
Grain-Aware Data Transformations: Type-Level Formal Verification at Zero Computational Cost
Source: arXiv:2601.00995 · Published 2026-01-02 · By Nikos Karayannidis
TL;DR
This paper tackles a long-standing pain point in data engineering: how to detect grain-related transformation bugs before running a pipeline on real data. The author argues that many silent errors—especially fan traps (double counting) and chasm traps (row loss)—come from losing track of the data’s grain, i.e. the minimum information needed to uniquely identify a row. The proposed solution is to formalize grain as a type-level concept and encode it into schemas so that a compiler or proof assistant can reject incorrect transformations at design time.
The novelty is a formal grain theory with three relations (equality, ordering, incomparability) plus a grain inference theorem for joins and inference rules for the rest of the relational algebra. In the paper’s framing, this makes verification a zero-runtime-cost schema analysis problem, rather than a data-materialization/testing problem. The author claims machine-checked Lean 4 proofs and reports 98–99% cost reduction, with per-pipeline verification costs of $8–$50 versus $415–$2,750 per bug under traditional iterative debugging. The paper also argues that large language models can generate correctness proofs, leaving humans to verify proofs rather than write them.
Key findings
- The paper claims the first formal mathematical definition of grain, generalizing an informal dimensional-modeling concept into a type-theoretic framework applicable to arbitrary data types, not just fact tables.
- A single join example in the introduction shows the failure mode: joining SalesChannel (customer-channel-date) with SalesProduct (customer-product-date) on customer_id and date can yield a result at grain customer×channel×product×date, silently doubling sales totals even though the final grouped output grain is customer×date.
- The paper states a general grain inference theorem for equi-joins that handles both comparable and incomparable join-key portions using type-level operations; the theorem is presented as Theorem 5.6 in the text excerpts.
- The framework defines three grain relations—equality (≡g), ordering (≤g), and incomparability (⟨⟩g)—and presents a bounded lattice for reasoning about grain relationships; the caption mentions “The bounded lattice of the ≤g partial order relation.”
- The author claims the approach can detect fan traps, chasm traps, and aggregation inconsistencies before processing data, using schema analysis alone.
- Reported cost reduction is 98–99%, framed as $8–$50 per pipeline versus $415–$2,750 per bug for traditional debugging/iterative testing.
- Lean 4 machine-checked proofs are said to validate the formal development, and the paper claims LLMs can automatically generate these proofs so that humans only verify them.
- The abstract and introduction claim the approach applies across joins, aggregations, filters, windows, unions, and arbitrary DAG compositions, though the provided excerpt gives the most concrete detail for joins and relational operations.
Threat model
The adversary is not a malicious attacker but the combination of accidental mis-specification, schema complexity, and transformation composition errors in data pipelines. The system assumes the engineer may write a join or aggregation that is syntactically valid yet semantically wrong because it changes grain, duplicating or dropping facts. It does not assume the presence of adversarial data manipulation; instead, it assumes the verifier has access to schemas, type-level grain annotations, and transformation definitions, and that the goal is to prevent incorrect pipelines from being deployed before any data is executed.
Methodology — deep read
The paper’s threat model is a correctness-verification setting rather than an adversarial security setting in the narrow sense. The “adversary” is really the combination of human error and transformation complexity: data engineers composing joins, aggregates, filters, and DAGs can accidentally change grain and thereby duplicate or drop facts. The paper assumes the engineer has access to schema/type information and is willing to annotate or encode grain in the type system, but not necessarily to run expensive test data through the full pipeline. It further assumes that grain can be represented as a type-level property and that the relevant transformations can be modeled compositionally.
On data, the excerpt does not describe a benchmark dataset, public corpus, or large empirical study. Instead, it uses illustrative schemas: a SalesChannel fact table at customer-channel-date grain, a SalesProduct fact table at customer-product-date grain, and simpler examples such as Customer, CustomerProfile, CustomerBasic, Order, and MonthlyAccountBalance. These examples are used to define the formal objects, show type-level subset and isomorphism relations, and motivate grain inference. The paper’s evaluation claims seem to be based on formal proof development and cost accounting rather than a large held-out benchmark. No train/validation/test split is described in the excerpt, and no preprocessing pipeline is mentioned because the core artifact is a formal calculus, not a learned model.
Architecturally, the contribution is a type-theoretic formalization. Grain is defined as a type G[R] that is isomorphic to a data type R and irreducible in the sense that no proper subset can serve as the grain. The paper introduces type-level set operations (union, intersection, difference) and type-level subset/proper-subset relations defined via projection functions. It then defines grain relations: equality, ordering, and incomparability, with ordering tied to the intuition that one grain is finer/coarser than another. The key algorithmic idea is the grain inference theorem for joins: given input grains and join-key relationships, the theorem computes the output grain using only type-level reasoning. The excerpt also says there are inference rules for relational operations including aggregations, filters, projections, theta-joins, semi-joins, anti-joins, and set operations. The novelty is not a new runtime operator; it is the use of grain as a static witness carried by types so that correctness can be checked at compile time.
Training regime is only relevant insofar as the paper claims Lean 4 proofs and LLM-assisted proof generation. The excerpt does not specify epochs, batch sizes, seeds, optimizer settings, or hardware. That absence matters: this is a formal methods paper, not a statistical learning paper. The “training” of the proof assistant artifacts is effectively proof construction and proof checking in Lean 4. The LLM angle is described conceptually: models can generate proofs, and humans can verify them. But the excerpt provides no experimental protocol for LLM proof success rates, no model names, and no ablation of prompt strategies. If there is an experimental section beyond the excerpt, it is not visible here.
The evaluation protocol, as far as the excerpt reveals, is a mix of formal correctness proofs, illustrative pipeline examples, and cost comparison. The strongest concrete example is the sales-report fan trap: the paper shows a join that appears semantically valid at the final grouped grain but is incorrect because the intermediate grain expands to customer×channel×product×date, duplicating metrics. The paper claims that grain theory would flag this through type-level mismatch before execution. The results reported in the abstract and introduction are the cost-reduction numbers: $8–$50 per pipeline for verification versus $415–$2,750 per bug under iterative debugging, yielding 98–99% savings. However, the excerpt does not show the underlying measurement methodology, the number of pipelines evaluated, statistical tests, or a baseline table. Reproducibility is partly strong and partly unclear: the paper says proofs are machine-checked in Lean 4, but the excerpt does not mention whether code, Lean files, or frozen theorem statements are released, nor whether the data examples are synthetic or whether a public artifact exists.
End-to-end, the concrete example works like this: a report needs total sales count and amount per customer and date. A naive implementation joins SalesChannel(customer_id, date, sales_count, ...) with SalesProduct(customer_id, date, sales_count, ...) on customer_id and date, then groups by customer_id and date. The paper argues the join creates a multiplicative intermediate grain over channel and product, so each source row is repeated before aggregation. Grain theory would represent each table’s grain at the type level, infer the join output grain from the input grains and the join-key relationship, and then compare that inferred grain against the intended output grain. If the inferred grain is finer than expected, the system can reject the transformation as a fan trap, before any rows are processed. That is the core operational story the paper is trying to formalize.
Technical innovations
- A formal definition of grain as an isomorphism-based, irreducible type-level representative of a data type’s minimal identifying information.
- A grain inference theorem for equi-joins that handles comparable and incomparable join-key portions via type-level operations.
- A three-way grain relation system—equality, ordering, incomparability—organized into a lattice for static reasoning about transformation correctness.
- A type-level verification strategy for relational pipelines that detects fan traps, chasm traps, and aggregation inconsistencies without executing the dataflow.
- A Lean 4 machine-checked formalization intended to support LLM-generated proofs that humans can verify rather than author from scratch.
Baselines vs proposed
- Traditional iterative testing / debugging: $415–$2,750 per bug vs proposed verification: $8–$50 per pipeline (reported 98–99% cost reduction)
- No formal baseline accuracy/precision/recall table is provided in the excerpt for fan-trap or chasm-trap detection; the paper instead claims compile-time rejection via type analysis
- No dataset-level benchmark comparison is described in the excerpt; the evaluation is presented through formal proofs and illustrative schema examples
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.00995.
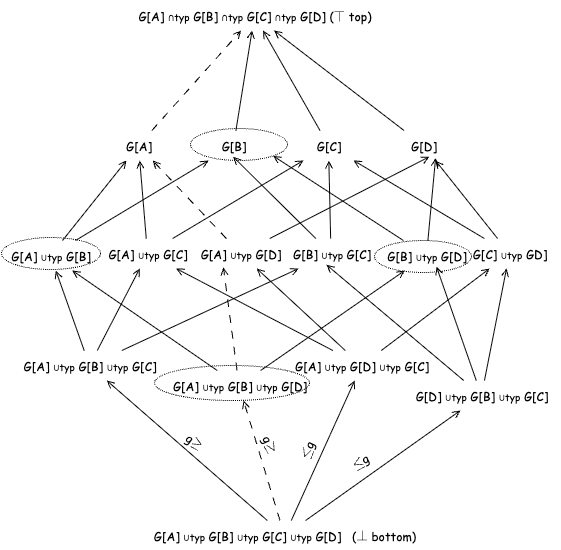
Fig 1: The bounded lattice of the ≤𝑔partial order relation
Limitations
- The excerpt does not provide a benchmark dataset, so the empirical scope appears limited or at least not visible here.
- The reported $415–$2,750 vs $8–$50 figures are not accompanied in the excerpt by a transparent measurement protocol, sample size, or sensitivity analysis.
- The formalism is strong on relational algebra examples, but the excerpt gives less concrete detail for windows, streams, graphs, and arbitrary algebraic types than for joins.
- The paper claims LLM-generated proofs, but the excerpt does not report success rates, failure modes, or a reproducible prompt/evaluation setup.
- The approach depends on accurate grain annotations/types; if the grain model is wrong or incomplete, static verification could give a false sense of safety.
- The framework appears to reason about schema/type structure rather than data-dependent semantics such as approximate uniqueness, late-arriving data, or business-rule exceptions.
Open questions / follow-ons
- How much manual annotation is required to establish grain for real-world schemas, especially when business keys are messy or partially inferred?
- Can the grain inference rules be extended to SQL features beyond the relational core, such as nested arrays, UDFs, approximate queries, and windowed semantics, while remaining decidable and useful?
- What is the empirical failure rate of LLM-generated Lean proofs for grain theorems, and how often do human reviewers need to intervene?
- Can this approach be integrated with existing dbt/warehouse tooling in a way that scales to large DAGs without creating annotation or maintenance overhead?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, the main relevance is methodological rather than domain-specific: it is an example of pushing correctness checks into the type system so bad transformations are rejected before runtime. If you maintain data pipelines for fraud signals, challenge telemetry, or bot-scoring features, the same idea suggests encoding “grain” or other invariants as static metadata so joins and aggregations cannot silently inflate or drop events. That matters when feature leakage, duplicated events, or broken identity joins can destabilize detection models and incident response dashboards.
The likely reaction from a bot-defense engineer is cautious interest. The formalism is attractive because telemetry pipelines often have hidden multiplicities—session-level data joined to user-level or device-level facts can create exactly the kind of duplication the paper targets. But adopting it would require careful definition of the correct grain for events, sessions, accounts, devices, and challenges, plus a way to handle schema evolution and data-quality edge cases. In practice, this paper is a reminder that static invariants can be more valuable than after-the-fact monitoring when the bug class is structural rather than statistical.
Cite
@article{arxiv2601_00995,
title={ Grain-Aware Data Transformations: Type-Level Formal Verification at Zero Computational Cost },
author={ Nikos Karayannidis },
journal={arXiv preprint arXiv:2601.00995},
year={ 2026 },
url={https://arxiv.org/abs/2601.00995}
}