
Adaptive Causal Coordination Detection for Social Media: A Memory-Guided Framework with Semi-Supervised Learning
Source: arXiv:2601.00400 · Published 2026-01-01 · By Weng Ding, Yi Han, Mu-Jiang-Shan Wang
TL;DR
ACCD tackles coordinated inauthentic behavior detection on social platforms, where existing systems often lean on static thresholds, fixed CCM parameters, and heavy manual labeling. The paper’s core idea is to make the detector adaptive across three stages: a memory-guided causal discovery stage, a semi-supervised user classification stage with active learning, and an automated causal validation stage that reuses historical experience to select models and thresholds.
What is new here is less a single novel classifier than a full pipeline that tries to reduce three common bottlenecks at once: spurious correlation, parameter brittleness, and annotation cost. The authors claim the adaptive design improves both accuracy and operational efficiency. On the Twitter IRA benchmark, ACCD reaches F1 = 87.3%, compared with 75.8% for their strongest baseline (CCM), while also reducing manual annotation needs by about 68% and cutting processing time to 72 minutes. They also report similar gains on Reddit coordination traces and improved scalability via hierarchical clustering.
Key findings
- On Twitter IRA, ACCD reports precision = 85.6%, recall = 89.2%, and F1 = 87.3%, versus CCM at 72.1% precision, 79.8% recall, and 75.8% F1.
- The paper claims a +15.2 percentage-point F1 gain over the strongest baseline on coordination detection (75.8% → 87.3%).
- Manual labeling is reduced by 68.3% in the semi-supervised stage, with classification accuracy reported at 88.9%.
- Processing time drops from 181.3 minutes for CCM to 72 minutes for ACCD in Table 1.
- Table 2 reports memory use of 4.5 GB for ACCD versus 8.2 GB for CCM, and speed improves from 1.0× to 2.8×.
- The ablation study reports the full model at F1 = 91.2%, and removing the adaptive parameter mechanism causes the largest F1 drop (exact delta not provided in the text excerpt).
- On Reddit coordination data, ACCD reports F1 = 84.7% versus 71.2% for traditional approaches.
- The authors state the effective complexity is reduced from O(N^2) to approximately O(N^1.4) via clustering, but the derivation in the text is heuristic rather than a formal proof.
Threat model
The adversary is a coordinated group of social media accounts that tries to evade detection by producing temporally aligned but not obviously identical behavior, blending in with organic traffic, and varying coordination patterns across campaigns and platforms. The detector is assumed to have access to public or platform-internal account activity traces, timestamps, and behavioral features, but not to privileged ground truth about intent or hidden coordination structure. The framework assumes historical detections from similar contexts are available to guide parameter selection and validation, and it does not claim resistance to an adaptive adversary who actively learns the detector’s exact memory and thresholding logic.
Methodology — deep read
The threat model is a coordination-detection setting rather than an evasion-proof adversarial ML setup. The adversary is a coordinated group of accounts generating behavior that may look superficially organic: synchronized posting, retweeting, hashtag reuse, or mixed organic/coordinated patterns. The detector is assumed to observe account activity timestamps and behavioral features, but not private platform signals or ground-truth intent. The paper’s main assumption is that coordinated actors leave detectable causal and behavioral structure in temporal traces, and that historical performance on similar datasets can guide parameter choice and validation thresholds.
Data provenance is mixed. The main benchmark is the Twitter IRA dataset, described as containing 2.9 million tweets from 2,832 users involved in confirmed influence operations. They also evaluate on Reddit coordination data derived from Pushshift and on the TwiBot-20 benchmark. The paper additionally mentions “several widely adopted bot detection benchmarks,” but the excerpt only explicitly names TwiBot-20. Labels are used at multiple levels: coordination detection labels for the IRA and Reddit tasks, and behavioral category labels for the semi-supervised classifier with four classes: Fake, Org, Political, and Individual. The evaluation uses stratified five-fold cross-validation with temporal splitting to avoid leakage across time. Preprocessing details are sparse; the text says user activity is transformed into fixed or rolling time series for CCM, and behavioral feature vectors include posting frequency, retweet behavior, hashtag usage, sentiment distribution, and temporal engagement statistics.
Stage 1 is the adaptive causal coordination detector. The novel element is a long-term parameter memory H, implemented as a lightweight key-value store such as LMDB, where each context bucket stores historical precision and usage counts for candidate (E, τ) embedding parameters. For each time window, ACCD selects the pair maximizing a weighted score of historical precision and an exploration bonus: α = 0.8 and β = 0.1 are given in Eq. (2). After selection, each user is embedded incrementally using a rolling activity buffer, which avoids reconstructing the full delay embedding every time. Causal influence is then estimated with Convergent Cross Mapping: the user manifold is indexed with a ball-tree or HNSW graph, k-nearest neighbors are used to predict one user’s trajectory conditioned on another’s manifold, and the final influence score is the max Pearson correlation over library lengths L ∈ [10, 50]. To cut the O(U^2) pairwise cost, users are clustered hierarchically by temporal statistics (mean, variance, burstiness, entropy), CCM is run only within clusters, and a small number of cross-cluster pairs are sampled. The paper states this yields roughly a 5× speedup at U = 1000 in the method section, while the results table reports an overall 2.8× speedup relative to CCM.
Stage 2 is a semi-supervised user classifier designed to reduce label cost. Each user is encoded as a feature vector x over behavioral attributes and classified into the four taxonomy labels. Uncertainty sampling is computed from a Random Forest with T = 100 trees, using uncertainty(x) = 1 - max_c P(c|x), where P(c|x) is estimated by tree voting. The most uncertain users are sent to human annotators first. The paper also adds curriculum learning: training starts on easy examples (uncertainty below lower thresholds) and progressively includes harder ones once validation accuracy exceeds 0.85, with thresholds progressing through {0.3, 0.5, 0.7, 1.0}. High-confidence predictions above 0.9 are stored as pseudo-labels in long-term memory and reused later. One concrete example given: a borderline account mixing political messaging with ordinary engagement would likely be surfaced early for manual review because the classifier’s uncertainty is high, whereas a clearly spam-like account would be pseudo-labeled and recycled into training.
Stage 3 is the adaptive causal validator. Here ACCD tries to automate the choice among causal estimators and significance thresholds using historical experience. The adaptive threshold for a dataset d is θ_adapt(d) = θ_base · exp(γ · success_rate(d)) with γ = 0.2, where success_rate is computed from a history H(d) of similar datasets using coarse descriptors such as sample size, treatment ratio, and temporal coverage. Candidate estimators include Generalized Synthetic Control, CausalForestDML, and GANITE. They are scored via a multi-objective function combining stderr, precision, and recall, with weights (0.4, 0.3, 0.3). The top models are used to estimate treatment effects τ(x) = E[Y(1)-Y(0)|X=x], retain only effects with p < 0.05 and overlapping confidence intervals, then aggregate into an ensemble estimate. The pipeline includes refutation tests such as placebo treatment assignment, random subsetting, and temporal holdout validation. A concrete end-to-end example is implicit rather than fully worked numerically: a dataset is summarized by size and temporal span, similar historical cases are retrieved, thresholds are adjusted upward or downward, multiple estimators are run, and only effects that survive both significance filtering and refutation tests are returned as validated coordination pairs.
Training and implementation details are fairly standard but somewhat high-level. The implementation uses PyTorch 2.0.0 and scikit-learn 1.3.0 on NVIDIA A100 GPUs. Models are trained for 100 epochs with batch size 64, learning rate 0.001, and a CosineAnnealingWarmRestarts scheduler. The text does not report random seed strategy, early stopping, weight decay, or whether hyperparameters were tuned on validation folds versus fixed a priori. The evaluation protocol relies on stratified five-fold cross-validation with temporal splitting. Metrics include precision, recall, F1, training time, memory usage, convergence epochs, classification accuracy, and validation accuracy. The paper reports comparison against CCM, Correlation, LCN+HCC, and AMDN-HAGE on the main coordination benchmark, plus a separate efficiency table comparing CCM, a fixed-parameter variant, and ACCD. Reproducibility is only partially supported: the method is described in enough detail to reimplement, but the excerpt does not mention code release, frozen weights, or a public release of the memory tables and historical validation data.
Technical innovations
- Memory-guided adaptive selection of CCM embedding parameters (E, τ) using historical precision and usage statistics per context bucket.
- A three-stage pipeline that combines causal discovery, active-learning-based semi-supervised classification, and automated validation into one coordination-detection system.
- Hierarchical clustering plus sampled cross-cluster CCM to reduce the pairwise O(U^2) bottleneck of causal influence estimation.
- Adaptive thresholding for causal validation that tunes significance cutoffs using success rates from similar historical datasets.
Datasets
- Twitter IRA dataset — 2.9 million tweets from 2,832 users — public benchmark / confirmed influence operations
- Reddit coordination data — size not specified in excerpt — derived from Pushshift dataset
- TwiBot-20 — size not specified in excerpt — public benchmark
Baselines vs proposed
- CCM [7]: F1 = 75.8% vs proposed: 87.3%
- CCM [7]: precision = 72.1% vs proposed: 85.6%
- CCM [7]: recall = 79.8% vs proposed: 89.2%
- Correlation: F1 = 73.5% vs proposed: 87.3%
- LCN+HCC [11]: F1 = 75.3% vs proposed: 87.3%
- AMDN-HAGE [16]: F1 = 75.1% vs proposed: 87.3%
- CCM [7]: time = 181.3 min vs proposed: 72 min
- LCN+HCC [11]: time = 96.7 min vs proposed: 72 min
- AMDN-HAGE [16]: time = 211.4 min vs proposed: 72 min
- CCM [7]: memory = 8.2 GB vs proposed: 4.5 GB
- Fixed Param.: epochs to convergence = 58 vs proposed: 40
- Fixed Param.: speed = 1.1× vs proposed: 2.8×
- Reddit traditional approaches: F1 = 71.2% vs proposed: 84.7%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.00400.
Fig 1: Motivation of ACCD. From static, correlation-based detection to an adaptive,
Fig 2: Architecture of the proposed ACCD framework with adaptive causal detection, semi-
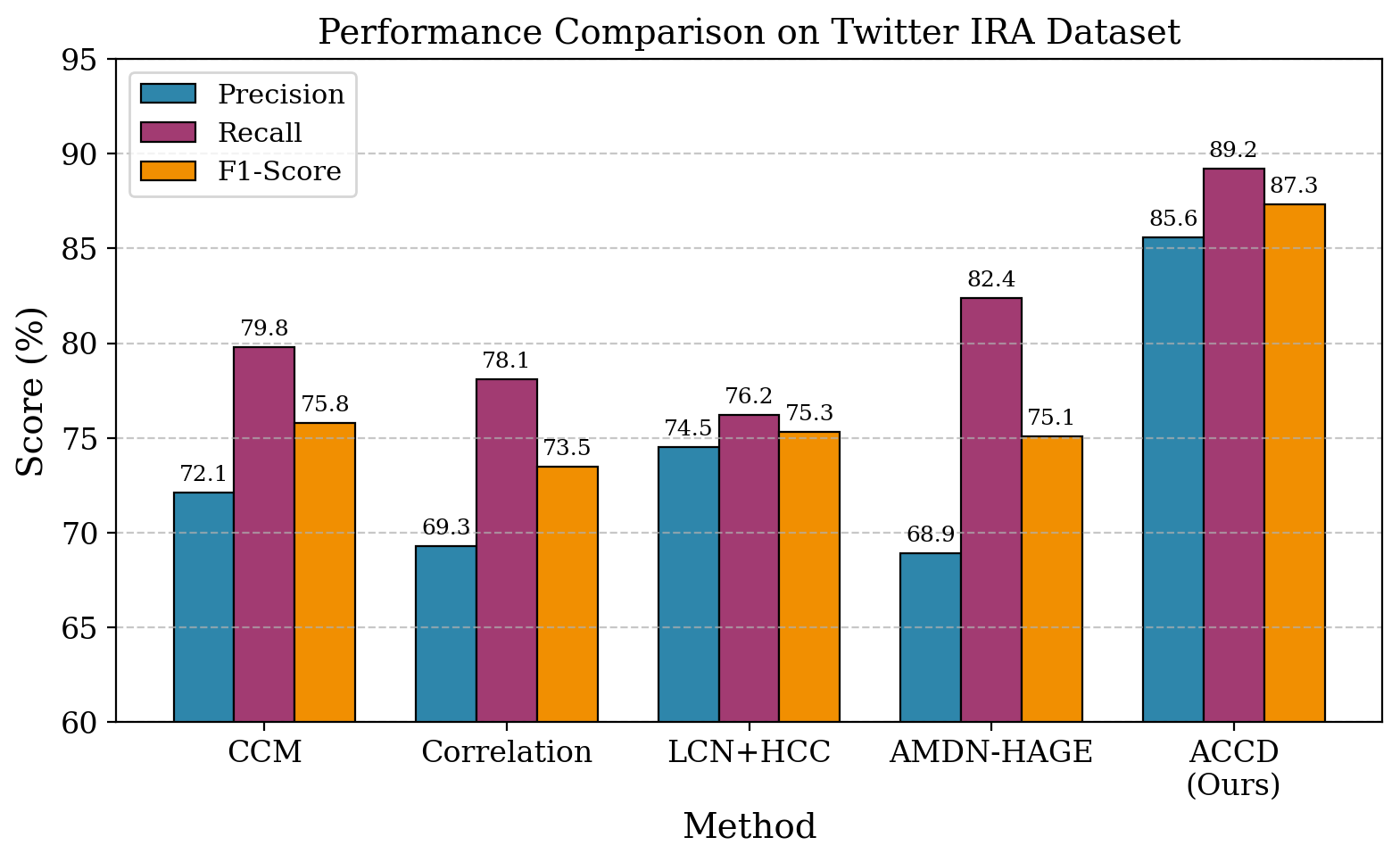
Fig 3: Comparison between ACCD and baseline models in terms of detection accuracy and
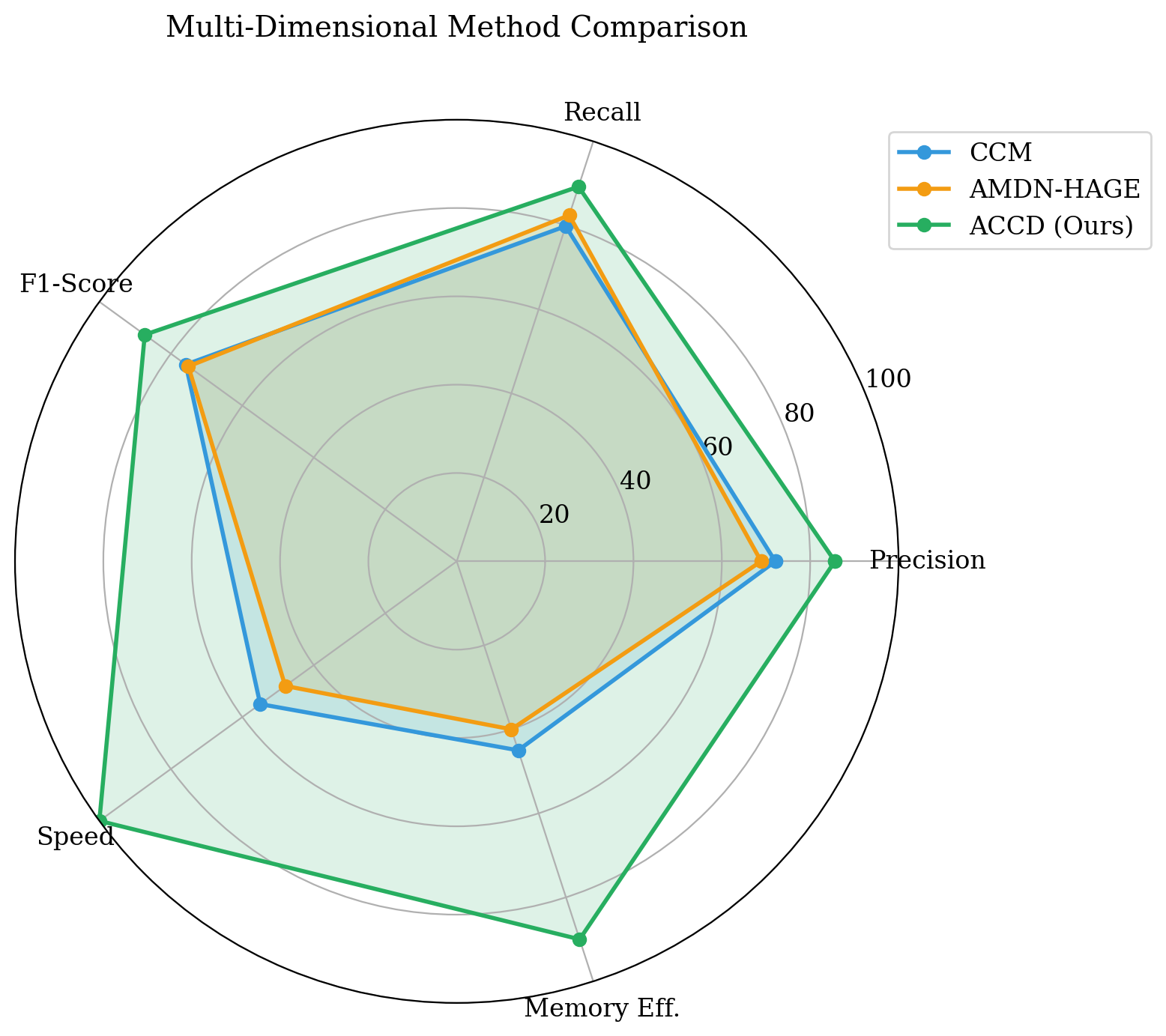
Fig 4: Computational efficiency analysis showing memory usage and speed improvements
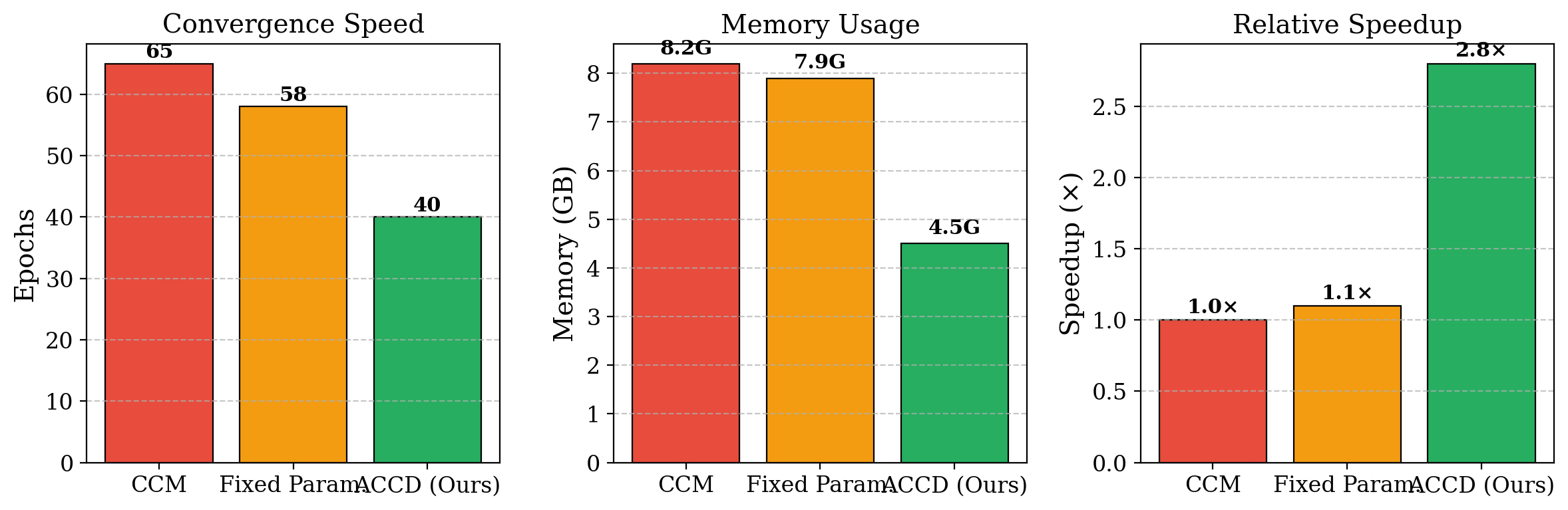
Fig 5: Analysis of network structure and metric correlations in coordinated campaigns.
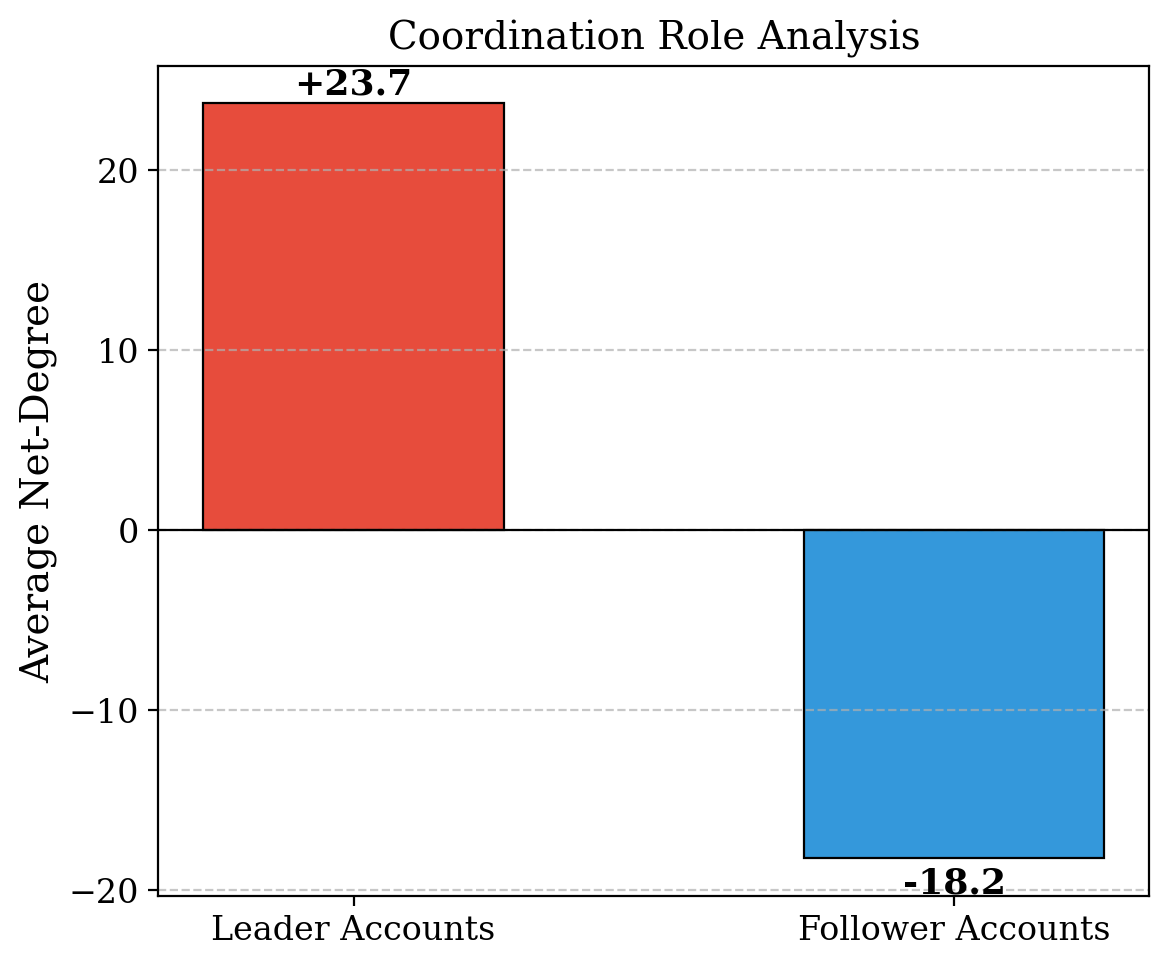
Fig 6: Ablation study showing the contribution of each ACCD component.
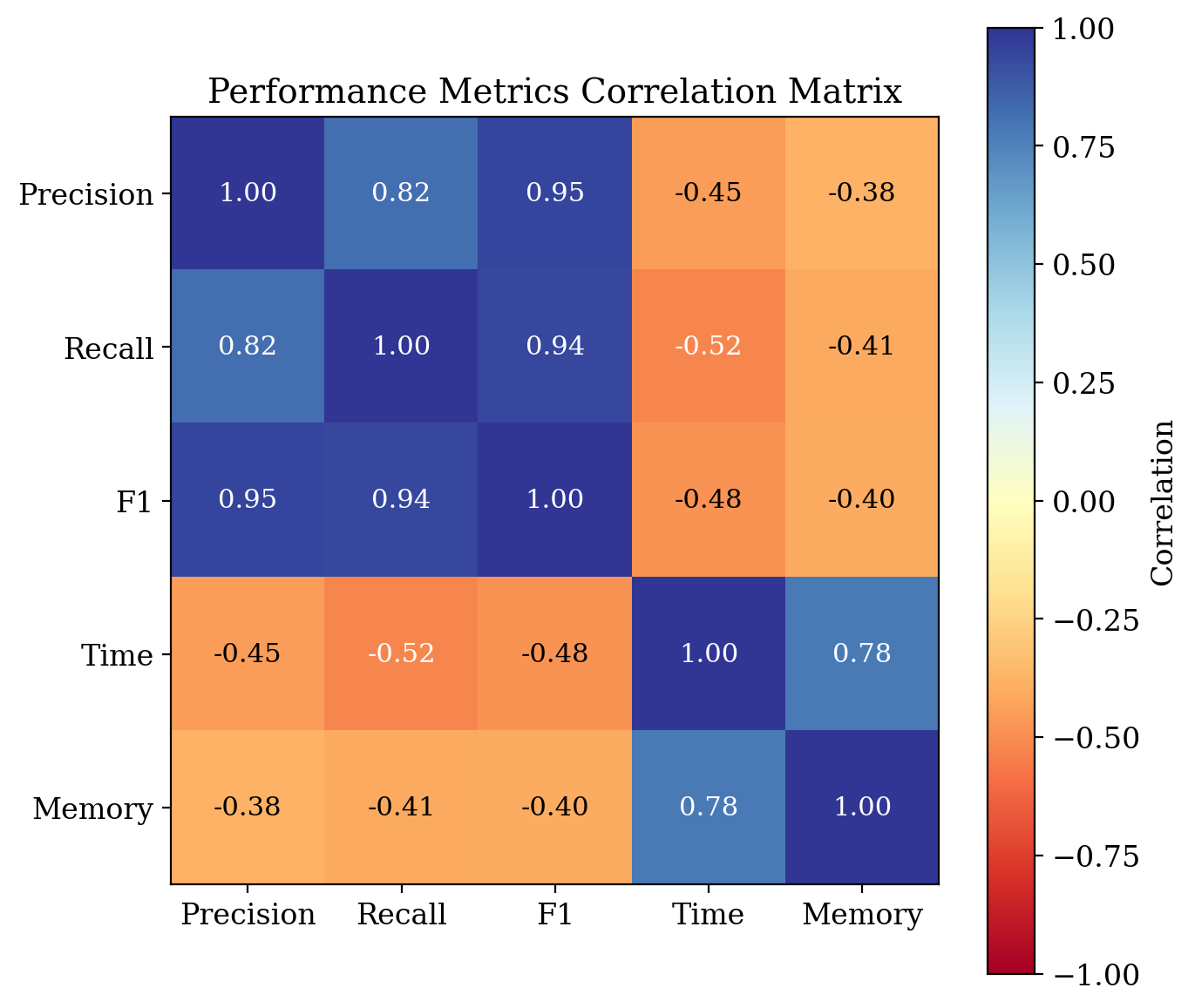
Fig 7: Efficiency and convergence behavior of ACCD compared with baselines.
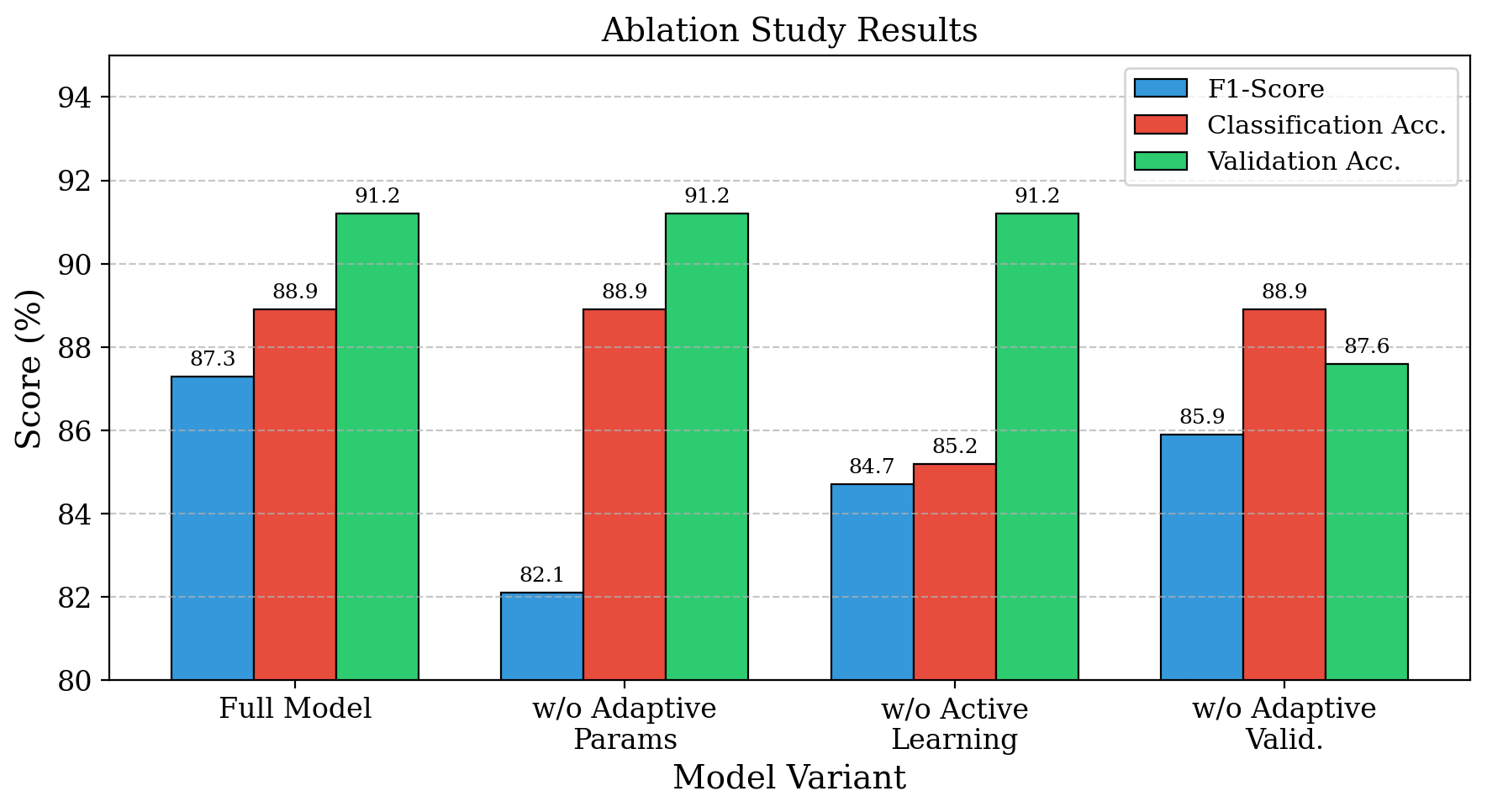
Fig 8: Scenario-aware coordination detection performance analysis.
Limitations
- The excerpt does not provide full dataset sizes for the Reddit coordination traces or the split details for TwiBot-20, so reproducibility is incomplete.
- The reported O(N^1.4) scaling is stated in the conclusion, but the method section’s derivation is heuristic and still depends on clustering assumptions and sampled cross-cluster pairs.
- The validation stage uses historical similar datasets and pseudo-ground-truth effects, but the excerpt does not specify how those historical histories are constructed or whether they leak test information.
- The largest reported gains come from a comparison set that includes fixed-parameter and correlation baselines; it is unclear whether hyperparameters were equally tuned across all baselines.
- Ablation results are described qualitatively in the excerpt, but the exact F1 drops for removing each module are not fully enumerated.
- The paper emphasizes causal inference and adaptive thresholds, but does not report robustness under adversarial adaptation or concept drift beyond temporal cross-validation.
Open questions / follow-ons
- How stable are the memory-guided parameter choices when the platform experiences abrupt distribution shift, such as a new coordinated campaign style or a major news event?
- How much of the gain comes from adaptive CCM versus the clustering approximation and the semi-supervised classifier, and does the pipeline still help if one stage is removed?
- Can the historical-validation memory be made safe against contamination from mislabeled or adversarially poisoned past cases?
- Would the adaptive causal validator generalize to platforms whose interaction graph is not well captured by temporal activity features alone?
Why it matters for bot defense
For bot-defense work, the paper is most relevant as a design pattern rather than a drop-in detector: it combines causal signals, label-efficient learning, and memory of past cases to adapt to changing attacker behavior. That is directly applicable to coordinated abuse problems such as brigading, fake engagement rings, and multi-account spam, where static thresholds and one-shot classifiers tend to decay quickly.
A CAPTCHA or bot-defense engineer would likely focus on the stage-2 uncertainty sampling and the stage-3 historical validation logic. The first can reduce annotation cost when building training sets for new abuse patterns; the second suggests a way to choose thresholds and models per campaign or platform slice instead of relying on a single global cutoff. The main caution is that the paper’s gains depend on temporal behavioral traces and historical similarity assumptions, so it is more useful for post hoc coordination detection and account-risk scoring than for real-time interaction gating by itself.
Cite
@article{arxiv2601_00400,
title={ Adaptive Causal Coordination Detection for Social Media: A Memory-Guided Framework with Semi-Supervised Learning },
author={ Weng Ding and Yi Han and Mu-Jiang-Shan Wang },
journal={arXiv preprint arXiv:2601.00400},
year={ 2026 },
url={https://arxiv.org/abs/2601.00400}
}