
Reinforcement Learning of Large Language Models for Interpretable Credit Card Fraud Detection
Source: arXiv:2601.05578 · Published 2026-01-09 · By Cooper Lin, Yanting Zhang, Maohao Ran, Wei Xue, Hongwei Fan, Yibo Xu et al.
TL;DR
This paper addresses the challenge of credit card fraud detection in e-commerce using Large Language Models (LLMs), a domain where conventional machine learning methods relying on engineered features and tabular data fall short in handling unstructured textual signals and lack interpretability. The authors propose a novel reinforcement learning (RL) based approach that post-trains lightweight LLMs directly on raw textual transaction data to extract meaningful trust and risk signals without manual feature engineering. Specifically, they apply Group Sequence Policy Optimization (GSPO), a variant designed to optimize sequence-level rewards and avoid excessive output length, combined with a rule-based reward system balancing accuracy and explanation format adherence.
Experiments on a large real-world dataset comprising 9,900 chronological e-commerce transactions with rich structured and unstructured fields demonstrate substantial improvements in fraud detection F1-score after RL post-training compared to base models. The RL-trained models better calibrate decision boundaries, drastically reducing false positives ('hallucinated suspicion') while maintaining or improving recall. The approach also yields concise, interpretable natural language reasoning before verdicts, suitable for real-time deployment. The authors identify the exploration aspect of RL as enabling discovery of novel fraud indicators beyond static rules, advancing both accuracy and interpretability in a critical financial domain.
Key findings
- Applying GSPO reinforcement learning yields F1-score improvements of 120.90% (4B), 98.35% (8B), and 105.27% (14B) over base Qwen3 models on held-out test data.
- Post-training dramatically increases Specificity (True Negative Rate), e.g., 8B model's specificity improved by 336.14%, reducing false positive fraud flags significantly.
- Smaller 4B model exhibits balanced gains improving both Recall (+16.32%) and Specificity, while larger models prioritize precision leading to lowered recall.
- GSPO algorithm removes length normalization from objective, preventing reinforcement of unnecessarily long explanations and reducing average token counts.
- Compressed RL setup using predefined risk/trust signals produces more deterministic and shorter outputs but with slightly lower F1-scores than open-ended standard setup.
- RL-trained LLMs generate natural language reasons faithfully representing input data, with hallucination testing (using DeepEval) confirming high factual faithfulness in most cases.
- General-purpose large LLMs (e.g., GPT-4.1, GPT-5-mini, Claude4.5) perform worse than smaller specialized models, indicating a major calibration gap on domain-specific fraud detection.
- Rule-based reward balancing format versus accuracy (ratio 1:2.5) emphasizes fraud detection effectiveness while maintaining interpretability via explicit rationale output.
Threat model
The adversary is a fraudster performing financial fraud via e-commerce transactions with access to transactional and customer information but without direct access to the detection model internals or ability to perform white-box attacks. The model aims to detect fraud by analyzing raw transaction data and cannot rely on adversarial manipulations of its parameters or training data. Real-time latency constraints prevent exhaustive multi-round verification.
Methodology — deep read
Threat Model & Assumptions: The adversary is an attacker attempting financial fraud via e-commerce transactions, generating suspicious patterns in customer, shipping, payment, and device data. The model sees raw transaction data and binary fraud labels but not explicit intermediate fraud signals. No direct adversarial manipulation or white-box attacks on the model are considered.
Data: The dataset contains ~9,900 e-commerce transactions from a Chinese global payment provider over June 2023–June 2024. It is split chronologically into a training set (~4,900 samples, balanced fraud:legit ~47:53) and a test set (~5,000 samples, naturally imbalanced with ~10% fraud). Each transaction includes JSON fields covering order details, geographic and network indicators, payment info, shipping address, identity verification features, distance/consistency checks, and historical order info. Labels come from the issuing bank.
Architecture & Algorithm: Models evaluated are variants of the Qwen3 series LLMs (4B, 8B, 14B parameters). Starting from pre-trained weights, they are fine-tuned using Group Sequence Policy Optimization (GSPO), a reinforcement learning algorithm tailored for sequence-level reward optimization without length normalization in the objective to prevent output verbosity buildup. GSPO computes importance sampling ratios on full sequences, normalizes rewards relative to group outputs to stabilize gradients, and clips to control updates.
The model prompt includes three parts: task instruction, raw e-commerce order data (textual and structured), and output format requirements for labeled trust and risk signals followed by a binary fraud verdict. The output is a natural language reasoning chain explaining identified signals, wrapped in XML-like tags for parsing.
Training Regime: RL training uses online rollouts where multiple candidate completions per example are sampled per batch. Rewards are computed using a rule-based system combining accuracy of the final verdict (weighted x2.5) and adherence to output format for interpretable reasoning. Batch sizes, epoch counts, seed strategy, or hardware details are not specified in the truncated text.
Evaluation Protocol: Metrics include Accuracy, Recall (TPR), Specificity (TNR), Precision, False Positive Rate (FPR), and F1-Score on held-out test transactions with natural class imbalance. Response length (token count) and hallucination testing using DeepEval evaluate efficiency and faithfulness. Baselines include base Qwen3 LLMs without RL and nine other popular open-source and closed-source LLMs. Ablations compare standard open-ended prompt RL to compressed prompts with predefined fraud signals.
Reproducibility: Code release and frozen weights are not mentioned, dataset is closed and proprietary. Exact hyperparameters and training runs are not publicly disclosed.
Concrete example: For a transaction record with detailed textual and structured fields, the RL-trained model samples multiple reasoning chains identifying suspicious geographic mismatches and inconsistent payment patterns as risk signals, cites supporting evidence in natural language, then outputs a fraud verdict within specified tags. The detected fraud label is compared with ground truth for reward computation, and the advantage over group outputs is used to update the policy model parameters via GSPO. This loop iterates over the training data to refine the model's fraud sensitivity and explanation style.
Technical innovations
- Application of Group Sequence Policy Optimization (GSPO) to fraud detection LLM fine-tuning, removing length normalization to control output verbosity.
- Novel reward system combining rule-based accuracy and format adherence incentives, weighting accuracy 2.5x more.
- Use of reinforcement learning to enable exploratory discovery of trust and risk signals in unstructured transaction text without manual feature engineering.
- Design of open-ended natural language prompt directing LLMs to produce structured, interpretable reasoning chains before verdicts.
Datasets
- Chinese Global Payment Solution E-commerce Transaction Dataset — ~9,900 samples from June 2023 to June 2024 — proprietary/closed-source
Baselines vs proposed
- Qwen3-4B base: F1-Score = 0.1627 vs GSPO.S post-trained: 0.3594 (+120.90%)
- Qwen3-8B base: F1-Score = 0.1814 vs GSPO.S post-trained: 0.3598 (+98.35%)
- Qwen3-14B base: F1-Score = 0.1689 vs GSPO.S post-trained: 0.3467 (+105.27%)
- GPT-4.1: F1-Score=0.1491 vs Qwen3-14B GSPO.S: 0.3467 (+132.7%)
- Compressed RL setup (GSPO.C): slightly lower F1 than standard setup but reduced token count (e.g., Qwen3-14B GSPO.C tokens=60.7 vs GSPO.S tokens=370.5)
- 8B model specificity improved from 0.2064 baseline to 0.9002 after GSPO.S (+336.14%)
- General-purpose LLMs (GPT, Claude, Gemini) have F1-scores below 0.17, underperforming domain-specific RL-trained models
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.05578.
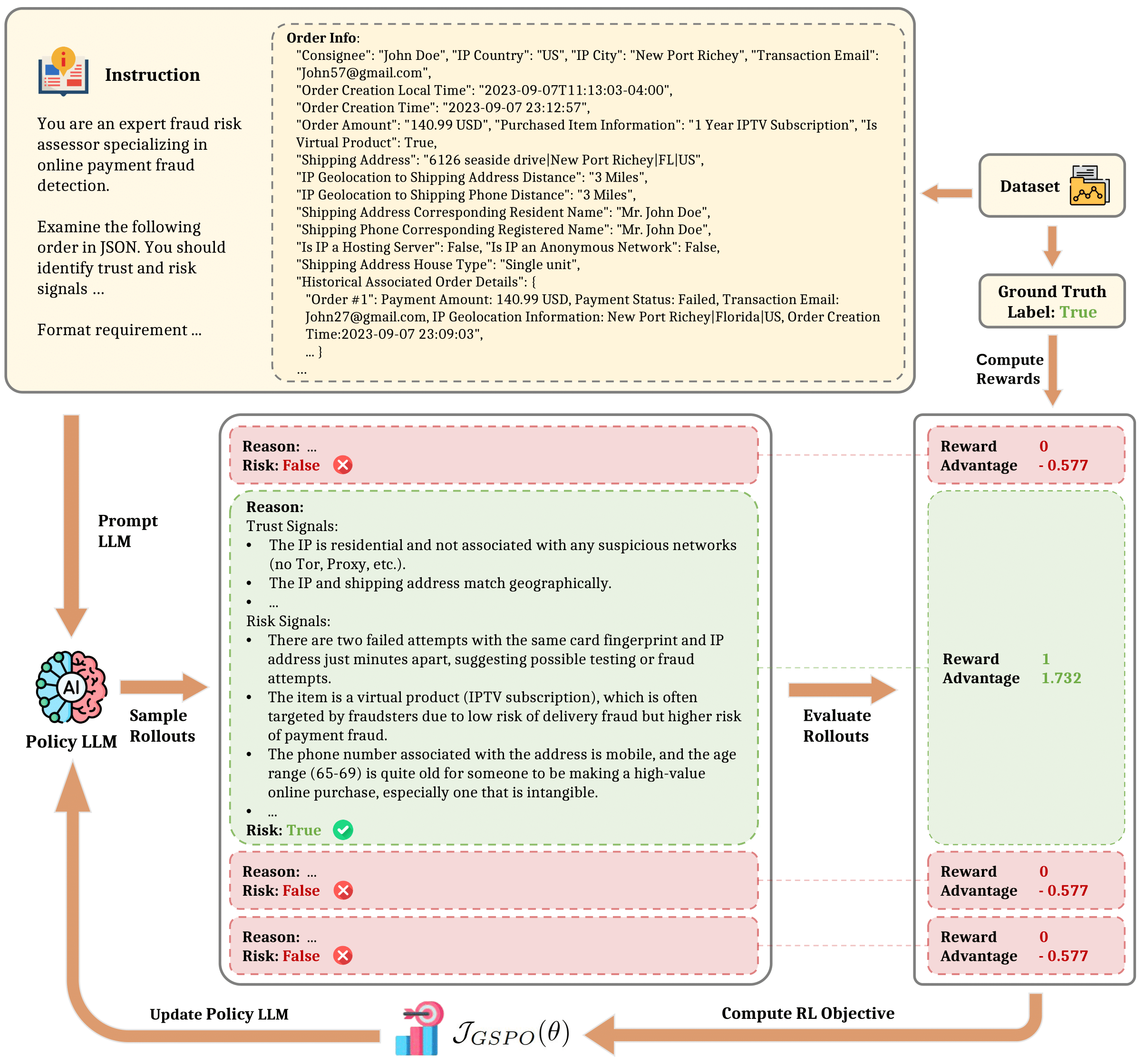
Fig 1: Overview of the GSPO reinforcement learning framework for fraud detection. For each input transaction,
Fig 2: Schematic of the reinforcement learning cycle for fraud detection. The forward path illustrates the

Fig 3: Prompt template for our fraud detection LMs.

Fig 4: An example output generated by the trained Qwen3-14B on the test set.

Fig 5: The prompt for the compressed setup and a response example generated by Qwen3-14B. The model is
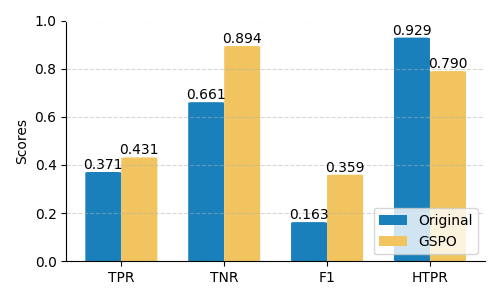
Fig 6: Performance comparison between the original LLMs and the trained versions with GSPO and standard
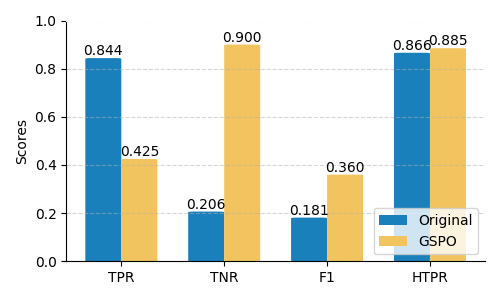
Fig 7: Example outputs of the trained Qwen3-4B and Qwen-8B, respectively. Some signals identified are omitted
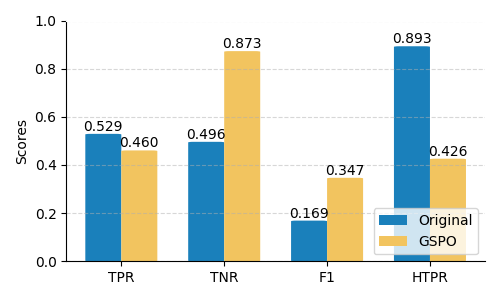
Fig 8: A response generated by the trained Qwen3-14B that fails the hallucination test, due to factual errors identified
Limitations
- Closed proprietary dataset limits external reproducibility and generalization assessment to other geographies or transaction types.
- No explicit adversarial evaluation to test robustness against adaptive fraudsters or evasion attempts.
- Training details such as epochs, batch size, hardware, and exact hyperparameter tuning are not fully disclosed.
- RL training may require significant compute and time costs, not quantified in the paper.
- No comprehensive analysis of model degradation or drift over time beyond held-out test sets.
- Hallucination testing, though performed, found some factual errors in reasoning outputs, indicating imperfect faithfulness.
Open questions / follow-ons
- How effective is the approach against active adversarial evasion tactics designed to mimic legitimate trust signals?
- Can the reinforcement learning framework adapt efficiently to entirely new fraud patterns emerging after deployment?
- What are the trade-offs in latency and computational cost when scaling RL training to larger LLMs or datasets?
- How does the model perform across different geographic regions, payment methods, or merchant categories beyond the studied dataset?
Why it matters for bot defense
This work demonstrates that domain-specific reinforcement learning can significantly improve the interpretability and accuracy of language model-based fraud detection on raw transaction data. Bot-defense engineers can view this as a novel methodology to incorporate unstructured textual signals into fraud and abuse classification tasks without heavy manual feature design. The interpretable reasoning chains produced by the RL-trained LLMs also align well with transparency requirements critical in sensitive financial contexts. However, practical deployment should consider careful calibration to balance false positives and latency. Furthermore, the GSPO algorithm's sequence-level optimization without length normalization may inspire similar approaches for other real-time bot-detection NLP tasks requiring concise outputs. Finally, the demonstrated calibration gap in general-purpose LLMs underscores the importance of tailored RL fine-tuning on domain-specific data for robust bot and fraud defenses.
Cite
@article{arxiv2601_05578,
title={ Reinforcement Learning of Large Language Models for Interpretable Credit Card Fraud Detection },
author={ Cooper Lin and Yanting Zhang and Maohao Ran and Wei Xue and Hongwei Fan and Yibo Xu and Zhenglin Wan and Sirui Han and Yike Guo and Jun Song },
journal={arXiv preprint arXiv:2601.05578},
year={ 2026 },
url={https://arxiv.org/abs/2601.05578}
}