
Beyond BeautifulSoup: Benchmarking LLM-Powered Web Scraping for Everyday Users
Source: arXiv:2601.06301 · Published 2026-01-09 · By Arth Bhardwaj, Nirav Diwan, Gang Wang
TL;DR
This paper investigates how large language models (LLMs) have democratized web scraping, enabling everyday users with limited technical skills to extract data from increasingly complex websites. Traditionally, web scraping required expertise in HTML parsing, session management, and anti-bot circumvention, limiting large-scale operations to skilled developers. The authors benchmark the capabilities of off-the-shelf LLM-powered scraping tools over 35 websites spanning five tiers of difficulty, including sites with authentication, multi-factor auth, and CAPTCHA protections.
Two scraping workflows are evaluated: LLM-assisted scripting (LAS), where users prompt LLMs to generate traditional scraping code executed manually, and end-to-end LLM agents (ELA) that autonomously navigate sites and extract data using integrated tools. The benchmarks reveal that end-to-end agents can successfully scrape complex protected sites with minimal user refinement (often fewer than 5 prompt modifications). Meanwhile, LLM-assisted scripting remains simpler and faster on static, unauthenticated sites. The study provides practical guidance on choosing workflows depending on site complexity and highlights the potential ease with which novice adversaries could abuse these capabilities. The authors open-source their code and evaluation suite, contributing an initial systematic foundation for measuring democratized web scraping powered by LLMs.
Key findings
- Simular.ai agent achieves 100% Extraction Success Rate (ESR) on Simple and Complex HTML sites, 63% on Simple Authentication, 70% on Complex Authentication, and 10% on CAPTCHA sites (Table 2).
- Claude agent achieves 100% ESR on Simple HTML, but lower rates on other categories: 57% on Complex HTML, 20% on Simple Authentication, 12% on Complex Authentication, and 5% on CAPTCHA sites (Table 2).
- Traditional tools (BeautifulSoup and Scrapy) achieve high ESR on Simple HTML (93% and 82%) but fail to support authentication or CAPTCHA tasks out-of-the-box (marked Not Supported).
- LLM-assisted scripting requires medium manual effort (2–4 retries) on static sites, whereas end-to-end agents only require low effort (0–1 retries) on those sites; on authentication and CAPTCHA sites, agents require medium to high effort (2–5+ retries) but still succeed, traditional tools fail completely (Table 3).
- Execution time for successful scrapes is substantially lower (~2s) for traditional LLM-assisted scripting on static sites, versus 10–20s for end-to-end agents due to browser automation overhead (Fig 2).
- For simple static sites, scripting is superior for speed and efficiency, but agents uniquely enable scraping of protected and dynamic websites where scripting breaks down.
- A single user prompt with minimal refinements (<5 prompt changes) was often sufficient for agents to complete complex scraping tasks, demonstrating low-skill accessibility.
- CAPTCHA solving success remains low for all tools; even advanced agents solve <10% of CAPTCHA demo tasks reliably.
Threat model
The adversary is a low-skill user with basic ability to run Python scripts and operate LLM interfaces, possessing user credentials where needed but lacking advanced scraping expertise or prompt engineering skills. The adversary uses off-the-shelf tools without extensive customization or debugging, working under resource constraints such as limited time, budget, and computation. They cannot deploy sophisticated evasion or stealth techniques beyond standard interactions and prompt-driven workflows.
Methodology — deep read
The authors develop a comprehensive benchmarking pipeline to evaluate two classes of LLM-powered web scraping workflows performed by users with limited technical expertise. The threat model assumes adversaries with basic script-running skill and ability to use LLMs, but not advanced scraping expertise or prompt engineering.
They select 35 websites across five incrementally difficult scraping challenges: Simple HTML (static pages), Complex HTML (nested structures, dynamic classes), Simple Authentication (login required), Complex Authentication (MFA, email verification), and CAPTCHA-protected sites (demo CAPTCHA services).
Two workflows are tested: (1) LLM-assisted scripting (LAS), where users prompt LLMs to generate Python scraping code using traditional libraries BeautifulSoup and Scrapy. Users manually execute and refine these scripts, handling HTTP requests and parsing. (2) End-to-end LLM agents (ELA), such as Claude and Simular.ai, which autonomously interact with websites via integrated tools (browsing, clicks, form filling, retries, error checking), given natural language goal prompts.
All tools run in a controlled MacOS environment, with identical network conditions. Each site/task pair is tested three times and metrics recorded: Extraction Success Rate, Execution Time, and Manual Effort Required (measured by retry counts and tuning complexity). Manual session clearing avoids cache bias. Agents receive natural language instructions, while scripting workflows rely on prompt-generated code.
The evaluation compares success rates, runtime, and human effort across tool-site pairs. Concrete tasks include login, content extraction, and data saving to CSV. The study stresses real-world scenarios with low-skill users relying on out-of-the-box tool usage without sophisticated customizations. Results highlight trade-offs between workflows depending on site complexity.
Technical innovations
- Introduction of a novel benchmark measuring LLM-powered web scraping success and usability for low-skill users across five realistic website categories with varying security complexity.
- Formalization of two contrasting LLM workflows: LLM-assisted scripting with manual execution versus end-to-end LLM agents autonomously navigating websites.
- Development of comparable unified metrics capturing success rate, execution time, and manual effort to quantify the accessibility–reliability tradeoff for modern scraping tools.
- Empirical demonstration that production LLM agents can scrape dynamic, authenticated, and protected sites with minimal prompt refinements by novice users.
- Open-sourcing of codebase, prompts, and generated scripts to foster reproducibility and further research in democratized web scraping.
Datasets
- 35 publicly selected websites spanning domains like news, social media, e-commerce, and demo CAPTCHA sites covering five tiers of complexity.
Baselines vs proposed
- BeautifulSoup on Simple HTML: ESR = 0.93 vs Simular.ai: ESR = 1.00
- Scrapy on Simple HTML: ESR = 0.82 vs Claude: ESR = 1.00
- BeautifulSoup on Simple Authentication: Not Supported vs Simular.ai: ESR = 0.63
- Claude on Complex Authentication: ESR = 0.12 vs Simular.ai: ESR = 0.70
- Claude on CAPTCHA: ESR = 0.05 vs Simular.ai: ESR = 0.10
- Manual Effort for Simple HTML - BeautifulSoup: Medium vs Simular.ai: Low
- Manual Effort for Complex Authentication - Claude: High vs Simular.ai: Medium
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.06301.

Fig 1: Benchmark for non-expert web scraping. We introduce a benchmark that evaluates what non-expert users can
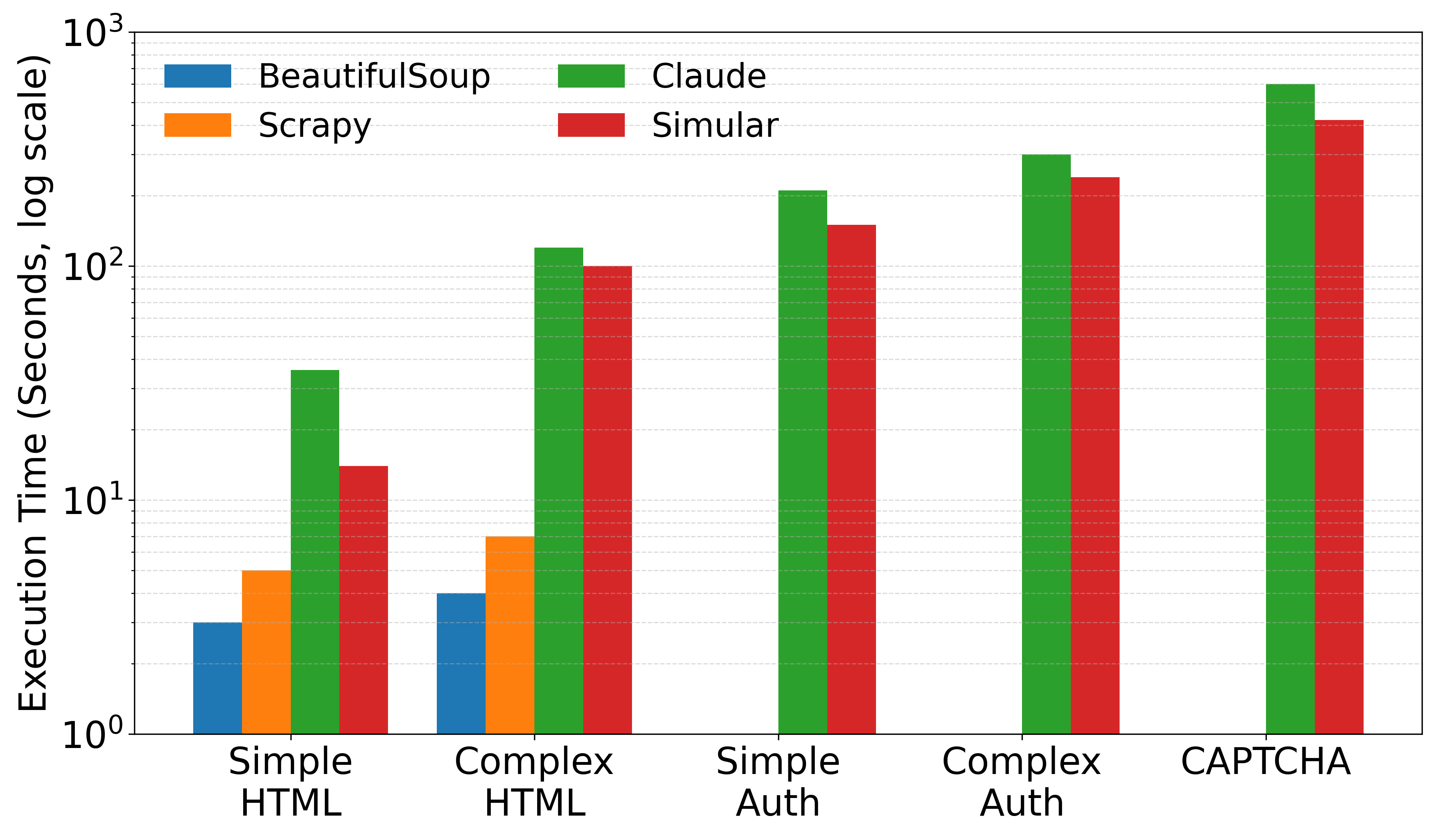
Fig 2: Average execution time per category. Note that the
Limitations
- Benchmark only tests a fixed set of 35 websites, limiting generalizability to wider web ecosystem.
- Evaluation uses a single hardware setup and fixed versions of tools, possibly biasing execution time and success results.
- CAPTCHA tests only performed on demo CAPTCHA sites rather than real-world production CAPTCHAs.
- LLM prompt tuning and advanced user expertise not explored; results reflect novice-level, out-of-the-box usage.
- Traditional browser automation tools like Selenium not included, which might improve scripting success on dynamic sites.
- No explicit adversarial or evasion robustness evaluation of scraping workflows against hardened anti-bot defenses.
Open questions / follow-ons
- How can hybrid approaches combining LLM-assisted scripting for authentication with traditional tools for efficient scraping be designed and benchmarked?
- What methods can improve CAPTCHA-solving success for LLM-powered agents in production environments?
- How do LLM-powered scraping tools perform against adaptive, hardened anti-bot and anomaly detection defenses?
- Can context-aware or site-specific prompting strategies reduce the manual effort required for successful scraping?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper provides empirical evidence that LLM-powered end-to-end agents enable even novice users to bypass many traditional anti-automation barriers like logins and multi-factor authentication with minimal effort. While classical scraping tools remain effective on static content, they fail entirely on protected sites where LLM agents succeed more frequently. This means defensive strategies cannot rely on complexity alone to deter adversaries using such agents. CAPTCHA mechanisms are only partially effective, as agents achieve low but non-negligible success rates on demo challenges. Defenders should therefore anticipate wider abuse potential through democratized LLM-powered scraping and consider designing robust, adaptive protections that account for agentic LLM capabilities, including possible automation of CAPTCHA solving and session handling. This work also highlights sites where scripting defenses are insufficient and agent detection mechanisms might be needed.
Cite
@article{arxiv2601_06301,
title={ Beyond BeautifulSoup: Benchmarking LLM-Powered Web Scraping for Everyday Users },
author={ Arth Bhardwaj and Nirav Diwan and Gang Wang },
journal={arXiv preprint arXiv:2601.06301},
year={ 2026 },
url={https://arxiv.org/abs/2601.06301}
}