spatiotemporal sequences of (x, y, t) tuples. For each human sample, the authors create one synthetic counterpart per synthesizer, so every human sample is paired with synthetic versions from all seven generation methods: ΣΛ kinematic reconstruction, ΣΛ kinematic synthesis, BeCAPTCHA GAN, DeepWriteSYN, SDT (Disentangled Transformer), DHG (Diffusion model for handwriting generation), and affine synthesis. Two input representations are considered: velocity (Euclidean distance divided by time delta) and trajectory offsets (Δx, Δy, Δt). The trajectory representation is specifically chosen to avoid feature engineering and to make the classifier less dependent on absolute device scale.
Architecture / algorithm: the detector is intentionally shallow: a single GRU hidden layer with 100 neurons, followed by dropout at rate 0.25 and one sigmoid output neuron. The output is interpreted as P(synth|z), and the classifier predicts synthetic when that probability exceeds 0.5. The key design choice is the use of raw trajectory offsets rather than a derived scalar velocity feature. The authors motivate GRU over vanilla RNNs and LSTMs as a computationally efficient recurrent unit that can handle sequence dependencies without the more complex LSTM state structure. They also note that ReLU performed poorly for sequence classification in their experiments, so they use tanh as the main activation and sigmoid inside the recurrent steps. Conceptually, the model must learn a hidden representation that encodes temporal shape, local curvature, and timing regularities directly from the sequence, instead of being handed a manually engineered summary.
Training regime: the detector is trained with Adam (β1 = 0.9, β2 = 0.999) and learning rate 0.0005, using binary cross-entropy. Batch size is 128, maximum training length is 400 epochs, and early stopping with patience 40 is used, monitored by classification accuracy. Inputs longer than 400 timesteps are truncated and shorter ones are zero-padded to 400. The default split is 70% train, 10% validation, 20% test, stratified to keep a 50/50 human-synthetic ratio in each partition. The authors state they train one model per dataset and only once, because different random initializations did not materially change performance in prior experiments. For the synthesizers, the paper provides separate training details: BeCAPTCHA is trained for 50 epochs with batch 128 and lr 0.0002; DeepWriteSYN for 100 epochs with batch 100 and lr 0.0001 and weighted KL term 0.25; SDT for 200,000 steps with batch 32 and lr 0.0002; DHG for 60,000 steps with batch 96 and lr 0.0001. The paper says all these generative models use Adam with default β values unless otherwise noted.
Evaluation protocol and concrete example: the main metrics are AUC and equal error rate (EER). The authors run three complementary evaluations: (1) standard within-dataset detection on all 10 datasets and all 7 generators, comparing velocity vs trajectory input; (2) few-shot experiments using 10% and 50% training splits, with 20% of the training partition held out as validation; and (3) out-of-domain experiments, where a model trained on one dataset is tested on a random 30% sample drawn from all the other datasets combined. They also run pooled experiments on all datasets together, once with the natural human/synthetic imbalance and once with balanced class proportions. One concrete end-to-end example is the standard within-dataset setting: for a given dataset, every human trajectory is duplicated via all seven synthesizers, the sequences are truncated/padded to 400 steps, converted to either velocity or Δx/Δy/Δt, and fed into the GRU. The model outputs a synthetic probability for each test sequence, which is thresholded at 0.5; AUC and EER are then computed over the held-out test split. The paper reports no statistical significance tests, no cross-validation, and no public note about frozen checkpoints or code release in the extracted text, so reproducibility beyond the described setup is not fully established here. In the results discussion, the authors reference Figures 3–8 and Tables II–IV to compare the representations, show few-shot behavior, and illustrate out-of-domain successes and failures.
Technical innovations
- A reverse-Turing-test formulation for online handwriting that treats human-vs-machine detection as a binary security problem rather than a symbol-recognition problem.
- A shallow GRU classifier that consumes raw spatiotemporal offsets (Δx, Δy, Δt) instead of engineered velocity features, reducing reliance on manual feature design.
- A broad benchmark spanning 10 public datasets and 7 synthesizers, including analytical ΣΛ reconstructions, GAN-based, Transformer-based, and diffusion-based handwriting generators.
- A few-shot and out-of-domain evaluation protocol that explicitly tests whether the detector learns a general notion of human motion rather than dataset-specific cues.
Datasets
- $1-GDS — size not specified in excerpt — public dataset
- $N-MMGS (stylus) — size not specified in excerpt — public dataset
- $N-MMGF (finger) — size not specified in excerpt — public dataset
- Chars74k — size not specified in excerpt — public dataset
- Biosecure — size not specified in excerpt — public dataset
- MCYT-100 — size not specified in excerpt — public dataset
- SUSIGv — size not specified in excerpt — public dataset
- BioSignS (stylus) — size not specified in excerpt — public dataset
- BioSignF (finger) — size not specified in excerpt — public dataset
- Mouse — size not specified in excerpt — public dataset
- MobileTouch — size not specified in excerpt — public dataset
- ProjectedSign — size not specified in excerpt — public dataset
Baselines vs proposed
- Velocity input vs trajectory input: AUC = lower overall performance vs proposed trajectory-based model = 98.3% average AUC (paper reports trajectory is better in nearly all settings; exact per-dataset velocity numbers are in Figs. 3–4 but not fully enumerated in the excerpt).
- ΣΛ reconstruction on Chars74k: AUC = 71% vs proposed = near 100% in most other dataset/generator pairs (paper explicitly calls this one of only three notable low points).
- ΣΛ reconstruction on Biosecure: AUC = 86% vs proposed = near 100% in most other dataset/generator pairs (explicitly named exception).
- DHG on Biosecure: AUC = 86% vs proposed = near 100% in most other dataset/generator pairs (explicitly named exception).
- SDT on Chars74k: AUC = 71% vs proposed = near 100% in most other dataset/generator pairs (explicitly named exception).
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.11700.

Fig 2: Examples of movement trajectories and their corresponding velocity profiles for a real sample (top row, vr) and seven synthetic counterparts, each
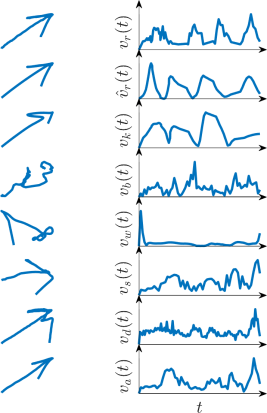
Fig 3: Classification of human versus synthetic samples: AUC results (higher is better).
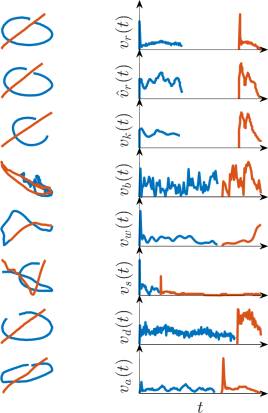
Fig 4: Classification of human versus synthetic samples: EER results (lower is better).
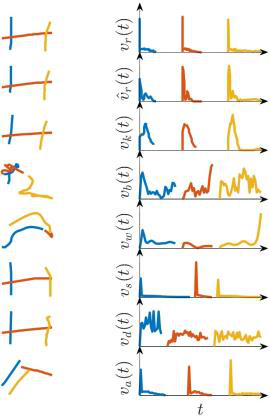
Fig 5: Few-shot classification of human versus synthetic samples: AUC results (higher is better). The “Training size” legend group denotes the number of
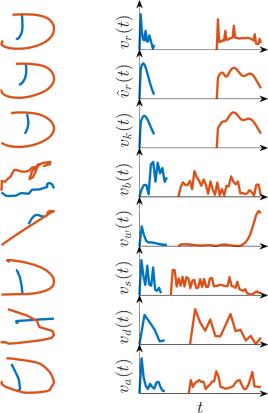
Fig 6: Few-shot classification of human versus synthetic samples: EER results (lower is better). The “Training size” legend group denotes the number of
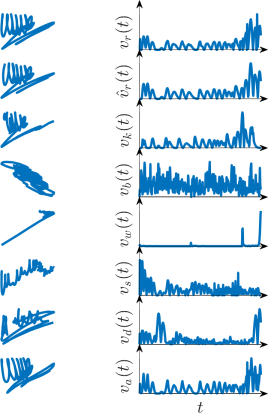
Fig 7: OOD classification of human versus synthetic samples: AUC results (higher is better). Our classifier is trained on a single dataset, denoted in the
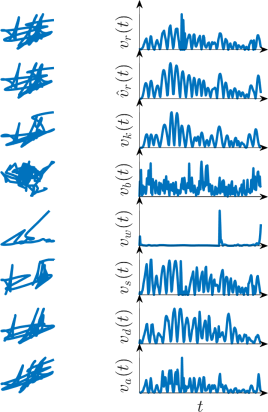
Fig 8: OOD classification of human versus synthetic samples: EER results (lower is better). Our classifier is trained on a single dataset, denoted in the
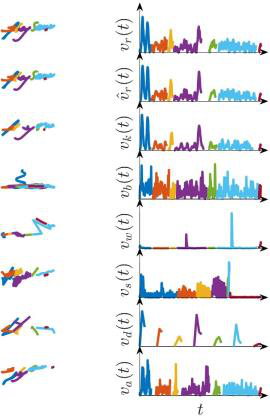
Fig 8 (page 6).
Limitations
- The excerpt does not provide full per-dataset/per-generator numeric tables for all comparisons, so some result granularity is only visible in the figures/tables referenced by the authors.
- The detector is evaluated primarily on synthetic data generated from the same public datasets; this is strong for in-domain robustness but may understate real-world attacker adaptation with novel generators or post-processing.
- No statistical significance tests, confidence intervals, or variance across random seeds are reported in the excerpt, and the authors state they trained each model once because prior seed variation showed no differences.
- The out-of-domain protocol is useful but still constrained: it tests transfer across known public datasets, not against truly unseen acquisition setups, languages, or adversaries.
- The method assumes access to sequential trajectory data; it does not address cases where only image-based offline handwriting is available.
- High performance may partly reflect artifacts in synthetic timestamp/spatial consistency for some generators, especially affine synthesis, rather than purely deep semantic differences between human and machine movement.
Open questions / follow-ons
- How well does the detector hold up against adaptive attackers who optimize directly against the GRU decision boundary or train a generator to evade this specific classifier?
- Would performance remain high if synthetic samples were post-processed with realistic timestamp jitter, device noise, or human replay traces instead of the generator defaults used here?
- Can a smaller, calibrated model expose which temporal signatures are most discriminative, so the system can be hardened against future generators rather than just detecting current ones?
- How does the approach transfer to offline handwriting images, pen-pressure-rich stylus data, or multimodal liveness checks that combine handwriting with touch dynamics and context signals?
Why it matters for bot defense
For bot defense, this paper is interesting because it suggests that raw handwriting trajectories already contain enough structure to support a strong liveness-style classifier, even against several modern generators. A CAPTCHA or reauthentication flow that asks for short handwriting input could potentially use a lightweight recurrent detector like this to reject obvious replay or synthetic traces without requiring a heavy feature pipeline. The caution is that the reported success is strongest on public datasets and known synthesizers; a production system would still need adversarial evaluation, calibration, and monitoring for generator drift, especially if attackers start training directly against the detector or emulate device-specific timing artifacts. The few-shot and out-of-domain results are encouraging, but they also imply that training data diversity matters a lot: MobileTouch’s breadth appears to improve transfer, so an operational system would likely need broad collection across devices and input modalities before being trusted at scale.
Cite
@article{arxiv2601_11700,
title={ Telling Human and Machine Handwriting Apart },
author={ Luis A. Leiva and Moises Diaz and Nuwan T. Attygalle and Miguel A. Ferrer and Rejean Plamondon },
journal={arXiv preprint arXiv:2601.11700},
year={ 2026 },
url={https://arxiv.org/abs/2601.11700}
}