
VIPER Strike: Defeating Visual Reasoning CAPTCHAs via Structured Vision-Language Inference
Source: arXiv:2601.06461 · Published 2026-01-10 · By Minfeng Qi, Dongyang He, Qin Wang, Lefeng Zhang
TL;DR
VIPER Strike studies visual reasoning CAPTCHAs (VRCs) as a combined perception-and-reasoning problem: the attacker must localize the right object(s) in a cluttered image and then follow natural-language constraints such as attributes, comparison, and spatial relations. The paper argues that prior solvers split into two weak camps: vision-centric systems that overfit to fixed templates, and LLM-centric systems that reason well in language but miss fine-grained visual details. VIPER’s core idea is to explicitly separate these two subproblems, using a detector to turn the image into structured object records and then using an LLM only on the pruned, semantically relevant candidate set.
Empirically, the paper reports strong cross-provider attack performance on six major VRC platforms: VTT, Geetest, NetEase, Dingxiang, Shumei, and Xiaodun. The headline result is up to 93.2% success, with reported gains over GraphNet (83.2%), the Holistic approach (89.5%), and Oedipus (65.8%). The authors also test backbone swap robustness across GPT, Grok, DeepSeek, and Kimi, saying accuracy stays above 90% in those settings. On the defensive side, they propose Template-Space Randomization (TSR), which perturbs question phrasing while keeping semantics fixed, and report that it measurably reduces solver performance on a 600-question custom set.
Key findings
- VIPER reports up to 93.2% success across six commercial VRC providers (VTT, Geetest, NetEase, Dingxiang, Shumei, Xiaodun), which the authors characterize as approaching human-level performance.
- Compared with GraphNet, VIPER improves from 83.2% to 93.2% on the reported benchmark summary, a +10.0 point gain.
- Compared with the Holistic approach, VIPER improves from 89.5% to 93.2%, a +3.7 point gain.
- Compared with Oedipus, VIPER improves from 65.8% to 93.2%, a +27.4 point gain.
- The paper claims the system sustains accuracy above 90% when swapping LLM backbones among GPT, Grok, DeepSeek, and Kimi.
- The benchmark contains 6,000 VRC challenges in total, plus a companion dataset of 1,200 multi-object annotated VRC scenes for perception training and assessment.
- For the defense study, TSR was evaluated on 600 customized questions and consistently reduced solver success rate, but the excerpt does not give the exact deltas.
- The authors state a zero-shot GPT-4o evaluation across CAPTCHA types found VRC accuracy at 31% versus roughly 50% on reCAPTCHA-style behavior challenges, highlighting VRCs as the harder frontier.
Threat model
The adversary is a remote black-box solver with access only to publicly rendered CAPTCHA images and prompts, the ability to submit answers, and binary success/failure feedback. The attacker may use any local compute, pretrained vision-language models, specialized detectors, and symbolic reasoning, but cannot access the defender’s backend, private challenge generator, gradients, or hidden labels. The defender controls challenge composition, presentation, and server-side verification, but the content is assumed visible to the client and therefore observable by the attacker.
Methodology — deep read
Threat model first: the attacker is an external black-box solver interacting only through the public CAPTCHA interface. The attacker can capture the rendered image and accompanying prompt, submit answers, and observe only binary correctness feedback. They cannot access backend logic, private training data, gradients, or intermediate challenge-generation states. The defender is the VRC provider, assumed to control template generation and verification but not to hide the content from the client. This makes VIPER a practical attack study rather than a white-box exploit: it is explicitly about solving publicly visible challenges under normal user-like constraints, not about software compromise or side channels.
The data pipeline is one of the paper’s main contributions. The benchmark aggregates six real-world VRC providers: Tencent VTT, Xiaodun, Geetest, NetEase, Dingxiang, and Shumei. The paper says it crawled 12,000 samples from Tencent’s VTT service using Selenium and incorporated five additional datasets from an open-source benchmark; the combined benchmark totals 6,000 challenges for evaluation according to the contribution summary, but the excerpt also lists 12,000 per-source counts for some providers, so the exact aggregation logic is not fully clear from the provided text. Regardless, the authors normalize all datasets into a unified object-centric format with per-object bounding boxes and compound labels capturing shape, color, and orientation. For datasets without box annotations, objects were manually labeled using a custom interface. For evaluation, they further sample 1,000 images per provider and annotate a single correct click region per image, turning the task into a one-answer coordinate classification problem: a prediction counts as correct if the clicked coordinate falls inside that annotated region. The companion perception dataset contains 1,200 multi-object annotated VRC scenes, intended to train and assess the detector. Table 2 in the paper summarizes provider-specific characteristics such as object counts, object types, prompt variety, and reasoning complexity.
Architecturally, VIPER is a modular pipeline with three stages: Exterior, Viewer, and Policymaker. Exterior just ingests the rendered image and instruction and formats the answer. Viewer handles structured perception. Its backbone is a multi-object detector trained to emit compound labels aligned to VRC language: each label encodes shape × color × orientation, spanning 91 categories over alphanumeric symbols and geometric primitives plus five colors and two orientations. The detector is trained on the unified multi-provider corpus with resized 640×640 inputs, standard augmentations (mosaic, flipping, color jittering), and a compound loss that combines localization, objectness, and classification terms. At inference, the detector outputs labeled boxes and centers. Then QIE (Question Information Extractor) parses the question into structured slots: referenced object type, color, orientation, and relation cues. Integrator performs partial matching between QIE slots and detector outputs, treating missing fields as wildcards and using predefined type maps for abstract categories like “letter,” “number,” or “3D object.” If the query is relational, RPIE (Relative Position Information Extractor) takes the relation cue and projected reference center, shifts by a fixed offset in the indicated direction, and tests whether the probe point lies inside any candidate box. The output is an augmented candidate set with explicit reference-target links. Policymaker then builds a task-conditioned prompt for an LLM, using the original question plus the structured candidate set and relation type. The LLM is constrained to output a single pixel coordinate; no chain-of-thought is requested. For direct attribute queries it selects the exact match, for spatial queries it uses the linked target or relation geometry, and for comparative queries it computes area or positional extrema over the candidate boxes.
Training and inference details are only partially specified in the excerpt. The paper says the detector is trained on the aggregated multi-provider corpus with compound-label normalization and standard augmentations, but the excerpt does not provide the number of epochs, batch size, learning rate, optimizer, seed strategy, or whether detector weights are released. In evaluation, the authors compare VIPER against three baseline families reimplemented on the same benchmark for fairness: Holistic (modular detector plus rule-based logic), VRC-GraphNet (graph neural network over object nodes and spatial/semantic edges), and Oedipus (LLM-driven decomposition and chain-of-thought reasoning). They also define two ablations: R1, an LLM-only multimodal solver that feeds image and instruction directly to the model; and R2, Detector → Prompt, which appends all detections to the prompt without QIE, Integrator, or RPIE. The paper claims to evaluate across four dimensions: component ablation, baseline comparison, LLM backbone swap, and response time. The excerpt does not include the full numerical breakdown by provider or by ablation, only the headline maxima and comparative summary numbers. A concrete end-to-end example from the text is: for “Please click on the object directly below the letter ‘T’,” QIE extracts a T reference and the relation “below”; Integrator selects all T detections; RPIE projects downward from each T center and finds the box containing that probe point; Policymaker then returns the linked target center as the final click coordinate.
Reproducibility is mixed. The authors say they publicly release the benchmark and raw data/annotations via Zenodo, which is a strong reproducibility signal for the evaluation side. They also describe the full pipeline and pseudo-code for RPIE, plus example serializations and ontology tables. However, the excerpt does not confirm release of training code, detector weights, prompt templates, or the exact LLM API settings for each backbone. The defense TSR is also only described at a high level: synonym substitution, relation rewording, and indirection over 600 customized questions, with no exact ablation or statistical test shown in the excerpt. So the work is fairly transparent at the system-design level, but several implementation knobs remain underspecified in the available text.
Technical innovations
- A structured VRC solver that decouples perception, semantic parsing, and reasoning instead of relying on a monolithic multimodal model.
- Compound-label object detection where each box directly encodes shape, color, and orientation to reduce downstream fusion ambiguity.
- A query parser plus Integrator that performs wildcard matching against detector outputs and supports abstract categories such as letters, numbers, and 3D objects.
- A relative-position inference module (RPIE) that turns spatial language into geometric probe-point tests over bounding boxes.
- Template-Space Randomization (TSR), a lightweight phrasing defense that preserves semantics while perturbing the solver’s language alignment.
Datasets
- VTT — 12,000 samples crawled via Selenium from Tencent’s official VTT service
- Xiaodun — 12,000 samples — source: open-source VRC benchmark
- Geetest — 12,000 samples — source: open-source VRC benchmark
- NetEase — 12,000 samples — source: open-source VRC benchmark
- Dingxiang — 12,000 samples — source: open-source VRC benchmark
- Shumei — 3,000 samples — source: open-source VRC benchmark
- Companion multi-object VRC scene dataset — 1,200 annotated scenes — source: released by authors
- Evaluation subset — 1,000 images per provider — manually annotated one-answer click regions
Baselines vs proposed
- GraphNet: success rate = 83.2% vs proposed: 93.2%
- Holistic: success rate = 89.5% vs proposed: 93.2%
- Oedipus: success rate = 65.8% vs proposed: 93.2%
- GPT-4o zero-shot on VRCs: accuracy = 31% vs behavior-centric reCAPTCHA-style challenges ≈ 50%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.06461.
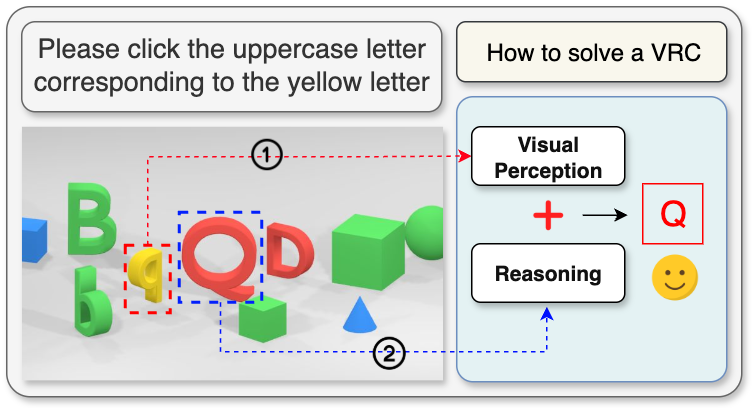
Fig 1: Example of a Visual Reasoning CAPTCHA
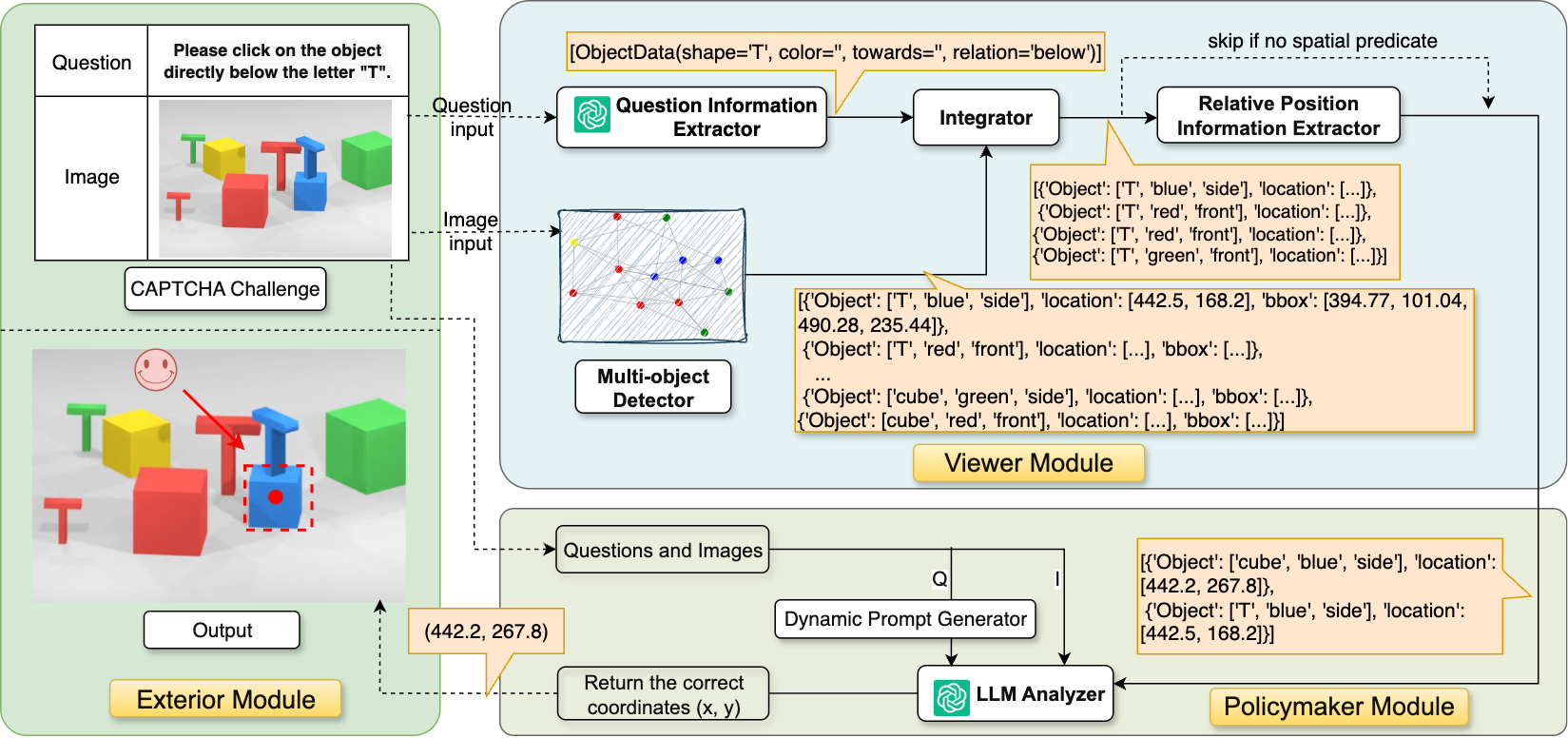
Fig 2: VIPER end-to-end pipeline. Exterior ingests image I and instruction q. Viewer conducts structured perception:
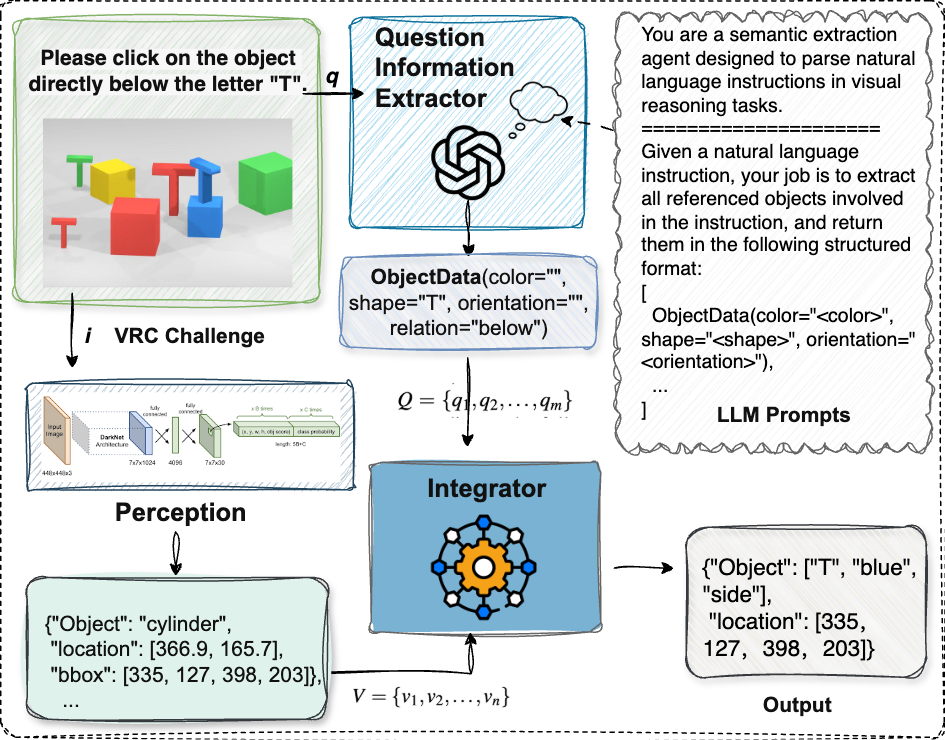
Fig 3: Semantic extraction and alignment. QIE
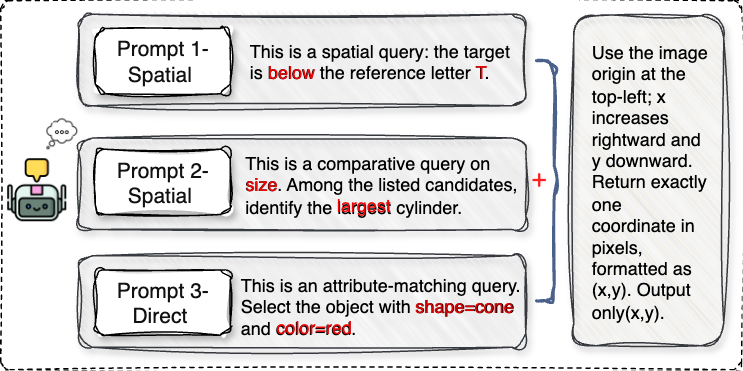
Fig 4: Task-conditioned prompts for Policymaker
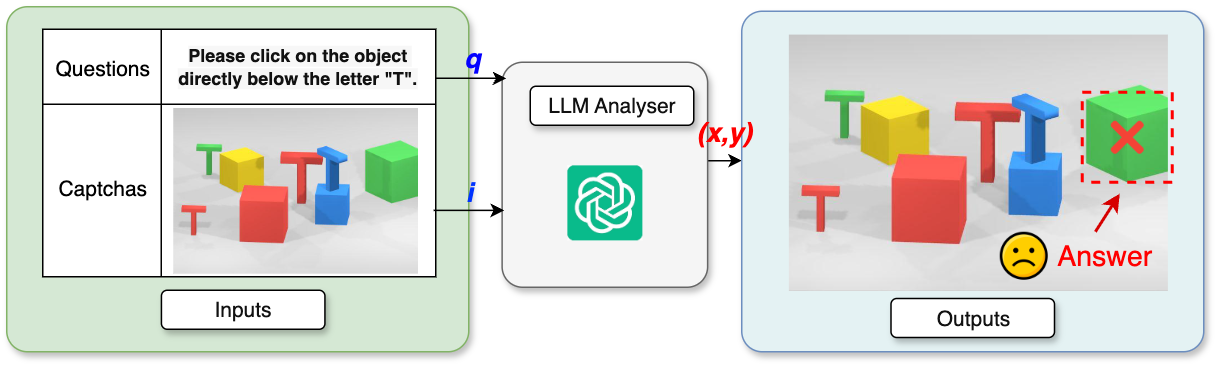
Fig 5: Schematic of ablation variants. R1 relies
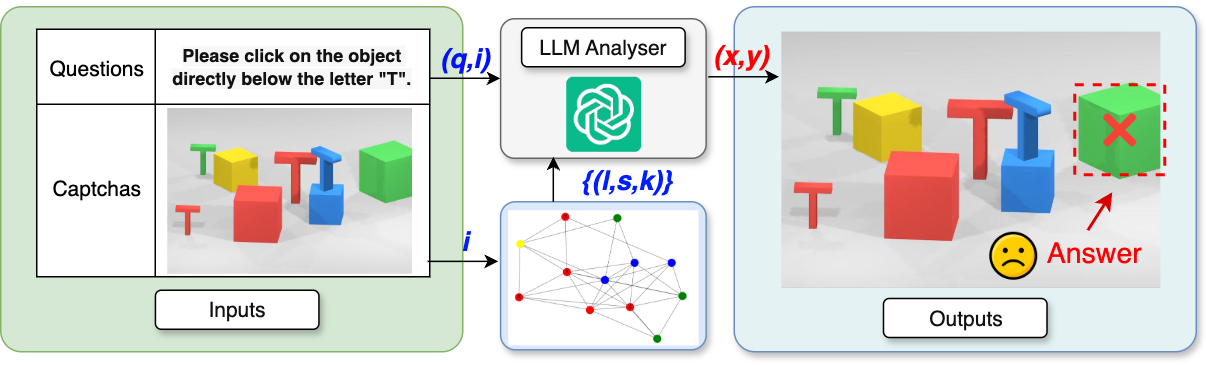
Fig 6: Component-wise ablation of the VIPER framework across four LLM backends. Each panel reports
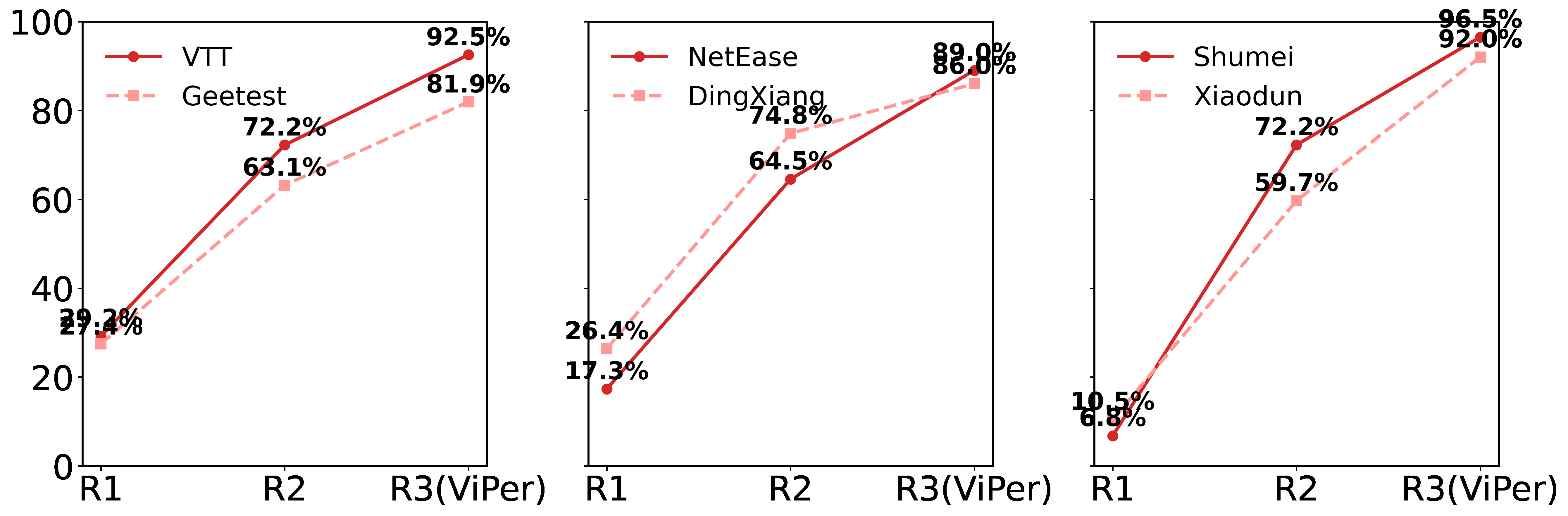
Fig 7: Comparison with benchmarks on six VRC platforms. Each subfigure reports average accuracy across
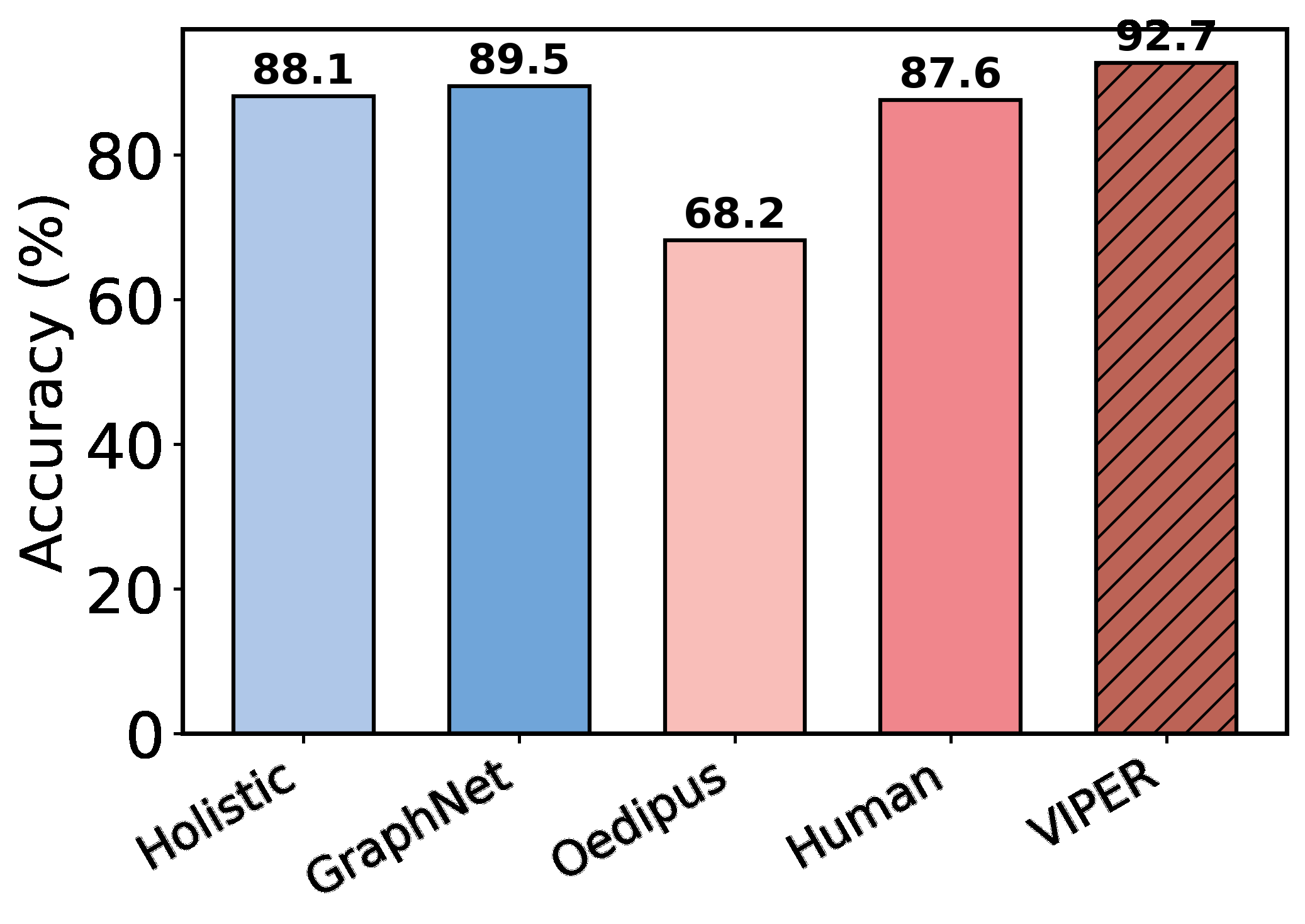
Fig 8: Accuracy comparison of four LLM back-
Limitations
- The excerpt does not report full per-provider results, so it is hard to tell whether the 93.2% headline comes from a single easy provider or a balanced macro-average.
- Training details for the detector and prompt pipeline are incomplete in the provided text: epochs, optimizer, learning rate, batch size, and seed strategy are not specified.
- The evaluation uses a one-answer click-region setup on 1,000 sampled images per provider, which may simplify inherently ambiguous challenges relative to true production use.
- The defense TSR is only preliminarily evaluated on 600 customized questions, with no exact before/after numbers or statistical significance reported in the excerpt.
- The attack relies on a trained detector and structured parsing; if providers shift templates substantially or introduce novel object ontologies, performance may degrade.
- No adversarially adaptive defender is modeled beyond TSR; there is no closed-loop retraining against VIPER or an online challenge mutation study.
Open questions / follow-ons
- How well does VIPER transfer to VRCs with unseen ontologies, more than two orientations, or relation types beyond left/right/above/below?
- How much of the gain comes from the detector versus the prompt-conditioning logic, especially under a stronger detector or a stronger multimodal LLM?
- Can TSR be hardened into an adaptive defense that preserves human solve rate while forcing continual attacker retraining?
- What is the best evaluation protocol for VRC security: one-answer click regions, full-task exactness, or interaction-time/behavioral metrics?
Why it matters for bot defense
For bot-defense practitioners, the main lesson is that VRC security depends on the weakest link in the perception-to-reasoning chain. If the challenge can be reduced to a stable ontology of object labels plus a small set of relation types, then a well-structured attack can outperform generic multimodal prompting by explicitly separating detection from reasoning. In practice, that means template diversity and linguistic variation matter as much as visual clutter: if the solver can normalize the scene into a compact candidate set, the remaining problem may become a straightforward selection task for an LLM.
From a defensive standpoint, TSR is the most actionable idea in the paper: perturb the language surface while preserving semantics, so that attackers cannot rely on brittle phrase templates or fixed relation wording. But the paper also suggests that purely linguistic randomization is probably insufficient on its own if the visual ontology stays stable. A bot-defense engineer would likely respond by increasing ontology diversity, introducing cross-modal dependencies that are harder to parse into fixed slots, and evaluating against structured solvers like VIPER rather than only against generic OCR or end-to-end multimodal baselines.
Cite
@article{arxiv2601_06461,
title={ VIPER Strike: Defeating Visual Reasoning CAPTCHAs via Structured Vision-Language Inference },
author={ Minfeng Qi and Dongyang He and Qin Wang and Lefeng Zhang },
journal={arXiv preprint arXiv:2601.06461},
year={ 2026 },
url={https://arxiv.org/abs/2601.06461}
}