
Deep Reinforcement Learning for Phishing Detection with Transformer-Based Semantic Features
Source: arXiv:2512.06925 · Published 2025-12-07 · By Aseer Al Faisal
TL;DR
This paper addresses the critical problem of detecting phishing URLs, a major cybersecurity threat used to steal personal information. Traditional detection approaches relying on handcrafted lexical features or static machine learning models struggle to generalize robustly to novel phishing tactics due to attackers' constant obfuscation and evasion. To overcome this, the author proposes a hybrid deep reinforcement learning (DRL) framework combining semantic embeddings from a frozen RoBERTa transformer with 50 manually engineered lexical and structural URL features to form a comprehensive state space for phishing classification. The reinforcement learning agent uses a Quantile Regression Deep Q-Network (QR-DQN) that models the full distribution of Q-values via quantile regression, rather than scalar expected returns as in standard DQN, aiming to better handle uncertainty and improve stability.
Using a curated dataset of 105,000 URLs collected from diverse sources including PhishTank, OpenPhish, and Cloudflare, the QR-DQN agent was trained and evaluated under an 80/20 split as well as 5-fold cross-validation. Results include a high test accuracy of 99.86%, precision at 99.75%, recall of 99.96%, and F1-score of 99.85%, demonstrating the model's strong phishing detection capability. Compared against a baseline standard DQN using only lexical features, the proposed method vastly reduces the generalization gap from 1.66% to 0.04%, indicating better robustness to unseen or obfuscated phishing variants. The approach also employs a carefully designed customized environment with an asymmetric reward function prioritizing the costly avoidance of false negatives. Extensive feature engineering combined with contextual RoBERTa embeddings proved effective in capturing both shallow and deep semantic cues in phishing URLs. Overall, the hybrid QR-DQN framework advances adaptive, uncertainty-aware phishing detection, showing promise for deployment in dynamic real-world cybersecurity settings.
Key findings
- QR-DQN with RoBERTa semantic embeddings plus 50 lexical features achieved test accuracy = 99.86%, precision = 99.75%, recall = 99.96%, F1-score = 99.85%.
- Compared to standard DQN with lexical features only, the hybrid QR-DQN lowered the generalization accuracy gap (train-test) from 1.66% to 0.04%.
- 5-fold cross-validation yielded a mean accuracy of 99.90% with a standard deviation of 0.04%, demonstrating model robustness.
- Incorporating semantic embeddings from RoBERTa (768 dimensions) alongside lexical features enabled better detection of obfuscated phishing tactics like homoglyphs, subdomain shuffling, and encoding tricks.
- QR-DQN uses quantile regression to model return distributions via multiple quantiles, improving stability and uncertainty awareness over traditional scalar-valued DQN.
- The asymmetric reward function penalized false negatives (-2.0) more than false positives (-0.5), leading to very high phishing recall (99.96%).
- Experiments included manipulated phishing URLs mimicking real attacker obfuscations (e.g., character substitution ‘g00gle’), stressing the model’s generalization.
- Experience replay buffer of 150,000 transitions and target network soft updates (τ=0.005) improved training stability and convergence.
Threat model
The adversary is a phishing attacker who crafts malicious URLs using obfuscation techniques such as character substitution, Punycode encoding, subdomain shuffling, and look-alike TLDs to evade detection. The attacker can modify URL lexical structures but cannot directly manipulate the semantic embeddings or the deployed detection system internals. The defense aims to identify phishing URLs reliably with a strong emphasis on minimizing missed detections (false negatives).
Methodology — deep read
Threat Model & Assumptions: The adversary is a phishing attacker attempting to evade automated URL classification by subtle obfuscation. The model assumes attackers cannot access or influence the learned policy directly but may modify URL patterns using homoglyphs, encoding, domain mimicry, etc. The goal is to detect phishing URLs with minimal false negatives, prioritizing recall due to the security risk.
Data: The dataset includes 105,000 URLs collected from public reputable sources: PhishTank, OpenPhish for phishing URLs, and Cloudflare's top domains for legitimate URLs. The set includes natural phishing URLs and deliberately manipulated ones mimicking obfuscation techniques (character substitutions, punycode, encoded URLs). 50 lexical features plus raw URL text were extracted. The data was split 80/20 for training/testing and also used in 5-fold cross-validation. The lexical features include URL length, special character counts, domain characteristics, content-based metrics, HTML structure info, etc.
Architecture / Algorithm: The input state combines fixed 50-dimensional normalized handcrafted lexical features with a 768-dimensional RoBERTa transformer embedding (CLS token) derived from the URL text tokenized with BPE. This hybrid vector forms the observation space for the agent. The agent is a Quantile Regression Deep Q-Network (QR-DQN), a value-based DRL method estimating a distribution over cumulative discounted rewards using N=51 quantiles, enabling better uncertainty modeling than scalar Q-value DQN. The Q-network is a fully connected MLP with layers [512, 512, 256, 128] and ReLU activations, outputting quantile estimates per action (2 discrete actions: phishing or legitimate). A separate target network is updated via Polyak averaging (τ=0.005) every 1,000 steps for training stability.
Training Regime: Training lasted 300,000 timesteps with an experience replay buffer capacity of 150,000 transitions. Batch size was 512 with 8 gradient updates every 4 steps. Exploration uses ε-greedy starting at ε=1 decaying to 0.02 over 25% of training. The optimizer minimizes quantile Huber loss between predicted and target quantiles. Gradients are clipped to norm ≤10. Reward function is asymmetric (+1 correct, -2 false negative, -0.5 false positive), formulated to prioritize reducing phishing misses.
Evaluation Protocol: Metrics include accuracy, precision, recall, F1-score, balanced accuracy, false negative rate (FNR), and false positive rate (FPR). The generalization gap between train and test accuracy and F1 was computed. Baselines included standard DQN trained only on lexical features. Tests included natural and obfuscated phishing URLs to assess robustness. Results were averaged over 5-fold cross-validation to verify stability.
Reproducibility: The paper does not explicitly mention releasing code or pretrained weights; the URL dataset is custom and partially private but built from public sources. RoBERTa-base is used pretrained without fine-tuning. Precomputed embeddings are cached to speed training. Parameter details and architecture are fully specified.
Example End-to-End: A URL string is tokenized by RoBERTa’s BPE model to yield a 768-dimensional embedding representing semantic context. Simultaneously, 50 lexical features (e.g. length, special char counts, obfuscation ratios) are extracted and normalized. These vectors are concatenated to form the state input to the QR-DQN MLP. The agent outputs quantile distributions of Q-values per action; taking the mean determines the predicted label for phishing or legitimate. Upon receiving a reward based on correctness (weighted more heavily for FN), the agent updates its Q-network via quantile regression loss using experience replay samples, optimizing its policy over time to adapt to novel phishing patterns captured by semantic and lexical cues.
Technical innovations
- Integration of frozen RoBERTa transformer-based 768-dimensional semantic embeddings with handcrafted lexical features for phishing URL representation.
- Application of Quantile Regression Deep Q-Network (QR-DQN) to phishing detection, modeling full return distributions for improved uncertainty-aware value estimation.
- Design of an asymmetric reward function biasing the DRL agent toward minimizing false negatives, reflecting real-world phishing detection priorities.
- Development of a hybrid state space combining deep semantic context with engineered lexical and structural URL features to enhance generalization against obfuscated attacks.
Datasets
- Custom Phishing URL Dataset — 105,000 URLs — Curated from public sources including PhishTank, OpenPhish, Cloudflare top domains
Baselines vs proposed
- Standard DQN (lexical features only): test accuracy gap = 1.66% vs QR-DQN (lex + semantic) gap = 0.04%
- QR-DQN (lex + RoBERTa semantic) test accuracy = 99.86%, precision = 99.75%, recall = 99.96%, F1-score = 99.85%
- QR-DQN 5-fold cross-validation mean accuracy = 99.90% with std dev 0.04%
Figures from the paper
Figures are reproduced from the source paper for academic discussion. Original copyright: the paper authors. See arXiv:2512.06925.
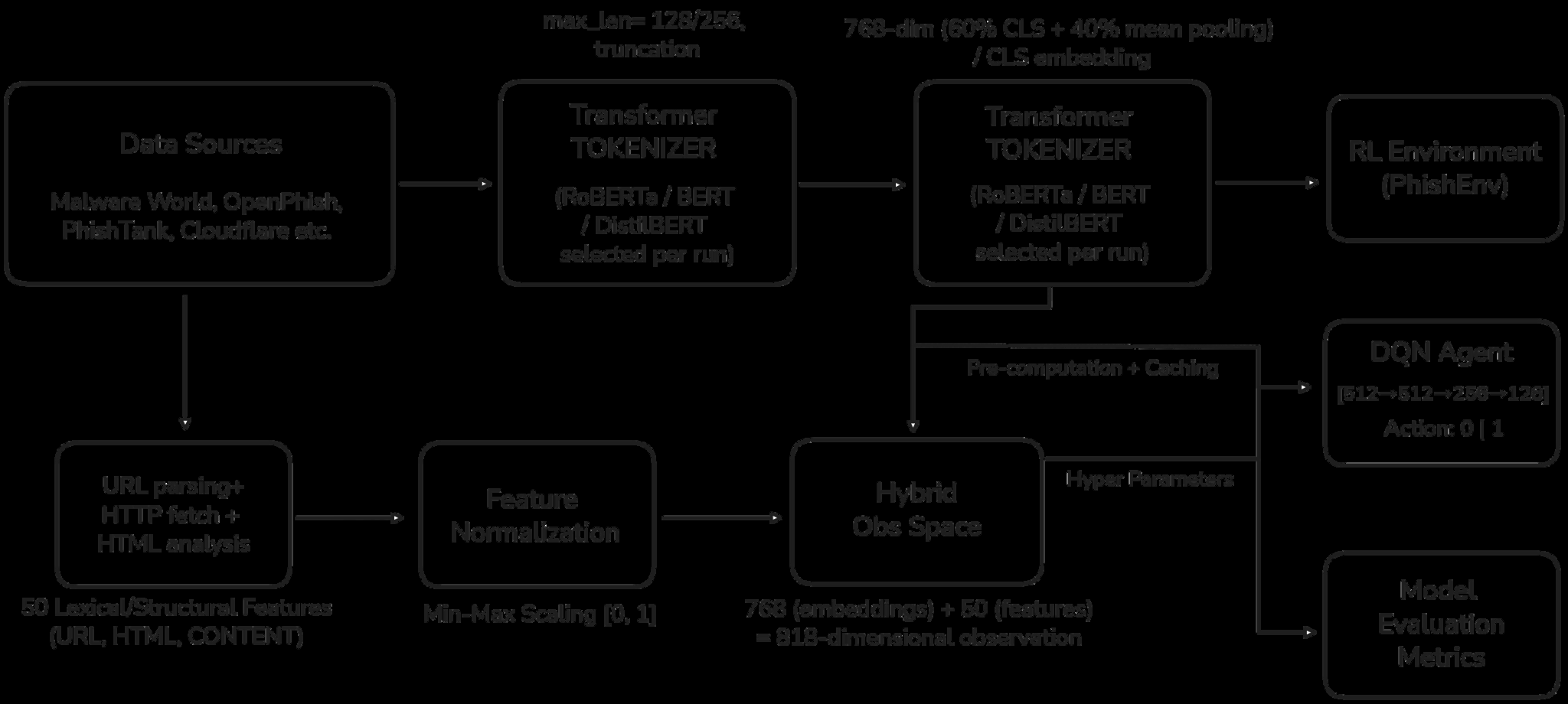
Fig 1: Architecture of the phishing detection system
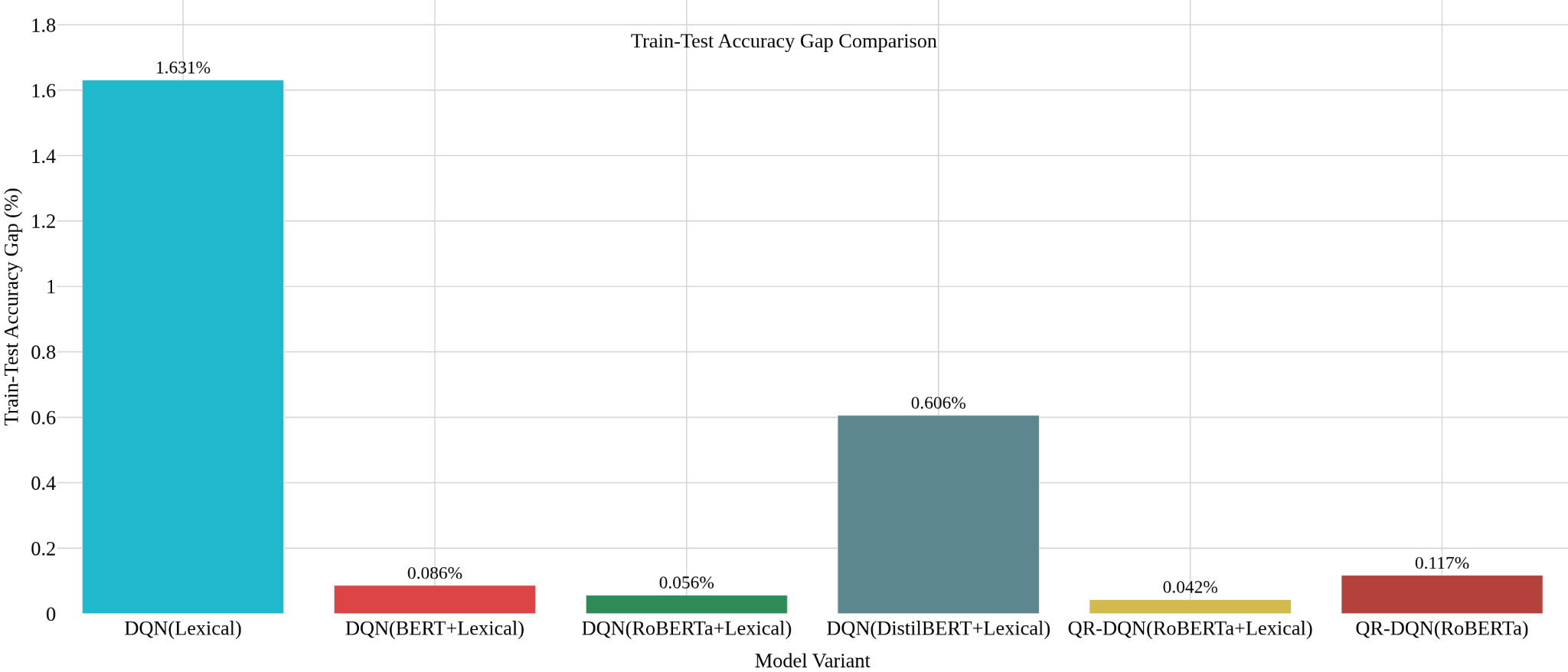
Fig 2 (page 15).
Limitations
- No explicit adversarial robustness evaluation against adaptive attackers who might target semantic embedding weaknesses.
- Dataset includes some manipulated phishing samples but lacks full real-world temporal drift testing or distribution shifts.
- RoBERTa embeddings were used frozen without domain-specific fine-tuning, possibly limiting semantic discrimination.
- No reported inference latency or computational cost measurements for real-time deployment feasibility.
- Code and dataset availability not confirmed, affecting reproducibility.
Open questions / follow-ons
- How does the QR-DQN based phishing detector perform under active adaptive adversarial attacks designed to deceive semantic embedding models?
- What improvements could be achieved with domain-specific fine-tuning of the RoBERTa embeddings on phishing URL corpora?
- How well does this method scale and perform in real-world production settings with real-time constraints and evolving attack distributions over time?
- Can other distributional RL algorithms or transformer architectures further improve uncertainty modeling or robustness in phishing detection?
Why it matters for bot defense
For bot-defense and CAPTCHA practitioners, this paper demonstrates advancing phishing URL detection by combining deep semantic embeddings and reinforcement learning with distributional value estimates. The use of QR-DQN to model Q-value distributions rather than expected values shows promising gains in uncertainty awareness and generalization—key for evolving adversarial environments encountered in bot attacks and automated fraud. Integrating transformer-based embeddings into a RL policy space alongside handcrafted lexical features illustrates a hybrid feature engineering approach that can improve detecting complex evasion techniques beyond surface heuristics. Practitioners seeking to augment CAPTCHA risk scoring or risk-based bot mitigation systems could benefit from similar hybrid encoding of URLs or webpage contents combined with distributional RL for adaptive threat recognition. The asymmetric reward design prioritizing false negative reduction also aligns with security priorities in CAPTCHAs, where missing a phishing threat can cause major damage. However, practical deployment would need real-time inference considerations and further robustness testing under adversarial pressures common in bot-driven attacks.
Cite
@article{arxiv2512_06925,
title={ Deep Reinforcement Learning for Phishing Detection with Transformer-Based Semantic Features },
author={ Aseer Al Faisal },
journal={arXiv preprint arXiv:2512.06925},
year={ 2025 },
url={https://arxiv.org/abs/2512.06925}
}