
Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances
Source: arXiv:2601.08516 · Published 2026-01-13 · By Ziqi Ding, Yunfeng Wan, Wei Song, Yi Liu, Gelei Deng, Nan Sun et al.
TL;DR
This paper argues that audio CAPTCHAs have quietly become brittle in the face of modern speech and audio foundation models. The authors do two things in one framework, AI-CAPTCHA: first, they build ACEVAL, an evaluation setup that attacks deployed audio CAPTCHAs with both large audio language models (LALMs) and an ASR+LLM pipeline; second, they propose ILLUSIONAUDIO, a new audio CAPTCHA that uses sine-wave speech illusions plus a non-invertible downsampling step to preserve human interpretability while depriving AI models of the acoustic structure they rely on.
The core result is a sharp human–AI asymmetry. Across seven deployed audio CAPTCHA schemes, the paper reports high AI bypass rates and poor human usability, then shows that ILLUSIONAUDIO achieves 0% bypass rate against all tested LALM and ASR attacks while maintaining a 100% first-attempt human success rate in their user study. The paper’s main claim is not just that existing audio CAPTCHAs are weak, but that accessibility-oriented designs can be rethought around perceptual phenomena that humans can decode and current AI systems struggle to generalize from.
Key findings
- Across seven deployed audio CAPTCHAs, the authors report average AI bypass rates of 41.67% for LALM-based solvers and 49.99% for ASR-based solvers.
- The seven evaluated schemes include four content-based systems (Geetest, Google, MTCaptcha, Telephone-Audio) and three rule-based systems (Math, Character, Arkose Labs).
- ILLUSIONAUDIO achieved 0% bypass rate against all tested LALM-based solvers: Qwen-Audio-Chat, SeaLLMs-Audio-7B, and Qwen2-Audio-7B-Instruct, under both zero-shot and chain-of-thought prompting.
- ILLUSIONAUDIO achieved 0% bypass rate against both ASR-based solvers: GPT-4o-Transcript and GPT-4o-mini-Transcript, in both prompt-guided and non-prompt-guided settings.
- In the user study, existing schemes often required multiple attempts; Google had a 23.33% first-attempt success rate, Telephone-Audio 23.33%, Character 50.00%, and Arkose Labs 76.67%.
- ILLUSIONAUDIO reached a 100% first-attempt success rate in the 63-participant study, including 36 PVIs and 27 sighted users.
- Without the clean reference audio, ILLUSIONAUDIO became much harder for humans: 96.67% of participants needed more than three attempts, and 0% succeeded in the first two attempts.
- The irreversible conversion module was decisive against simple heuristics: an RMS-based attack reached 100% bypass rate when the module was disabled, and 0% when it was enabled.
Threat model
The adversary is a black-box web attacker trying to automate audio CAPTCHA solving at scale using repeated access to public challenges, off-the-shelf ASR systems, and advanced LALMs. They know the broad CAPTCHA structure but not the internal generation implementation or training data. They cannot directly access the CAPTCHA internals, and the paper does not consider attackers who fine-tune specifically on sine-wave speech or bypass the CAPTCHA layer through unrelated application flaws.
Methodology — deep read
The threat model is a black-box web attacker trying to automatically solve audio CAPTCHAs at scale for abuse such as account creation or credential stuffing. The attacker can repeatedly request challenges from public websites, knows the broad CAPTCHA type (content-based vs. rule-based), and can use off-the-shelf AI systems, including LALMs and ASR models. The authors explicitly exclude attacks that bypass the CAPTCHA layer entirely, and they do not evaluate attackers who fine-tune on sine-wave speech. That matters because the proposed defense is built around a specific perceptual gap, so the evaluation is strongest against zero-shot or generic AI solvers rather than a fully adaptive adversary.
On the data side, ACEVAL evaluates seven deployed audio CAPTCHA schemes with 30 samples per scheme, for 210 AI-evaluation instances total. The seven schemes are Geetest, Google, MTCaptcha, Telephone-Audio, Math, Character, and Arkose Labs. They say samples were generated using official open-source implementations with default settings. For usability, they run a human study with 240 CAPTCHA instances spanning the seven baselines plus ILLUSIONAUDIO; 63 participants took part, including 36 visually impaired participants (PVIs) and 27 sighted users. Each participant solved 12 distinct CAPTCHAs, producing 756 total trials. The paper also reports an ablation on ILLUSIONAUDIO’s components and includes an RMS-based heuristic attack to test whether the design leaks simple amplitude cues. The source does not provide a public dataset release or frozen benchmark split beyond the generated sample sets described in the evaluation.
ACEVAL’s solver architecture is deliberately broader than classic ASR-only attacks. The LALM-based solver feeds raw audio directly into an audio-language model, which outputs a natural-language interpretation that is then parsed into a final answer. The paper instantiates this with Qwen-Audio-Chat, SeaLLMs-Audio-7B, and Qwen2-Audio-7B-Instruct, and tests both zero-shot and chain-of-thought prompting. The ASR-based solver is two-stage: first the audio is transcribed by GPT-4o-Transcript or GPT-4o-mini-Transcript, in either prompt-guided or non-prompt-guided mode; then GPT-4o performs semantic reasoning on the transcript to derive the answer. This is an important methodological point: for rule-based CAPTCHAs, the attack is not just transcription, but transcription plus downstream reasoning. A concrete example is a Math CAPTCHA: the ASR stage extracts the spoken arithmetic problem, and GPT-4o then solves the math rather than merely returning the transcript.
ILLUSIONAUDIO has three modules. First, Automated Audio Generation builds a pool of short intelligible audio clips from text prompts using a text-to-speech model. The algorithm iteratively synthesizes K candidates per prompt, discards clips longer than 2 seconds, scores them for intelligibility, transcribes them with ASR, and uses transcription feedback to refine the prompt over up to R refinement rounds until a target dataset size is reached. The paper gives pseudocode (Algorithm 1) but does not fully specify the exact intelligibility scorer, the concrete TTS model name beyond a citation to hexgrad (2024), or all prompt-refinement details. Second, Illusionary Audio Generation transforms clean speech into sine-wave speech, keeping temporal envelope and coarse formant trajectories while stripping away conventional spectral detail. This is the central perceptual illusion: humans can often reconstruct intelligible speech from sparse sinusoidal cues, but current AI systems are much less robust to this representation. Third, Audio CAPTCHA Generation wraps the illusionary audio in an option-based interface: users hear a clean reference and then select the matching illusionary clip from a small randomized set. To reduce shortcut learning, the design randomizes task framing and option composition, and sometimes includes the unmodified clean audio to prevent amplitude-based heuristics.
The paper adds a randomized irreversible conversion module after the sine-wave transform: ~ x = Ssine(x; ψ), then x^ = M(~ x; ϕ) with ϕ sampled uniformly from [0.5, 0.8] via random downsampling. The authors claim this removes enough information to make reconstruction difficult while preserving human intelligibility. In ablation, this module did not change the 0% bypass rate against the LALM and ASR solvers, but it was necessary to stop an RMS-based attacker from exploiting amplitude patterns. Evaluation uses bypass rate for AI attacks and human success rate for usability. All experiments were run on a workstation with an Intel Xeon 6 6787P CPU and two NVIDIA RTX 5090 GPUs. The paper does not report multi-seed statistical testing, confidence intervals, or significance tests, so the evidence is primarily point-estimate based.
One concrete end-to-end example is the usability setting for ILLUSIONAUDIO: a user hears a clean reference audio first, then a set of candidate clips, one of which is the illusionary version of the same content. The user does not type a transcript; instead they match the perceptually primed reference against the sine-wave surrogate. In the reported study, this led to 100% first-attempt success. Without the clean reference, usability collapsed: nearly all participants needed multiple tries, which supports the authors’ claim that the reference is acting as a necessary perceptual priming cue rather than a cosmetic addition. Reproducibility is partial: the paper references a project website and open-source implementations for baseline CAPTCHAs, but the excerpt does not indicate a public release of the full AI-CAPTCHA code, generation scripts, or human-study raw data.
Technical innovations
- ACEVAL extends audio CAPTCHA evaluation beyond ASR-only attacks by including end-to-end LALM solvers and an ASR-plus-LLM reasoning pipeline.
- ILLUSIONAUDIO uses sine-wave speech illusions as the core security primitive, aiming to preserve human intelligibility while removing the acoustic features exploited by modern AI solvers.
- The irreversible conversion module adds randomized downsampling after sine-wave synthesis to block simple reconstruction and amplitude-based heuristic attacks.
- The option-based interaction design replaces direct transcription with matching-based selection, which the authors argue is more accessible for users and harder to brute-force blindly.
Datasets
- Seven deployed audio CAPTCHA schemes — 210 AI-evaluation samples total (30 per scheme) — generated from official open-source implementations with default configurations
- Human usability study set — 240 CAPTCHA instances total — collected for 63 participants (36 PVIs, 27 sighted users)
Baselines vs proposed
- Geetest: first-attempt human success = 100.00% vs proposed: 100.00%
- Google: first-attempt human success = 23.33% vs proposed: 100.00%
- MTCaptcha: first-attempt human success = 80.00% vs proposed: 100.00%
- Telephone-Audio: first-attempt human success = 23.33% vs proposed: 100.00%
- Math: first-attempt human success = 80.00% vs proposed: 100.00%
- Character: first-attempt human success = 50.00% vs proposed: 100.00%
- Arkose Labs: first-attempt human success = 76.67% vs proposed: 100.00%
- LLM/ASR attacks on existing schemes: bypass rate = up to 100.00% vs proposed: 0.00%
- RMS-based attack without irreversible conversion: bypass rate = 100.00% vs proposed with irreversible conversion: 0.00%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.08516.

Fig 1: Architecture of content-based Audio CAP-
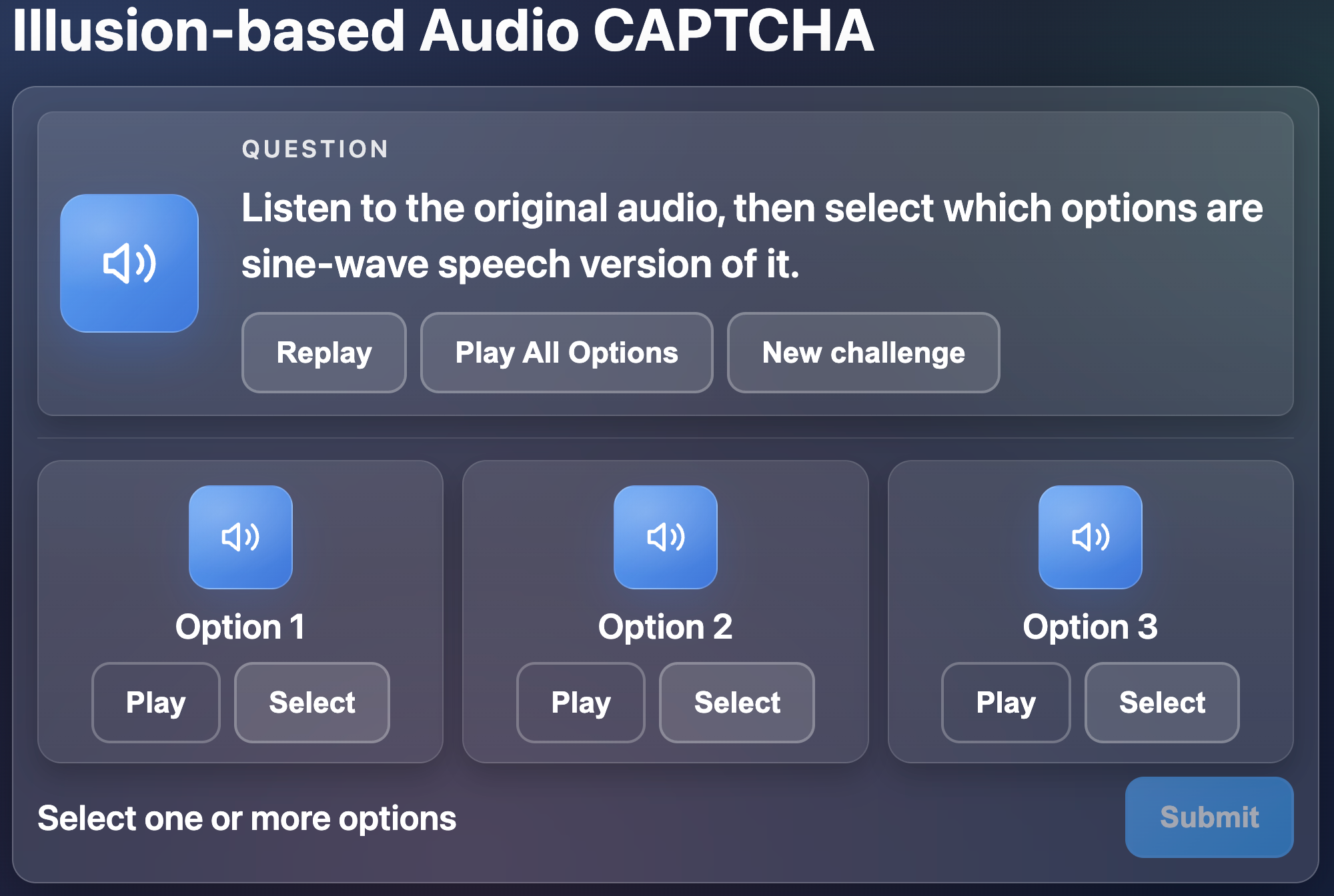
Fig 3: Interface of our CAPTCHA.
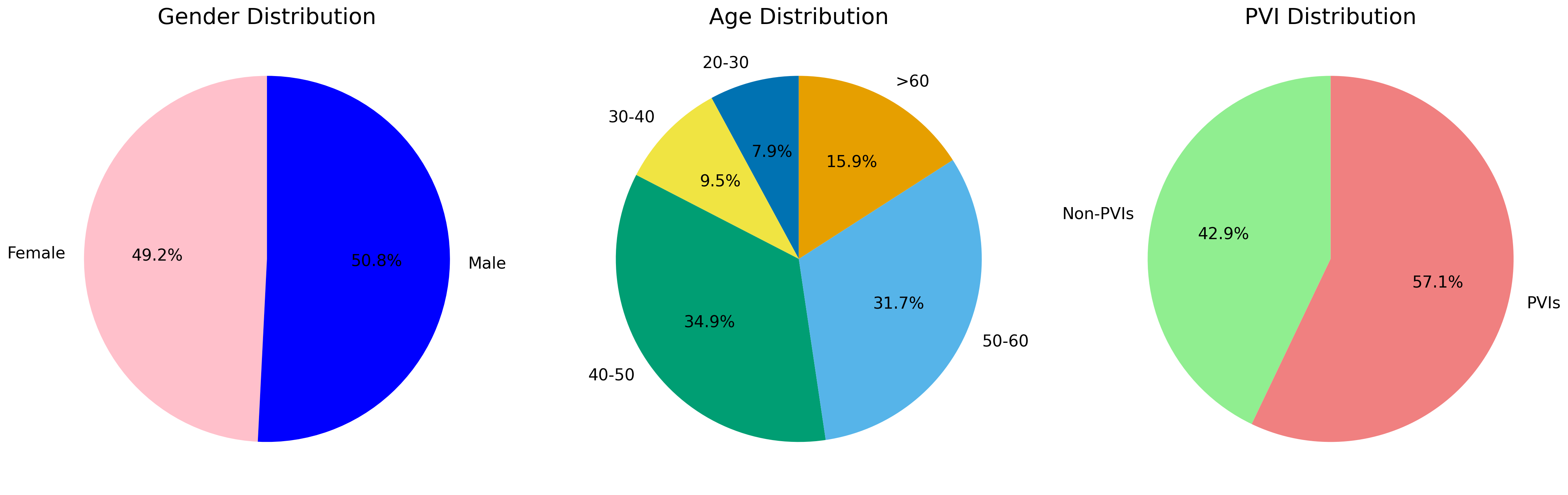
Fig 4: Demographic distributions of participants.
Limitations
- The user study is modest in size (63 participants), limiting statistical power and subgroup analysis.
- The evaluation was run in a controlled setting, so real-world factors like ambient noise, device variability, hearing differences, and latency were not fully captured.
- Adaptive adversaries that fine-tune on sine-wave speech were not evaluated, leaving open the question of how quickly the proposed asymmetry erodes under targeted training.
- The paper reports point estimates but not confidence intervals or significance tests, so the strength of some comparisons is hard to judge statistically.
- The exact implementation details of the intelligibility scorer, prompt refinement, and some generation settings are not fully specified in the excerpt.
Open questions / follow-ons
- How robust is sine-wave speech CAPTCHA under adaptive training on large synthetic or collected sine-wave datasets?
- Can the perceptual gap be preserved if the challenge is diversified with other auditory illusions or randomized transformations?
- How does ILLUSIONAUDIO behave under realistic deployment conditions such as background noise, cheap speakers, and hearing impairment variability?
- Can the evaluation framework be extended to cover human-in-the-loop or tool-augmented attackers beyond pure LALM/ASR pipelines?
Why it matters for bot defense
For bot-defense practitioners, the main takeaway is that audio CAPTCHA security assumptions have shifted: if the challenge is fundamentally transcribable or instruction-following, modern AI may already be close to human performance. This paper suggests two practical implications. First, if you are auditing an existing audio CAPTCHA, you should test it not just with ASR but with LALMs and with a transcript-plus-reasoning pipeline, because rule-based designs can fail even when transcription is imperfect. Second, if you are designing a replacement, perceptual-illusion approaches may create a stronger human/AI split than more noise, distortion, or background masking, which often just make things worse for both humans and machines.
At the same time, a defender should treat the result as a starting point, not a permanent solution. The clean-reference priming step is doing real work for usability, and the security story depends on the assumption that AI models do not yet generalize well to sine-wave speech. In practice, a bot-defense engineer would want to stress-test this idea against adaptive models, collect telemetry on solve times and failure modes across devices, and think about how to rotate or diversify the illusion so that the challenge does not become a static target for model training.
Cite
@article{arxiv2601_08516,
title={ Robust CAPTCHA Using Audio Illusions in the Era of Large Language Models: from Evaluation to Advances },
author={ Ziqi Ding and Yunfeng Wan and Wei Song and Yi Liu and Gelei Deng and Nan Sun and Huadong Mo and Jingling Xue and Shidong Pan and Yuekang Li },
journal={arXiv preprint arXiv:2601.08516},
year={ 2026 },
url={https://arxiv.org/abs/2601.08516}
}