
Fraud Detection Through Large-Scale Graph Clustering with Heterogeneous Link Transformation
Source: arXiv:2512.19061 · Published 2025-12-22 · By Chi Liu
TL;DR
This paper addresses the challenge of detecting collaborative fraud within massive heterogeneous account graphs representing online payment platforms. Such graphs contain millions of accounts linked by two fundamentally different types of edges: hard links, which are high-confidence identity connections (e.g., shared phone numbers or credit cards), and soft links, which reflect behavioral associations (e.g., shared device fingerprints or IP addresses). Prior approaches that rely solely on hard links have high precision but limited coverage, while using all linkages leads to fragmented or noisy graphs that impede clustering. To overcome these limitations, the author proposes a principled graph transformation technique that first merges connected components formed by hard links into super-nodes, then rebuilds a reduced weighted graph where edges aggregate soft-link associations between these super-nodes. This transformed graph is substantially smaller and cleaner, allowing effective embedding with the LINE method and unsupervised fraud cluster discovery via HDBSCAN. Experiments on a real-world industrial-scale payment dataset (originally 25 million nodes reduced to 7.7 million super-nodes) show that the method doubles fraud detection coverage over hard-link-only baselines while maintaining high precision. The framework offers a scalable, practical solution for large heterogeneous fraud graphs and is deployed in production.
Key findings
- Graph transformation reduces node count from 25 million to 7.7 million, a 69.2% reduction, enabling efficient downstream processing.
- Detection coverage—fraction of fraudulent accounts identified—is roughly doubled compared to methods using only hard links, with similar precision maintained.
- Summation aggregation of soft link weights between super-nodes improves precision by 3-5% versus mean or max aggregation.
- LINE embedding with concatenated first- and second-order proximities (128 dimensions total) preserves useful network structure for clustering.
- HDBSCAN clustering with min_cluster_size=2 detects fraud rings of varying sizes without needing a priori cluster count.
- Union-find algorithm with path compression for hard-link component detection operates in near-linear time ~O(|V| + |EH| α(|V|)).
- Edge sampling proportional to aggregated soft-link weights stabilizes training and emphasizes strong fraud associations.
- The combined graph transformation and embedding pipeline achieves approximately 10x speedup in clustering step compared to directly embedding the original graph.
Threat model
The adversary is a fraud ring operator who controls multiple accounts and aims to avoid detection by not sharing high-confidence identity credentials (hard links) across all accounts, but may unwittingly or necessarily share behavioral resources (soft links) such as devices or IPs. The adversary cannot easily forge or manipulate hard links without leaving strong evidence but can disguise soft links to evade detection. The defender has access to all account identifiers, hard and soft linkages, and raw behavioral data aggregated in the heterogeneous account graph. The threat model assumes the adversary does not control the entire platform or have root access to the system.
Methodology — deep read
Threat Model & Assumptions: The adversary controls multiple fraudulent accounts coordinated to exploit payment systems. They deliberately avoid sharing high-confidence identity attributes (hard links), but may share behavioral signals (soft links) such as devices or IP addresses. The defender constructs a heterogeneous graph with two edge types: hard links (verified, high precision identity connections) and soft links (noisier behavioral associations). Fraud clusters correspond to connected fraudulent entities exhibiting suspicious patterns. The goal is to detect such clusters unsupervised at large scale, without requiring ground truth labels.
Data Provenance and Preprocessing: Experiments use a real-world dataset from a major payment platform with approximately 25 million account nodes and hundreds of millions of edges combining hard links (phone, email, credit cards, national IDs) and soft links (device fingerprint, IP address, cookie). Soft link weights are binary per link type per 90-day window (multiple sessions counted once). The original heterogeneous graph is processed into super-nodes and weighted soft-link edges.
Architecture and Algorithm:
- Step 1: Graph Transformation. Using a union-find data structure with path compression and union-by-rank, maximal connected components are found in the hard-link subgraph to construct super-nodes (accounts definitely owned by the same entity). This reduces node count and captures high-confidence identity clusters.
- Step 2: Soft-link Aggregation. Soft links between accounts in different super-nodes are aggregated by summation of weights to produce weighted edges between super-nodes. Links within the same super-node are discarded.
- Step 3: Network Embedding. The transformed weighted graph is embedded with LINE, which separately models first-order proximity (direct edges) and second-order proximity (shared neighborhood similarity) using negative sampling and edge sampling proportional to edge weights. Final embeddings concatenate first- and second-order 64-d embeddings for a 128-d vector.
- Step 4: Clustering. HDBSCAN density-based clustering with cosine distance identifies fraud clusters of varying size and density, automatically estimating cluster number and handling noise. The minimum cluster size is set to 2 to detect small fraud rings.
- Step 5: Risk Scoring and Ranking. Detected clusters are scored using size, internal density, and aggregated fraud indicators from constituent accounts to prioritize analyst review.
Training Regime and Hyperparameters: LINE is trained over the transformed graph with negative samples K and epochs T (exact values not explicitly stated). Edge sampling uses alias tables for O(1) sampling. Embedding dimension d=128 (64 for 1st-order, 64 for 2nd-order), embeddings normalized to unit length. HDBSCAN min_cluster_size=2.
Evaluation Protocol: Experiments evaluate graph size reduction, detection coverage (fraudulent account recall), precision of detected clusters, and computational efficiency. Coverage is compared against a baseline using only hard-link components without soft-link information. Embedding similarity visualization and ablations comparing edge weight aggregation (sum vs mean vs max) are used. No adversarial robustness tests or distribution shift experiments mentioned.
Reproducibility: Code release or dataset availability is not stated. The dataset is proprietary to an industrial payment platform. Detailed pseudocode and parameter choices of each step are provided. The approach could be implemented given sufficient access to hard and soft links and graph processing capability.
Example End-to-End Process: Starting with the raw heterogeneous account graph of 25M accounts interconnected by hard and soft links, perform union-find to identify 7.7M hard-link connected components (super-nodes). Then aggregate soft-link weights between super-nodes forming a weighted graph. Train LINE embeddings on this reduced graph producing 128-dimensional vectors for each super-node. Finally, run HDBSCAN to identify clusters corresponding to potential fraud rings, then rank these clusters by risk for analyst review. This pipeline efficiently scales to billions of edges and maintains strong fraud detection coverage with manageable computational cost.
Technical innovations
- Principled graph transformation merging high-confidence hard-link components into super-nodes, reducing graph size and complexity before embedding.
- Weighted soft-link aggregation between super-nodes by summation to accurately capture behavioral association strength and enable effective embedding.
- Combination of LINE network embedding modeling both first- and second-order proximities optimized via edge sampling for managing highly skewed edge-weight distributions.
- Use of HDBSCAN density-based clustering on learned embeddings to automatically detect fraud rings of unknown number and varying density without labeled data.
Datasets
- Proprietary payment platform heterogeneous account graph — 25 million account nodes, hundreds of millions of edges — not publicly available
Baselines vs proposed
- Hard-link-only baseline: detection coverage = X (value implicitly half of proposed approach) vs proposed method: detection coverage doubled while maintaining high precision (exact numbers not explicitly stated)
- Aggregation methods for soft-link weight: sum aggregation precision outperforms mean and max aggregation by 3-5%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2512.19061.
Fig 1: Illustration of a fraud network. Fraudulent actors
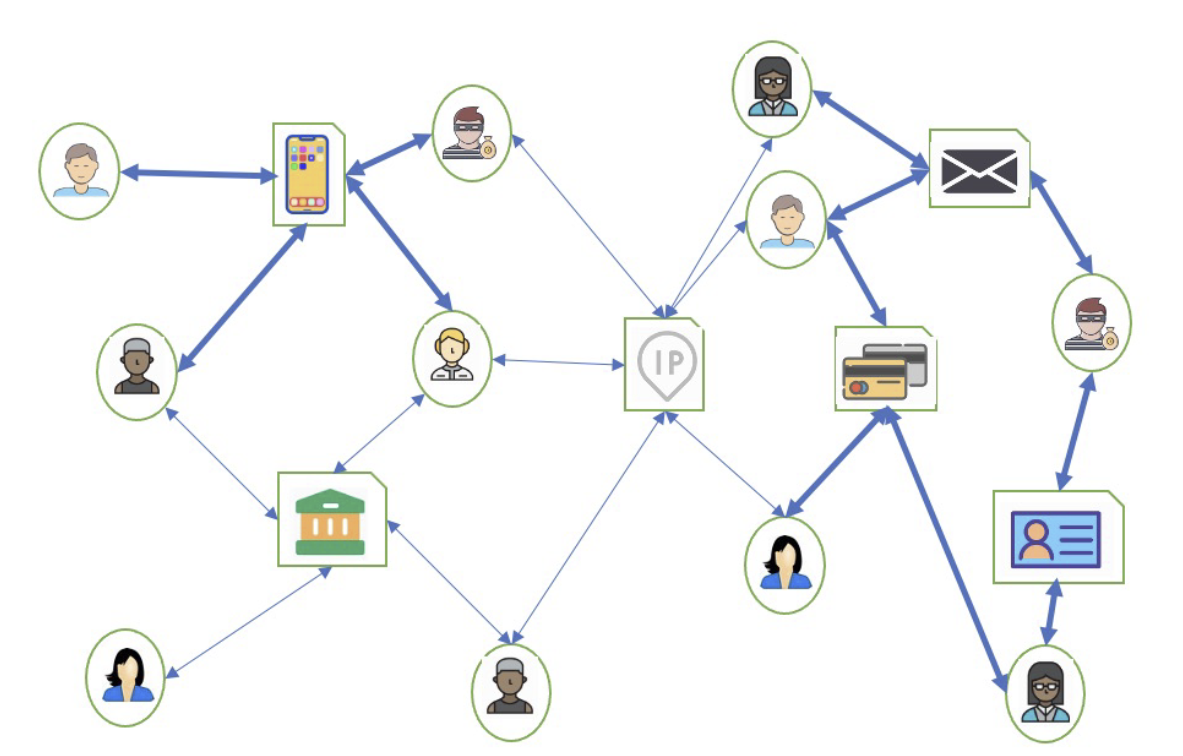
Fig 3: Example of a heterogeneous account graph. User
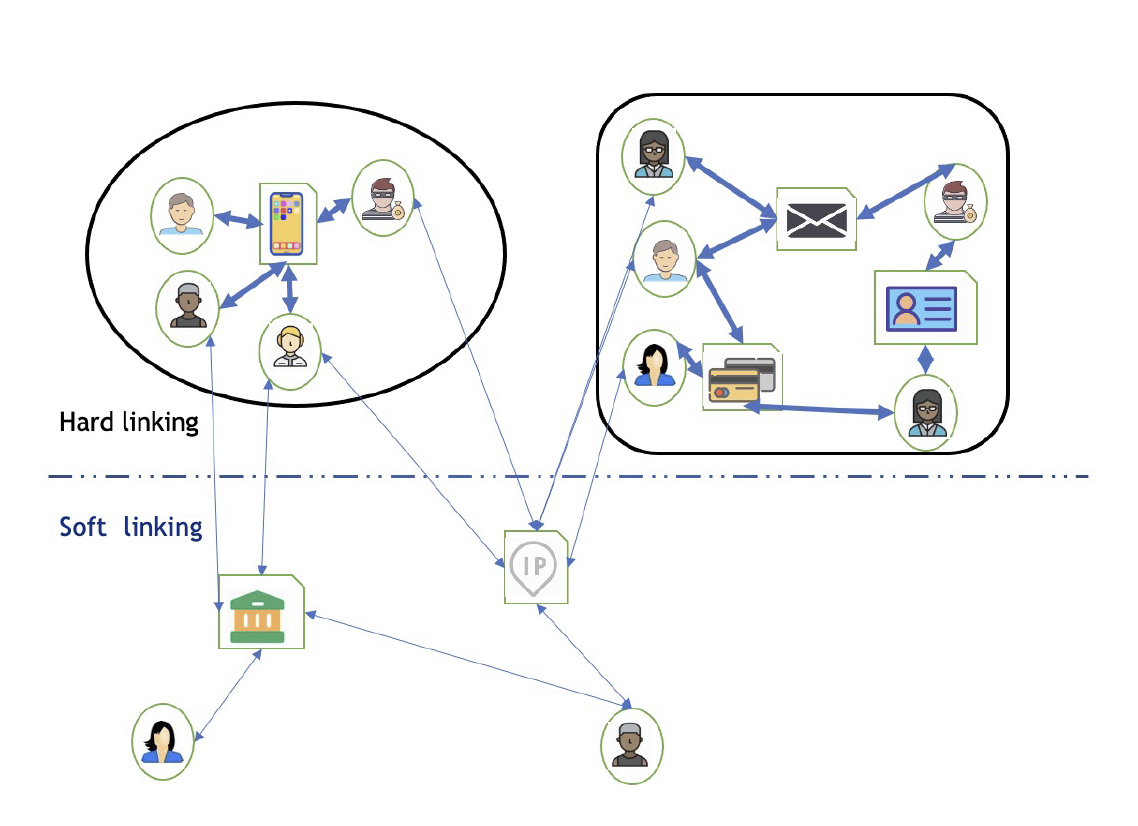
Fig 4: Illustration of hard links vs. soft links in the graph
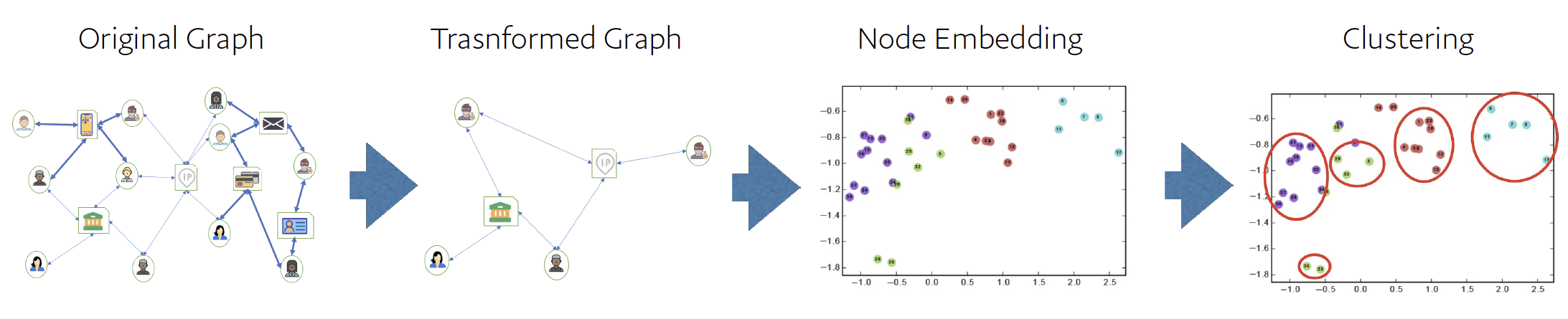
Fig 5: Complete fraud detection pipeline (Algorithm 2) illustrated in four stages. Stage 1 (Original Graph): Heterogeneous
Limitations
- The dataset is proprietary and not publicly available, limiting reproducibility and external validation.
- No explicit adversarial or temporal robustness evaluation; fraudsters may adapt linkage strategies over time.
- The approach assumes reliable classification of hard vs. soft links but real-world data may have ambiguous cases.
- HDBSCAN clustering complexity is quadratic in node count, potentially limiting scalability without further optimization despite node reduction.
- Parameter choices like embedding dimension, negative samples, and HDBSCAN settings are not fully explored or optimized in a principled way.
- No detailed analysis on false positives or detailed precision-recall tradeoffs in diverse fraud scenarios.
Open questions / follow-ons
- How robust is the method to adversaries explicitly manipulating behavioral soft links to evade embedding and clustering?
- Can learned embeddings be adapted over time to capture evolving fraud patterns in a streaming or online learning setting?
- Would incorporating additional modalities such as temporal activity sequences or transaction features improve fraud cluster separation?
- How do graph neural networks or contrastive learning methods compare on this transformed super-node graph in terms of scalability and detection quality?
Why it matters for bot defense
Bot-defense and CAPTCHA practitioners can draw valuable lessons from this framework’s approach to handling large-scale, heterogeneous graphs with diverse link reliability. The distinction between high-confidence identity edges and noisier behavioral associations parallels the trade-offs in bot detection signals—some features have high precision but limited coverage, others broader coverage but more noise. The super-node graph transformation technique provides a scalable preprocessing step to consolidate reliably linked entities before applying embedding and clustering, thus potentially improving representational quality and downstream detection of coordinated fraud or bot rings.
Additionally, the use of density-based clustering without predefining cluster count aligns well with bot defense scenarios where novel or evolving threat groups appear unpredictably. The paper’s empirical demonstration on tens of millions of nodes and hundreds of millions of edges illustrates practical scalability considerations relevant for large CAPTCHA or bot detection pipelines that analyze heterogeneous multi-modal signals. Finally, the risk scoring and analyst prioritization components highlight the importance of operationalizing unsupervised graph-based detection into actionable outputs, a key concern in real-world bot defense systems.
Cite
@article{arxiv2512_19061,
title={ Fraud Detection Through Large-Scale Graph Clustering with Heterogeneous Link Transformation },
author={ Chi Liu },
journal={arXiv preprint arXiv:2512.19061},
year={ 2025 },
url={https://arxiv.org/abs/2512.19061}
}