
EdgeJury: Cross-Reviewed Small-Model Ensembles for Truthful Question Answering on Serverless Edge Inference
Source: arXiv:2601.00850 · Published 2025-12-29 · By Aayush Kumar
TL;DR
EdgeJury addresses the challenge of hallucinations and untruthful answers in question answering under resource-constrained, serverless edge inference settings, where using very large models or retrieval-augmented pipelines is impractical. The framework orchestrates a four-stage ensemble of small instruction-tuned language models (3B–8B parameters) to improve truthfulness and robustness without external retrieval. These stages include role-specialized answer generation by diverse models, anonymized cross-review with structured critiques and rankings, a chairman synthesis model that produces a consolidated final answer integrating peer feedback, and claim-level consistency labeling based on inter-model agreement.
The authors demonstrate substantial accuracy gains on multiple benchmarks, notably achieving 76.2% accuracy on the TruthfulQA MC1 dataset, a relative improvement of +21.4% over a single 8B baseline. On a challenging adversarial EdgeCases dataset emphasizing misconception traps and ambiguity, EdgeJury improves accuracy by +48.2% relative. Manual error analysis of incorrect answers reveals a ~55% reduction in factual hallucinations compared to the single-model baseline. Deployed on Cloudflare Workers AI, the system attains median 8.4 second end-to-end latency, validating feasibility in a serverless edge environment. Overall, the paper illustrates that coordinated cross-reviewed small-model ensembles coupled with structured synthesis offer a practical and effective approach to truthful question answering without reliance on proprietary large models or retrieval pipelines.
Key findings
- EdgeJury achieves 76.2% accuracy on TruthfulQA MC1 (95% CI: 72.8–79.6%), a +21.4% relative gain over single LLaMA-3.1-8B model baseline at 62.8%.
- On a 200-question adversarial EdgeCases set, EdgeJury yields +48.2% relative accuracy improvement (95% CI: 44.0–52.4%) compared to single-model baseline.
- Manual error analysis on 100 incorrect answers shows approximately 55% reduction in factual hallucinations versus single-model baseline (9/50 vs 4/50 errors).
- Component ablation on TruthfulQA MC1 quantifies Stage 3 synthesis contributes −8.8% and Stage 2 cross-review −7.6% absolute accuracy drops when removed (Table 4).
- Stage 4 claim-level consistency verifier attains 94.2% precision and 87.3% recall for identifying supported factual claims on human-labeled dataset.
- EdgeJury's compute cost on TruthfulQA MC1 is 10 model calls totaling ~3,900 tokens, roughly 1.6× more tokens than single-model (500 tokens) or 5-sample self-consistency (2,400 tokens), but yields +8–13% absolute accuracy improvements versus these baselines.
- Latency measured on Cloudflare Workers AI: median end-to-end query completion 8.4 seconds, with Stage 1 (generation), Stage 2 (cross-review), and Stage 3 (synthesis) each contributing roughly one-third of total latency.
- Cross-review yields largest gains for misconception and trick question categories within TruthfulQA (e.g., +12.4% and +18.7% respectively).
Threat model
The adversary is conceptualized as any prompt or question that induces hallucinations or untruthful responses from language models; the system assumes no external knowledge manipulation or direct attacks on the deployment infrastructure. Models cannot collude or maliciously manipulate critiques. The adversary cannot access or modify internal model inputs beyond posed questions nor tamper with orchestration or synthesis steps.
Methodology — deep read
The threat model assumes an adversary that attempts to induce hallucinations or untruthful answers in LLM-based question answering. The system focuses on improving internal model disagreement detection and synthesis, not defending against direct adversarial attacks or model extraction.
Data provenance includes four benchmarks: TruthfulQA MC1 (817 questions, multiple choice), an adversarial EdgeCases set (200 questions authored to stress misconception traps and ambiguity), MMLU (500 questions, 5-shot), and BIG-Bench Hard and Natural Questions subsets. The adversarial EdgeCases dataset and rubrics are released with code. Scoring applies exact-match or rubric-based evaluation depending on task.
EdgeJury uses four small instruction-tuned LLM instances (two LLaMA-3.1-8B with different role prompts, one LLaMA-3.2-3B, and one Mistral-7B) in Stage 1. Role prompts induce specialized behavior: Direct Answerer, Edge Case Finder, Step-by-Step Explainer, and Pragmatic Implementer, to maximize output diversity and reduce correlated errors.
Stage 2 has each model anonymously cross-review the other candidates, generating structured JSON critiques including numeric ratings on accuracy, insight, clarity; discrete issue flags (factual risk, missing edge cases, unclear phrasing, incomplete answers); and extracts of ‘best bits’. Rankings aggregate via Borda count.
Stage 3 uses a chairman model (LLaMA-3.1-8B) that ingests question, candidate answers with role info, and aggregated peer critiques to synthesize a consolidated final JSON answer. The synthesis aims to select best content, resolve flagged issues, rewrite for clarity, and enforce output constraints (e.g., single MC choice).
Stage 4 uses a claim-level verifier model to decompose the final answer into atomic factual claims and label each as consistent, uncertain, or contradicted based on agreement patterns across Stage 1 candidates. This is a post-hoc verification generating interpretable reliability tags.
Across all stages, EdgeJury performs a fixed 10 model calls per query (4 gen + 4 cross-review + 1 synthesis + 1 verification). The parallelizable Stage 1 and Stage 2 enable latency efficiency.
The system is deployed on Cloudflare Workers AI, orchestrating model calls over serverless edge infrastructure. Latency and cost metrics are collected over 500 queries from a balanced subset.
Baselines include the single strongest LLaMA-3.1-8B model, self-consistency sampling (3 and 5 samples), majority vote ensemble across three models, and a simulated retrieval-augmented generation (RAG) pipeline with local index. An oracle best-of-3 ceiling baseline estimates maximum gains from answer selection.
Statistical significance is assessed with paired McNemar's test and Holm–Bonferroni correction. Confidence intervals use stratified bootstrap over question categories.
Reproducibility is ensured with full code, exact model hashes, prompt templates, and benchmark splits released on GitHub, alongside raw per-call execution traces.
A concrete example: For a given question, each Stage 1 model with a distinct role prompt produces a candidate answer in parallel. Then each model (as reviewer) rates anonymized candidates and flags issues. Reviews are aggregated via Borda count. The chairman model synthesizes a final answer incorporating critiques. Finally, the verifier extracts atomic claims from the synthesized answer and labels their agreement status.
The final output is a single answer (e.g., an MC choice letter) plus claim-level confidence tags. This pipeline contrasts with standard self-consistency or majority vote ensembles by enabling explicit peer critique and synthesis under fixed call and latency budgets suitable for serverless edge deployment.
Technical innovations
- EdgeJury's four-stage pipeline combining role-specialized parallel generation, anonymized cross-review with structured critiques, chairman synthesis integrating critiques, and claim-level consistency verification is novel for small-model ensembles.
- Anonymized, structured peer review with fixed-issue taxonomy and numeric ratings enables explicit detection and correction of factual risks and missing nuances during synthesis.
- Use of role prompt specialization across heterogeneous small models to maximize complementary failure modes and coverage, reducing correlated hallucinations versus repeated sampling of one model.
- Single-round cross-review and synthesis design balances truthful answer gains with interactive latency constraints of serverless edge inference.
- Post-hoc claim extraction and inter-model agreement labeling provide interpretable reliability tags for downstream selective answering.
Datasets
- TruthfulQA MC1 — 817 questions — public benchmark for truthful question answering
- EdgeCases adversarial set — 200 questions — authored by paper for testing misconception traps and ambiguity
- MMLU (5-shot subset) — 500 questions — public benchmark
- BIG-Bench Hard (BBH) subset — 300 questions — public benchmark
- Natural Questions (NQ) subset — 200 questions — public benchmark
Baselines vs proposed
- Single Model (LLaMA-3.1-8B): TruthfulQA MC1 accuracy = 62.8% vs EdgeJury = 76.2%
- Self-Consistency (k=5 samples): TruthfulQA MC1 accuracy = 68.1% vs EdgeJury = 76.2%
- Majority Vote (3 models): TruthfulQA MC1 accuracy = 67.8% vs EdgeJury = 76.2%
- RAG-S1 (retrieval-augmented single model): TruthfulQA MC1 accuracy = 72.1% vs EdgeJury = 76.2%
- Single Model (S1): EdgeCases accuracy = 41.5% vs EdgeJury = 61.5%
- Self-Consistency (k=5): EdgeCases accuracy = 49.3% vs EdgeJury = 61.5%
- Majority Vote: EdgeCases accuracy = 48.0% vs EdgeJury = 61.5%
- RAG-S1: EdgeCases accuracy = 55.0% vs EdgeJury = 61.5%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2601.00850.
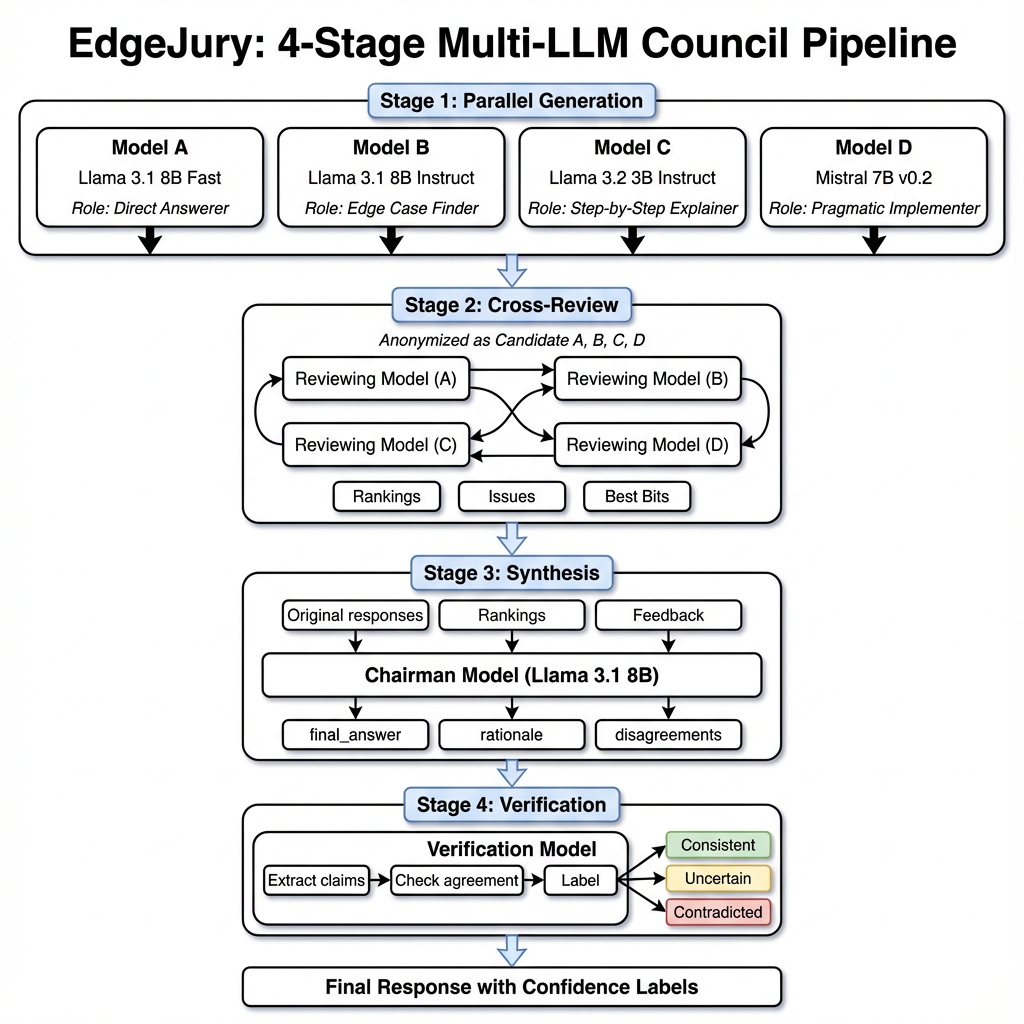
Fig 1: EdgeJury four-stage ensemble pipeline. (a) Stage 1: Multiple small LLMs (3B–8B)
Limitations
- Stage 4 consistency verifier depends on intra-ensemble agreement; it cannot detect shared hallucinations if all candidates share the same falsehood.
- EdgeJury does not incorporate external retrieval or grounding; accuracy may remain limited by knowledge cutoff and hallucination of all models.
- Latency (~8.4s median) remains higher than single model inference, which may limit real-time use cases despite serverless edge deployment.
- Evaluation focuses on instruction-tuned models under zero-shot/few-shot settings; no adversarial adversary model or strong attack scenarios explored.
- The system requires orchestration overhead and multiple model calls (10 per query), possibly increasing cost compared to single large models in different deployment contexts.
- Role prompt design and model selection may require tuning per domain and task; generalization to other question answering domains beyond tested benchmarks is unclear.
Open questions / follow-ons
- Can the cross-review and synthesis approach scale effectively with more diverse model families or larger ensembles without excessive latency?
- How robust is EdgeJury under adaptive adversarial attacks targeting cross-review mechanisms or exploiting model ensemble blind spots?
- Can integrating lightweight retrieval or external knowledge references further enhance claims verification without violating edge constraints?
- How transferable is EdgeJury to other modalities (e.g., multimodal QA) or to domains requiring real-time interaction at lower latency?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, EdgeJury offers an intriguing approach to improving truthfulness and reliability of question-answering systems in latency- and cost-sensitive environments typical of edge deployments. The explicit cross-review and synthesis mechanism could inspire multi-agent verification or adjudication designs to better handle adversarial queries or misinformation from automated bots. The claim-level reliability labeling can provide interpretable confidence signals valuable for selective challenge generation or dynamic verification policies.
However, the multi-call orchestration and ~8-second latency may be too high for many CAPTCHA contexts requiring near-instantaneous proving. Also, reliance on ensemble agreement rather than external grounding limits defense efficacy against coordinated misinformation attacks or highly sophisticated adversaries. Nevertheless, the design trade-offs and structured multi-model critique could inform lightweight ensemble architectures where external retrieval is impractical and trustworthiness remains paramount.
Cite
@article{arxiv2601_00850,
title={ EdgeJury: Cross-Reviewed Small-Model Ensembles for Truthful Question Answering on Serverless Edge Inference },
author={ Aayush Kumar },
journal={arXiv preprint arXiv:2601.00850},
year={ 2025 },
url={https://arxiv.org/abs/2601.00850}
}